
Heim >Technologie-Peripheriegeräte >KI >KI unterstützt die Forschung an Gehirn-Computer-Schnittstellen, die bahnbrechende neuronale Sprachdekodierungstechnologie der New York University, veröffentlicht in der Unterzeitschrift „Nature'.
KI unterstützt die Forschung an Gehirn-Computer-Schnittstellen, die bahnbrechende neuronale Sprachdekodierungstechnologie der New York University, veröffentlicht in der Unterzeitschrift „Nature'.

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2024-04-17 08:40:051349Durchsuche

Autor |. Chen Xupeng
In den letzten Jahren hat die rasante Entwicklung des Deep Learning und der Brain-Computer-Interface-Technologie (BCI) die Möglichkeit eröffnet, Neurosprachprothesen zu entwickeln, die aphasischen Menschen bei der Kommunikation helfen können. Die Sprachdekodierung neuronaler Signale steht jedoch vor Herausforderungen.
Kürzlich haben Forscher von VideoLab und Flinker Lab an der Universität von Jordanien einen neuen Typ eines differenzierbaren Sprachsynthesizers entwickelt, der ein leichtes Faltungs-Neuronales Netzwerk verwenden kann, um Sprache in eine Reihe interpretierbarer Sprachparameter (wie Tonhöhe, Lautstärke, Formant) zu kodieren Frequenz usw.) und diese Parameter werden über ein differenzierbares neuronales Netzwerk in Sprache synthetisiert. Dieser Synthesizer kann auch Sprachparameter (wie Tonhöhe, Lautstärke, Formantenfrequenzen usw.) über ein leichtes Faltungs-Neuronales Netzwerk analysieren und Sprache über einen differenzierbaren Sprachsynthesizer neu synthetisieren.
Die Forscher haben ein System zur Decodierung neuronaler Signale entwickelt, das gut interpretierbar und auf Situationen mit kleinen Datenmengen anwendbar ist, indem neuronale Signale diesen Sprachparametern zugeordnet werden, ohne die Bedeutung des ursprünglichen Inhalts zu ändern.
Die Forschung trug den Titel „
Ein neuronales Sprachdekodierungs-Framework, das Deep Learning und Sprachsynthese nutzt“ und wurde am 8. April 2024 in der Zeitschrift „Nature Machine Intelligence“ veröffentlicht.
 Link zum Papier:
Link zum Papier:
Forschungshintergrund
Die meisten Versuche, Decoder für neuronale Sprache zu entwickeln, basieren auf einem A-Special Art der Daten: Daten von Patienten, die sich einer Epilepsieoperation unterzogen, mittels Elektrokortikographie (ECoG)-Aufzeichnungen. Mithilfe von Elektroden, die Patienten mit Epilepsie implantiert werden, um während der Sprachproduktion Daten aus der Großhirnrinde zu sammeln, haben diese Daten eine hohe räumlich-zeitliche Auflösung und haben Forschern dabei geholfen, eine Reihe bemerkenswerter Ergebnisse auf dem Gebiet der Sprachdekodierung zu erzielen und so die Entwicklung von Gehirn-Computer-Schnittstellen voranzutreiben Feld.
Die Sprachdekodierung neuronaler Signale steht vor zwei großen Herausforderungen.
Erstens sind die Daten, die zum Trainieren personalisierter neuronaler Sprachdekodierungsmodelle verwendet werden, zeitlich sehr begrenzt, normalerweise nur etwa zehn Minuten, während Deep-Learning-Modelle oft eine große Menge an Trainingsdaten benötigen, um zu fahren.
Zweitens ist die menschliche Aussprache sehr unterschiedlich. Selbst wenn dieselbe Person wiederholt dasselbe Wort spricht, ändern sich die Sprechgeschwindigkeit, die Intonation und die Tonhöhe, was den vom Modell erstellten Darstellungsraum komplexer macht.
Frühe Versuche, neuronale Signale in Sprache zu dekodieren, stützten sich hauptsächlich auf lineare Modelle. Die Modelle erforderten normalerweise keine großen Trainingsdatensätze und waren gut interpretierbar, aber die Genauigkeit war sehr gering.
Neuere Forschungen, die auf tiefen neuronalen Netzen basieren, insbesondere die Verwendung von Faltungs- und wiederkehrenden neuronalen Netzarchitekturen, werden in zwei Schlüsseldimensionen entwickelt: der latenten Zwischendarstellung simulierter Sprache und der Qualität synthetisierter Sprache. Beispielsweise gibt es Studien, die die Aktivität der Großhirnrinde in Mundbewegungsräume dekodieren und diese dann in Sprache umwandeln. Obwohl die Dekodierungsleistung leistungsstark ist, klingt die rekonstruierte Stimme unnatürlich.
