
Heim >Technologie-Peripheriegeräte >KI >Der derzeit stärkste heimische Sora! Das Tsinghua-Team durchbricht 16 Sekunden lange Videos, versteht die Sprache mit mehreren Linsen und kann physikalische Gesetze simulieren
Der derzeit stärkste heimische Sora! Das Tsinghua-Team durchbricht 16 Sekunden lange Videos, versteht die Sprache mit mehreren Linsen und kann physikalische Gesetze simulieren

- 王林nach vorne
- 2024-04-28 13:04:011190Durchsuche
Sie sagten, die Schachtel sollte mit Diamanten gefüllt sein, also war die Schachtel mit Diamanten gefüllt, was noch schillernder war als die echte Aufnahme. Welche Crew würde solche Fähigkeiten nicht mögen?
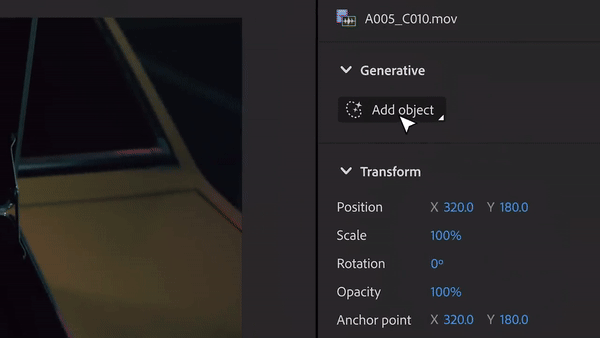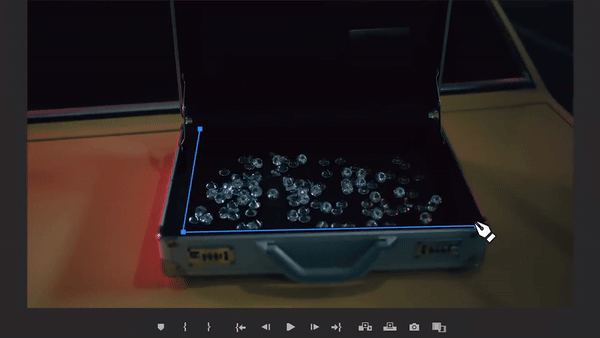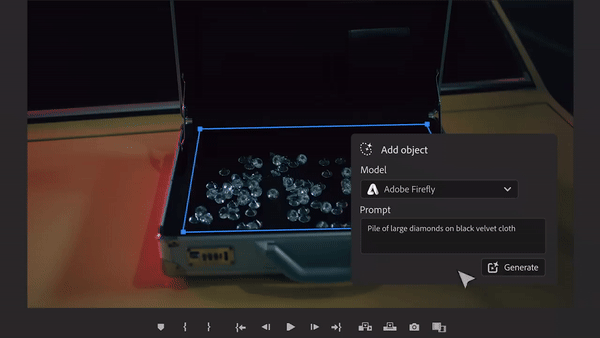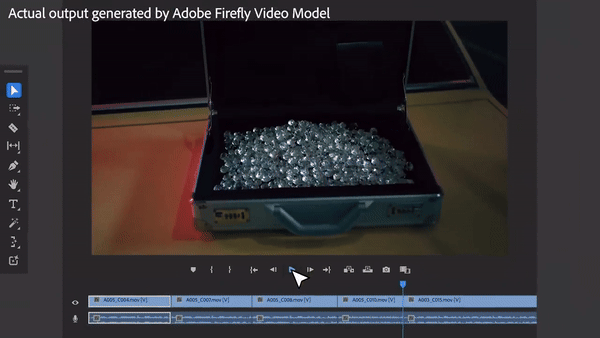
Das ist die „Magie“, die Adobes Videobearbeitungssoftware Premiere Pro vor einiger Zeit präsentierte. Diese Software führt KI-Videotools wie Sora, Runway und Pika ein, um die Möglichkeit zu erreichen, Objekte hinzuzufügen, Objekte zu entfernen und Videoclips in Videos zu generieren. Dies gilt als eine weitere technologische Innovation im Videobereich.
