
Heim >Technologie-Peripheriegeräte >KI >CVPR 2024 |. Das neue Framework CustomNeRF bearbeitet 3D-Szenen präzise mit nur Text- oder Bildaufforderungen
CVPR 2024 |. Das neue Framework CustomNeRF bearbeitet 3D-Szenen präzise mit nur Text- oder Bildaufforderungen

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2024-04-15 10:13:19881Durchsuche
Das Meitu Imaging Research Institute (MT Lab) hat zusammen mit dem Institut für Informationstechnik der Chinesischen Akademie der Wissenschaften, der Beijing University of Aeronautics and Astronautics und der Sun Yat-sen University gemeinsam eine 3D-Szenenbearbeitungsmethode vorgeschlagen – CustomNeRF. Die Forschungsergebnisse wurden vom CVPR 2024 akzeptiert. CustomNeRF unterstützt nicht nur Textbeschreibungen und Referenzbilder als Bearbeitungstipps für 3D-Szenen, sondern generiert auch hochwertige 3D-Szenen basierend auf den von Benutzern bereitgestellten Informationen.
Neural Radiance Field (NeRF) Seit der Einführung des Neural Radiance Field (NeRF) im Jahr 2020 hat es den impliziten Ausdruck auf eine neue Ebene gehoben. Als eine der derzeit modernsten Technologien wurde NeRF schnell verallgemeinert und in Bereichen wie Computer Vision, Computergrafik, Augmented Reality und Virtual Reality angewendet und erfährt weiterhin große Aufmerksamkeit. NeRF ermöglicht eine qualitativ hochwertige Bildsynthese durch Modellierung der Strahlung und Dichte jedes Punkts in der Szene, was es für Anwendungen in Bereichen wie Computer Vision, Computergrafik, Augmented Reality und Virtual Reality äußerst attraktiv macht. NeRF ist einzigartig in seiner Fähigkeit, hochwertige Bilder aus Eingabeszenen zu generieren, ohne dass komplexe 3D-Scans oder dichte Perspektivbilder erforderlich sind. Aufgrund dieser Funktion hat NeRF breite Anwendungsaussichten in vielen Bereichen, darunter Computer Vision, Computergrafik, Augmented Reality und Virtual Reality, und erfährt weiterhin große Aufmerksamkeit. NeRF ermöglicht eine hochwertige Bildsynthese durch Modellierung der Strahlkraft und Dichte jedes Punkts in der Szene. Mit NeRF können auch hochwertige 3D-Renderings erstellt werden, was es für Anwendungen in Bereichen wie Virtual Reality und Augmented Reality sehr vielversprechend macht. Die rasante Entwicklung und weit verbreitete Anwendung von NeRF wird weiterhin große Aufmerksamkeit erhalten, und es wird erwartet, dass in Zukunft weitere Innovationen und Anwendungen auf Basis von NeRF entstehen werden.
NeRF (Neural Radiation Field) ist eine Funktion zur Optimierung und kontinuierlichen Darstellung, die viele Anwendungen bei der 3D-Szenenrekonstruktion hat. Es hat sogar die Forschung im Bereich der Bearbeitung von 3D-Szenen vorangetrieben, beispielsweise der Neuzeichnung von Texturen und der Stilisierung von 3D-Objekten oder Szenen. Um die Flexibilität der 3D-Szenenbearbeitung weiter zu verbessern, werden in letzter Zeit auch NeRF-Bearbeitungsmethoden basierend auf vorab trainierten Modellen intensiv untersucht. Aufgrund der impliziten Darstellung von NeRF und der geometrischen Eigenschaften von 3D-Szenen werden Bearbeitungsergebnisse erzielt, die den Textaufforderungen entsprechen Diese können sehr einfach umgesetzt werden.
Um eine textgesteuerte 3D-Szenenbearbeitung zu ermöglichen und eine präzise Steuerung zu erreichen, haben das Meitu Imaging Research Institute (MT Lab), das Institut für Informationstechnik der Chinesischen Akademie der Wissenschaften, die Beihang-Universität und die Sun Yat-sen-Universität gemeinsam Folgendes vorgeschlagen: Methode, die Textbeschreibung und Referenz kombiniert. Image Unification stellt das CustomNeRF-Framework für die Bearbeitung bereit. Das Framework verfügt über ein integriertes perspektivenspezifisches Subjekt V∗, das in die Hybriddarstellung eingebettet ist, um allgemeine und benutzerdefinierte Anforderungen an die Bearbeitung von 3D-Szenen zu erfüllen. Die Forschungsergebnisse wurden im CVPR 2024 aufgezeichnet und der Code ist Open Source.

