
Heim >Technologie-Peripheriegeräte >KI >Die Low-Bit-Quantisierungsleistung von Llama 3 sinkt erheblich! Umfassende Bewertungsergebnisse finden Sie hier |. HKU & Beihang University & ETH
Die Low-Bit-Quantisierungsleistung von Llama 3 sinkt erheblich! Umfassende Bewertungsergebnisse finden Sie hier |. HKU & Beihang University & ETH

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2024-04-28 09:01:121168Durchsuche
Die Leistung großer Modelle lässt LLaMA3 neue Höhen erreichen:
Auf den 15T+ Token-Daten, die in großem Maßstab vorab trainiert wurden, wurden beeindruckende Leistungsverbesserungen erzielt, und es ist erneut explodiert, weil es die empfohlenen Werte bei weitem übertrifft Band der Chinchilla Open-Source-Community-Diskussion.
Gleichzeitig ist auf der Ebene der praktischen Anwendung auch ein weiteres heißes Thema aufgetaucht:
Wie hoch wird die quantitative Leistung von LLaMA3 in Szenarien mit begrenzten Ressourcen sein?
Die Universität Hongkong, die Beihang-Universität und die Eidgenössische Technische Hochschule Zürich haben gemeinsam eine empirische Studie gestartet, die die Low-Bit-Quantisierungsfähigkeiten von LLaMA3 vollständig aufdeckte.

Die Forscher bewerteten die Ergebnisse von LLaMA3 mit 1-8 Bits und verschiedenen Bewertungsdatensätzen unter Verwendung von 10 vorhandenen quantisierten LoRA-Feinabstimmungsmethoden nach dem Training. Sie fanden heraus:
Trotz seiner beeindruckenden Leistung leidet LLaMA3 immer noch unter einer nicht zu vernachlässigenden Verschlechterung bei niedriger Bitquantisierung, insbesondere bei extrem niedrigen Bitbreiten.

Das Projekt wurde als Open Source auf GitHub bereitgestellt und das quantitative Modell wurde auch auf HuggingFace gestartet.
Schauen wir uns die empirischen Ergebnisse konkret an.
Track 1: Quantisierung nach dem Training
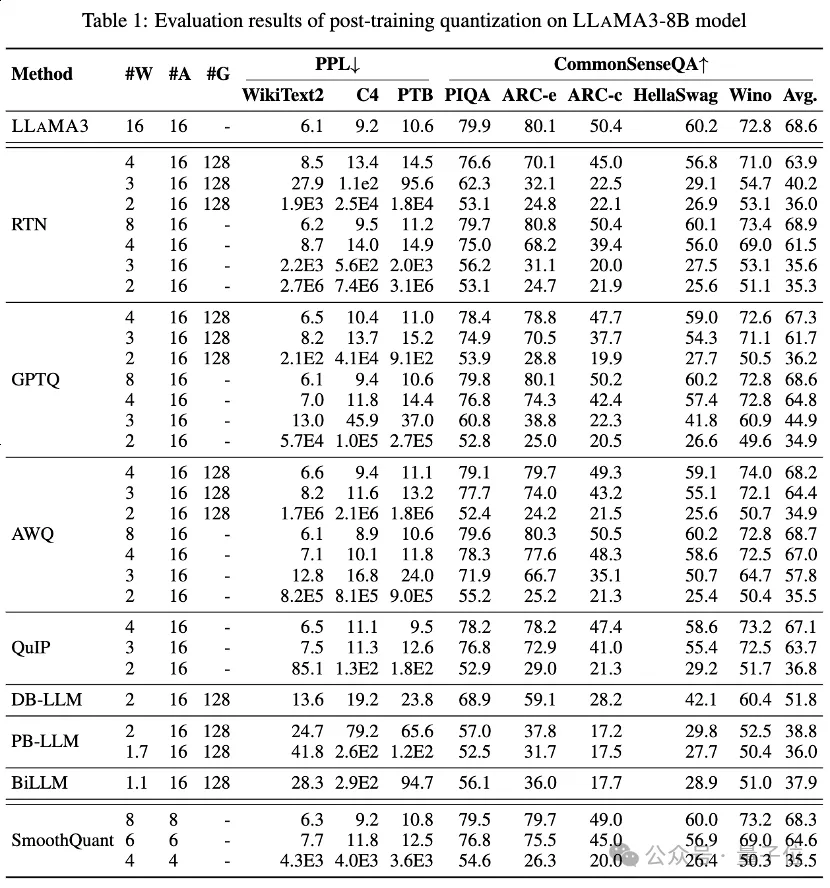
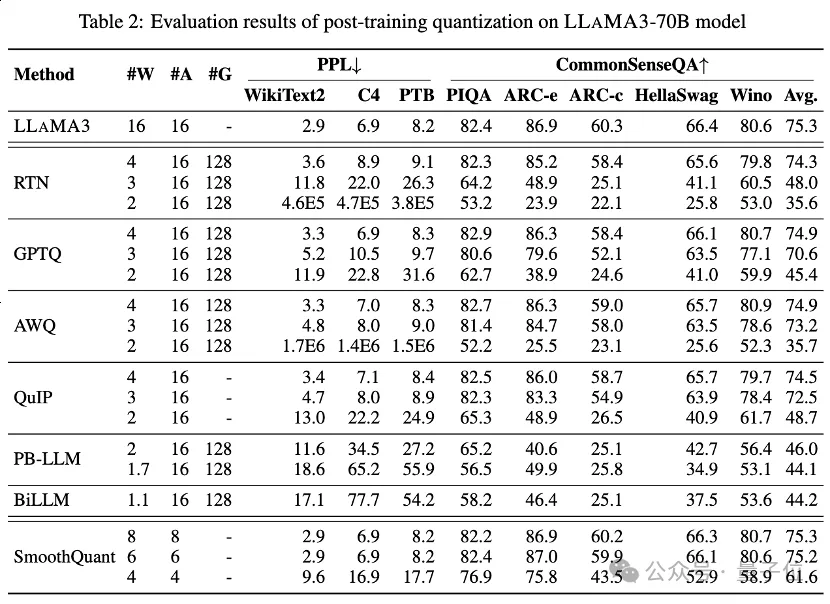
Tabelle 1 und Tabelle 2 bieten die Low-Bit-Leistung von LLaMA3-8B und LLaMA3-70B unter 8 verschiedenen PTQ-Methoden und decken einen weiten Bereich von 1 Bit bis 8 Bit Bitbreite ab.
1. Low-Bit-Privilegiengewichtung
Unter diesen ist Round-To-Nearest (RTN) eine grundlegende Rundungsquantisierungsmethode.
GPTQ ist eine der derzeit effizientesten und effektivsten Nur-Gewicht-Quantisierungsmethoden, die die Fehlerkompensation bei der Quantisierung ausnutzt. Bei 2-3 Bit führt GPTQ jedoch zu einem erheblichen Genauigkeitseinbruch bei der Quantisierung von LLaMA3.