Seit Februar, als Sora die Welt erneut mit der Magie von Adobe eroberte, ist Übersee in vollem Gange. Im Gegensatz dazu befindet sich China im Videobereich immer noch in einem „Wartezustand“, insbesondere in Richtung der Erzeugung langer Videos. In den letzten zwei Monaten haben wir einige Behauptungen gehört, die Sora verfolgen würden, konnten aber noch keine nennenswerten Fortschritte im Inland feststellen. Aber das kurze Video, das Shengshu Technology heute gerade veröffentlicht hat, hält uns für viele Überraschungen bereit. 
Dies ist das offizielle Video des neuesten Videomodells „Vidu“, das von Shengshu Technology und der Tsinghua University veröffentlicht wurde. Es ist ersichtlich, dass das von ihm generierte Video kein „GIF“ mehr ist, das einige Sekunden dauert, sondern eine Länge von mehr als zehn Sekunden hat (das längste kann etwa 16 Sekunden erreichen). Was natürlich noch überraschender ist, ist, dass die Bildwirkung von „Vidu“ der von Sora sehr nahe kommt. Es funktioniert sehr gut in Mehrlinsensprache, Zeit- und Raumkonsistenz und folgt physikalischen Gesetzen, und das kann es auch fiktiv eine Welt erschaffen, die es nicht gibt , die mit aktuellen Videogenerationsmodellen schwer zu erreichen sind. In nur zwei Monaten konnte Shengshu Technology solche Ergebnisse erzielen, was wirklich überraschend ist.
Das erste Videomodell in China, das vollständig mit Sora verglichen wird
Seit der Veröffentlichung von Sora hat der Kampf um „inländisches Sora“ begonnen. Aber wenn sich die Industrie auf das „lange“ Feature konzentriert, ignorieren sie alle, dass hinter Sora eigentlich die Verbesserung umfassender Effekte wie Konsistenz, Realismus, Schönheit usw. in langen Sequenzen steckt.
Aus Sicht der umfassenden Wirkung ist „Vidu“ das erste und einzige Videomodell, das auf Wirkungsebene vollständig mit Sora vergleichbar ist , nicht nur im Inland, sondern auch weltweit, und es ist auch das erste Videomodell, das dies erreicht ein Durchbruch nach Sora. Anhand der spezifischen Effekte können wir deutlich mehrere offensichtliche Vorteile erkennen:
Fügen Sie „Linsensprache“ in das Video ein
Es gibt ein sehr wichtiges Konzept in der Videoproduktion – Linsensprache. Es ist die wichtigste Möglichkeit, die Handlung auszudrücken, die Psychologie der Figur zu enthüllen, die Atmosphäre zu schaffen und die Emotionen des Publikums durch Bilder zu lenken. Unterschiedliche Aufnahmemöglichkeiten, Winkel, Bewegungen und Kombinationen haben großen Einfluss auf die Erzählung und das Erlebnis des Publikums.
Bestehende KI-generierte Videos können die Monotonie der Objektivsprache deutlich spüren und die Bewegung des Objektivs ist auf einfache Aufnahmen wie leichtes Drücken, Ziehen und Verschieben beschränkt. Der Hauptgrund dafür ist, dass die meisten existierenden Videoinhalte zunächst einen einzelnen Frame generieren und dann aufeinanderfolgende Frames vorher und nachher vorhersagen. Mit dem gängigen technischen Weg ist es jedoch schwierig, langfristige kohärente kleine dynamische Vorhersagen zu erzielen. Der Trailer zum Science-Fiction-Film „Trailer: Genesis“ von Runway wurde im Juli letzten Jahres erstellt.

