
Heim >Technologie-Peripheriegeräte >KI >Gedanken und Praxis zur unterstützten Generierung von B-End-Frontend-Code unter großen Modellen
Gedanken und Praxis zur unterstützten Generierung von B-End-Frontend-Code unter großen Modellen

- PHPznach vorne
- 2024-04-18 09:30:151302Durchsuche
1. Hintergrund
Während der Refactoring-Arbeit, Codespezifikationen: Während des B-End-Frontend-Entwicklungsprozesses werden Entwickler immer mit dem Problem konfrontiert, dass die Elementmodule vieler CRUD-Seiten grundsätzlich ähnlich sind Da der Zeitaufwand für die einfache Elementkonstruktion immer noch manuell entwickelt werden muss, verringert sich die Entwicklungseffizienz der Geschäftsanforderungen. Da die Codierungsstile verschiedener Entwickler gleichzeitig inkonsistent sind, wird der Einstieg für andere während der Iteration teurer.
KI ersetzt einfache Gehirnleistung: Durch die kontinuierliche Weiterentwicklung großer KI-Modelle verfügt sie bereits über einfache Verständnisfähigkeiten und kann Sprache in Anweisungen umwandeln. Allgemeine Anweisungen zum Erstellen grundlegender Seiten können den Anforderungen des täglichen grundlegenden Seitenaufbaus gerecht werden und die Effizienz der Geschäftsentwicklung in allgemeinen Szenarien verbessern.
2. Übersicht über generierte Links
B-Seitenlisten, Formulare und Details zur gesamten Support-Generierung können grob in die folgenden Schritte unterteilt werden.
 Bilder
Bilder
- Natürliche Eingabesprache
- Kombiniert mit dem großen Modell, um die entsprechenden Konstruktionsinformationen gemäß den angegebenen Regeln zu extrahieren
- Gebäudeinformationen werden mit der Codevorlage und AST kombiniert, um den Front-End-Code auszugeben
Drei. Express-Anforderungen
Grafisch Der erste Schritt bei der Konfiguration
besteht darin, ihm mitzuteilen, welche Art von Schnittstelle entwickelt werden soll. Dabei denken wir zunächst an die Seitenkonfiguration, die derzeit gängige Form von Low-Code-Produkten. Benutzer erstellen Seiten über eine Reihe grafischer Konfigurationen, wie unten gezeigt:
 Bilder
Bilder
Zielt auf allgemeine Szenarien (z. B. Es hat einen guten Effekt auf die Verbesserung der Effizienz von CURD-Seiten mit relativ einfacher Hintergrundverwaltung) oder spezifische Geschäftsszenarien (z. B. den Bau von Veranstaltungsorten). Bei relativ komplexen Anforderungen, die eine kontinuierliche Iteration der Logik erfordern, sind die Anforderungen an das interaktive Design höher, da die Konfiguration über grafische Vorgänge erfolgt und gleichzeitig mit zunehmender Komplexität der Anforderungen ein gewisser Kostenaufwand verbunden ist Je höher die Konfiguration, desto komplexer werden die Formularinteraktionen und die Wartungskosten werden immer höher. Daher ist die Verwendung von Frontend-Feldern in der Seitenkonfiguration relativ zurückhaltend.
KI generiert direkt Code
KI-generierter Code wird häufiger in Werkzeugfunktionsszenarien verwendet, aber für die Anforderungen spezifischer Geschäftsszenarien innerhalb des Unternehmens müssen möglicherweise die folgenden Punkte berücksichtigt werden:
- Generierungsanpassung : Firmenteam Es verfügt über einen eigenen Technologie-Stack und leistungsstarke allgemeine Komponenten, und dieses Wissen muss vorab trainiert werden. Derzeit wird für Langtext-Pre-Training-Inhalte nur die Einzelsitzungsinjektion unterstützt, und der Token-Verbrauch ist vorhanden hoch;
- Genauigkeit: Die Genauigkeit des von der KI generierten Codes ist relativ groß. Darüber hinaus enthält das Vortraining einen großen Teil der Eingabeaufforderungen, da der Code zu viele Details und Modellillusionen aufweist Die Rate des Geschäftscodes ist derzeit relativ hoch und die Genauigkeit ist eine Frage der Hilfscodierung. Wenn dies nicht gelöst werden kann, wird der Hilfscodierungseffekt stark reduziert.