Andererseits rekonstruieren einige Methoden erfolgreich natürlich klingende Sprache mithilfe von Wavenet-Vocoder, Generative Adversarial Network (GAN) usw., ihre Genauigkeit ist jedoch begrenzt. Kürzlich wurden in einer Studie an Patienten mit implantierten Geräten sowohl genaue als auch natürliche Sprachwellenformen erzielt, indem quantisierte HuBERT-Merkmale als Zwischendarstellungsraum und ein vortrainierter Sprachsynthesizer zur Umwandlung dieser Merkmale in Sprache verwendet wurden.
Allerdings können die HuBERT-Funktionen keine sprecherspezifischen akustischen Informationen darstellen und nur feste und einheitliche Sprechertöne erzeugen. Daher sind zusätzliche Modelle erforderlich, um diesen universellen Klang in die Stimme eines bestimmten Patienten umzuwandeln. Darüber hinaus wurde in dieser Studie und den meisten früheren Versuchen eine nicht-kausale Architektur verwendet, was ihre Verwendung in praktischen Anwendungen von Gehirn-Computer-Schnittstellen, die zeitliche kausale Operationen erfordern, möglicherweise einschränkt.
Hauptmodellrahmen
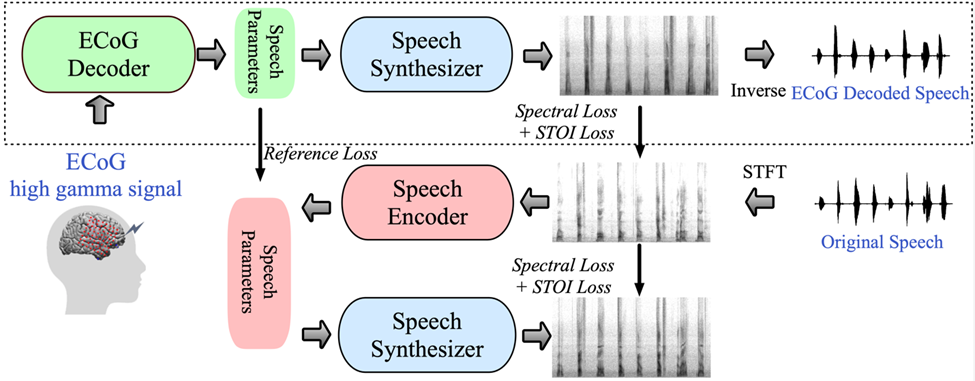 Abbildung 1: Vorgeschlagener Rahmen für die neuronale Sprachdekodierung. (Quelle: Papier)
Abbildung 1: Vorgeschlagener Rahmen für die neuronale Sprachdekodierung. (Quelle: Papier)
Das von der Forschung vorgeschlagene Framework besteht aus zwei Teilen: Der eine ist der ECoG-Decoder, der das ECoG-Signal in akustische Sprachparameter umwandelt, die wir verstehen können (wie Tonhöhe, ob es ausgesprochen wird, Lautstärke und Formantenfrequenz usw.). ); der andere Teil ist ein Sprachsynthesizer, der diese Sprachparameter in ein Spektrogramm umwandelt.
Die Forscher haben einen differenzierbaren Sprachsynthesizer entwickelt, der es dem Sprachsynthesizer ermöglicht, während des Trainings des ECoG-Decoders auch am Training teilzunehmen und gemeinsam zu optimieren, um den Fehler bei der Spektrogrammrekonstruktion zu reduzieren. Dieser niedrigdimensionale latente Raum verfügt über eine starke Interpretierbarkeit, gepaart mit einem leichten vorab trainierten Sprachkodierer zur Generierung von Referenz-Sprachparametern, was Forschern hilft, ein effizientes neuronales Sprachdekodierungs-Framework aufzubauen und das Problem der Datenknappheit zu überwinden.
Dieses Framework kann natürliche Sprache erzeugen, die der eigenen Stimme des Sprechers sehr nahe kommt, und der ECoG-Decoder-Teil kann in verschiedene Deep-Learning-Modellarchitekturen eingebunden werden und unterstützt auch kausale Operationen. Die Forscher sammelten und verarbeiteten ECoG-Daten von 48 neurochirurgischen Patienten und verwendeten dabei mehrere Deep-Learning-Architekturen (einschließlich Faltung, rekurrentes neuronales Netzwerk und Transformer) als ECoG-Decoder.