Paper Link: https://arxiv.org/abs/2312.01663
code Link: https://github.com/hrz2000/customnerf

: die Bearbeitungseffekt von CustomNeRF in textgesteuertem (links) und bildgesteuertem (rechts)
Zwei große Herausforderungen, die von CustomNeRF gelöst werden
Derzeit sind es hauptsächlich die gängigen Methoden für die 3D-Szenenbearbeitung, die auf vorab trainierten Diffusionsmodellen basieren in zwei Kategorien unterteilt.
Eine besteht darin, das Bildbearbeitungsmodell zu verwenden, um die Bilder im Datensatz iterativ zu aktualisieren. Aufgrund der begrenzten Fähigkeiten des Bildbearbeitungsmodells schlägt dies jedoch in einigen Bearbeitungssituationen fehl. Zweitens wird der SDS-Verlust (Fractional Destillation Sampling) zum Bearbeiten der Szene verwendet. Aufgrund des Ausrichtungsproblems zwischen Text und Szene kann diese Methode jedoch nicht direkt an die reale Szene angepasst werden und führt zu unnötigen Verzerrungen in der Nicht-Szene. Bearbeitungsbereich erfordert häufig explizite Zwischenausdrücke wie Netz oder Voxel.
Darüber hinaus konzentrieren sich die beiden aktuellen Methoden hauptsächlich auf textgesteuerte 3D-Szenenbearbeitungsaufgaben. Es ist oft schwierig, die Bearbeitungsanforderungen des Benutzers genau auszudrücken, und es ist nicht möglich, bestimmte Konzepte in Bildern in 3D-Szenen anzupassen Da die ursprüngliche 3D-Szene im Allgemeinen bearbeitet wird, ist es schwierig, die vom Benutzer erwarteten Bearbeitungsergebnisse zu erzielen.
Tatsächlich liegt der Schlüssel zum Erreichen der gewünschten Bearbeitungsergebnisse darin, den Bildvordergrundbereich genau zu identifizieren, was eine geometrisch konsistente Bildvordergrundbearbeitung unter Beibehaltung des Bildhintergrunds fördert.
Um eine genaue Bearbeitung nur des Vordergrundbereichs des Bildes zu erreichen, schlägt das Papier daher ein Trainingsschema für die lokal-globale iterative Bearbeitung (LGIE) vor, das zwischen der Bearbeitung des Bildvordergrundbereichs und der vollständigen Bildbearbeitung wechselt. Diese Lösung kann den Bildvordergrundbereich genau lokalisieren und nur den Bildvordergrund bearbeiten, während der Bildhintergrund erhalten bleibt.
Darüber hinaus besteht bei der bildgesteuerten 3D-Szenenbearbeitung das Problem geometrischer Inkonsistenzen in den Bearbeitungsergebnissen, die durch eine Überanpassung des fein abgestimmten Diffusionsmodells an die Referenzbildperspektive verursacht werden. In diesem Zusammenhang entwirft das Papier eine klassengesteuerte Regularisierung, bei der in der lokalen Bearbeitungsphase nur Klassenwörter zur Darstellung des Subjekts des Referenzbilds verwendet werden und eine allgemeine Klasse vorab in einem vorab trainierten Diffusionsmodell genutzt wird, um eine geometrisch konsistente Bearbeitung zu fördern.
Der Gesamtprozess von CustomNeRF
Wie in Abbildung 2 dargestellt, verwendet CustomNeRF drei Schritte, um das Ziel der präzisen Bearbeitung und Rekonstruktion von 3D-Szenen unter Anleitung von Textaufforderungen oder Referenzbildern zu erreichen.
