
Heim >Technologie-Peripheriegeräte >KI >Die lokale Ausführungsleistung des Embedding-Dienstes übertrifft die von OpenAI Text-Embedding-Ada-002, was sehr praktisch ist!
Die lokale Ausführungsleistung des Embedding-Dienstes übertrifft die von OpenAI Text-Embedding-Ada-002, was sehr praktisch ist!

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2024-04-15 09:01:011238Durchsuche
Ollama ist ein superpraktisches Tool, mit dem Sie Open-Source-Modelle wie Llama 2, Mistral und Gemma problemlos lokal ausführen können. In diesem Artikel werde ich vorstellen, wie man Ollama zum Vektorisieren von Text verwendet. Wenn Sie Ollama nicht lokal installiert haben, können Sie diesen Artikel lesen.
In diesem Artikel verwenden wir das Modell nomic-embed-text[2]. Es handelt sich um einen Text-Encoder, der OpenAI text-embedding-ada-002 und text-embedding-3-small bei kurzen und langen Kontextaufgaben übertrifft.
Starten Sie den nomic-embed-text-Dienst.
Nachdem Sie Ollama erfolgreich installiert haben, verwenden Sie den folgenden Befehl, um das nomic-embed-text-Modell abzurufen:
ollama pull nomic-embed-text
Nachdem Sie das Modell erfolgreich abgerufen haben, geben Sie den folgenden Befehl ein Terminal, starten Sie den Ollama-Dienst:
ollama serve
Danach können wir mit Curl überprüfen, ob der Einbettungsdienst normal läuft:
curl http://localhost:11434/api/embeddings -d '{"model": "nomic-embed-text","prompt": "The sky is blue because of Rayleigh scattering"}'Verwenden Sie den nomic-embed-text-Dienst
Als nächstes stellen wir vor, wie um langchainjs und den nomic -embed-text-Dienst zu verwenden, der Einbettungsvorgänge für lokale TXT-Dokumente implementiert. Der entsprechende Vorgang ist in der folgenden Abbildung dargestellt:
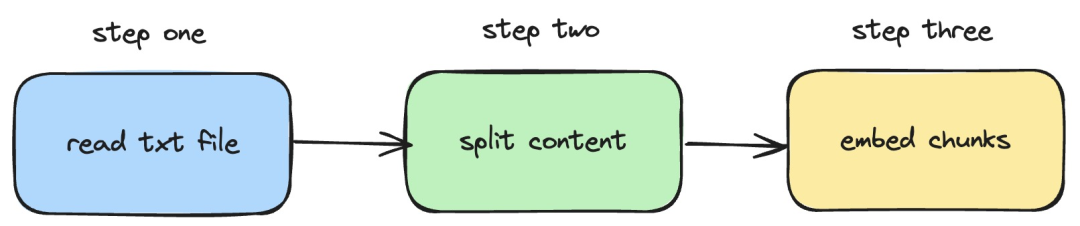 Bilder
Bilder
1. Lesen Sie die lokale TXT-Datei
import { TextLoader } from "langchain/document_loaders/fs/text";async function load(path: string) {const loader = new TextLoader(path);const docs = await loader.load();return docs;}Im obigen Code haben wir eine Ladefunktion definiert, die intern den von langchainjs bereitgestellten TextLoader verwendet Lesen Sie „Lokales TXT-Dokument abrufen“.
2. Teilen Sie den TXT-Inhalt in Textblöcke auf
import { RecursiveCharacterTextSplitter } from "langchain/text_splitter";import { Document } from "langchain/document";function split(documents: Document[]) {const splitter = new RecursiveCharacterTextSplitter({chunkSize: 500,chunkOverlap: 20,});return splitter.splitDocuments(documents);}Im obigen Code verwenden wir RecursiveCharacterTextSplitter, um den gelesenen TXT-Text zu schneiden und die Größe jedes Textblocks auf 500 festzulegen.
