
Heim >Technologie-Peripheriegeräte >KI >Das multimodale Modell des Nationalen Volkskongresses bewegt sich in Richtung AGI: Es realisiert erstmals unabhängige Aktualisierungen und die Foto-Video-Generierung übertrifft Sora
Das multimodale Modell des Nationalen Volkskongresses bewegt sich in Richtung AGI: Es realisiert erstmals unabhängige Aktualisierungen und die Foto-Video-Generierung übertrifft Sora

- PHPznach vorne
- 2024-04-30 08:13:071353Durchsuche
Im Vergleich zum ChatImg-Sequenzmodell der vorherigen Generation der Sophon Engine übernimmt Awaker 1.0 eine neue MOE-Architektur und verfügt über unabhängige Aktualisierungsfunktionen. Es ist das erste multimodale große Modell in der Branche, das „echte“ Unabhängigkeit erreicht aktualisieren.
In Bezug auf die visuelle Generierung verwendet Awaker 1.0 eine vollständig selbst entwickelte Videogenerierungsbasis VDT, die bei der Generierung von Fotovideos bessere Ergebnisse als Sora erzielt und die Schwierigkeit der „letzten Meile“ bei der Landung großer Modelle überwindet.
 Awaker 1.0 ist ein multimodales großes Modell, das visuelles Verständnis und visuelle Generierung hervorragend integriert. Auf der Verständnisseite interagiert Awaker 1.0 mit der digitalen Welt und der realen Welt und gibt während der Aufgabenausführung Daten zum Szenenverhalten zurück, um eine kontinuierliche Aktualisierung und Schulung zu erreichen. Auf der Generierungsseite kann Awaker 1.0 hochwertige Multi-Daten generieren. Modaler Inhalt, Simulation der realen Welt und Bereitstellung weiterer Trainingsdaten für das verstehende Seitenmodell.
Awaker 1.0 ist ein multimodales großes Modell, das visuelles Verständnis und visuelle Generierung hervorragend integriert. Auf der Verständnisseite interagiert Awaker 1.0 mit der digitalen Welt und der realen Welt und gibt während der Aufgabenausführung Daten zum Szenenverhalten zurück, um eine kontinuierliche Aktualisierung und Schulung zu erreichen. Auf der Generierungsseite kann Awaker 1.0 hochwertige Multi-Daten generieren. Modaler Inhalt, Simulation der realen Welt und Bereitstellung weiterer Trainingsdaten für das verstehende Seitenmodell.
Besonders wichtig ist, dass Awaker 1.0 aufgrund seiner „echten“ autonomen Update-Fähigkeiten für ein breiteres Spektrum an Branchenszenarien geeignet ist und komplexere praktische Aufgaben lösen kann, wie z. B. AI Agent, verkörperte Intelligenz, umfassendes Management, und Sicherheitsinspektion usw.
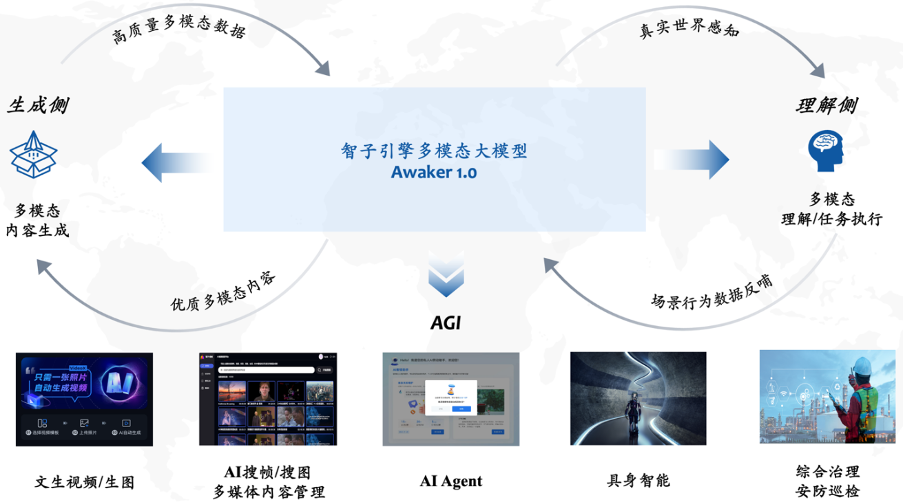
Auf der Verständnisseite löst das Basismodell von Awaker 1.0 hauptsächlich das Problem schwerwiegender Konflikte im multimodalen Multitasking-Vortraining. Das Basismodell von Awaker 1.0 profitiert von der sorgfältig entwickelten Multitask-MOE-Architektur und kann nicht nur die Grundfunktionen des multimodalen Großmodells ChatImg der vorherigen Generation der Sophon Engine übernehmen, sondern auch die einzigartigen Fähigkeiten erlernen, die für jede multimodale Aufgabe erforderlich sind . Im Vergleich zum multimodalen Großmodell ChatImg der vorherigen Generation wurden die Basismodellfunktionen von Awaker 1.0 in mehreren Aufgaben erheblich verbessert.