Das Framework hat bei verschiedenen Modellen eine hohe Genauigkeit bewiesen, wobei die Faltungsarchitektur (ResNet) die beste Leistung erzielte, wobei der Pearson-Korrelationskoeffizient (PCC) zwischen dem ursprünglichen und dem dekodierten Spektrogramm 0,806 erreichte. Das von den Forschern vorgeschlagene Framework kann nur durch kausale Operationen und eine relativ niedrige Abtastrate (niedrige Dichte, 10 mm Abstand) eine hohe Genauigkeit erreichen.
Die Forscher zeigten außerdem, dass eine effektive Sprachdekodierung sowohl von der linken als auch von der rechten Gehirnhälfte aus durchgeführt werden kann, wodurch die Anwendung der neuronalen Sprachdekodierung auf die rechte Gehirnhälfte ausgeweitet wurde.
Forschungsbezogener Code Open Source: https://github.com/flinkerlab/neural_speech_decoding
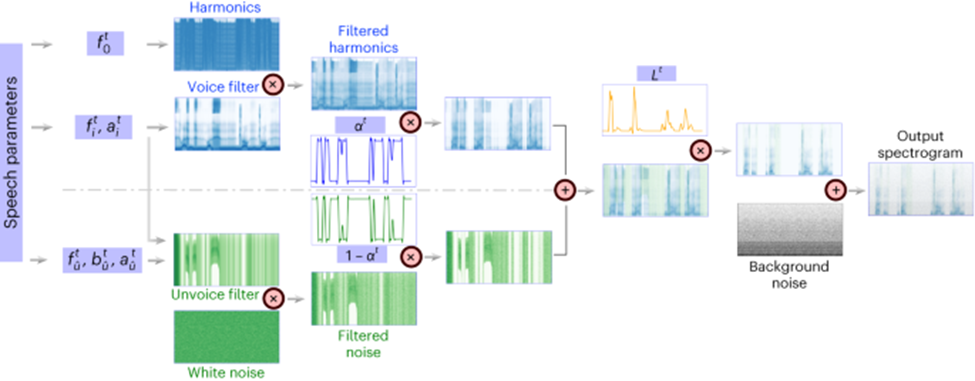
Die wichtige Innovation dieser Forschung besteht darin, einen differenzierbaren Sprachsynthesizer (Sprachsynthesizer) vorzuschlagen, der die Aufgabe der Sprachneusynthese sehr effizient macht und hochauflösende Aufkleber mit sehr kleiner Sprachanpassung synthetisieren kann Audio.
Das Prinzip des differenzierbaren Sprachsynthesizers basiert auf dem Prinzip des menschlichen generativen Systems und unterteilt die Sprache in zwei Teile: Stimme (zur Modellierung von Vokalen) und Unvoice (zur Modellierung von Konsonanten):
Der Sprachteil kann zunächst mit dem verwendet werden Basis Das Frequenzsignal erzeugt Harmonische, und der Filter, der aus den Formantenspitzen von F1-F6 besteht, wird gefiltert, um die spektralen Eigenschaften des Vokalteils zu erhalten. Der Forscher filtert das weiße Rauschen mit dem entsprechenden Filter, um das entsprechende zu erhalten Spektrum, das mit den erlernten Parametern das Mischungsverhältnis der beiden Teile zu jedem Zeitpunkt steuern kann. Anschließend wird das Lautstärkesignal verstärkt und Hintergrundgeräusche hinzugefügt, um das endgültige Sprachspektrum zu erhalten. Basierend auf diesem Sprachsynthesizer entwirft dieser Artikel ein effizientes Sprachresynthese-Framework und ein neuronales Sprachdecodierungs-Framework.