3. Führen Sie eine Einbettungsoperation für Textblöcke durch
const EMBEDDINGS_URL = "http://127.0.0.1:11434/api/embeddings";async function embedding(path: string) {const docs = await load(path);const splittedDocs = await split(docs);for (let doc of splittedDocs) {const embedding = await sendRequest(EMBEDDINGS_URL, {model: "nomic-embed-text",prompt: doc.pageContent,});console.dir(embedding.embedding);}}Im obigen Code definieren wir eine Einbettungsfunktion, in der die zuvor definierten Lade- und Teilungsfunktionen aufgerufen werden. Durchlaufen Sie dann den generierten Textblock und rufen Sie den lokal gestarteten Einbettungsdienst nomic-embed-text auf. Die sendRequest-Funktion wird zum Senden von Einbettungsanforderungen verwendet. Ihr Implementierungscode ist sehr einfach, nämlich die Verwendung der Abruf-API zum Aufrufen der vorhandenen REST-API.
async function sendRequest(url: string, data: Record<string, any>) {try {const response = await fetch(url, {method: "POST",body: JSON.stringify(data),headers: {"Content-Type": "application/json",},});if (!response.ok) {throw new Error(`HTTP error! status: ${response.status}`);}const responseData = await response.json();return responseData;} catch (error) {console.error("Error:", error);}}Als nächstes definieren wir weiterhin eine EmbedTxtFile-Funktion, rufen die vorhandene Einbettungsfunktion direkt innerhalb der Funktion auf und fügen die entsprechende Ausnahmebehandlung hinzu.
async function embedTxtFile(path: string) {try {embedding(path);} catch (error) {console.dir(error);}}embedTxtFile("langchain.txt")Schließlich verwenden wir den Befehl npx esno src/index.ts, um die lokale ts-Datei schnell auszuführen. Wenn der Code in index.ts erfolgreich ausgeführt wird, werden die folgenden Ergebnisse im Terminal ausgegeben:
 Bilder
Bilder
Tatsächlich können wir zusätzlich zur Verwendung der oben genannten Methode auch direkt [OllamaEmbeddings im @ verwenden langchain/community module ](https://js.langchain.com/docs/integrations/text_embedding/ollama „OllamaEmbeddings“)-Objekt, das intern die Logik des Aufrufs des Ollama-Einbettungsdienstes kapselt:
import { OllamaEmbeddings } from "@langchain/community/embeddings/ollama";const embeddings = new OllamaEmbeddings({model: "nomic-embed-text", baseUrl: "http://127.0.0.1:11434",requestOptions: {useMMap: true,numThread: 6,numGpu: 1,},});const documents = ["Hello World!", "Bye Bye"];const documentEmbeddings = await embeddings.embedDocuments(documents);console.log(documentEmbeddings);Der in eingeführte Inhalt Dieser Artikel befasst sich mit der Entwicklung des RAG-Systems und dem Prozess der Erstellung eines Wissensdatenbank-Inhaltsindex. Wenn Sie das RAG-System nicht kennen, können Sie verwandte Artikel lesen.
Referenzen
[1]Ollama: https://ollama.com/
[2]nomic-embed-text: https://ollama.com/library/nomic-embed-text
Das obige ist der detaillierte Inhalt vonDie lokale Ausführungsleistung des Embedding-Dienstes übertrifft die von OpenAI Text-Embedding-Ada-002, was sehr praktisch ist!. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Der Unterschied zwischen has und with im Laravel-Assoziationsmodell (ausführliche Einführung)
- Was ist ein Softwareentwicklungsmodell und welche gängigen Softwareentwicklungsmodelle gibt es?
- Was sind die gängigen Softwareentwicklungsmodelle?
- Auf welches Modell bezieht sich die 7-schichtige Netzwerkstruktur?
- So kopieren Sie ein Modell in eine andere Datei in 3dmax