
Heim >Technologie-Peripheriegeräte >KI >Durch die direkte Erweiterung auf unendliche Länge beendet Google Infini-Transformer die Debatte über die Kontextlänge
Durch die direkte Erweiterung auf unendliche Länge beendet Google Infini-Transformer die Debatte über die Kontextlänge

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2024-04-13 08:00:24878Durchsuche
Ich weiß nicht, ob Gemini 1.5 Pro diese Technologie verwendet.
Google hat einen weiteren großen Schritt gemacht und das Transformer-Modell der nächsten Generation Infini-Transformer herausgebracht.
Führt einen praktischen und leistungsstarken Aufmerksamkeitsmechanismus Infini-Aufmerksamkeit ein – mit komprimiertem Langzeitgedächtnis und lokaler kausaler Aufmerksamkeit, der effektiv genutzt werden kann modellieren Sie langfristige und kurzfristige Kontextabhängigkeiten; Infini-Attention nimmt minimale Änderungen an der standardmäßig skalierten Punktproduktaufmerksamkeit vor und ist so konzipiert, dass es ein kontinuierliches Plug-and-Play-Vortraining und Selbstlernen über lange Kontexte unterstützt. Anpassung; Diese Methode ermöglicht es Transformer LLM, extrem lange Eingaben über Streams zu verarbeiten und auf unendlich lange Kontexte mit begrenzten Speicher- und Rechenressourcen zu skalieren. H-Paper-Link: https://arxiv.org/pdf/2404.07143.pdf

- Diese subtile, aber entscheidende Änderung der Transformer-Aufmerksamkeitsschicht kann das Kontextfenster bestehender LLMs durch kontinuierliches Vortraining und Feinabstimmung auf unendliche Längen erweitern.
-
Infini-Attention übernimmt alle Schlüssel-, Wert- und Abfragezustände der Standard-Aufmerksamkeitsberechnungen für die Konsolidierung und den Abruf des Langzeitgedächtnisses und speichert den alten KV-Aufmerksamkeitszustand im komprimierten Speicher, anstatt sie wie der Standard-Aufmerksamkeitsmechanismus zu verwerfen.Bei der Verarbeitung nachfolgender Sequenzen verwendet Infini-attention den Aufmerksamkeitsabfragestatus, um Werte aus dem Speicher abzurufen. Um die endgültige Kontextausgabe zu berechnen, aggregiert Infini-attention die Abrufwerte des Langzeitgedächtnisses und den lokalen Aufmerksamkeitskontext. Wie in Abbildung 2 unten dargestellt, verglich das Forschungsteam Infini-Transformer und Transformer-XL basierend auf der Infini-Aufmerksamkeit. Ähnlich wie Transformer-XL arbeitet Infini-Transformer mit einer Folge von Segmenten und berechnet den standardmäßigen kausalen Punktprodukt-Aufmerksamkeitskontext in jedem Segment. Daher ist die Berechnung der Skalarproduktaufmerksamkeit in gewissem Sinne lokal. 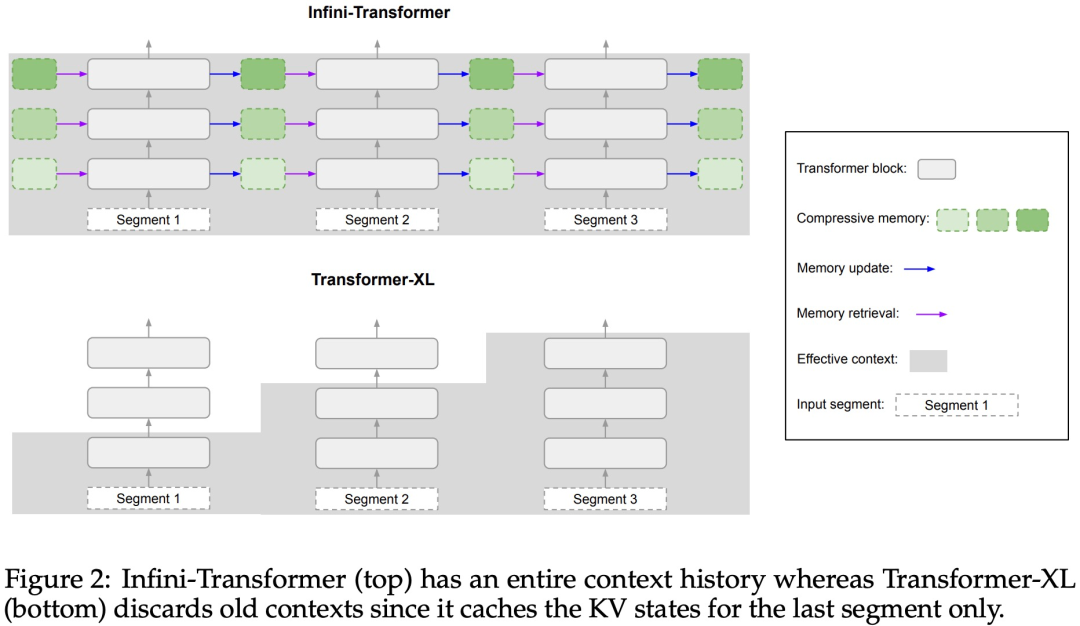
Allerdings verwirft die lokale Aufmerksamkeit den Aufmerksamkeitszustand des vorherigen Segments, wenn sie das nächste Segment verarbeitet, aber Infini-Transformer verwendet den alten KV-Aufmerksamkeitszustand wieder, um den gesamten Kontextverlauf durch komprimierte Speicherung aufrechtzuerhalten. Daher verfügt jede Aufmerksamkeitsschicht von Infini-Transformer über einen globalen komprimierten Zustand und einen lokalen feinkörnigen Zustand. Ähnlich wie bei der Multi-Head-Aufmerksamkeit (MHA) verwaltet Infini-Attention zusätzlich zur Punktproduktaufmerksamkeit auch H parallel komprimierte Erinnerungen für jede Aufmerksamkeitsschicht (H ist die Anzahl der Aufmerksamkeitsköpfe). 