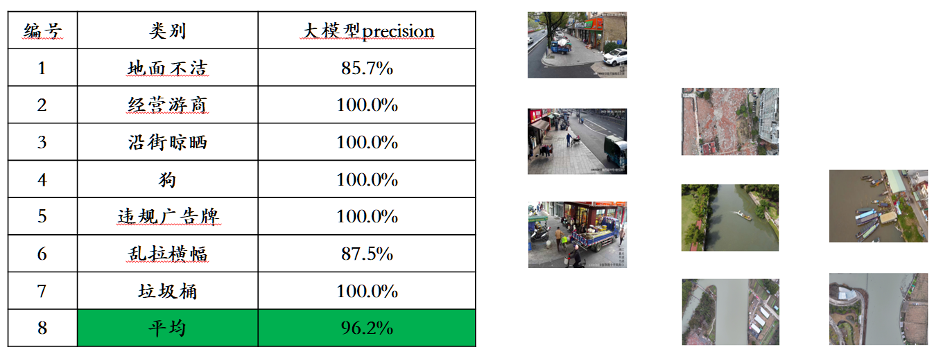
Angesichts des Problems der Leckage von Bewertungsdaten in gängigen multimodalen Bewertungslisten haben wir strenge Standards übernommen, um unseren eigenen Bewertungssatz zu erstellen, in dem die meisten Testbilder aus persönlichen Mobiltelefonalben stammen. In diesem multimodalen Bewertungssatz führen wir eine faire manuelle Bewertung von Awaker 1.0 und den drei fortschrittlichsten multimodalen Großmodellen im In- und Ausland durch. Die detaillierten Bewertungsergebnisse sind in der folgenden Tabelle aufgeführt. Beachten Sie, dass GPT-4V und Intern-VL Erkennungsaufgaben nicht direkt unterstützen. Ihre Erkennungsergebnisse werden dadurch erhalten, dass das Modell die Objektorientierung mithilfe von Sprache beschreiben muss.
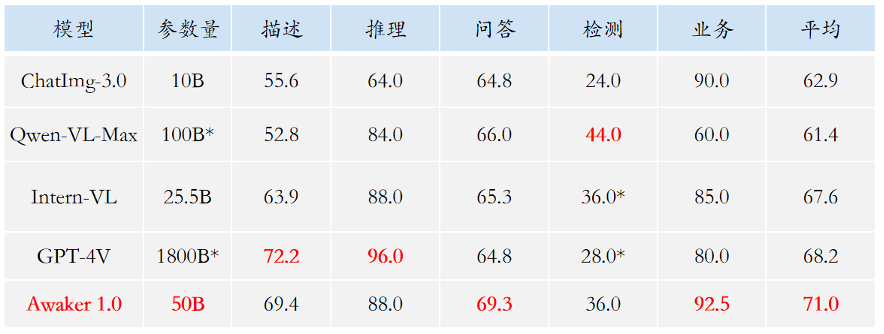 Wir haben festgestellt, dass das Basismodell von Awaker 1.0 GPT-4V, Qwen-VL-Max und Intern-VL bei der visuellen Beantwortung von Fragen und Geschäftsanwendungsaufgaben übertraf und gleichzeitig das nächstbeste Ergebnis erzielte. Insgesamt übertrifft die durchschnittliche Punktzahl von Awaker 1.0 die der drei fortschrittlichsten Modelle im In- und Ausland und bestätigt die Wirksamkeit der Multitasking-MOE-Architektur. Nachfolgend finden Sie einige konkrete Beispiele für vergleichende Analysen.
Wir haben festgestellt, dass das Basismodell von Awaker 1.0 GPT-4V, Qwen-VL-Max und Intern-VL bei der visuellen Beantwortung von Fragen und Geschäftsanwendungsaufgaben übertraf und gleichzeitig das nächstbeste Ergebnis erzielte. Insgesamt übertrifft die durchschnittliche Punktzahl von Awaker 1.0 die der drei fortschrittlichsten Modelle im In- und Ausland und bestätigt die Wirksamkeit der Multitasking-MOE-Architektur. Nachfolgend finden Sie einige konkrete Beispiele für vergleichende Analysen.