Forschungsergebnisse
Ergebnisse der Sprachdekodierung mit zeitlicher Kausalität
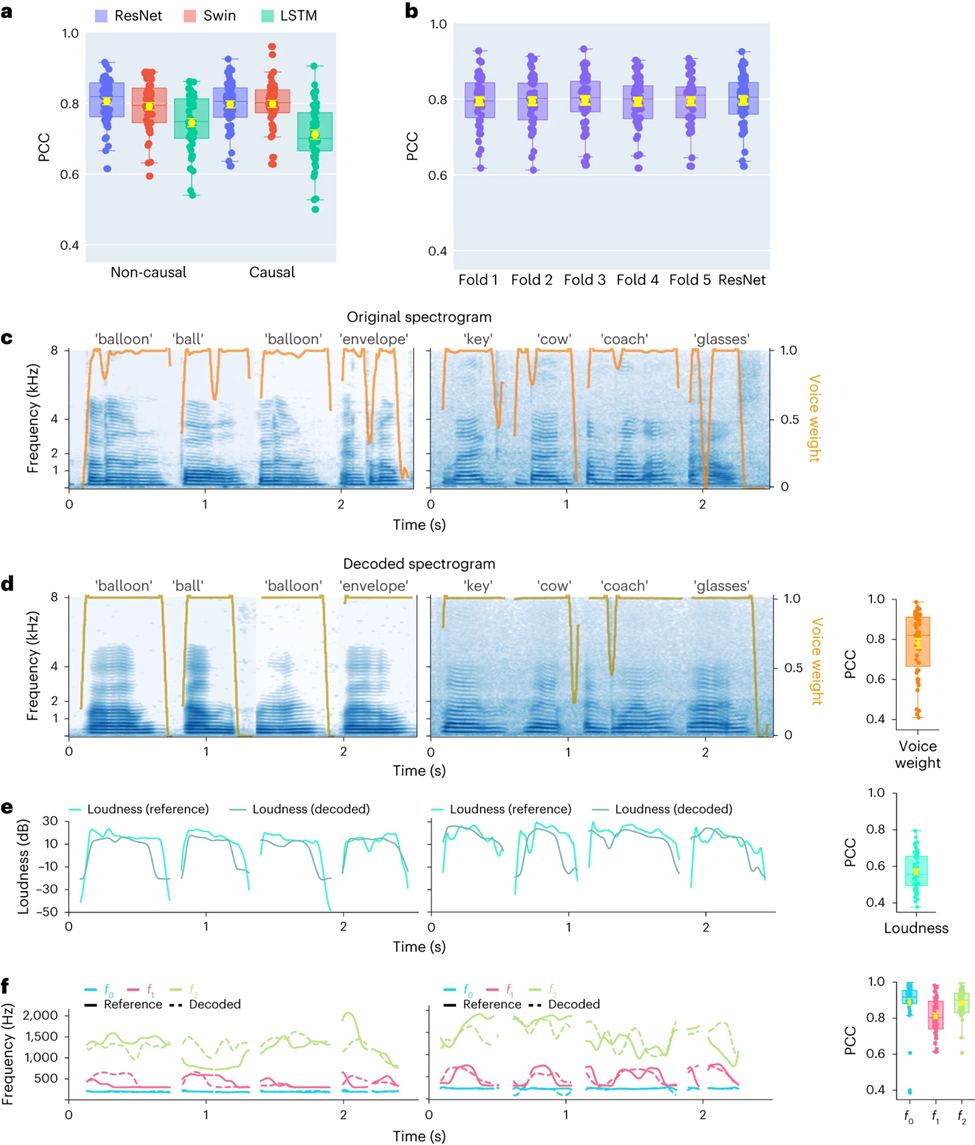
Zunächst verglichen die Forscher direkt die Unterschiede in der Sprachdekodierungsleistung verschiedener Modellarchitekturen (Convolution (ResNet), Recurrent (LSTM) und Transformer (3D Swin). Es ist erwähnenswert, dass diese Modelle keine Leistung erbringen können -kausale oder kausale Operationen auf Zeit
Die Ergebnisse zeigen, dass das ResNet-Modell unter allen Modellen den höchsten Pearson-Korrelationskoeffizienten (PCC) erreicht. Der durchschnittliche PCC für kausal und kausal beträgt 0,806 bzw. 0,797. gefolgt vom Swin-Modell (der durchschnittliche PCC für nicht-kausal und 0,798) (Abbildung 2a)
Ein ähnliches Ergebnis wurde durch die Auswertung des STOI+-Indikators erzielt Dies hat erhebliche Auswirkungen auf Brain-Computer-Interface-Anwendungen (BCI): Kausale Modelle verwenden nur vergangene und aktuelle neuronale Signale, um Sprache zu erzeugen, während akausale Modelle auch zukünftige neuronale Signale verwenden. Bei Verwendung eines nicht-kausalen Modells ist dies in Echtzeitanwendungen nicht möglich Daher konzentrierten sich die Forscher auf den Vergleich der Leistung desselben Modells bei der Durchführung nicht-kausaler und kausaler Operationen.