Tabelle 1 unten listet den Kontextspeicherbedarf und die effektive Kontextlänge auf, die von mehreren Modellen basierend auf Modellparametern und Eingabesegmentlänge definiert werden. Infini-Transformer unterstützt unendliche Kontextfenster mit begrenztem Speicherbedarf. 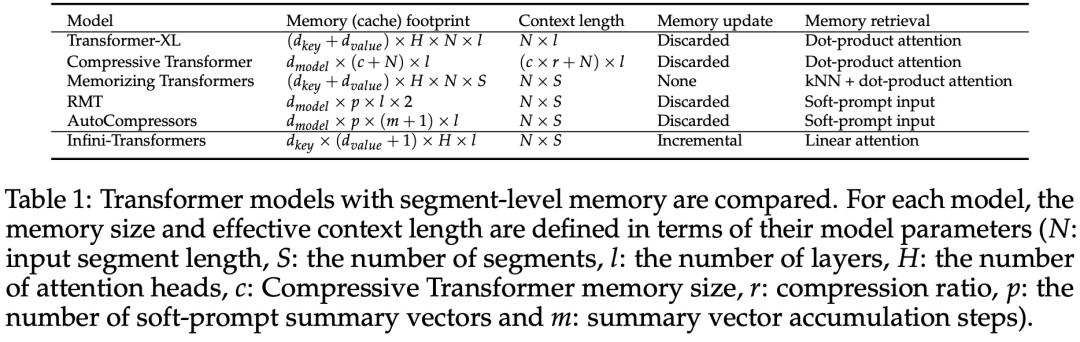
Experimente Die Studie evaluierte das Infini-Transformer-Modell zur Sprachmodellierung mit langen Kontexten, zum Abrufen von Schlüsselkontextblöcken mit einer Länge von 1 Mio. und zu Buchzusammenfassungsaufgaben mit einer Länge von 500.000, die eine extrem lange Eingabesequenz aufweisen. Für die Sprachmodellierung entschieden sich die Forscher dafür, das Modell von Grund auf zu trainieren, während die Forscher für die Schlüssel- und Buchzusammenfassungsaufgaben ein kontinuierliches Vortraining von LLM verwendeten, um die Plug-and-Play-Anpassbarkeit von Infini-attention für lange Kontexte zu beweisen. Sprachmodellierung mit langem Kontext. Die Ergebnisse in Tabelle 2 zeigen, dass Infini-Transformer die Baselines von Transformer-XL und Memorizing Transformers übertrifft und im Vergleich zum Memorizing Transformer-Modell 114-mal weniger Parameter speichert. 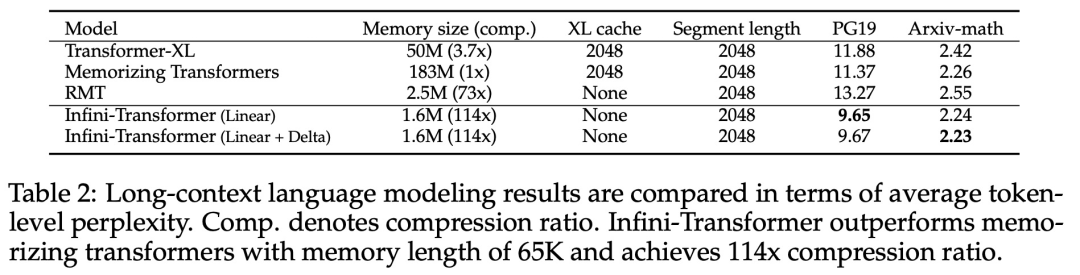
Schlüsselmission. Tabelle 3 zeigt den Infini-Transformer, der auf eine Eingabe mit einer Länge von 5 KB fein abgestimmt ist und die Schlüsselaufgabe bis zu einer Kontextlänge von 1 MB löst. Die Eingabetoken im Experiment lagen zwischen 32.000 und 1 Mio. Für jede Testteilmenge kontrollierten die Forscher die Position des Schlüssels so, dass er sich nahe dem Anfang, der Mitte oder dem Ende der Eingabesequenz befand. Experimente berichten von Nullschussgenauigkeit und Feinabstimmungsgenauigkeit. Nach 400 Feinabstimmungsschritten an einer Eingabe mit 5K Länge löst Infini-Transformer Aufgaben mit einer Kontextlänge von bis zu 1M. 