Einerseits erwarten die Menschen, dass die verkörperte Intelligenz anpassungsfähig ist, das heißt, der Agent kann sich durch kontinuierliches Lernen an sich ändernde Anwendungsumgebungen anpassen. Er kann nicht nur bekannte multimodale Aufgaben besser erledigen, sondern sich auch schnell anpassen zu multimodalen Aufgaben.
Andererseits erwarten die Menschen auch, dass verkörperte Intelligenz wirklich kreativ ist, in der Hoffnung, dass sie durch autonome Erkundung der Umwelt neue Strategien und Lösungen entdecken und die Grenzen der Fähigkeiten künstlicher Intelligenz erkunden kann. Durch die Verwendung multimodaler großer Modelle als „Gehirne“ der verkörperten Intelligenz haben wir das Potenzial, die Anpassungsfähigkeit und Kreativität der verkörperten Intelligenz dramatisch zu steigern und letztendlich die Schwelle von AGI zu erreichen (oder sogar AGI zu erreichen).
Es gibt jedoch zwei offensichtliche Probleme bei bestehenden großen multimodalen Modellen: Erstens ist der iterative Aktualisierungszyklus des Modells lang und erfordert große menschliche und finanzielle Investitionen; zweitens kommen die Trainingsdaten des Modells Aus vorhandenen Daten kann das Modell nicht kontinuierlich eine große Menge an neuem Wissen gewinnen. Obwohl die kontinuierliche Entstehung neuen Wissens auch durch RAG und langen Kontext eingebracht werden kann, lernt das multimodale große Modell selbst dieses neue Wissen nicht, und diese beiden Korrekturmethoden bringen auch zusätzliche Probleme mit sich.
Kurz gesagt, die aktuellen großen multimodalen Modelle sind in tatsächlichen Anwendungsszenarien nicht sehr anpassungsfähig, geschweige denn kreativ, was bei der Implementierung in der Branche zu verschiedenen Schwierigkeiten führt.
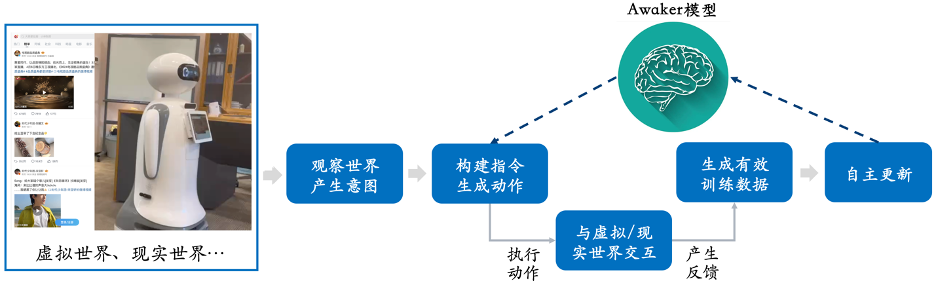 Der von Sophon Engine veröffentlichte Awaker 1.0 ist dieses Mal das weltweit erste multimodale Großmodell mit einem autonomen Aktualisierungsmechanismus, der als „Gehirn“ der verkörperten Intelligenz verwendet werden kann. Der autonome Aktualisierungsmechanismus von Awaker 1.0 umfasst drei Schlüsseltechnologien: aktive Datengenerierung, Modellreflexion und -bewertung sowie kontinuierliche Modellaktualisierung.
Der von Sophon Engine veröffentlichte Awaker 1.0 ist dieses Mal das weltweit erste multimodale Großmodell mit einem autonomen Aktualisierungsmechanismus, der als „Gehirn“ der verkörperten Intelligenz verwendet werden kann. Der autonome Aktualisierungsmechanismus von Awaker 1.0 umfasst drei Schlüsseltechnologien: aktive Datengenerierung, Modellreflexion und -bewertung sowie kontinuierliche Modellaktualisierung.
Anders als alle anderen großen multimodalen Modelle ist Awaker 1.0 „live“ und seine Parameter können kontinuierlich in Echtzeit aktualisiert werden.
Wie aus dem Rahmendiagramm oben ersichtlich ist, kann Awaker 1.0 mit verschiedenen intelligenten Geräten kombiniert werden, die Welt über intelligente Geräte beobachten, Handlungsabsichten generieren und automatisch Anweisungen erstellen, um intelligente Geräte zu steuern, um verschiedene Aktionen auszuführen. Intelligente Geräte generieren nach Abschluss verschiedener Aktionen automatisch verschiedene Rückmeldungen. Aus diesen Aktionen und Rückmeldungen kann Awaker 1.0 effektive Trainingsdaten zur kontinuierlichen Selbstaktualisierung abrufen und die verschiedenen Fähigkeiten des Modells kontinuierlich stärken.
