
Heim >Technologie-Peripheriegeräte >KI >Jenseits von BEVFormer! CR3DT: RV-Fusion hilft bei der 3D-Erkennung und -Verfolgung neuer SOTA (ETH)
Jenseits von BEVFormer! CR3DT: RV-Fusion hilft bei der 3D-Erkennung und -Verfolgung neuer SOTA (ETH)

- PHPznach vorne
- 2024-04-24 18:07:211226Durchsuche
Vorab geschrieben und nach persönlichem Verständnis des Autors
In diesem Artikel wird eine Kamera-Millimeterwellen-Radarfusionsmethode (CR3DT) für die 3D-Zielerkennung und die Verfolgung mehrerer Ziele vorgestellt. Die Lidar-basierte Methode hat in diesem Bereich einen hohen Standard gesetzt, ihre hohe Rechenleistung und ihre hohen Kosten haben jedoch die Entwicklung dieser Lösung im Bereich des autonomen Fahrens eingeschränkt Kosten Es ist relativ niedrig und hat die Aufmerksamkeit vieler Wissenschaftler auf sich gezogen, aber aufgrund seiner schlechten Ergebnisse. Daher wird die Fusion von Kameras und Millimeterwellenradar zu einer vielversprechenden Lösung. Unter dem bestehenden Kamera-Framework BEVDet führt der Autor die räumlichen und Geschwindigkeitsinformationen des Millimeterwellenradars zusammen und kombiniert sie mit dem CC-3DT++-Tracking-Kopf, um die Genauigkeit der 3D-Zielerkennung und -verfolgung erheblich zu verbessern und den Widerspruch zwischen Leistung und Kosten zu neutralisieren.
Hauptbeitrag
SensorfusionsarchitekturDer vorgeschlagene CR3DT nutzt die Zwischenfusionstechnologie vor und nach dem BEV-Encoder, um Millimeterwellen-Radardaten zu integrieren, während für die Verfolgung ein quasi-dichter Einbettungskopf verwendet wird, Target Korrelation unter Verwendung der Geschwindigkeitsschätzung vom Millimeterwellenradar.
Bewertung der Erkennungsleistung CR3DT erreichte 35,1 % mAP und 45,6 % nuScenes Detection Score (NDS) im nuScenes 3D-Erkennungsvalidierungssatz. Durch die Nutzung der umfangreichen Geschwindigkeitsinformationen, die in den Radardaten enthalten sind, wird der mittlere Geschwindigkeitsfehler (mAVE) des Detektors im Vergleich zu SOTA-Kameradetektoren um 45,3 % reduziert.
Bewertung der Tracking-Leistung CR3DT erreicht eine Tracking-Leistung von 38,1 % AMOTA auf dem nuScenes-Tracking-Validierungssatz, eine AMOTA-Verbesserung von 14,9 % im Vergleich zum Nur-Kamera-SOTA-Tracking-Modell, der expliziten Verwendung von Geschwindigkeitsinformationen im Tracker Durch weitere Verbesserungen wurde die Anzahl der IDS deutlich um etwa 43 % reduziert.
Modellarchitektur
Diese Methode basiert auf dem EV-Det-Framework, fusioniert die räumlichen und Geschwindigkeitsinformationen von RADAR und wird mit dem CC-3DT++-Tracking-Kopf kombiniert, der explizit einen verbesserten Millimeterwellen-Radar-Detektor verwendet seine Datenverknüpfung, was letztendlich die 3D-Zielerkennung und -verfolgung ermöglicht.
