
Heim >Technologie-Peripheriegeräte >KI >Erkundung der Grenzen von Agenten: AgentQuest, ein modulares Benchmark-Framework zur umfassenden Messung und Verbesserung der Leistung großer Sprachmodellagenten
Erkundung der Grenzen von Agenten: AgentQuest, ein modulares Benchmark-Framework zur umfassenden Messung und Verbesserung der Leistung großer Sprachmodellagenten

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2024-04-11 20:52:211418Durchsuche
Basierend auf der kontinuierlichen Optimierung großer Modelle haben LLM-Agenten – diese leistungsstarken algorithmischen Einheiten – das Potenzial gezeigt, komplexe mehrstufige Argumentationsaufgaben zu lösen. Von der Verarbeitung natürlicher Sprache bis hin zum Deep Learning rücken LLM-Agenten nach und nach in den Fokus von Forschung und Industrie. Sie können nicht nur menschliche Sprache verstehen und generieren, sondern auch Strategien formulieren, Aufgaben in verschiedenen Umgebungen ausführen und sogar API-Aufrufe und Codierung zum Erstellen verwenden Lösungen.
In diesem Zusammenhang ist der Vorschlag des AgentQuest-Frameworks ein Meilenstein. Es bietet nicht nur eine modulare Benchmarking-Plattform für die Bewertung und den Fortschritt von LLM-Agenten, sondern bietet durch seine einfach zu erweiternde API auch eine Plattform für die Forschung „Personal“ bietet ein leistungsstarkes Tool, um die Leistung dieser Agenten auf einer detaillierteren Ebene zu verfolgen und zu verbessern. Der Kern von AgentQuest liegt in seinen innovativen Bewertungsindikatoren – Fortschrittsrate und Wiederholungsrate –, die das Verhaltensmuster des Agenten bei der Lösung von Aufgaben aufdecken und so die Optimierung und Anpassung der Architektur steuern können.
„AgentQuest: A Modular Benchmark Framework to Measure Progress and Improve LLM Agents“ wurde von einem vielfältigen Forschungsteam von NEC European Laboratories, Politecnico di Torino und der Deutschen Universität San Cyril y Medo geschrieben. Dieses Papier wird auf dem nordamerikanischen Kapitel der Konferenz der Association for Computational Linguistics 2024 (NAACL-HLT 2024) vorgestellt, was zeigt, dass die Forschungsergebnisse des Teams auf dem Gebiet der menschlichen Sprachtechnologie von Fachkollegen anerkannt wurden, was nicht nur den Wert darstellt des AgentQuest-Frameworks Die Anerkennung ist auch eine Bestätigung des zukünftigen Entwicklungspotenzials von LLM-Agenten.
Als Tool zum Messen und Verbessern der Fähigkeiten von LLM-Agenten (Large Language Model) besteht der Hauptbeitrag des AgentQuest-Frameworks darin, eine modulare und skalierbare Benchmarking-Plattform bereitzustellen. Diese Plattform kann nicht nur die Leistung eines Agenten bei einer bestimmten Aufgabe bewerten, sondern auch das Verhaltensmuster des Agenten bei der Lösung des Problems aufdecken, indem sie das Verhaltensmuster des Agenten bei der Lösung des Problems zeigt. Der Vorteil von AgentQuest ist seine Flexibilität und Offenheit, die es Forschern ermöglicht, Benchmarks an ihre Bedürfnisse anzupassen und so die Entwicklung der LLM-Agententechnologie voranzutreiben.
Übersicht über das AgentQuest-Framework
Das AgentQuest-Framework ist ein innovatives Forschungstool, das entwickelt wurde, um die Leistung von LLM-Agenten (Large-Scale Language Model) zu messen und zu verbessern. Es ermöglicht Forschern, den Fortschritt eines Agenten bei der Ausführung komplexer Aufgaben systematisch zu verfolgen und potenzielle Bereiche für Verbesserungen zu identifizieren, indem es eine modulare Reihe von Benchmarks und Bewertungsmetriken bereitstellt.