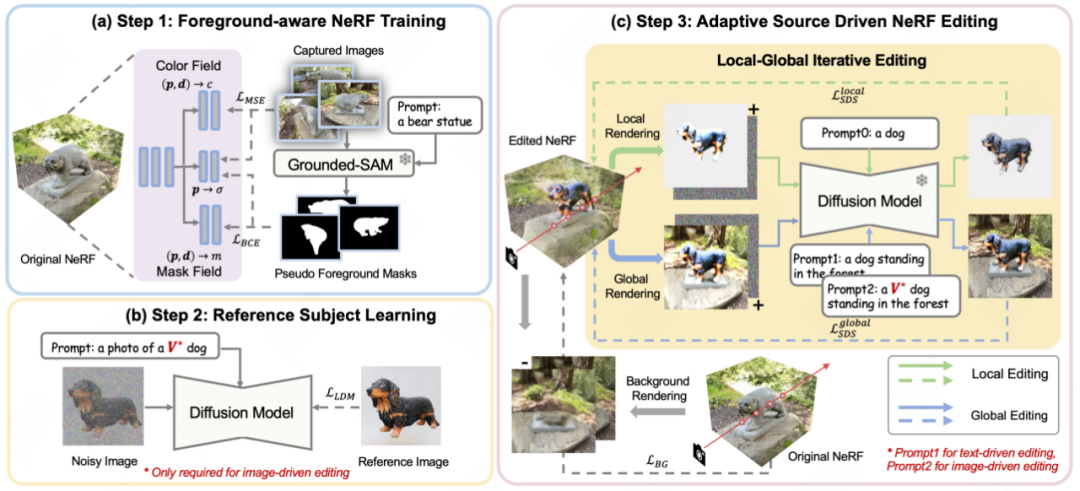
Abbildung 2 Gesamtflussdiagramm von Customerf
Erstens führt Customerf bei der Rekonstruktion der ursprünglichen 3D -Szene ein zusätzliches Maskenfeld ein, um die Bearbeitungswahrscheinlichkeiten über die Dichte hinaus abzuschätzen. Wie in Abbildung 2(a) gezeigt, verwendet das Papier für einen Satz von Bildern, die eine 3D-Szene rekonstruieren müssen, zunächst Grouded SAM, um die Maske des Bildbearbeitungsbereichs aus der Beschreibung in natürlicher Sprache zu extrahieren, und kombiniert den Originalbildsatz damit Trainieren Sie vordergrundbewusstes NeRF. Nach der NeRF-Rekonstruktion werden die Bearbeitungswahrscheinlichkeiten verwendet, um zu bearbeitende Bildbereiche (d. h. Bildvordergrundbereiche) von irrelevanten Bildbereichen (d. h. Bildhintergrundbereiche) zu unterscheiden, um das entkoppelte Rendern während des Bildbearbeitungstrainings zu erleichtern.
Zweitens: Um bildgesteuerte und textgesteuerte 3D-Szenenbearbeitungsaufgaben zu vereinheitlichen, wie in Abbildung 2(b) dargestellt, verwendet das Papier die Methode der benutzerdefinierten Diffusion, um das Referenzbild unter bildgesteuerten Lernbedingungen zu optimieren die fachspezifischen Key Features. Nach dem Training kann das spezielle Wort V* als reguläres Wort-Tag verwendet werden, um das thematische Konzept im Referenzbild auszudrücken und so einen hybriden Hinweis wie „ein Foto eines V*-Hundes“ zu bilden. Auf diese Weise ermöglicht CustomNeRF eine konsistente und effiziente Bearbeitung adaptiver Datentypen, einschließlich Bildern oder Text.
In der letzten Bearbeitungsphase führt die Optimierung des gesamten 3D-Bereichs mithilfe von SDS-Verlust aufgrund des impliziten Ausdrucks von NeRF zu erheblichen Änderungen in den Hintergrundbereichen, die nach der Bearbeitung mit der Originalszene übereinstimmen sollten. Wie in Abbildung 2(c) dargestellt, schlägt das Papier ein Local-Global Iterative Editing (LGIE)-Schema für entkoppeltes SDS-Training vor, das es ermöglicht, Hintergrundinhalte bei der Bearbeitung des Layoutbereichs beizubehalten.