AWQ verwendet eine Methode zur Unterdrückung abnormaler Kanäle, um die Schwierigkeit der Gewichtsquantisierung zu verringern, während QuIP durch Optimierung der Matrixberechnungen die Inkonsistenz zwischen Gewichten und Hessian sicherstellt. Sie alle behalten die Fähigkeiten von LLaMA3 bei 3 Bit bei und bringen sogar die 2-Bit-Quantisierung auf ein vielversprechendes Niveau.
2. LLM-Gewichtungskomprimierung mit extrem niedriger Bitbreite
Die kürzlich entwickelte binäre LLM-Quantisierungsmethode erreicht eine LLM-Gewichtungskomprimierung mit extrem niedriger Bitbreite.
PB-LLM verwendet eine Quantisierungsstrategie mit gemischter Genauigkeit, um die volle Präzision eines kleinen Teils wichtiger Gewichte beizubehalten und gleichzeitig die meisten Gewichte in 1 Bit zu quantisieren.
DB-LLM erreicht eine effiziente LLM-Komprimierung durch doppelte Binarisierungsgewichtsteilung und schlägt eine voreingenommene Destillationsstrategie vor, um die 2-Bit-LLM-Leistung weiter zu verbessern.
BiLLM verschiebt die LLM-Quantisierungsgrenze durch Restnäherung signifikanter Gewichte und gruppierte Quantisierung nicht signifikanter Gewichte weiter auf 1,1 Bit. Diese LLM-Quantisierungsmethoden, die speziell für extrem niedrige Bitbreiten entwickelt wurden, können eine Quantisierung mit höherer Präzision LLaMA3-8B mit ~2 Bits erreichen, die weit über Methoden wie GPTQ, AWQ und QuIP mit 2 Bits (und in einigen Fällen sogar 3 Bits) hinausgeht.
3. Low-Bit-quantisierte Aktivierungen
führten auch eine LLaMA3-Bewertung für quantisierte Aktivierungen über SmoothQuant durch, wodurch die Quantisierungsschwierigkeit von Aktivierungen auf Gewichte übertragen wird, um Aktivierungsausreißer zu glätten. Die Auswertung zeigt, dass SmoothQuant die Genauigkeit von LLaMA3 bei 8-Bit- und 6-Bit-Gewichten und -Aktivierungen beibehalten kann, bei 4-Bit jedoch einen Einbruch erleidet.
Spur 2: LoRA-Feinabstimmung der Quantisierung
Beim MMLU-Datensatz für LLaMA3-8B unter LoRA-FT-Quantisierung ist die auffälligste Beobachtung, dass die Feinabstimmung mit niedrigem Rang nicht nur beim Alpaka-Datensatz erfolgt kompensiert die Quantisierung nicht. Die eingeführten Fehler verschlimmern den Leistungsabfall noch weiter.