AgentQuest ist ein modulares Framework, das mehrere Benchmarks und Agentenarchitekturen unterstützt. Es führt zwei neue Metriken ein – Fortschrittsrate und Wiederholungsrate –, um das Verhalten von Agentenarchitekturen zu bewerten. Dieses Framework definiert eine Standardschnittstelle zum Verbinden beliebiger Agentenarchitekturen mit einer Vielzahl von Benchmarks und zur Berechnung von Fortschritts- und Wiederholungsraten daraus.
In AgentQuest sind vier Benchmark-Tests enthalten: ALFWorld, Lateral Thinking Puzzles, Mastermind und Numerical Solitude. Darüber hinaus führt AgentQuest auch neue Tests ein. Sie können ganz einfach zusätzliche Benchmarks hinzufügen, ohne Änderungen an den getesteten Agenten vorzunehmen.
 Bilder
Bilder
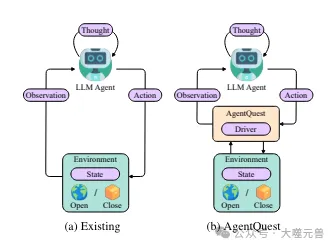
Abbildung 1: Übersicht über die grundlegende Interaktion von Agenten im aktuellen Framework AgentQuest. AgentQuest definiert eine gemeinsame Schnittstelle für die Interaktion mit Benchmarks und die Berechnung von Fortschrittsmetriken, was das Hinzufügen neuer Benchmarks vereinfacht und es Forschern ermöglicht, ihre Agentenarchitekturen zu bewerten und zu testen.
Grundlegende Zusammensetzung und Funktionalität
Der Kern des AgentQuest-Frameworks ist sein modularer Aufbau, der es Forschern ermöglicht, Benchmarks nach Bedarf hinzuzufügen oder zu ändern. Diese Flexibilität wird durch die Aufteilung von Benchmarks und Bewertungsmetriken in unabhängige Module erreicht, die jeweils unabhängig voneinander entwickelt und optimiert werden können. Zu den Hauptkomponenten des Frameworks gehören:
Benchmark-Modul: Dies sind vordefinierte Aufgaben, die der Agent ausführen muss. Sie reichen von einfachen Wortspielen bis hin zu komplexen Logikrätseln.
Bewertungsindikatormodul: Bietet eine Reihe von Tools zur Quantifizierung der Agentenleistung, wie z. B. Fortschrittsrate und Wiederholungsrate. Diese Indikatoren helfen Forschern, das Verhaltensmuster von Agenten bei Aufgaben zu verstehen.
API-Schnittstelle: Ermöglicht Forschern die Verbindung ihrer eigenen Agentenarchitekturen mit dem AgentQuest-Framework sowie die Interaktion mit externen Datenquellen und Diensten.
Die Bedeutung modularer Benchmarks und Metriken
Ein wesentlicher Vorteil modularer Benchmarks besteht darin, dass sie eine standardisierte Möglichkeit bieten, die Leistung verschiedener Agenten zu bewerten. Dies bedeutet, dass Forscher Ergebnisse verschiedener Wirkstoffe unter denselben Bedingungen vergleichen können, um Konsistenz und Vergleichbarkeit der Ergebnisse sicherzustellen. Darüber hinaus ermöglicht der modulare Aufbau den Forschern auch, Benchmarks an die Bedürfnisse spezifischer Studien anzupassen, was in herkömmlichen Benchmarking-Frameworks oft schwierig zu erreichen ist.
Bewertungsmetriken sind ebenso wichtig, da sie tiefe Einblicke in die Leistung des Agenten liefern. Beispielsweise kann die Fortschrittsrate zeigen, wie effizient ein Agent eine Aufgabe löst, während die Wiederholungsrate Aufschluss darüber gibt, ob ein Agent bei bestimmten Schritten in Wiederholungen stecken bleibt, was darauf hindeuten könnte, dass der Entscheidungsprozess verbessert werden muss.
