Die Kombination aus großen Modellen und KI-Datenbanken ist zu einer Erfolgsformel geworden, um die Kosten zu senken, die Effizienz großer Modelle zu steigern und Big Data wirklich intelligent zu machen.

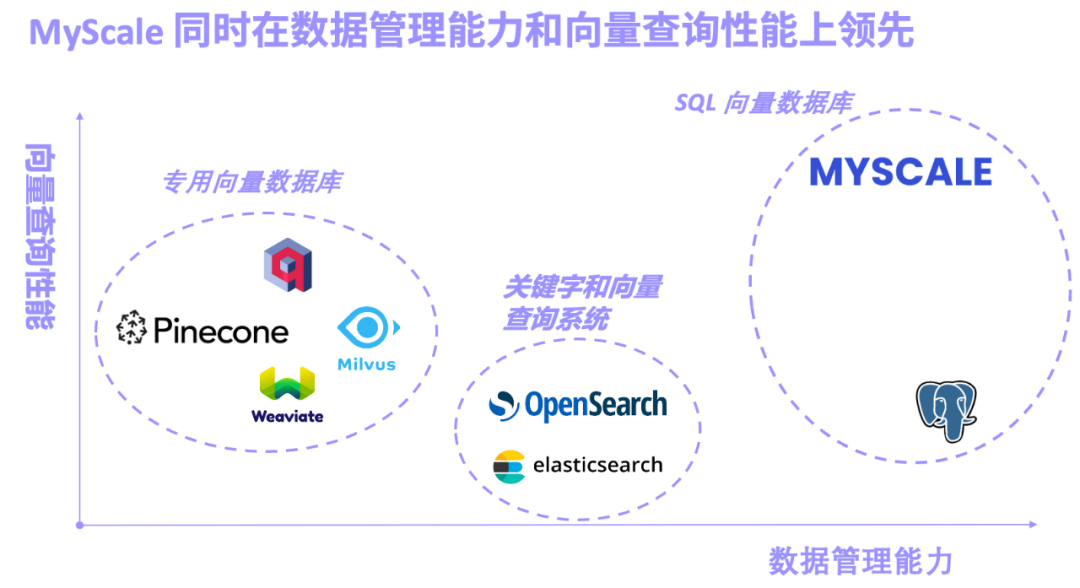
Die Welle der Large Models (LLM) nimmt seit mehr als einem Jahr zu, insbesondere die Modelle, die von GPT-4, Gemini-1.5, Claude-3 usw. vertreten werden. Auf der LLM-Strecke konzentrieren sich einige Forschungen auf die Erhöhung der Modellparameter, andere sind verrückt nach Multimodalität ... Unter anderem ist die Fähigkeit von LLM, die Kontextlänge zu verarbeiten, zu einem wichtigen Indikator für die Bewertung von Modellen geworden. Ein stärkerer Kontext bedeutet, dass das Modell vorhanden ist stärkere Abrufleistung. Beispielsweise hat die Fähigkeit einiger Modelle, bis zu 1 Million Token auf einmal zu verarbeiten, viele Forscher dazu veranlasst, darüber nachzudenken, ob die RAG-Methode (Retrieval-Augmented Generation) noch notwendig ist. Manche Leute denken, dass RAG durch das lange Kontextmodell getötet wird, aber diese Ansicht wurde von vielen Forschern und Architekten widerlegt. Sie glauben, dass Datenstrukturen einerseits komplex sind, sich regelmäßig ändern und dass viele Daten wichtige Zeitdimensionen haben, die für LLM möglicherweise zu komplex sind. Andererseits ist es unrealistisch, alle riesigen heterogenen Daten von Unternehmen und Branchen in das Kontextfenster einzubeziehen. Die Kombination aus großen Modellen und KI-Datenbanken fügt professionelle, genaue und Echtzeitinformationen in das generative KI-System ein, wodurch Illusionen erheblich reduziert und die Praktikabilität des Systems verbessert werden. Gleichzeitig kann die datenzentrierte LLM-Methode auch die umfangreichen Datenverwaltungs- und Abfragefunktionen von KI-Datenbanken nutzen, um die Kosten für das Training und die Feinabstimmung großer Modelle erheblich zu senken und die Optimierung kleiner Stichproben in verschiedenen Szenarien des Modells zu unterstützen System. Zusammenfassend lässt sich sagen: Die Kombination aus großen Modellen und KI-Datenbanken senkt nicht nur die Kosten und erhöht die Effizienz großer Modelle, sondern macht Big Data auch wirklich intelligent. Nach mehreren Jahren der Entwicklung und Iteration ist MyScaleDB endlich Open Source RAG ermöglicht es LLM, Informationen aus umfangreichen Wissensdatenbanken genau zu extrahieren und in Echtzeit professionelle und aufschlussreiche Antworten zu generieren. Darüber hinaus hat sich auch die Vektordatenbank, die Kernfunktion des RAG-Systems, rasant entwickelt. Gemäß dem Designkonzept der Vektordatenbank können wir sie grob in drei Kategorien einteilen: dedizierte Vektordatenbank, Abrufsystem, das Schlüsselwörter und Vektoren kombiniert. und SQL-Vektordatenbank.