Am Beispiel der Einspeisung neuen Wissens kann Awaker 1.0 kontinuierlich die neuesten Nachrichteninformationen im Internet lernen und auf der Grundlage der neu erlernten Nachrichteninformationen verschiedene komplexe Fragen beantworten. Im Gegensatz zu den herkömmlichen RAG- und Long-Context-Methoden kann Awaker 1.0 wirklich neues Wissen erlernen und sich die Parameter des Modells „merken“.

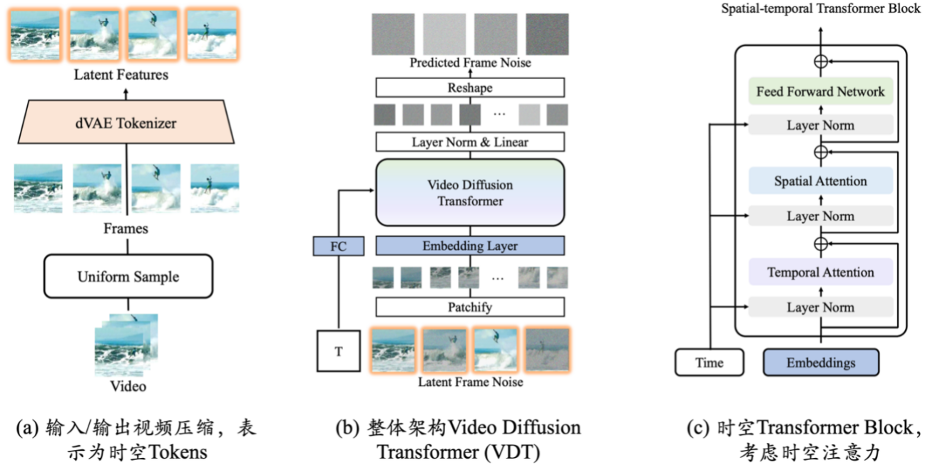
Die Anwendung der Transformer-Technologie auf die diffusionsbasierte Videogenerierung zeigt das große Potenzial von Transformer im Bereich der Videogenerierung. Der Vorteil von VDT ist seine hervorragende zeitabhängige Erfassungsfähigkeit, die die Erzeugung zeitlich kohärenter Videobilder ermöglicht, einschließlich der Simulation der physikalischen Dynamik dreidimensionaler Objekte im Zeitverlauf. Schlagen Sie einen einheitlichen räumlich-zeitlichen Maskenmodellierungsmechanismus vor, damit VDT eine Vielzahl von Videogenerierungsaufgaben bewältigen kann, und realisieren Sie so die breite Anwendung dieser Technologie. Die flexiblen bedingten Informationsverarbeitungsmethoden von VDT, wie z. B. einfaches Token-Space-Splicing, vereinheitlichen effektiv Informationen unterschiedlicher Länge und Modalitäten. Gleichzeitig ist VDT durch die Kombination mit dem räumlich-zeitlichen Maskenmodellierungsmechanismus zu einem universellen Videodiffusionswerkzeug geworden, das auf die bedingungslose Generierung, die Vorhersage nachfolgender Videobilder, die Bildinterpolation, bildgenerierende Videos und Videobilder angewendet werden kann, ohne die Daten zu ändern Modellstruktur. Fertigstellung und andere Videogenerierungsaufgaben.


Das obige ist der detaillierte Inhalt vonDas multimodale Modell des Nationalen Volkskongresses bewegt sich in Richtung AGI: Es realisiert erstmals unabhängige Aktualisierungen und die Foto-Video-Generierung übertrifft Sora. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Intel verfügt über umfassende Einblicke in die Branche in vier Hauptgeschäftsbereichen und interpretiert Anwendungsbeispiele, innovative Produkte und Lösungen – Intel Vision
- Top 10 der besten PC-Emulatoren für PUBG Mobile für Windows PC und Mac 2022
- Künstliche Intelligenz bringt neuen Schwung in die Pharmaindustrie meines Landes
- Lassen Sie uns gemeinsam das digitale Guangxi aufbauen und gemeinsam in eine digitale Zukunft gehen! Die ökologische Konferenz der Industrie für künstliche Intelligenz in Guangxi Kunpeng Shengteng 2023 wurde erfolgreich abgehalten
- Installieren Sie einen Emulator auf dem Apple Mac, um die Verwendung von Simulationssoftware unter dem Mac zu erleichtern