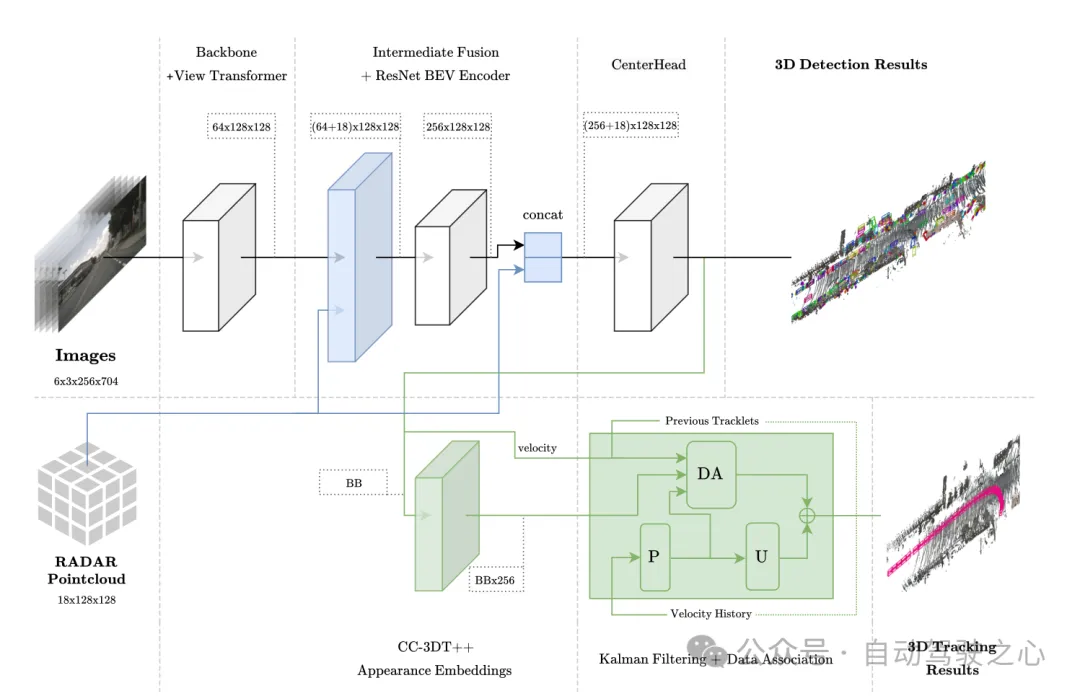 Abbildung 1 Gesamtarchitektur. Erkennung und Verfolgung werden in Hellblau bzw. Grün hervorgehoben.
Abbildung 1 Gesamtarchitektur. Erkennung und Verfolgung werden in Hellblau bzw. Grün hervorgehoben.
Sensorfusion im BEV-Raum
Dieses Modul verwendet eine Fusionsmethode ähnlich wie PointPillars, einschließlich Aggregation und Verbindung darin. Das BEV-Raster ist auf [-51,2, 51,2] mit einer Auflösung von 0,8 eingestellt, was zu einem (128×128)-Feature-Raster führt. Projizieren Sie die Bildmerkmale direkt in den BEV-Raum. Die Anzahl der Kanäle jeder Gittereinheit beträgt 64 × 128 × 128. In ähnlicher Weise werden die 18-dimensionalen Informationen von Radar in jedem In zusammengefasst Die Gittereinheit umfasst die X-, Y- und Z-Koordinaten des Punkts, und die Radardaten werden nicht verbessert. Der Autor bestätigte, dass die Radar-Punktwolke bereits mehr Informationen enthält als die LiDAR-Punktwolke, sodass die Radar-BEV-Funktion (18×128×128) beträgt. Schließlich sind die Bild-BEV-Merkmale (64 × 128 × 128) und die Radar-BEV-Merkmale (18 × 128 × 128) direkt miteinander verbunden ((64 + 18) × 128 × 128) als Eingabe der BEV-Merkmalscodierungsschicht. In nachfolgenden Ablationsexperimenten wurde festgestellt, dass es vorteilhaft ist, der Ausgabe der BEV-Merkmalskodierungsschicht Restverbindungen mit einer Dimension von (256×128×128) hinzuzufügen, was zu einer endgültigen Eingabegröße des CenterPoint-Erkennungskopfes von ( (256+18 )×128×128).