- Spezialisierte Vektordatenbanken, vertreten durch Pinecone/Weaviate/Milvus, sind von Anfang an für die Vektorabfrage konzipiert und gebaut, aber die allgemeine Datenverwaltungsfunktion ist schwach.
- Die von Elasticsearch/OpenSearch repräsentierten Schlüsselwort- und Vektor-Retrieval-Systeme werden aufgrund ihrer vollständigen Schlüsselwort-Retrieval-Funktionen häufig in der Produktion eingesetzt. Sie beanspruchen jedoch viele Systemressourcen und die gemeinsame Abfragegenauigkeit und Leistung von Schlüsselwörtern und Vektoren sind nicht zufriedenstellend . Die Leute bekommen, was sie wollen.
- SQL-Vektordatenbanken, dargestellt durch pgvector (Vektorsuch-Plug-in für PostgreSQL) und MyScale AI-Datenbank, basieren auf SQL und verfügen über leistungsstarke Datenverwaltungsfunktionen. Aufgrund der Nachteile der PostgreSQL-Zeilenspeicherung und der Einschränkungen von Vektoralgorithmen weist pgvector jedoch eine geringe Genauigkeit bei komplexen Vektorabfragen auf.
MyScale AI-Datenbank (MyScaleDB) basiert auf einer leistungsstarken SQL-Spaltenspeicherdatenbank, einem selbst entwickelten leistungsstarken Vektorindexalgorithmus mit hoher Datendichte und einer gemeinsamen Abfrage von SQL und Vektor zum Abrufen und Speichern. Die Engine wurde einer umfassenden Forschung, Entwicklung und Optimierung unterzogen. Sie ist das weltweit erste SQL-Vektordatenbankprodukt, dessen umfassende Leistung und Kosteneffizienz die einer dedizierten Vektordatenbank bei weitem übertreffen.
Dank der langfristigen Politur der SQL-Datenbank in Szenarios mit massiven strukturierten Daten unterstützt MyScaleDB sowohl massive Vektor- als auch strukturierte Daten
, einschließlich effizienter Speicherung und Speicherung mehrerer Datentypen wie Zeichenfolgen, JSON, Leerzeichen usw Zeitreihenabfrage und wird in naher Zukunft leistungsstarke invertierte Tabellen- und Schlüsselwortsuchfunktionen einführen, um die Genauigkeit des RAG-Systems weiter zu verbessern und Systeme wie Elasticsearch zu ersetzen.
Nach fast 6 Jahren Entwicklungszeit und mehreren Versionsiterationen ist MyScaleDB seit kurzem Open Source. Alle Entwickler und Unternehmensbenutzer sind herzlich eingeladen, auf GitHub zu spielen und eine neue Möglichkeit zu eröffnen, SQL zum Erstellen von KI-Anwendungen auf Produktionsebene zu nutzen! Projektadresse: https://github.com/myscale/myscaledbVollständig kompatibel mit SQL, verbessert die Genauigkeit und senkt die KostenMit Hilfe vollständiger SQL-Datenverwaltungsfunktionen leistungsstark und effizient Mit strukturierten, vektoriellen und heterogenen Datenspeicher- und Abfragefunktionen wird MyScaleDB voraussichtlich die erste KI-Datenbank sein, die wirklich auf große Modelle und Big Data ausgerichtet ist. Native Kompatibilität von SQL und VektorenSeit der Geburt von SQL vor einem halben Jahrhundert nimmt die sich ständig weiterentwickelnde SQL-Datenbank trotz der Wellen von NoSQL, Big Data usw. immer noch die Mehrheit ein des Datenmanagement-Marktanteils haben sogar Retrieval- und Big-Data-Systeme wie Elasticsearch und Spark nach und nach SQL-Schnittstellen unterstützt. Obwohl dedizierte Vektordatenbanken optimiert und Systeme für Vektoren entwickelt wurden, mangelt es ihren Abfrageschnittstellen in der Regel an Standardisierung und sie verfügen nicht über erweiterte Abfragesprachen. Dies führt zu schwachen Generalisierungsfähigkeiten der Schnittstelle. Beispielsweise umfasst die Abfrageschnittstelle von Pinecone nicht einmal die Angabe der abzurufenden Felder, geschweige denn allgemeine Datenbankfunktionen wie Paging und Aggregation. Die schwache Generalisierungsfähigkeit der Schnittstelle führt dazu, dass sie sich häufig ändert, was die Lernkosten erhöht. Das MyScale-Team ist davon überzeugt, dass das systematisch optimierte SQL- und Vektorsystem die vollständige SQL-Unterstützung aufrechterhalten und gleichzeitig eine hohe Leistung beim Vektorabruf gewährleisten kann, und die Ergebnisse ihrer Open-Source-Evaluierung haben dies vollständig bewiesen.