Insbesondere unterteilt dieses Papier den Bearbeitungsschulungsprozess von NeRF in eine detailliertere Art und Weise. Mit vordergrundbewusstem NeRF kann CustomNeRF den Rendering-Prozess von NeRF während des Trainings flexibel steuern, d. Während des Trainingsprozesses kann die aktuelle NeRF-Szene mithilfe des SDS-Verlusts auf verschiedenen Ebenen bearbeitet werden, indem Vorder- und Hintergrund iterativ gerendert werden, kombiniert mit entsprechenden Vordergrund- oder Hintergrundhinweisen. Unter anderem ermöglicht Ihnen das lokale Vordergrundtraining, sich nur auf den Bereich zu konzentrieren, der während des Bearbeitungsprozesses bearbeitet werden muss, wodurch die Bearbeitungsaufgaben in komplexen Szenen vereinfacht werden, während das globale Training die gesamte Szene berücksichtigt und die Koordination aufrechterhalten kann Vordergrund und Hintergrund. Um den nicht bearbeiteten Bereich weiterhin unverändert zu lassen, verwendet das Papier vor dem Bearbeitungstraining auch den neu gerenderten Hintergrund während des Hintergrundüberwachungstrainings, um die Konsistenz der Hintergrundpixel aufrechtzuerhalten.
Darüber hinaus kommt es bei der bildgesteuerten 3D-Szenenbearbeitung zu zunehmenden geometrischen Inkonsistenzen. Da das mit dem Referenzbild feinabgestimmte Diffusionsmodell während des Inferenzprozesses tendenziell Bilder mit einer ähnlichen Perspektive wie das Referenzbild erzeugt, führt dies dazu, dass mehrere Perspektiven der bearbeiteten 3D-Szene zu geometrischen Problemen in der Vorderansicht führen. Zu diesem Zweck entwirft das Papier eine klassengesteuerte Regularisierungsstrategie, bei der spezielle Deskriptoren V* in globalen Hinweisen und nur Klassenwörter in lokalen Hinweisen verwendet werden, um die im vorab trainierten Diffusionsmodell enthaltenen Klassenprioritäten zu nutzen und mehr neue Konzepte einzuführen geometrisch konsistent in die Szene einzufügen.
Experimentelle Ergebnisse
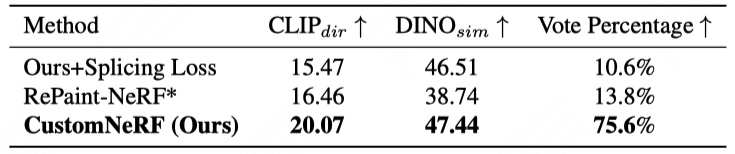
Abbildung 3 und Abbildung 4 zeigen den Vergleich der 3D-Szenenrekonstruktionsergebnisse von CustomNeRF und der Baseline-Methode, sowohl bei Referenzbild- als auch bei textgesteuerten 3D-Szenenbearbeitungsaufgaben erzielte CustomNeRF nicht nur gute Bearbeitungsergebnisse Es wird eine gute Anpassung an die Bearbeitungstipps erreicht und die Hintergrundbereiche bleiben im Einklang mit der Originalszene. Darüber hinaus zeigen Tabelle 1 und Tabelle 2 den quantitativen Vergleich von CustomNeRF mit der Basismethode, wenn sie durch Bilder und Text gesteuert wird. Die Ergebnisse zeigen, dass CustomNeRF die Basismethode in Bezug auf Textausrichtungsmetriken, Bildausrichtungsmetriken und menschliche Bewertung übertrifft.

Quantitativer Vergleich mit der Basislinie unter bildgesteuerter Bearbeitung. Bearbeitungsaufforderungen für Textbeschreibungen oder Referenzbilder und löst zwei Hauptherausforderungen: genaue Bearbeitung nur im Vordergrund und Konsistenz über mehrere Ansichten hinweg, wenn Referenzbilder in einer einzigen Ansicht verwendet werden. Das Schema umfasst das Local-Global Iterative Editing (LGIE)-Trainingsschema, das es Bearbeitungsvorgängen ermöglicht, sich auf den Vordergrund zu konzentrieren, während der Hintergrund unverändert bleibt, und eine klassengesteuerte Regularisierung, die Ansichtsinkonsistenzen bei der bildgesteuerten Bearbeitung verringert, und wurde verifiziert Durch umfangreiche Experimente ermöglicht CustomNeRF die genaue Bearbeitung von 3D-Szenen, die durch Textbeschreibungen und Referenzbilder in einer Vielzahl realer Szenarien angeregt werden. 
Das obige ist der detaillierte Inhalt vonCVPR 2024 |. Das neue Framework CustomNeRF bearbeitet 3D-Szenen präzise mit nur Text- oder Bildaufforderungen. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!