Tipp: In einem malerischen Ferienhaus am Meer taucht die Sonne den Raum, die Kamera bewegt sich langsam zu einem Balkon mit Blick auf das ruhige Meer und schließlich friert die Kamera auf dem schwimmenden Meer, den Segelbooten und den reflektierenden Wolken ein. (Vollständiger Videoclip veröffentlicht auf der offiziellen Website von Shengshus PixWeaver-Produkt)
Darüber hinaus kann „Vidu“, wie aus mehreren Clips im Kurzfilm hervorgeht, direkt Effekte wie Übergänge, Fokusverfolgung und Totalaufnahmen erzeugen, einschließlich der Möglichkeit, Filmmaterial auf Film- und Fernsehniveau zu erzeugen und Objektivsprache einzufügen das Video und verbessern das Gesamtbild.



Aufrechterhaltung der Konsistenz von Zeit und Raum
Dahinter steckt eigentlich die räumlich-zeitliche Konsistenz der Charaktere und Szenen, wie z als Charaktere im Raum Die Bewegung ist immer konsistent und die Szene kann sich ohne Übergänge nicht plötzlich ändern. Dies ist für die KI schwierig zu erreichen, insbesondere wenn die von der KI erzeugten Videos Probleme wie Erzählbrüche, visuelle Inkohärenz und logische Fehler aufweisen. Diese Probleme beeinträchtigen den Realismus und das Vergnügen des Videos erheblich.
„Vidu“ überwindet diese Probleme bis zu einem gewissen Grad. Anhand des damit erstellten Videos „Katze mit Perlenohrring“ können wir erkennen, dass die Katze als Motiv des Bildes bei Bewegung der Kamera im 3D-Raum und im Video als Ganzes immer den gleichen Ausdruck und die gleiche Kleidung beibehält ist sehr kohärent und flüssig und behält eine gute Zeit- und Raumkonsistenz bei. 
Tipps: Dies ist ein Porträt einer orangefarbenen Katze mit blauen Augen, die sich langsam dreht, inspiriert von Vermeers „Mädchen mit dem Perlenohrring“. Das Bild trägt einen Perlenohrring und braunes Haar wie Holland Cap. schwarzer Hintergrund, Studiobeleuchtung. (Vollständiger Videoclip veröffentlicht auf der offiziellen Website des PixWeaver-Produkts unter Shengshu)
Simulation der realen physischen Welt
Eine der erstaunlichen Funktionen von Sora ist, dass es die Bewegung der realen physischen Welt simulieren kann, z die Bewegung und Interaktion von Objekten. Einer der klassischen Fälle von Sora – das Bild eines „alten SUV, der auf einem Hügel fährt“ – simuliert sehr gut den von den Reifen aufgewirbelten Staub, das Licht und den Schatten im Wald und die Schattenveränderungen während der Fahrt des Autos . Unter dem gleichen Stichwort sind die erzeugten Effekte von „Vidu“ und Sora sehr ähnlich und Details wie Staub, Licht und Schatten kommen der menschlichen Erfahrung in der realen physischen Welt sehr nahe.  Tipp: Die Kamera folgt einem weißen Oldtimer-SUV mit schwarzem Dachträger, der eine steile, von Pinien umgebene unbefestigte Straße hinunterrast, während Reifen Staub aufwirbeln und Sonnenlicht auf den SUV fällt und ihm einen warmen Glanz verleiht gesamte Szene. Die unbefestigte Straße schlängelte sich sanft in die Ferne, ohne dass andere Autos oder Fahrzeuge zu sehen waren. Auf beiden Seiten der Straße stehen Mammutbäume und hier und da sind grüne Flecken verstreut. Von hinten betrachtet folgt das Auto Kurven mit Leichtigkeit und sieht aus, als würde es über unwegsames Gelände fahren. Die unbefestigte Straße ist von steilen Hügeln und Bergen umgeben, mit klarem blauen Himmel und Wolkenfetzen darüber. (Vollständige Videofragmente veröffentlicht auf der offiziellen Website des Pixweaver-Produkts)
Tipp: Die Kamera folgt einem weißen Oldtimer-SUV mit schwarzem Dachträger, der eine steile, von Pinien umgebene unbefestigte Straße hinunterrast, während Reifen Staub aufwirbeln und Sonnenlicht auf den SUV fällt und ihm einen warmen Glanz verleiht gesamte Szene. Die unbefestigte Straße schlängelte sich sanft in die Ferne, ohne dass andere Autos oder Fahrzeuge zu sehen waren. Auf beiden Seiten der Straße stehen Mammutbäume und hier und da sind grüne Flecken verstreut. Von hinten betrachtet folgt das Auto Kurven mit Leichtigkeit und sieht aus, als würde es über unwegsames Gelände fahren. Die unbefestigte Straße ist von steilen Hügeln und Bergen umgeben, mit klarem blauen Himmel und Wolkenfetzen darüber. (Vollständige Videofragmente veröffentlicht auf der offiziellen Website des Pixweaver-Produkts) 
Soras Produktionseffekt.