In tatsächlichen komplexen KI-Anwendungsszenarien kann die Kombination von SQL und Vektoren die Flexibilität der Datenmodellierung erheblich erhöhen und den Entwicklungsprozess vereinfachen. Im Science Navigator-Projekt, das zwischen dem MyScale-Team und dem Beijing Institute of Scientific Intelligence kooperiert, wird MyScaleDB beispielsweise verwendet, um umfangreiche wissenschaftliche Literaturdaten abzurufen und intelligente Fragen zu beantworten. Es gibt mehr als 10 Haupt-SQL-Tabellenstrukturen, von denen viele etabliert sind Vektoren und invertierter Tabellenindex, und verwenden Sie den Primärschlüssel und den Fremdschlüssel, um die Zuordnung herzustellen. Bei tatsächlichen Abfragen umfasst das System auch gemeinsame Abfragen von strukturierten Daten, Vektor- und Schlüsselwortdaten sowie zugehörige Abfragen mehrerer Tabellen. Diese Modellierung und Korrelationen sind in einer dedizierten Vektordatenbank schwer zu erreichen, was auch zu einer langsamen Iteration des endgültigen Systems, ineffizienten Abfragen und schwieriger Wartung führt.
Schematische Darstellung der Haupttabellenstruktur von NScience Navigator (Spalten mit fett gedruckten Körpern erstellen Vektorindizes oder invertierte Indizes) Genauigkeit und Wirkung des Abrufs sind die größten Engpässe, die seine Umsetzung einschränken. Dies erfordert, dass die KI-Datenbank gemeinsame Abfragen von Struktur-, Vektor- und Schlüsselwortdaten effizient unterstützt, um die Abrufgenauigkeit umfassend zu verbessern. In einem Finanzszenario müssen Benutzer beispielsweise die Dokumentbibliothek „Wie hoch ist der Umsatz verschiedener globaler Geschäfte eines bestimmten Unternehmens im Jahr 2023?“, „Ein bestimmtes Unternehmen“, „2023“ und andere strukturierte Abfragen durchführen Metainformationen können von Vektoren nicht gut erfasst werden und spiegeln sich möglicherweise nicht einmal direkt im entsprechenden Absatz wider. Wenn Sie den Vektorabruf direkt für die gesamte Datenbank durchführen, erhalten Sie eine große Menge an Rauschinformationen und verringern die endgültige Genauigkeit des Systems. Andererseits können Firmenname, Jahr usw. normalerweise als Metainformationen des Dokuments abgerufen werden. Wir können WHERE Jahr=2023 UND Firma ILIKE „%%“ als Filterbedingung für die Vektorabfrage verwenden Genau lokalisieren. Es werden relevante Informationen erhalten, was die Zuverlässigkeit des Systems erheblich verbessert. In den Bereichen Finanzen, Fertigung, wissenschaftliche Forschung und anderen Szenarien hat das MyScale-Team die Leistungsfähigkeit heterogener Datenmodellierung und damit verbundener Abfragen beobachtet. In vielen Szenarien hat sich die Genauigkeit sogar von 60 %90 % verbessert. Obwohl traditionelle Datenbankprodukte im KI-Zeitalter nach und nach die Bedeutung von Vektorabfragen erkannt haben und damit begonnen haben, der Datenbank Vektorfunktionen hinzuzufügen, gibt es immer noch erhebliche Probleme mit der Genauigkeit ihrer gemeinsamen Abfragen. Wenn beispielsweise im Szenario der Filterabfrage das Filterverhältnis 0,1 beträgt, sinkt der QPS von Elasticsearch auf nur etwa 5, während die Abrufgenauigkeit von PostgresSQL (mit dem pgvector-Plug-in) bei der Filterung nur etwa 50 % beträgt Das Verhältnis beträgt 0,01, wodurch die Genauigkeit/Leistung der Abfrage stark eingeschränkt wird. Und MyScale verbraucht nur 36 % der Kosten von pgvector und 12 % der Kosten von ElasticSearch