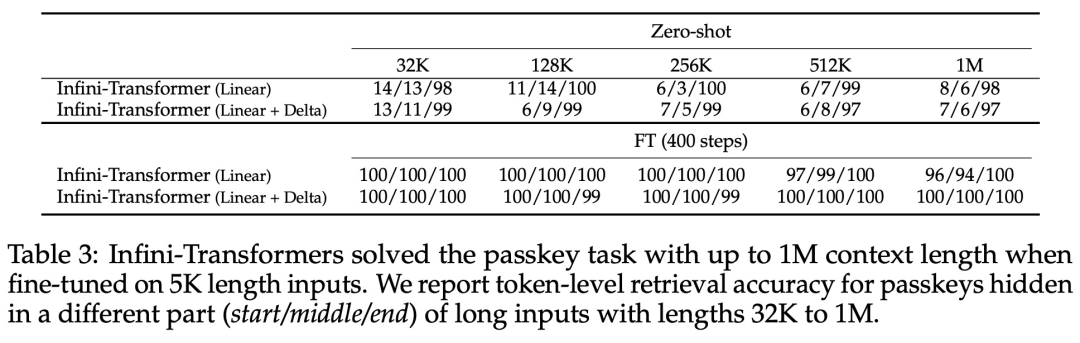
Zusammenfassende Aufgaben. Tabelle 4 vergleicht Infini-Transformer mit einem Encoder-Decoder-Modell, das speziell für die Zusammenfassungsaufgabe entwickelt wurde. Die Ergebnisse zeigen, dass Infini-Transformer die bisherigen besten Ergebnisse übertrifft und durch die Verarbeitung des gesamten Buchtextes neue SOTA auf BookSum erreicht. 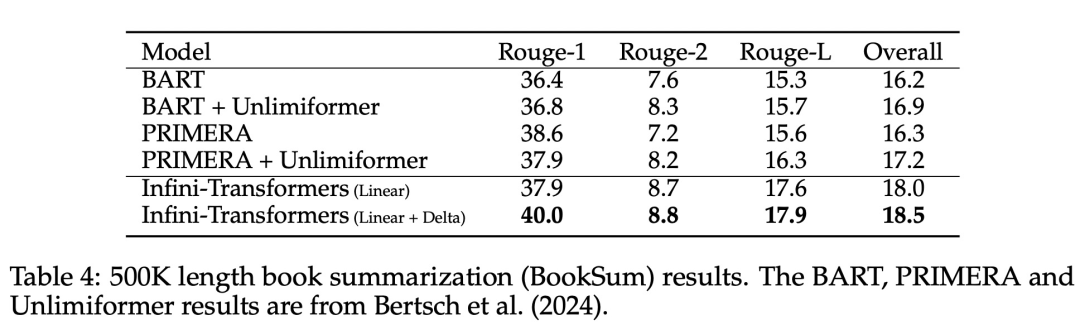
Die Forscher haben auch den gesamten Rouge-Score der BookSum-Datenvalidierungsaufteilung in Abbildung 4 dargestellt. Der Polylinientrend zeigt, dass Infini-Transformer die zusammenfassenden Leistungsmetriken verbessern, wenn die Eingabelänge zunimmt. 
Das obige ist der detaillierte Inhalt vonDurch die direkte Erweiterung auf unendliche Länge beendet Google Infini-Transformer die Debatte über die Kontextlänge. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
Stellungnahme:
Dieser Artikel ist reproduziert unter:jiqizhixin.com. Bei Verstößen wenden Sie sich bitte an admin@php.cn löschen
Vorheriger Artikel:Wie KI-Agenten auf Unternehmensebene in der Automobilindustrie implementiert werden können, ist dies das erste inländische Whitepaper, das systematisch erläutertNächster Artikel:Wie KI-Agenten auf Unternehmensebene in der Automobilindustrie implementiert werden können, ist dies das erste inländische Whitepaper, das systematisch erläutert