Erweiterbarkeit von AgentQuest
Die API-Schnittstelle von AgentQuest ist der Schlüssel zu seiner Skalierbarkeit. Über die API können Forscher AgentQuest problemlos in bestehende Forschungsabläufe integrieren, sei es durch das Hinzufügen neuer Benchmarks, Bewertungsmetriken oder die Verbindung mit externen Datenquellen und Diensten. Diese Skalierbarkeit beschleunigt nicht nur den iterativen Prozess der Forschung, sondern fördert auch die interdisziplinäre Zusammenarbeit, da Experten aus verschiedenen Bereichen mithilfe des AgentQuest-Frameworks zusammenarbeiten können, um gemeinsame Forschungsfragen zu lösen.
Das AgentQuest-Framework bietet durch seine modularen Benchmarking- und Bewertungsmetriken und die Erweiterbarkeit durch APIs eine leistungsstarke Plattform für die Forschung und Entwicklung von LLM-Agenten. Es fördert nicht nur die Standardisierung und Reproduzierbarkeit der Forschung, sondern ebnet auch den Weg für zukünftige Innovationen und die Zusammenarbeit intelligenter Agenten.
Benchmarking- und Bewertungsmetriken
Im AgentQuest-Framework ist Benchmarking eine Schlüsselkomponente zur Bewertung der Leistung von LLM-Agenten. Diese Tests bieten nicht nur eine standardisierte Umgebung zum Vergleich der Fähigkeiten verschiedener Agenten, sondern können auch die Verhaltensmuster von Agenten bei der Lösung spezifischer Probleme aufdecken.
AgentQuest stellt eine einzige einheitliche Python-Schnittstelle bereit, nämlich den Treiber und zwei Klassen, die die Komponenten der Agent-Umgebung-Interaktion (d. h. Beobachtungen und Aktionen) widerspiegeln. Die Beobachtungsklasse verfügt über zwei erforderliche Eigenschaften: (i) Ausgabe, eine Zeichenfolge, die Informationen über den Zustand der Umgebung meldet; (ii) Abschluss, eine boolesche Variable, die angibt, ob die letzte Aufgabe derzeit abgeschlossen ist. Aktionsklassen haben ein erforderliches Attribut, den Aktionswert. Dies ist die Zeichenfolge, die direkt vom Agenten ausgegeben wird. Sobald es verarbeitet und der Umgebung bereitgestellt wird, löst es Veränderungen in der Umgebung aus. Um Interaktionen anzupassen, können Entwickler optionale Eigenschaften definieren.
Mastermind Benchmark
Mastermind ist ein klassisches Logikspiel, bei dem Spieler einen versteckten Farbcode erraten müssen. Im AgentQuest-Framework wird dieses Spiel als einer der Benchmarks verwendet, bei dem der Agent die Aufgabe hat, durch eine Reihe von Vermutungen den richtigen Code zu ermitteln. Nach jeder Vermutung gibt die Umgebung eine Rückmeldung, die dem Agenten mitteilt, wie viele Farben richtig waren, sich aber an falschen Positionen befanden, und wie viele sowohl in den Farben als auch in den Positionen richtig waren. Dieser Vorgang wird fortgesetzt, bis der Agent den richtigen Code errät oder eine voreingestellte Anzahl von Schritten erreicht.
 Abbildung 2: Hier stellen wir ein Beispiel für die Implementierung von Interaktion durch Mastermind vor.
Abbildung 2: Hier stellen wir ein Beispiel für die Implementierung von Interaktion durch Mastermind vor.
Sudoku-Benchmark
Sudoku ist ein weiteres beliebtes Logikrätsel, bei dem die Spieler Zahlen in ein 9x9-Raster eintragen müssen, sodass in jeder Zeile, jeder Spalte und jedem 3x3-Untergitter keine Zahlen wiederholt werden. Im AgentQuest-Framework wird Sudoku als Benchmark verwendet, um die Fähigkeiten eines Agenten im räumlichen Denken und Planen zu bewerten. Der Agent muss effiziente Zahlenfüllstrategien entwickeln und das Rätsel innerhalb einer begrenzten Anzahl von Zügen lösen.