Natürlich konnte „Vidu“ die Teildetails von „mit schwarzem Dachträger“ nicht generieren. Aber seine Mängel täuschen nicht über seine Vorzüge hinweg, und seine Gesamtwirkung kommt der realen Welt sehr nahe.
🎜🎜Reiche Vorstellungskraft🎜🎜🎜Im Vergleich zu realen Aufnahmen hat die Verwendung von KI zur Erstellung von Videos einen großen Vorteil: Sie kann Bilder erzeugen, die in der realen Welt nicht existieren. In der Vergangenheit erforderte der Aufbau bzw. die Erstellung von Spezialeffekten für diese Bilder oft viel Arbeitskraft und materielle Ressourcen, doch die KI kann sie in kurzer Zeit automatisch erzeugen. 🎜In der Szene unten zum Beispiel erscheinen „Segelboot“ und „Wellen“ selten im Studio und die Interaktion zwischen den Wellen und dem Segelboot ist sehr natürlich. 
Eingabeaufforderung: Ein Schiff im Studio segelt auf die Kamera zu. (Kompletter Videoclip veröffentlicht auf der offiziellen Website von Shengshus PixWeaver-Produkt)

Der „Aquarium-Mädchen“-Clip im Kurzfilm ist ebenfalls fantastisch, hat aber einen gewissen Sinn für Vernünftigkeit. Diese Fähigkeit, Bilder zu erstellen, die es in der realen Welt nicht gibt, ist sehr hilfreich für die Erstellung surrealistischer Inhalte. Sie kann nicht nur Schöpfer inspirieren und neuartige visuelle Erlebnisse bieten, sondern auch die Grenzen des künstlerischen Ausdrucks erweitern und reichhaltigere und vielfältigere Inhaltsformate ermöglichen.
Chinesische Elemente verstehen
Zusätzlich zu den oben genannten vier Merkmalen haben wir auch einige andere Überraschungen aus den von „Vidu“ veröffentlichten Kurzfilmen gesehen. „Vidu“ kann Bilder mit einzigartigen chinesischen Elementen wie Pandas und Drachen erzeugen. Palastszenen usw. 
Tipps: Am ruhigen See spielt ein Panda eifrig Gitarre und erweckt die ganze Umgebung zum Leben. Die Szene wird auf ruhigen Gewässern unter einem klaren Himmel reflektiert und in lebendigen Panoramaaufnahmen festgehalten, die Realismus mit dem lebhaften Geist des Großen Pandas verbinden und so eine harmonische Mischung aus Energie und Ruhe schaffen. (Kompletter Videoclip, veröffentlicht auf der offiziellen Website von Shenshus PixWeaver-Produkt)
Wie haben Sie diesen schnellen Durchbruch in zwei Monaten geschafft?
Shengshu Technology, das Forschungs- und Entwicklungsteam hinter „Vidu“, ist ein Unternehmerteam im Bereich multimodaler Großmodelle. Die Kernmitglieder stammen vom Forschungsinstitut für künstliche Intelligenz der Tsinghua-Universität. Modalgenerierungsfelder wie Bilder, 3D und Videos.