Die Studie ergab, dass sogar die kausale Version des ResNet-Modells vergleichbar ist. und es gibt keinen signifikanten Unterschied zwischen ihnen. Ebenso ist die Leistung der kausalen und nicht-kausalen Version des Swin-Modells ähnlich, aber die Leistung der kausalen Version des LSTM-Modells ist deutlich geringer als die der nicht-kausalen Version Daher werden sich die Forscher in Zukunft auf die Modelle ResNet und Swin konzentrieren.
Um sicherzustellen, dass sich das in diesem Artikel vorgeschlagene Framework gut auf unbekannte Wörter übertragen lässt, führten die Forscher eine strengere Kreuzvalidierung auf Wortebene durch, was bedeutet, dass verschiedene Versuche durchgeführt werden Das gleiche Wort wird nicht gleichzeitig im Trainingssatz und im Test angezeigt. Wie in Abbildung 2b gezeigt, ist die Leistung bei nicht sichtbaren Wörtern mit der experimentellen Standardmethode im Artikel vergleichbar, was darauf hinweist, dass das Modell gut dekodieren kann Auch wenn es während des Trainings nicht gesehen wurde, was hauptsächlich auf diesen Artikel zurückzuführen ist, führt das gebaute Modell eine Sprachdekodierung auf Phonem- oder ähnlicher Ebene durch.
Darüber hinaus demonstrieren die Forscher die Leistung des ResNet-Kausaldecoders auf Einzelwortebene und zeigen Daten von zwei Teilnehmern (EKoG mit niedriger Abtastrate). Das dekodierte Spektrogramm behält die spektral-zeitliche Struktur der ursprünglichen Sprache genau bei (Abbildung 2c, d).
Die Forscher verglichen auch die vom neuronalen Decoder vorhergesagten Sprachparameter mit den vom Sprachcodierer codierten Parametern (als Referenzwerte). Die Forscher zeigten den durchschnittlichen PCC-Wert (N=48) mehrerer wichtiger Sprachparameter, einschließlich der Klanggewichtung (). Wird zur Unterscheidung von Vokalen und Konsonanten verwendet), Lautstärke, Tonhöhe f0, erster Formant f1 und zweiter Formant f2. Eine genaue Rekonstruktion dieser Sprachparameter, insbesondere Tonhöhe, Klanggewicht und die ersten beiden Formanten, ist entscheidend für eine genaue Sprachdekodierung und -rekonstruktion, die die Stimme des Teilnehmers auf natürliche Weise nachahmt.
Die Forschungsergebnisse zeigen, dass sowohl nicht-kausale als auch kausale Modelle vernünftige Dekodierungsergebnisse erzielen können, was eine positive Orientierung für zukünftige Forschung und Anwendungen bietet.
Studie zur Sprachdekodierung neuronaler Signale der linken und rechten Gehirnhälfte und zur räumlichen Abtastrate
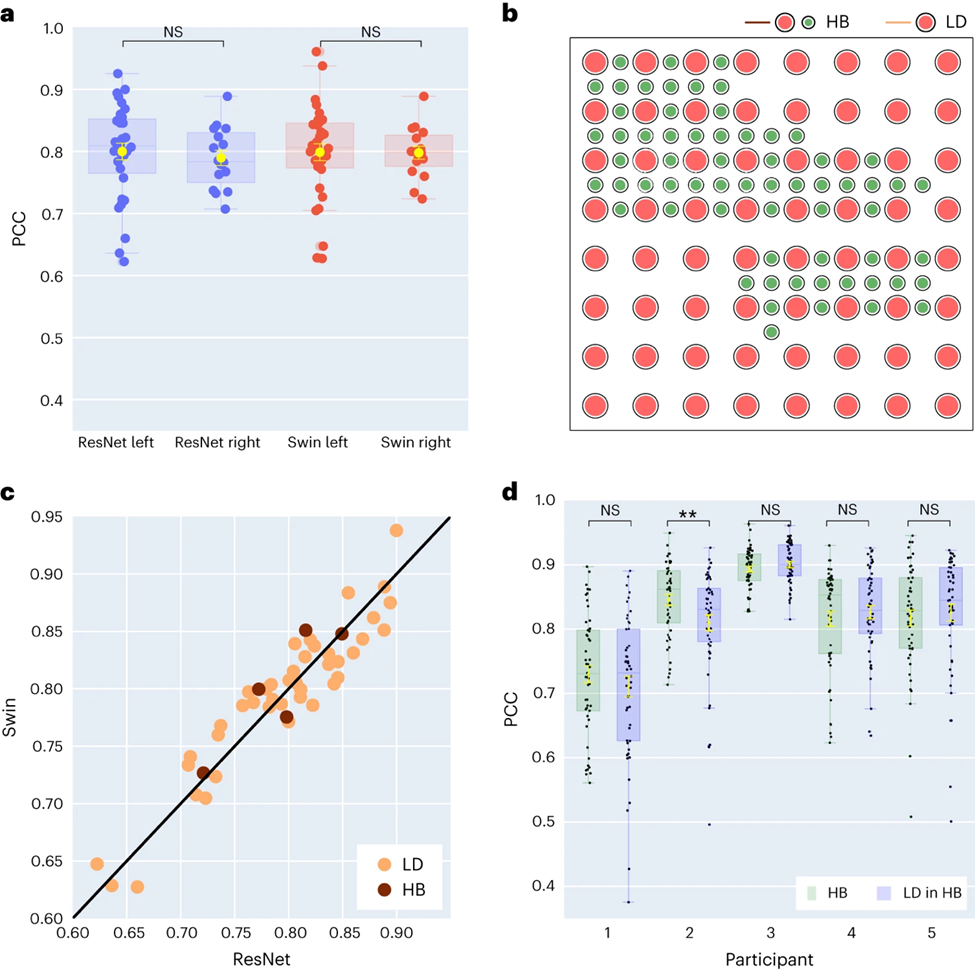