- Unvollständiger generierter Inhalt: Aufgrund der Einschränkungen einer einzelnen GPT-Sitzung Bei komplexen Anforderungen besteht eine gewisse Wahrscheinlichkeit, dass die Codegenerierung abgeschnitten wird, was sich auf die Erfolgsquote der Generierung auswirkt.
Natürliche Sprache für Anweisungen
GPT hat tatsächlich eine sehr wichtige Fähigkeit, nämlich natürliche Sprache für Anweisungen, Anweisungen sind Aktionen. Zum Beispiel gehen wir davon aus, dass eine Funktionsmethode implementiert ist und die Eingabe natürlich ist Können wir durch die Kombination von GPT mit der integrierten Eingabeaufforderung, die eine stabile Ausgabe bestimmter Wörter ermöglicht, durch die Ausgabe dieser Wörter weitere Maßnahmen ergreifen? Dies hat gegenüber der grafischen Konfiguration folgende Vorteile:
- Geringe Lernschwelle: Da die natürliche Sprache selbst die Muttersprache des Menschen ist, müssen Sie die Seite nur nach Ihren Vorstellungen beschreiben. Natürlich muss der Inhalt der Beschreibung so sein Befolgen Sie einige Spezifikationen. Ja, aber die Effizienz ist im Vergleich zur grafischen Konfiguration erheblich verbessert.
- Komplexitäts-Blackbox: Die Komplexität der grafischen Konfiguration nimmt mit zunehmender Komplexität der Konfigurationsseite zu und diese Komplexität wird auf einen Blick angezeigt Bei vielen Benutzern verlieren sich Benutzer möglicherweise in komplexen Interaktionen mit Konfigurationsseiten, und die Konfigurationskosten steigen allmählich an einige Eingabeaufforderungen, aber die grafische Konfiguration erfordert die Entwicklung komplexer Formulare, um eine schnelle Eingabe zu ermöglichen.
- Möglicherweise haben Sie hier eine Frage:
Würden die generierten Befehlsinformationen nicht auch die Illusion eines großen Modells zeigen? Wie kann sichergestellt werden, dass die jedes Mal generierten Befehlsinformationen stabil und konsistent sind?
Die Übersetzung natürlicher Sprache in Anweisungen ist aus folgenden Gründen möglich:
- Das Konvertieren von Langtext in Schlüsselinformationen gehört zu den zusammenfassenden Inhalten. Die Genauigkeit großer Modelle ist in Diffusionsszenarien viel höher.
- Da die Anweisungsinformationen nur die Schlüsselinformationen in den Anforderungen extrahieren, besteht keine Notwendigkeit Führen Sie eine Schulung zum Code-Technologie-Stack durch, sodass durch die Optimierung und Verbesserung des Eingabeaufforderungsinhalts die Genauigkeit der Ausgabe effektiv verbessert werden kann Ausdrucksanforderungen kann die Genauigkeit durch eine einzelne Testvorhersageausgabe überprüft werden. Wenn ein badCase auftritt, greifen wir nach der Optimierung auf den einzelnen Test für den badCase zu. Stellen Sie sicher, dass sich die Genauigkeit weiter verbessert.
- Sehen wir uns die endgültigen Ergebnisse der Informationskonvertierung an:
Zur Codeunterstützung können solche Informationen basierend auf der Anforderungsbeschreibung des Benutzers durch PROMPT-Verarbeitung abgerufen werden. Geben Sie grundlegende Informationen für die Codegenerierung an.