Im Januar dieses Jahres hat Shengshu Technology auf seiner Plattform für visuelles kreatives Design PixWeaver eine Funktion zur Generierung von Kurzvideos eingeführt, die 4-sekündige, hochästhetische Kurzvideoinhalte unterstützt. Nach dem Start von Sora im Februar soll Shengshu Technology ein formelles internes Forschungsteam eingerichtet haben, um den Forschungs- und Entwicklungsfortschritt der ursprünglichen Videorichtung zu beschleunigen. Im März erreichte das Unternehmen intern eine 8-Sekunden-Videogenerierung und erzielte dann den Durchbruch die 16-Sekunden-Generation im April und erzielte Durchbrüche in allen Aspekten der Generationsqualität und -dauer.
Wie wir alle wissen, hat Sora nicht allzu viele technische Details bekannt gegeben. Der Kern dafür, in so kurzer Zeit Durchbrüche erzielen zu können, ist die tiefe technische Anhäufung des Teams und viele originelle Erfolge von 0 auf 1, insbesondere in der Kernebene der technischen Architektur.
Die unterste Ebene von „Vidu“ basiert auf der völlig selbst entwickelten U-ViT-Architektur, die vom Team im September 2022 vorgeschlagen wurde. Sie ist früher als die von Sora übernommene DiT-Architektur und die weltweit erste Architektur das Diffusion und Transformer integriert.

Zwei Monate vor der Veröffentlichung des DiT-Papiers reichte Zhu Juns Team von der Tsinghua-Universität ein Papier ein – „All are Worth Words: A ViT Backbone for Diffusion Models“. In diesem Artikel wird eine Netzwerkarchitektur U-ViT vorgeschlagen, die Transformer verwendet, um das CNN-basierte U-Net zu ersetzen. Dies ist die wichtigste technische Grundlage von „Vidu“.
Auf der technischen Route übernimmt „Vidu“ die Diffusions- und Transformer-Fusionsarchitektur, die genau die gleiche ist wie Sora. Im Gegensatz zur mehrstufigen Verarbeitungsmethode der Interpolation von Frames zur Generierung langer Videos verfolgt „Vidu“ den gleichen Weg wie Sora, nämlich die direkte Generierung hochwertiger Videos in einem einzigen Schritt. Aus einer einfachen Perspektive handelt es sich um eine „einstufige“ Implementierungsmethode, die vollständig auf einem einzigen Modell basiert und keine Zwischenrahmeneinfügung und andere mehrstufige Textkonvertierung erfordert zum Video ist direkt und kontinuierlich. Darüber hinaus trainierte das Team im März 2023 basierend auf der U-ViT-Architektur ein multimodales Modell mit 1 Milliarde Parametern – UniDiffuser – auf dem Open-Source-Großgrafik- und Textdatensatz LAION-5B und erstellte es Open Source (siehe „Das Team von Tsinghua Zhu Jun hat das erste groß angelegte multimodale Diffusionsmodell auf Basis von Transformer als Open Source bereitgestellt, bei dem Text und Grafiken zusammenwirken und alles neu geschrieben wurde》).
UniDiffuser eignet sich hauptsächlich für Grafik- und Textaufgaben und kann die beliebige Generierung und Konvertierung zwischen Grafik- und Textmodi unterstützen. Die Implementierung von UniDiffuser hat einen wichtigen Wert: Sie hat zum ersten Mal die Skalierbarkeit (Skalierungsgesetz) der Fusionsarchitektur in groß angelegten Trainingsaufgaben überprüft, was dem Durchlaufen aller Prozesse der U-ViT-Architektur im Großen und Ganzen entspricht -skalierte Trainingsaufgaben. Erwähnenswert ist, dass UniDiffuser der Einführung von Stable Diffusion 3, einem Grafikmodell mit derselben DiT-Architektur, ein Jahr voraus ist.