Die Forscher verglichen außerdem die Ergebnisse der Sprachdekodierung der linken und rechten Gehirnhälfte. Die meisten Studien konzentrieren sich auf die linke Gehirnhälfte, die für Sprache und Sprachfunktionen verantwortlich ist. Allerdings ist wenig darüber bekannt, wie Sprachinformationen aus der rechten Gehirnhälfte entschlüsselt werden. Als Reaktion darauf verglichen die Forscher die Dekodierungsleistung der linken und rechten Gehirnhälfte der Teilnehmer, um die Möglichkeit zu überprüfen, die rechte Gehirnhälfte zur Sprachwiederherstellung zu nutzen.
Von den 48 in der Studie erfassten Probanden wurden die ECoG-Signale von 16 Probanden aus der rechten Gehirnhälfte erfasst. Durch den Vergleich der Leistung von ResNet- und Swin-Dekodierern stellten die Forscher fest, dass die rechte Hemisphäre auch Sprache stabil dekodieren kann (der PCC-Wert von ResNet beträgt 0,790, der PCC-Wert von Swin beträgt 0,798), was sich weniger vom Dekodierungseffekt der linken Hemisphäre unterscheidet ( As (siehe Abbildung 3a).
Diese Erkenntnis gilt auch für die Bewertung von STOI+. Dies bedeutet, dass für Patienten mit einer Schädigung der linken Hemisphäre und einem Verlust der Sprachfähigkeit die Verwendung neuronaler Signale der rechten Hemisphäre zur Wiederherstellung der Sprache eine praktikable Lösung sein kann.
Dann untersuchten die Forscher den Einfluss der Elektroden-Abtastdichte auf den Sprachdekodierungseffekt. Frühere Studien verwendeten meist Elektrodengitter mit höherer Dichte (0,4 mm), während die Dichte der in der klinischen Praxis üblicherweise verwendeten Elektrodengitter geringer ist (LD 1 cm).
Fünf Teilnehmer verwendeten Hybrid-Elektrodengitter (HB) (siehe Abbildung 3b), bei denen es sich hauptsächlich um Probenentnahme mit niedriger Dichte handelt, in die jedoch zusätzliche Elektroden integriert sind. Die restlichen 43 Teilnehmer wurden in geringer Dichte beprobt. Die Dekodierungsleistung dieser Hybrid-Samples (HB) ist ähnlich wie bei herkömmlichen Low-Density-Samples (LD), schneidet jedoch bei STOI+ etwas besser ab.
Die Forscher verglichen die Wirkung der ausschließlichen Verwendung von Elektroden mit geringer Dichte mit der Verwendung aller gemischten Elektroden zur Dekodierung und stellten fest, dass der Unterschied zwischen beiden nicht signifikant war (siehe Abbildung 3d), was darauf hindeutet, dass das Modell in der Lage ist, Proben aus der Großhirnrinde zu entnehmen Es werden unterschiedliche räumliche Dichten erlernt, was auch impliziert, dass die in der klinischen Praxis üblicherweise verwendete Abtastdichte für zukünftige Gehirn-Computer-Schnittstellenanwendungen ausreichend sein könnte.