Bewertungsmetriken: Fortschrittsrate und Wiederholungsrate
AgentQuest führt zwei neue Bewertungsmetriken ein: Fortschrittsrate (PR) und Wiederholungsrate (RR). Die Fortschrittsrate ist ein Wert zwischen 0 und 1, der den Fortschritt des Agenten bei der Erledigung einer Aufgabe misst. Sie wird berechnet, indem die Anzahl der vom Agenten erreichten Meilensteine durch die Gesamtzahl der Meilensteine dividiert wird. Wenn der Agent beispielsweise im Mastermind-Spiel von insgesamt vier Vermutungen zwei richtige Farben und Orte errät, beträgt die Fortschrittsrate 0,5.
Die Wiederholungsrate misst die Tendenz eines Agenten, während der Ausführung einer Aufgabe die gleichen oder ähnliche Aktionen zu wiederholen. Bei der Berechnung der Wiederholungsrate werden alle vorherigen Aktionen des Agenten berücksichtigt und anhand einer Ähnlichkeitsfunktion ermittelt, ob die aktuelle Aktion früheren Aktionen ähnlich ist. Die Wiederholungsrate wird berechnet, indem die Anzahl der Wiederholungen durch die Gesamtzahl der Wiederholungen (abzüglich des ersten Schritts) geteilt wird.
Bewerten und verbessern Sie die Leistung von LLM-Agenten durch Metriken
Diese Metriken bieten Forschern ein leistungsstarkes Tool zur Analyse und Verbesserung der Leistung von LLM-Agenten. Durch die Beobachtung der Fortschrittsraten können Forscher verstehen, wie effizient ein Agent ein Problem löst, und mögliche Engpässe identifizieren. Gleichzeitig kann die Analyse der Wiederholungsraten mögliche Probleme im Entscheidungsprozess des Agenten aufdecken, wie etwa eine übermäßige Abhängigkeit von bestimmten Strategien oder mangelnde Innovation.
 Tabelle 1: Übersicht der in AgentQuest verfügbaren Benchmarks.
Tabelle 1: Übersicht der in AgentQuest verfügbaren Benchmarks.
Im Allgemeinen bieten die Benchmark-Test- und Bewertungsindikatoren im AgentQuest-Framework ein umfassendes Bewertungssystem für die Entwicklung von LLM-Agenten. Mithilfe dieser Tools können Forscher nicht nur die aktuelle Leistung von Agenten bewerten, sondern auch künftige Verbesserungsrichtungen vorgeben und so die Anwendung und Entwicklung von LLM-Agenten bei verschiedenen komplexen Aufgaben fördern.
Anwendungsfälle von AgentQuest
Die tatsächlichen Anwendungsfälle des AgentQuest-Frameworks bieten ein detailliertes Verständnis seiner Funktionen und Auswirkungen. Durch Mastermind und andere Benchmark-Tests können wir die Leistung von LLM-Agenten in verschiedenen Szenarien beobachten und analysieren, wie ihre Leistung durch spezifische Strategien verbessert werden kann.
Mastermind-Anwendungsfälle
Im Mastermind-Spiel wird das AgentQuest-Framework verwendet, um die logische Denkfähigkeit des Agenten zu bewerten. Der Agent muss einen versteckten Code erraten, der aus Zahlen besteht, und nach jedem Raten gibt das System eine Rückmeldung mit der Nummer und dem Ort der richtigen Nummer. Durch diesen Prozess lernt der Agent, seine Schätzstrategie basierend auf dem Feedback anzupassen, um seine Ziele effizienter zu erreichen.