Bilder  4. Informationen in Code umwandeln
4. Informationen in Code umwandeln
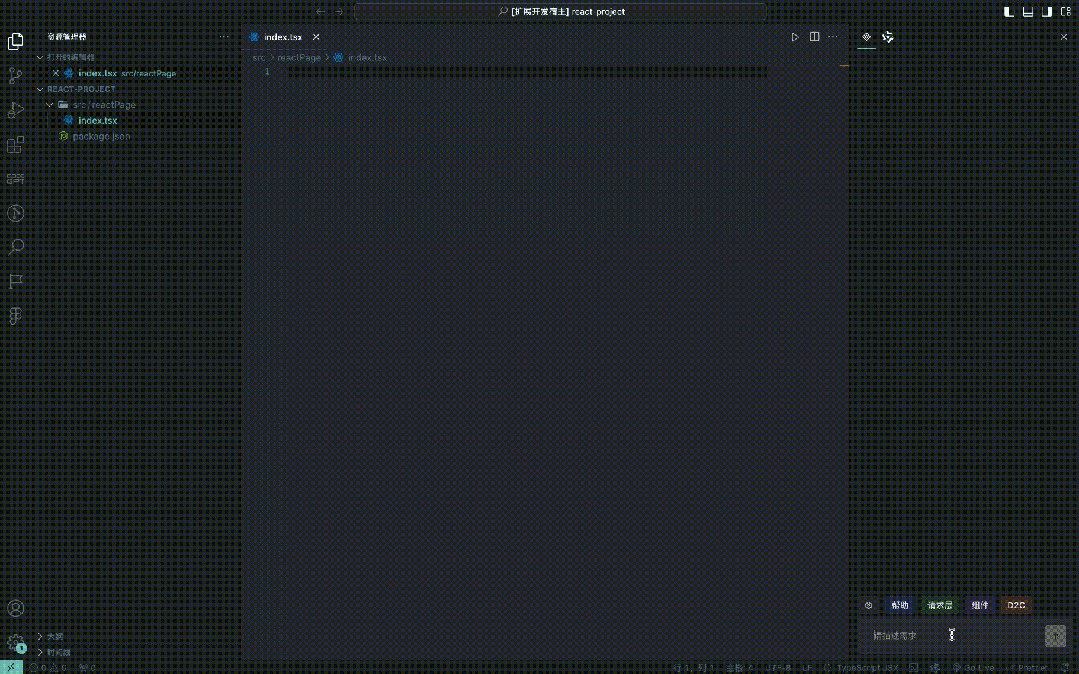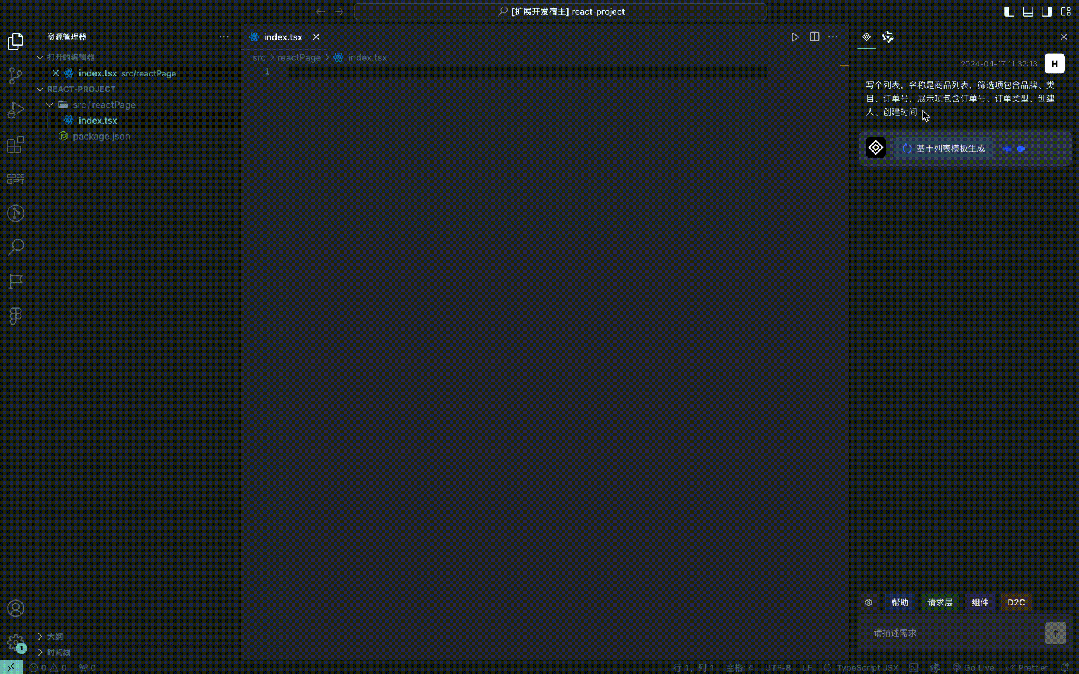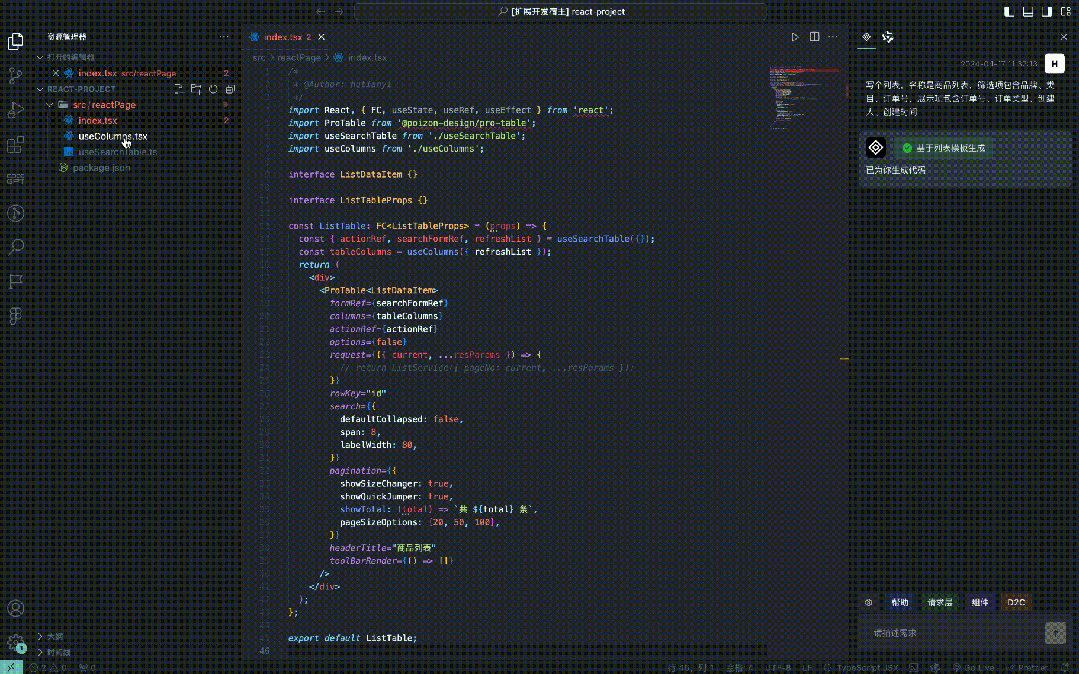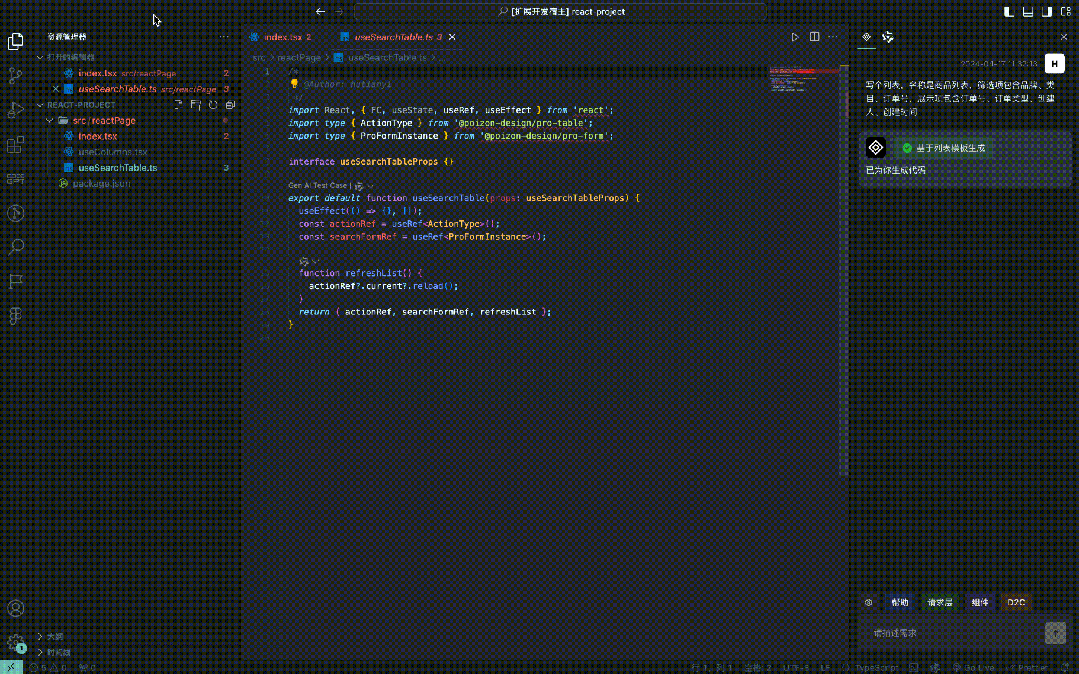
Nachdem wir die codierbaren Informationen, die der natürlichen Sprache entsprechen, über das große Modell (im obigen Beispiel JSON) erhalten haben, können wir den Code basierend auf diesen Informationen konvertieren. Für eine Seite mit einem klaren Szenario kann diese im Allgemeinen in Hauptcodevorlage (Liste, Formular, Beschreibungsrahmen) + Geschäftskomponenten unterteilt werden.