Untersuchung des Beitrags verschiedener Gehirnbereiche der linken und rechten Gehirnhälfte zur Sprachdekodierung
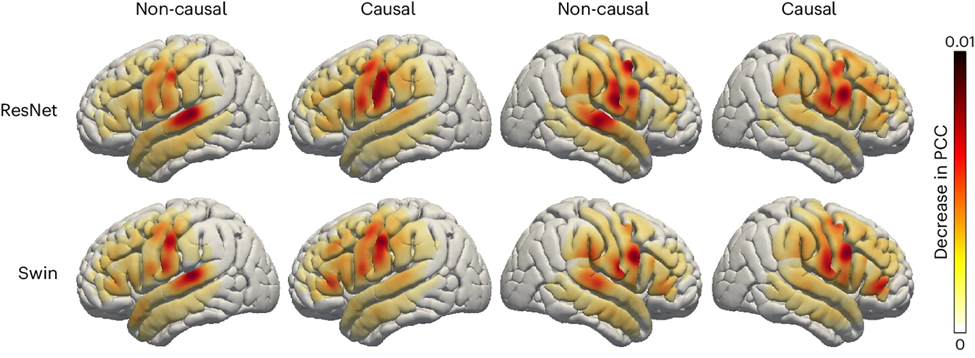
Abschließend untersuchten die Forscher den Beitrag sprachbezogener Bereiche des Gehirns beim Sprachdekodierungsprozess, der eine wichtige Referenz für die zukünftige Implantation von Sprachwiederherstellungsgeräten in die linke und rechte Gehirnhälfte liefert . Die Forscher nutzten die Okklusionsanalyse, um den Beitrag verschiedener Gehirnregionen zur Sprachdekodierung zu bewerten.
Kurz gesagt: Wenn ein bestimmter Bereich für die Decodierung entscheidend ist, verringert das Blockieren des Elektrodensignals in diesem Bereich (d. h. das Setzen des Signals auf Null) die Genauigkeit der rekonstruierten Sprache (PCC-Wert).
Mit dieser Methode haben die Forscher die Verringerung des PCC-Werts gemessen, wenn jeder Bereich verschlossen war. Durch den Vergleich der kausalen und nicht-kausalen Modelle von ResNet- und Swin-Dekodierern wird festgestellt, dass der auditorische Kortex einen größeren Beitrag zum nicht-kausalen Modell leistet. Dies unterstreicht, dass in Echtzeit-Sprachdekodierungsanwendungen kausale Modelle verwendet werden müssen Durch die Echtzeit-Sprachdekodierung können wir Neurofeedback-Signale nicht nutzen.
Darüber hinaus ist der Beitrag des sensomotorischen Kortex, insbesondere des Bauchbereichs, sowohl in der rechten als auch in der linken Hemisphäre ähnlich, was darauf hindeutet, dass es möglich sein könnte, Nervenprothesen in der rechten Hemisphäre zu implantieren.
Schlussfolgerungen und inspirierender Ausblick
Forscher haben einen neuen Typ eines differenzierbaren Sprachsynthesizers entwickelt, der ein leichtes Faltungs-Neuronales Netzwerk verwenden kann, um Sprache in eine Reihe interpretierbarer Sprachparameter (wie Tonhöhe, Lautstärke, Formantenfrequenzen usw.) zu kodieren. ) und synthetisieren Sie die Sprache durch einen differenzierbaren Sprachsynthesizer neu.
Durch die Zuordnung neuronaler Signale zu diesen Sprachparametern haben die Forscher ein neuronales Sprachdekodierungssystem entwickelt, das gut interpretierbar und auf Situationen mit geringem Datenvolumen anwendbar ist und natürlich klingende Sprache erzeugen kann. Diese Methode ist bei allen Teilnehmern (insgesamt 48 Personen) in hohem Maße reproduzierbar, und die Forscher haben erfolgreich die Wirksamkeit der kausalen Dekodierung mithilfe von Faltungs- und Transformer-Architekturen (3D Swin) demonstriert, die beide rekurrenten Architekturen (LSTM) überlegen sind.
Dieses Framework kann hohe und niedrige räumliche Abtastdichten verarbeiten und EEG-Signale aus der linken und rechten Hemisphäre verarbeiten, was ein starkes Potenzial für die Sprachdekodierung zeigt.