und kann hohe Leistung und hohe PräzisionAbfragen in verschiedenen Szenarien mit unterschiedlichen Filterverhältnissen erreichen. 场 In unterschiedlichen Filterverhältnissen nutzt myscale niedrige Kosten, um eine hochpräzise und leistungsstarke Abfrage zu erreichen. Aufgrund der Bedeutung und hohen Aufmerksamkeit in großen Modellanwendungen ist das Gleichgewicht zwischen Leistung und Kosten in realen Szenen gewährleistet. Immer mehr Teams haben in den Vektordatenbank-Track investiert. Zunächst lag der Fokus aller auf der Verbesserung der QPS in reinen Vektorsuchszenarien, aber „reine Vektorsuche reicht bei weitem nicht aus“! In tatsächlichen Szenarien sind Datenmodellierung, Abfrageflexibilität und -genauigkeit sowie der Ausgleich von Datendichte, Abfrageleistung und Kosten wichtigere Themen. Im RAG-Szenario weist die reine Vektorabfrageleistung einen 10-fachen Überschuss auf, Vektoren belegen riesige Ressourcen, fehlende gemeinsame Abfragefunktionen, schlechte Leistung und Genauigkeit sind in aktuellen proprietären Vektordatenbanken oft die Norm. MyScaleDB setzt sich dafür ein, die umfassende Leistung von KI-Datenbanken in realen Szenarien mit großen Datenmengen zu verbessern. Der von ihm eingeführte MyScale Vector Database Benchmark ist auch der erste in der Branche, der die umfassende Leistung und Kosteneffizienz gängiger Vektordatenbanksysteme in verschiedenen Abfragen vergleicht Szenarien mit einer Skala von fünf Millionen Vektoren, Open-Source-Bewertungssystem, jeder ist willkommen, aufmerksam zu sein und Probleme anzusprechen. Das MyScale-Team sagte, dass es in realen Anwendungsszenarien noch viel Raum für die Optimierung der KI-Datenbank gebe und hoffe auch, das Produkt weiter zu verbessern und das Bewertungssystem in der Praxis zu verbessern. MyScale Vector Database Benchmark-Projektadresse: https://github.com/myscale/vector-db-benchmarkAusblick: Großes Modell + Big-Data-Agentenplattform unterstützt durch KI-DatenbankMaschinelles Lernen + Big Data haben den Erfolg des Internets und der vorherigen Generation von Informationssystemen vorangetrieben. Im Zeitalter der großen Modelle ist das MyScale-Team auch bestrebt, eine neue Generation von Lösungen für große Modelle und große Daten vorzuschlagen. Mit Hochleistungs-SQL + Vektordatenbank als solider Unterstützung bietet MyScaleDB die Schlüsselfunktionen der Datenverarbeitung im großen Maßstab, der Wissensabfrage, der Beobachtbarkeit, der Datenanalyse und des Lernens kleiner Stichproben, baut einen geschlossenen KI- und Datenkreislauf auf und wird zum next A Generierung großer Modelle + die wichtigste Grundlage der Big-Data-Agentenplattform
. Das MyScale-Team hat bereits die Implementierung dieser Lösung in der wissenschaftlichen Forschung, im Finanzwesen, in der Industrie, in der Medizin und in anderen Bereichen untersucht. Mit der rasanten Entwicklung der Technologie wird erwartet, dass in den nächsten 5 bis 10 Jahren ein gewisser Sinn für allgemeine künstliche Intelligenz (AGI) entsteht. Bei diesem Thema kommen wir nicht umhin zu denken: Ist ein großes Modell nötig, das statisch, virtuell und mit Menschen konkurrenzfähig ist, oder gibt es eine andere, umfassendere Lösung? Daten sind zweifellos eine wichtige Verbindung zwischen großen Modellen, der Welt und den Benutzern. Die Vision des MyScale-Teams besteht darin, große Modelle und Big Data organisch zu kombinieren, um ein KI-System zu schaffen, das professioneller, in Echtzeit und effizienter in der Zusammenarbeit ist voller menschlicher Wärme und Wert.
Das obige ist der detaillierte Inhalt vonLanger Text kann RAG nicht töten: SQL+-Vektor steuert große Modelle und das neue Paradigma von Big Data, die MyScale AI-Datenbank ist offiziell Open Source. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!