In praktischen Anwendungen ist die anfängliche Leistung des Agenten möglicherweise nicht ideal und dieselben oder ähnliche Vermutungen werden häufig wiederholt, was zu einer hohen Wiederholungsrate führt. Durch die Analyse von Daten zu Fortschritten und Wiederholungsraten können Forscher jedoch Mängel im Entscheidungsprozess des Agenten erkennen und Maßnahmen zu dessen Verbesserung ergreifen. Durch die Einführung einer Gedächtniskomponente kann sich der Agent beispielsweise an frühere Vermutungen erinnern und die Wiederholung wirkungsloser Versuche vermeiden, wodurch Effizienz und Genauigkeit verbessert werden.
Anwendungsfälle anderer Benchmarks
Neben Mastermind enthält AgentQuest auch andere Benchmarks wie Sudoku, Wortspiele und Logikrätsel. Bei diesen Tests wird die Leistung des Agenten auch durch Metriken zur Fortschrittsrate und Wiederholungsrate beeinflusst. Beim Sudoku-Test muss der Agent beispielsweise ein 9x9-Raster ausfüllen, damit sich die Zahlen in jeder Zeile, jeder Spalte und jedem 3x3-Untergitter nicht wiederholen. Dies erfordert, dass der Agent über räumliche Denkfähigkeiten und strategische Planungsfähigkeiten verfügt.
Bei diesen Tests kann der Agent auf unterschiedliche Herausforderungen stoßen. Einige Agenten verfügen möglicherweise über ein hervorragendes räumliches Denken, verfügen jedoch nicht über ausreichende Strategieplanung. Durch das detaillierte Feedback des AgentQuest-Frameworks können Forscher Problembereiche gezielt identifizieren und die Gesamtleistung des Agenten durch Algorithmenoptimierung oder Anpassung von Trainingsmethoden verbessern.
Der Einfluss von Speicherkomponenten
Das Hinzufügen von Speicherkomponenten hat erhebliche Auswirkungen auf die Leistung des Agenten. Im Mastermind-Test konnte der Agent nach dem Hinzufügen der Gedächtniskomponente die Wiederholung ungültiger Vermutungen vermeiden und so die Wiederholungsrate deutlich reduzieren. Dadurch erhöht sich nicht nur die Geschwindigkeit, mit der der Agent Probleme löst, sondern auch die Erfolgsquote. Darüber hinaus ermöglicht die Gedächtniskomponente dem Agenten, bei ähnlichen Problemen schneller zu lernen und sich anzupassen, wodurch seine Lerneffizienz langfristig verbessert wird.
Insgesamt bietet das AgentQuest-Framework ein leistungsstarkes Tool zur Leistungsbewertung und -verbesserung von LLM-Agenten, indem es modulare Benchmarking- und Bewertungsmetriken bereitstellt. Durch die Analyse tatsächlicher Anwendungsfälle können wir erkennen, dass die Leistung des Agenten durch eine Anpassung der Strategie und die Einführung neuer Komponenten, wie beispielsweise Speichermodule, deutlich verbessert werden kann.
Experimenteller Aufbau und Ergebnisanalyse
Im experimentellen Aufbau des AgentQuest-Frameworks haben die Forscher eine Referenzarchitektur übernommen, die auf einem vorgefertigten Chat-Agenten basiert, der von einem großen Sprachmodell (LLM) wie GPT-4 gesteuert wird. Diese Architektur wurde gewählt, weil sie intuitiv, leicht erweiterbar und Open Source ist, was es Forschern ermöglicht, verschiedene Agentenstrategien einfach zu integrieren und zu testen.
 Bilder
Bilder
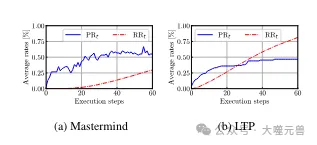
Abbildung 4: Durchschnittliche Fortschrittsrate PRt und Wiederholungsrate RRt für Mastermind und LTP. Mastermind: RRt ist zunächst niedrig, wird aber nach Schritt 22 ansteigen, während der Fortschritt ebenfalls bei 55 % stoppt. LTP: Anfänglich ermöglicht eine höhere RRt den Agenten, durch kleine Änderungen erfolgreich zu sein, aber später flacht dies ab.