Die meisten früheren Studien berücksichtigten nicht die zeitliche Kausalität von Dekodierungsvorgängen in Echtzeit-Gehirn-Computer-Schnittstellenanwendungen. Viele nichtkausale Modelle basieren auf akustischen Rückmeldungssignalen. Die Analyse der Forscher zeigte, dass das nicht-kausale Modell hauptsächlich auf dem Beitrag des oberen Schläfengyrus beruhte, während das kausale Modell diesen im Wesentlichen eliminierte. Forscher glauben, dass die Vielseitigkeit nicht-kausaler Modelle in Echtzeit-BCI-Anwendungen aufgrund der übermäßigen Abhängigkeit von Rückkopplungssignalen begrenzt ist.
Einige Methoden versuchen, Feedback im Training zu vermeiden, beispielsweise die Dekodierung der imaginären Sprache des Probanden. Trotzdem verwenden die meisten Studien immer noch akausale Modelle und können Rückkopplungseffekte während des Trainings und der Schlussfolgerung nicht ausschließen. Darüber hinaus sind in der Literatur häufig verwendete rekurrente neuronale Netze in der Regel bidirektional, was zu nicht-kausalem Verhalten und Vorhersageverzögerungen führt, während unsere Experimente zeigen, dass unidirektional trainierte rekurrente Netze die schlechteste Leistung erbringen.
Obwohl in der Studie keine Echtzeitdekodierung getestet wurde, erreichten die Forscher eine Latenz von weniger als 50 Millisekunden bei der Synthese von Sprache aus neuronalen Signalen, was die Hörverzögerung kaum beeinträchtigte und eine normale Sprachproduktion ermöglichte.
In der Studie wurde untersucht, ob eine höhere Abdeckungsdichte die Decodierungsleistung verbessern kann. Die Forscher fanden heraus, dass sowohl eine Gitterabdeckung mit niedriger als auch hoher Dichte eine hohe Decodierungsleistung erzielte (siehe Abbildung 3c). Darüber hinaus stellten die Forscher fest, dass sich die Decodierungsleistung bei Verwendung aller Elektroden nicht wesentlich von der Leistung bei Verwendung nur von Elektroden mit geringer Dichte unterschied (Abbildung 3d).
Dies beweist, dass der von den Forschern vorgeschlagene ECoG-Decoder Sprachparameter aus neuronalen Signalen für die Sprachrekonstruktion extrahieren kann, solange die peritemporale Abdeckung ausreichend ist, selbst bei Teilnehmern mit geringer Teilnehmerdichte. Ein weiterer bemerkenswerter Befund war die kortikale Struktur der rechten Hemisphäre und der Beitrag des rechten peritemporalen Kortex zur Sprachdekodierung. Obwohl einige frühere Studien einen möglichen Beitrag der rechten Hemisphäre zur Dekodierung von Vokalen und Sätzen gezeigt haben, liefern unsere Ergebnisse Hinweise auf eine robuste phonologische Repräsentation in der rechten Hemisphäre.
Die Forscher erwähnten auch einige Einschränkungen des aktuellen Modells, wie z. B. den Decodierungsprozess, der Sprachtrainingsdaten gepaart mit ECoG-Aufzeichnungen erfordert, was möglicherweise nicht auf Aphasiker anwendbar ist. In Zukunft hoffen die Forscher auch, Modellarchitekturen zu entwickeln, die mit Nicht-Grid-Daten umgehen und multimodale EEG-Daten mehrerer Patienten besser nutzen können.
Der erste Autor dieses Artikels: Xupeng Chen, Ran Wang, korrespondierender Autor: Adeen Flinker.
Finanzielle Unterstützung: National Science Foundation unter Grant No. IIS-1912286, 2309057 (Y.W., A.F.) und National Institute of Health R01NS109367, R01NS115929, R01DC018805 (A.F.).
Weitere Informationen zur Kausalität bei der Dekodierung neuronaler Sprache finden Sie in einem anderen Artikel der Autoren „Distributed Feedforward and Feedback Cortical Processing Supports Human Language Production“: https://www.pnas.org/doi /10.1073 /pnas.2300255120
Quelle: Brain Computer Interface Community
Das obige ist der detaillierte Inhalt vonKI unterstützt die Forschung an Gehirn-Computer-Schnittstellen, die bahnbrechende neuronale Sprachdekodierungstechnologie der New York University, veröffentlicht in der Unterzeitschrift „Nature'.. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!