Konvertierungsprozess
Bilder
Wie entwickeln wir Code?
Tatsächlich ist dieser Schritt der Entwicklung des Codes selbst sehr ähnlich. Nachdem wir die Anforderungen erhalten haben, extrahiert unser Gehirn die Schlüsselinformationen, dh die oben erwähnten Anweisungen zur Konvertierung natürlicher Sprache, und erstellt dann eine Datei in vscode und dann Die folgenden Vorgänge werden ausgeführt:
Zuerst müssen Sie eine Codevorlage erstellen und dann entsprechend dem Szenario entsprechende Hochleistungskomponenten einführen. Beispielsweise wird ProTable für Listen und ProForm eingeführt Formen.
Basiert auf leistungsstarken Komponenten wie ProTable und fügt einige Eigenschaften hinzu, z. B. headerTitle, pageSize und andere listenbezogene Informationen.
Führen Sie Komponenten basierend auf der Bedarfsbeschreibung ein. Wenn beispielsweise erkannt wird, dass im Filterelement eine Kategorieauswahl vorhanden ist, wird eine neue Geschäftskomponente in useColumns hinzugefügt In der Bedarfsbeschreibung wird an der angegebenen Stelle auf der Seite eine neue Import- und Exportgeschäftskomponente hinzugefügt.
Holen Sie sich den Scheinlink, fügen Sie eine Anforderungsebene hinzu und fügen Sie sie an der angegebenen Stelle auf der Seite ein.