Experimenteller Aufbau
Der experimentelle Aufbau umfasst mehrere Benchmark-Tests wie Mastermind und ALFWorld. Jeder Test dient dazu, die Leistung des Agenten in einem bestimmten Bereich zu bewerten. Die maximale Anzahl der Ausführungsschritte wird im Experiment festgelegt, normalerweise 60 Schritte, um die Anzahl der Versuche zu begrenzen, die der Agent bei der Lösung des Problems unternehmen kann. Diese Einschränkung simuliert die Situation begrenzter Ressourcen in der realen Welt und zwingt den Agenten, in begrenzten Versuchen die effektivste Lösung zu finden.
Experimentelle Ergebnisanalyse
Im Mastermind-Benchmark-Test zeigen die experimentellen Ergebnisse, dass ohne Gedächtniskomponente die Wiederholungsrate des Agenten relativ hoch ist und auch die Fortschrittsrate begrenzt ist. Dies zeigt, dass Agenten beim Versuch, Probleme zu lösen, dazu neigen, ungültige Vermutungen zu wiederholen. Mit der Einführung der Memory-Komponente konnte jedoch die Leistung des Agenten deutlich verbessert werden, wobei die Erfolgsquote von 47 % auf 60 % stieg und die Wiederholungsrate auf 0 % sank. Dies zeigt, dass die Speicherkomponente entscheidend für die Verbesserung der Effizienz und Genauigkeit des Agenten ist.
 Bilder
Bilder
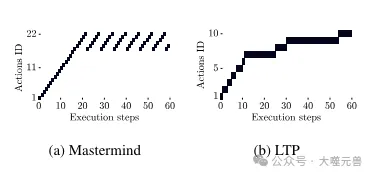
Abbildung 5: Beispiel für wiederholte Vorgänge in Mastermind und LTP. Mastermind: Beginnt mit einer Reihe einzigartiger Bewegungen, bleibt dann aber dabei stecken, immer wieder dieselben Bewegungen zu wiederholen. LTP: Wiederholte Aktionen sind kleine Variationen desselben Problems, die zu Fortschritten führen.
Im ALFWorld-Benchmark muss der Agent eine Textwelt erkunden, um Objekte zu lokalisieren. Experimentelle Ergebnisse zeigen, dass der Agent zwar die Aktionswiederholungen beim Erkunden des Lösungsraums einschränkte (RR60 = 6 %), es ihm jedoch nicht gelang, alle Spiele zu lösen (PR60 = 74 %). Dieser Unterschied kann auf die Tatsache zurückzuführen sein, dass der Agent beim Erkennen von Objekten mehr Erkundungsschritte benötigt. Bei der Erweiterung der Benchmark-Laufzeit auf 120 Schritte verbesserten sich sowohl die Erfolgs- als auch die Fortschrittsraten, was die Nützlichkeit von AgentQuest beim Verständnis von Agentenfehlern weiter bestätigt.
Anpassung der Agentenarchitektur
Gemäß den Indikatoren von AgentQuest können Forscher die Agentenarchitektur anpassen. Wenn Sie beispielsweise feststellen, dass sich ein Agent bei einem bestimmten Benchmark häufig wiederholt, muss sein Entscheidungsalgorithmus möglicherweise verbessert werden, um die Wiederholung ineffektiver Versuche zu vermeiden. Wenn die Fortschrittsrate niedrig ist, muss der Lernprozess des Agenten möglicherweise optimiert werden, um sich schneller an die Umgebung anzupassen und Lösungen für Probleme zu finden.
Der vom AgentQuest-Framework bereitgestellte experimentelle Aufbau und die Bewertungsmetriken bieten detaillierte Einblicke in die Leistung von LLM-Agenten. Durch die Analyse experimenteller Ergebnisse können Forscher die Stärken und Schwächen eines Agenten identifizieren und die Architektur des Agenten entsprechend anpassen, um seine Leistung bei einer Vielzahl von Aufgaben zu verbessern.