Diese in Grafik- und Textaufgaben gesammelten Ingenieurserfahrungen haben den Grundstein für die Entwicklung von Videomodellen gelegt. Da es sich bei einem Video im Wesentlichen um einen Bildstrom handelt, kommt es einer Erweiterung des Bildes auf der Zeitachse gleich. Daher können die bei Bild- und Textaufgaben erzielten Ergebnisse häufig in Videoaufgaben wiederverwendet werden. Sora tut genau das: Es nutzt die Re-Annotation-Technologie von DALL・E 3, um detaillierte Beschreibungen für die visuellen Trainingsdaten zu generieren, sodass das Modell den Textanweisungen des Benutzers zum Generieren von Videos genauer folgen kann. Dieser Effekt wird bei „Vidu“ zwangsläufig auftreten.
Laut früheren Nachrichten nutzt „Vidu“ auch viele Erfahrungen von Bioshu Technology bei Grafik- und Textaufgaben, einschließlich Trainingsbeschleunigung, parallelem Training, Training mit geringem Gedächtnis usw., und führt so den Trainingsprozess schnell durch. Es wird berichtet, dass sie die Videodatenkomprimierungstechnologie verwendet haben, um die Sequenzdimension der Eingabedaten zu reduzieren, und gleichzeitig ein selbst entwickeltes verteiltes Trainingsframework übernommen haben. Dabei wurde die Berechnungsgenauigkeit sichergestellt, die Kommunikationseffizienz verdoppelt und der Speicheraufwand reduziert um 80 % und die Trainingsgeschwindigkeit wurde insgesamt um das 40-fache erhöht.
Von der Vereinheitlichung von Grafikaufgaben bis zur Integration von Videofunktionen kann „Vidu“ als allgemeines visuelles Modell betrachtet werden, das die Generierung vielfältigerer und längerer Videoinhalte unterstützen kann. Beamte gaben außerdem bekannt, dass „Vidu“ derzeit iterative Verbesserungen beschleunigt. Mit Blick auf die Zukunft wird die flexible Modellarchitektur von „Vidu“ auch mit einem breiteren Spektrum multimodaler Fähigkeiten kompatibel sein.
Ein fähiges Team der Tsinghua-Universität
Lassen Sie uns zum Schluss über das Team hinter „Vidu“ sprechen – Shengshu Technology. Dies ist ein fähiges Team mit einem Tsinghua-Hintergrund.
Das Kernteam von Shengshu Technology stammt vom Forschungsinstitut für künstliche Intelligenz der Tsinghua-Universität. Der leitende Wissenschaftler ist Zhu Jun, stellvertretender Direktor des Tsinghua-Instituts für künstliche Intelligenz; CEO Tang Jiayu hat an der Fakultät für Informatik der Tsinghua-Universität studiert und ist Mitglied der THUNLP-Gruppe Er ist Doktorand am Institut für Informatik der Tsinghua-Universität und Professor Zhu Jun. Er ist Mitglied des Forschungsteams und beschäftigt sich seit langem mit der Forschung auf dem Gebiet der Diffusionsmodelle. Er leitete die Fertigstellung von U-ViT und UniDiffuser. Das Team beschäftigt sich seit mehr als 20 Jahren mit der Forschung zu generativer künstlicher Intelligenz und Bayesianischem maschinellen Lernen und führte in den frühen Tagen des Durchbruchs tiefer generativer Modelle eingehende Forschung durch. In Bezug auf Diffusionsmodelle übernahm das Team die Führung bei der Einleitung der Forschung in diese Richtung in China, und die Ergebnisse umfassen Full-Stack-Technologierichtungen wie Backbone-Netzwerke, Hochgeschwindigkeits-Inferenzalgorithmen und groß angelegte Schulungen.