Abbildung 2 Radar-Punktwolken-Visualisierung, aggregiert im BEV-Raum für den Fusionsbetrieb. Während des Trainingsprozesses werden eindimensionale visuelle Merkmalseinbettungsvektoren durch quasi-dichtes multivariates positives Kontrastlernen erhalten, und dann werden Erkennung und Merkmalseinbettung gleichzeitig in der Verfolgungsphase von CC-3DT verwendet. Der Datenassoziationsschritt (DA-Modul in Abbildung 1) wurde geändert, um die verbesserte CR3DT-Positionserkennung und Geschwindigkeitsschätzung zu nutzen. Die Details sind wie folgt:
Experimente und Ergebnisse
 wurden auf der Grundlage des nuScenes-Datensatzes durchgeführt und bei allen Schulungen wurde kein CBGS verwendet.
wurden auf der Grundlage des nuScenes-Datensatzes durchgeführt und bei allen Schulungen wurde kein CBGS verwendet.
Eingeschränktes Modell
Da der Autor das gesamte Modell auf einem Computer mit einer 3090-Grafikkarte durchgeführt hat, wird es als eingeschränktes Modell bezeichnet. Der Zielerkennungsteil des Modells verwendet BEVDet als Erkennungsbasislinie, das Bildcodierungs-Backbone ist ResNet50 und die Bildeingabe ist auf (3×256×704) eingestellt. Bildinformationen aus der Vergangenheit oder Zukunft werden im Modell nicht verwendet Die Batchgröße ist auf 8 eingestellt. Um die Spärlichkeit der Radardaten zu verringern, werden fünf Scans zur Verbesserung der Daten verwendet. Im Fusionsmodell werden keine zusätzlichen zeitlichen Informationen verwendet.
Verwenden Sie zur Zielerkennung die Scores von mAP, NDS und mAVE zur Auswertung; zur Verfolgung verwenden Sie AMOTA, AMOTP und IDS zur Auswertung. Objekterkennungsergebnisse

Tabelle 1 Erkennungsergebnisse im nuScenes-Validierungssatz
Tabelle 1 zeigt die Erkennungsleistung von CR3DT im Vergleich zur Basisarchitektur BEVDet (R50), die nur Kameras verwendet. Es ist offensichtlich, dass die Hinzufügung von Radar die Erkennungsleistung erheblich verbessert. Unter den Einschränkungen einer geringen Auflösung und eines geringen Zeitrahmens erreicht CR3DT erfolgreich eine Verbesserung des mAP um 5,3 % und eine NDS-Verbesserung von 7,7 % im Vergleich zum reinen Kamera-BEVDet. Aufgrund der begrenzten Rechenleistung konnte das Papier jedoch keine experimentellen Ergebnisse mit hoher Auflösung, Zusammenführung von Zeitinformationen usw. erzielen. Darüber hinaus ist in der letzten Spalte von Tabelle 1 auch die Inferenzzeit angegeben.
Tabelle 2 Ablationsexperiment des Erkennungsrahmens
In Tabelle 2 wird der Einfluss verschiedener Fusionsarchitekturen auf Erkennungsindikatoren verglichen. Die Fusionsmethoden sind hier in zwei Typen unterteilt: Der erste wird im Artikel erwähnt, der auf die z-dimensionale Voxelisierung und die anschließende 3D-Faltung verzichtet und die verbesserten Bildmerkmale und reinen RADAR-Daten direkt in Spalten aggregiert und so die bekannte Merkmalsgröße erhält ist ((64+18)×128×128); die andere besteht darin, die verbesserten Bildmerkmale und reinen RADAR-Daten in einen Würfel mit einer Größe von 0,8×0,8×0,8 m zu voxeln, um alternative Merkmale zu erhalten. Die Größe ist ((64+ 18) × 10 × 128 × 128), daher muss das BEV-Kompressormodul in Form einer 3D-Faltung verwendet werden. Wie aus Tabelle 2(a) ersichtlich ist, führt eine Erhöhung der Anzahl der BEV-Kompressoren zu einem Leistungsabfall, und es ist ersichtlich, dass die erste Lösung eine bessere Leistung erbringt. Aus Tabelle 2(b) ist auch ersichtlich, dass das Hinzufügen des Restblocks von Radardaten auch die Leistung verbessern kann, was auch bestätigt, was in der vorherigen Modellarchitektur erwähnt wurde. Das Hinzufügen von Restverbindungen zur Ausgabe der BEV-Feature-Codierungsschicht ist von Vorteil .