Diskussion und zukünftige Arbeit
Der Vorschlag des AgentQuest-Frameworks hat einen neuen Weg für die Forschung und Entwicklung von LLM-Agenten (Large Language Model) eröffnet. Es bietet nicht nur eine systematische Methode zur Messung und Verbesserung der Leistung von LLM-Agenten, sondern fördert auch das tiefgreifende Verständnis der Forschungsgemeinschaft für das Agentenverhalten.
Die potenziellen Auswirkungen von AgentQuest auf die LLM-Agentenforschung
AgentQuest ermöglicht es Forschern, den Fortschritt und die Effizienz von LLM-Agenten bei bestimmten Aufgaben durch seine modularen Benchmarking- und Bewertungsmetriken genauer zu messen. Diese präzise Bewertungsfähigkeit ist entscheidend für die Entwicklung effizienterer und intelligenterer Agenten. Da LLM-Agenten zunehmend in verschiedenen Bereichen eingesetzt werden, vom Kundenservice bis zur Verarbeitung natürlicher Sprache, werden die von AgentQuest bereitgestellten detaillierten Analysetools Forschern dabei helfen, den Entscheidungsprozess des Agenten zu optimieren und seine Leistung in praktischen Anwendungen zu verbessern.
AgentQuests Rolle bei der Förderung von Transparenz und Fairness
Ein weiterer wichtiger Beitrag von AgentQuest besteht darin, die Transparenz der LLM-Agentenforschung zu erhöhen. Durch öffentliche Bewertungsmetriken und reproduzierbare Benchmarks fördert AgentQuest die Praxis der offenen Wissenschaft und macht Forschungsergebnisse einfacher verifizierbar und vergleichbar. Darüber hinaus ermöglicht der modulare Charakter von AgentQuest Forschern, Benchmarks anzupassen, was bedeutet, dass Tests für unterschiedliche Bedürfnisse und Kontexte konzipiert werden können und so Vielfalt und Inklusion in der Forschung gefördert werden.
Die zukünftige Entwicklung von AgentQuest und die möglichen Beiträge der Forschungsgemeinschaft
Aufgrund der Weiterentwicklung der Technologie wird erwartet, dass das AgentQuest-Framework weiterhin erweitert und verbessert wird. Durch die Hinzufügung neuer Benchmarks und Bewertungsindikatoren kann AgentQuest mehr Arten von Aufgaben und Szenarien abdecken und so eine umfassendere Perspektive für die Bewertung von LLM-Agenten bieten. Darüber hinaus kann AgentQuest mit der Weiterentwicklung der Technologie der künstlichen Intelligenz auch erweiterte Funktionen integrieren, beispielsweise die Möglichkeit, die Agentenarchitektur automatisch anzupassen, um eine effizientere Leistungsoptimierung zu erreichen.
Der Beitrag der Forschungsgemeinschaft zu AgentQuest ist ebenfalls ein integraler Bestandteil seiner Entwicklung. Der Open-Source-Charakter bedeutet, dass Forscher ihre Verbesserungen und Innovationen teilen können, was die Weiterentwicklung des AgentQuest-Frameworks beschleunigt. Gleichzeitig werden Rückmeldungen und praktische Erfahrungen aus der Forschungsgemeinschaft dazu beitragen, dass AgentQuest den Anforderungen praktischer Anwendungen besser gerecht wird und die Entwicklung der LLM-Agententechnologie vorantreibt.
Referenz: https://arxiv.org/abs/2404.06411
Das obige ist der detaillierte Inhalt vonErkundung der Grenzen von Agenten: AgentQuest, ein modulares Benchmark-Framework zur umfassenden Messung und Verbesserung der Leistung großer Sprachmodellagenten. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Das CSS-Box-Modell verstehen: In 5 Minuten verstehen, was das CSS-Box-Modell ist?
- So ändern Sie Python in die chinesische Version
- So lesen Sie Excel-Tabellendaten in Python
- So behalten Sie 2 Dezimalstellen in Python bei
- Verstehen Sie die Funktion der Subnetzmaskierung und ihre Bedeutung bei der Netzwerkplanung