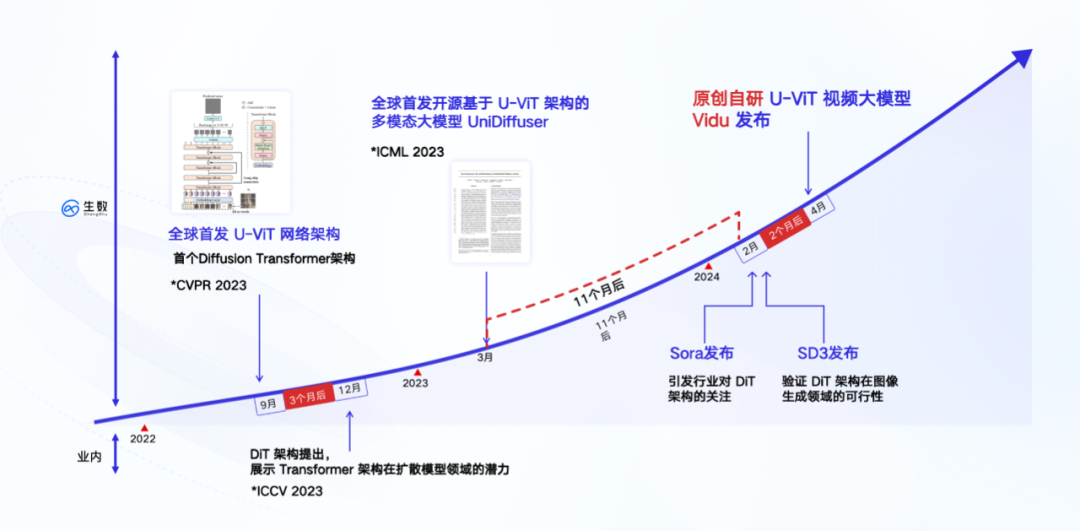 Das Team veröffentlichte fast 30 Artikel im Zusammenhang mit dem multimodalen Bereich auf führenden Konferenzen für künstliche Intelligenz wie ICML, NeurIPS und ICLR. Darunter die vorgeschlagenen trainingsfreien Inferenzalgorithmen Analytic-DPM, DPM-Solver und Weitere bahnbrechende Ergebnisse wurden mit dem ICLR Outstanding Paper Award ausgezeichnet und von ausländischen Spitzeninstitutionen wie OpenAI, Apple und Stability.ai übernommen und in Starprojekten wie DALL・E 2 und Stable Diffusion verwendet.
Das Team veröffentlichte fast 30 Artikel im Zusammenhang mit dem multimodalen Bereich auf führenden Konferenzen für künstliche Intelligenz wie ICML, NeurIPS und ICLR. Darunter die vorgeschlagenen trainingsfreien Inferenzalgorithmen Analytic-DPM, DPM-Solver und Weitere bahnbrechende Ergebnisse wurden mit dem ICLR Outstanding Paper Award ausgezeichnet und von ausländischen Spitzeninstitutionen wie OpenAI, Apple und Stability.ai übernommen und in Starprojekten wie DALL・E 2 und Stable Diffusion verwendet.
Seit seiner Gründung im Jahr 2023 wurde das Team von vielen namhaften Industrieinstitutionen wie Ant Group, Qiming Venture Partners, BV Baidu Ventures, Byte Jinqiu Fund usw. anerkannt und hat Finanzierungen in Höhe von Hunderten Millionen Yuan abgeschlossen. Berichten zufolge ist
Shengshu Technology derzeit das Unternehmerteam mit der höchsten Bewertung im multimodalen Großmodellbereich in China. Die Einführung von „Vidu“ ist eine weitere Innovation und Führungsrolle von Shenshu Technology im Bereich multimodaler nativer Großmodelle. 🔜 Dieses große Modellteam der Tsinghua-Universität gibt Hoffnung》
Das obige ist der detaillierte Inhalt vonDer derzeit stärkste heimische Sora! Das Tsinghua-Team durchbricht 16 Sekunden lange Videos, versteht die Sprache mit mehreren Linsen und kann physikalische Gesetze simulieren. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Was tun, wenn der Premiere-Bildschirm einfriert?
- So exportieren Sie Videos in Premiere
- So füllen Sie das Video in Premiere bildschirmfüllend aus
- Wie kann die von Python-Websites übertragene Datenmenge reduziert und die Zugriffsgeschwindigkeit durch Komprimierungstechnologie verbessert werden?
- Wie können kollaborative Roboter die intelligente Fertigung und Modernisierung der täglichen chemischen Industrie unterstützen? Hören Sie, was die Experten sagen