Tabelle 3 Tracking-Ergebnisse für den nuScenes-Validierungssatz basierend auf verschiedenen Konfigurationen von BEVDet und CR3DT.
Tabelle 3 zeigt die Tracking-Ergebnisse des verbesserten CC3DT++-Tracking-Modells für den nuScenes-Validierungssatz die Basislinie und die Leistung des CR3DT-Erkennungsmodells. Das CR3DT-Modell verbessert die Leistung von AMOTA um 14,9 % gegenüber dem Ausgangswert und verringert sie um 0,11 m bei AMOTP. Darüber hinaus ist zu erkennen, dass das IDS im Vergleich zum Ausgangswert um ca. 43 % reduziert ist.
Tabelle 4 Tracking-Architektur-Ablationsexperimente, die am CR3DT-Erkennungs-Backbone durchgeführt wurden
Schlussfolgerung
Diese Arbeit schlägt ein effizientes Kamera-Radar-Fusionsmodell vor – CR3DT, speziell für die 3D-Objekterkennung und die Verfolgung mehrerer Objekte. Durch die Zusammenführung von Radardaten in die reine Kamera-BEVDet-Architektur und die Einführung der CC-3DT++-Tracking-Architektur hat CR3DT die Genauigkeit der 3D-Zielerkennung und -verfolgung erheblich verbessert, wobei mAP und AMOTA um 5,35 % bzw. 14,9 % gestiegen sind.
Die Lösung der Integration von Kamera und Millimeterwellenradar hat den Vorteil geringerer Kosten im Vergleich zu reinem LiDAR oder der Lösung der Integration von LiDAR und Kamera und kommt der aktuellen Entwicklung autonomer Fahrzeuge nahe. Darüber hinaus hat Millimeterwellenradar den Vorteil, dass es bei schlechtem Wetter robust ist und eine Vielzahl von Anwendungsszenarien bewältigen kann. Das derzeitige große Problem ist die Spärlichkeit von Millimeterwellenradar-Punktwolken und die Unfähigkeit, Höheninformationen zu erkennen. Ich glaube jedoch, dass die zukünftige Integration von Kameras und Millimeterwellenradarlösungen mit der kontinuierlichen Weiterentwicklung des 4D-Millimeterwellenradars ein höheres Niveau erreichen und noch bessere Ergebnisse erzielen wird!
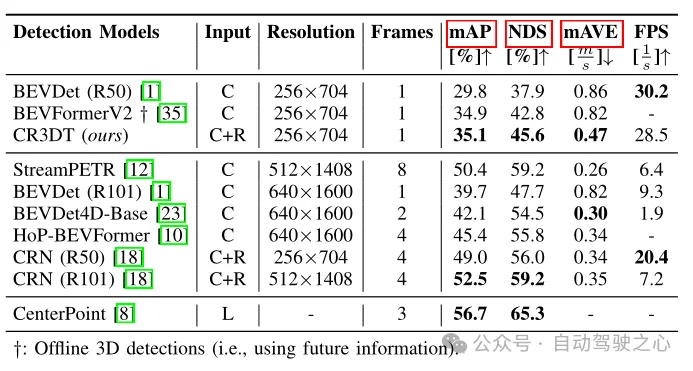
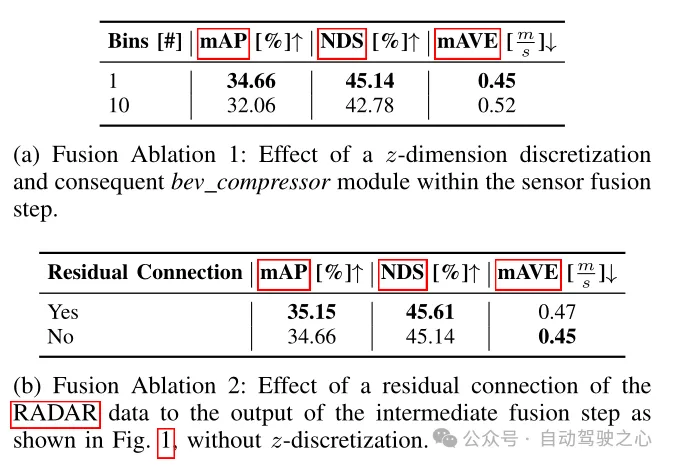
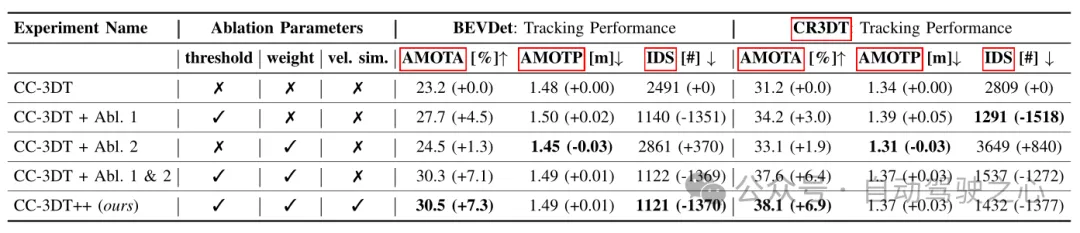 Tabelle 3 Tracking-Ergebnisse für den nuScenes-Validierungssatz basierend auf verschiedenen Konfigurationen von BEVDet und CR3DT.