Die oben genannten gängigen Szenarios zum Einfügen von Code können in JSON gekapselt werden. Anschließend wird der entsprechende Code durch Codevorlagen in Kombination mit AST-Einfügung oder Ersetzen von Zeichenfolgenvorlagen generiert.
5. Die Quellcode-Generierung
Die Quellcode-Unterstützung hilft Entwicklern hauptsächlich, sich wiederholende Arbeiten zu reduzieren und die Codierungseffizienz zu verbessern Spezifische Szenarien Die Seite ist vollständig und die Anzahl der Seitenfunktionen ist aufzählbar. Es gibt auch hervorragende Praktiken in der Low-Code-Konstruktion. Das Quellcode-Hilfstool soll Benutzern dabei helfen, so viel Geschäftsanforderungscode wie möglich zu initialisieren. Anschließende Änderungen und Wartung werden den Benutzern auf Codeebene übergeben, um die Entwicklungseffizienz neuer Seiten zu verbessern.
Sehen Sie sich die spezifische funktionale Architektur unten an:
Bilder
6. Suche und Einbettung von Komponentenvektoren Bei der Front-End-Entwicklung besteht der Kern der Effizienzsteigerung darin, weniger Code zu entwickeln, und eine schnellere Seitengenerierung ist ein Aspekt Eine gute Komponentenextraktion ist ein sehr wichtiger Bestandteil, um die Einführungsverknüpfungen von Komponenten zu optimieren und Komponenten schnell in Initialisierungsvorlagen und Bestandscodes zu suchen. Link zur Einführung von Komponentenvektoren
Bei der Front-End-Entwicklung besteht der Kern der Effizienzsteigerung darin, weniger Code zu entwickeln, und eine schnellere Seitengenerierung ist ein Aspekt Eine gute Komponentenextraktion ist ein sehr wichtiger Bestandteil, um die Einführungsverknüpfungen von Komponenten zu optimieren und Komponenten schnell in Initialisierungsvorlagen und Bestandscodes zu suchen. Link zur Einführung von Komponentenvektoren
Bilder
 Eingabe von Komponenteninformationen
Eingabe von Komponenteninformationen
Unterstützt den schnellen Zugriff auf Komponentenbeschreibungsinhalte und Komponenteneinführungsparadigmen, die Eingabe von Komponenten mit einem Klick und die Komponentenbeschreibung wird in konvertiert Vektordaten zur Speicherung Vektordatenbank.
Bilder
 Komponentenvektorsuche
Komponentenvektorsuche
Nachdem der Benutzer die Beschreibung eingegeben hat, wird die Beschreibung in einen Vektor umgewandelt und mit der Komponentenliste basierend auf der Kosinusähnlichkeit verglichen, um die TOP N-Komponenten mit dem zu finden höchste Ähnlichkeit.
Bilder
 Schnelles Einfügen von Komponenten
Schnelles Einfügen von Komponenten
Benutzer können über die Beschreibung schnell nach der Komponente mit dem höchsten Übereinstimmungsgrad im Lagercode suchen und zum Einfügen die Eingabetaste drücken.
 Bilder
Bilder
VII. Komponenteneinbettungsvorlagen: Derzeit unterstützen Komponenten die Vektorsuche, die durch die Kombination von Quellcodeseiten generiert wird, und unterstützen dynamische Matching-Komponenten und Einbettungsvorlagen.
- Bearbeiten und Generieren von Aktiencode: Derzeit nur unterstützt Die Quellcodegenerierung neuer Seiten wird in Zukunft unterstützt, und das teilweise Hinzufügen von Code zu vorhandenen Seiten wird in Zukunft unterstützt.
- Codevorlagen-Pipeline: Die Codeoperationstools von AST verbinden natürliche Sprache und Codeschreiben weiter und verbessern so die Effizienz der Szenenerweiterung.
Das obige ist der detaillierte Inhalt vonGedanken und Praxis zur unterstützten Generierung von B-End-Frontend-Code unter großen Modellen. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!