Konkret ist die quantisierte LLaMA3-Leistung, die durch verschiedene LoRA-FT-Quantisierungsmethoden bei 4 Bit erzielt wird, schlechter als die entsprechenden 4-Bit-Versionen ohne LoRA-FT. Dies steht in scharfem Gegensatz zu ähnlichen Phänomenen auf LLaMA1 und LLaMA2, wo die 4-Bit-Version mit niedriger, fein abgestimmter Quantisierung sogar das ursprüngliche FP16-Gegenstück auf MMLU deutlich übertrifft.
Laut intuitiver Analyse liegt der Hauptgrund für dieses Phänomen darin, dass die leistungsstarke Leistung von LLaMA3 von seinem groß angelegten Vortraining profitiert, was bedeutet, dass der Leistungsverlust nach der Quantisierung des Originalmodells nicht bei einem kleinen Satz von durchgeführt werden kann Parameterdaten mit niedrigem Rang Feinabstimmung zum Ausgleich (dies kann als Teilmenge des Originalmodells betrachtet werden).
Obwohl die durch die Quantisierung verursachte erhebliche Verschlechterung nicht durch Feinabstimmung ausgeglichen werden kann, übertrifft der 4-Bit-LoRA-FT-quantisierte LLaMA3-8B LLaMA1-7B und LLaMA2-7B bei verschiedenen Quantisierungsmethoden deutlich. Bei Verwendung der QLoRA-Methode beträgt beispielsweise die durchschnittliche Genauigkeit von 4-Bit-LLaMA3-8B 57,0 (FP16: 64,8), was die 38,4 von 4-Bit-LLaMA1-7B (FP16: 34,6) um 18,6 und die 43,9 von übersteigt 4-Bit LLaMA2-7B (FP16: 45,5) 13.1. Dies zeigt die Notwendigkeit eines neuen LoRA-FT-Quantisierungsparadigmas in der LLaMA3-Ära.
Ein ähnliches Phänomen trat beim CommonSenseQA-Benchmark auf. Die mit QLoRA und IR-QLoRA fein abgestimmte Modellleistung nahm im Vergleich zum 4-Bit-Pendant ohne LoRA-FT ebenfalls ab (z. B. 2,8 % durchschnittliche Abnahme für QLoRA gegenüber 2,4 % durchschnittliche Abnahme für IR-QLoRA). Dies zeigt weiter den Vorteil der Verwendung hochwertiger Datensätze in LLaMA3 und dass der generische Datensatz Alpaca nicht zur Leistung des Modells bei anderen Aufgaben beiträgt.
Fazit
Dieses Papier bewertet umfassend die Leistung von LLaMA3 in verschiedenen Low-Bit-Quantisierungstechniken, einschließlich Quantisierung nach dem Training und fein abgestimmter LoRA-Quantisierung.
Dieses Forschungsergebnis zeigt, dass LLaMA3 nach der Quantisierung zwar immer noch eine überlegene Leistung aufweist, der mit der Quantisierung verbundene Leistungsabfall jedoch erheblich ist und in vielen Fällen sogar zu einem größeren Rückgang führen kann.
Dieser Befund verdeutlicht die potenziellen Herausforderungen, die bei der Bereitstellung von LLaMA3 in ressourcenbeschränkten Umgebungen auftreten können, und zeigt reichlich Raum für Wachstum und Verbesserung im Zusammenhang mit der Low-Bit-Quantisierung auf. Es wird erwartet, dass nachfolgende Quantisierungsparadigmen durch die Behebung der durch die Low-Bit-Quantisierung verursachten Leistungseinbußen es LLMs ermöglichen werden, stärkere Fähigkeiten bei geringeren Rechenkosten zu erreichen und letztendlich die repräsentative generative künstliche Intelligenz auf ein neues Niveau zu heben.
Papierlink: https://arxiv.org/abs/2404.14047.
Projektlink: https://github.com/Macaronlin/LLaMA3-Quantizationhttps://huggingface.co/LLMQ.
Das obige ist der detaillierte Inhalt vonDie Low-Bit-Quantisierungsleistung von Llama 3 sinkt erheblich! Umfassende Bewertungsergebnisse finden Sie hier |. HKU & Beihang University & ETH. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- So wechseln Sie auf Github zu Chinesisch
- Auf welche Bereiche konzentriert sich Künstliche Intelligenz derzeit?
- Was sind die neuen Features der Künstlichen Intelligenz?
- So überprüfen Sie, wie das Git-Passwort lautet
- Koreanische Schöpfer starten einen groß angelegten Boykott von KI-Comics und lehnen Verstöße, Veruntreuung und illegale Kommerzialisierung ab