Tabelle 3 Tracking-Ergebnisse für den nuScenes-Validierungssatz basierend auf verschiedenen Konfigurationen von BEVDet und CR3DT. 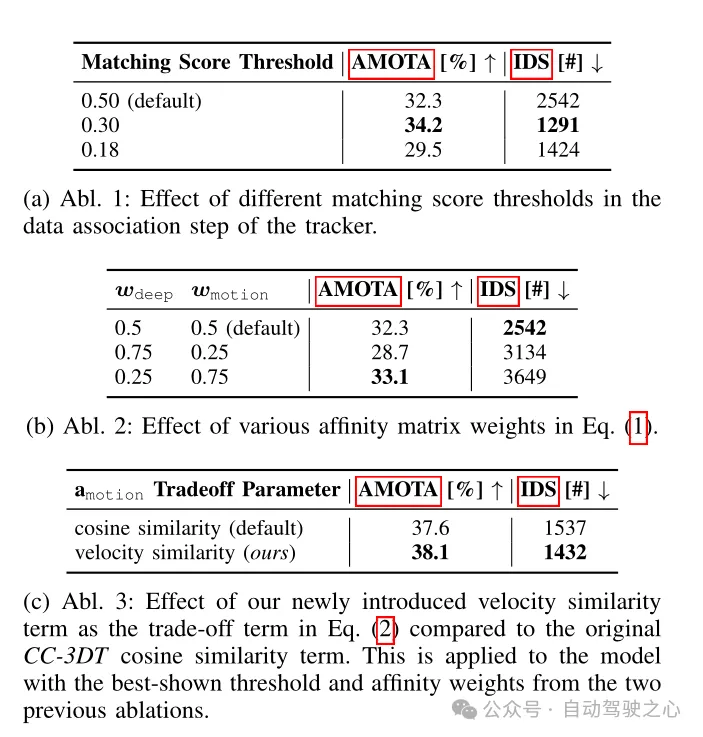

Das obige ist der detaillierte Inhalt vonJenseits von BEVFormer! CR3DT: RV-Fusion hilft bei der 3D-Erkennung und -Verfolgung neuer SOTA (ETH). Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- In einem Artikel geht es um das Problem der Zeitstempelsynchronisierung bei der Lidar- und Kamerakalibrierung
- Neue Spionagefotos des Xpeng P5 enthüllt: Äußeres und Inneres erneuert, Radarkonfiguration kann angepasst werden
- Hesai Technology arbeitet mit der FAW Group zusammen, um die erste globale Lidar-Lösung für intelligentes Fahren zu entwickeln
- Hesai Technology stellt einen Branchenrekord auf: Die Lieferung von 50.000 fahrzeugmontierten Lidars in einem einzigen Monat weist den Weg zu neuen Höhen
- Der neue Allrad-Pickup „Radar Horizon' von Radar Automotive steht kurz vor der Markteinführung und beschleunigt von 0 auf 0-60 Sekunden in 4 Sekunden