
Heim >Technologie-Peripheriegeräte >KI >Große Modelle sind auch bei der Vorhersage von Zeitreihen sehr leistungsstark! Das chinesische Team aktiviert neue LLM-Funktionen und erreicht SOTA über traditionelle Modelle hinaus
Große Modelle sind auch bei der Vorhersage von Zeitreihen sehr leistungsstark! Das chinesische Team aktiviert neue LLM-Funktionen und erreicht SOTA über traditionelle Modelle hinaus

- PHPznach vorne
- 2024-04-11 09:43:20994Durchsuche
Das Potenzial großer Sprachmodelle wird gefördert –
Eine hochpräzise Zeitreihenvorhersage kann ohne Training großer Sprachmodelle erreicht werden und übertrifft alle herkömmlichen Zeitreihenmodelle.
Monash University, Ant und IBM Research haben gemeinsam ein allgemeines Framework entwickelt, das die Fähigkeit großer Sprachmodelle, Sequenzdaten über Modalitäten hinweg zu verarbeiten, erfolgreich förderte. Das Framework ist zu einer wichtigen technologischen Innovation geworden.

Die Vorhersage von Zeitreihen ist für die Entscheidungsfindung in typischen komplexen Systemen wie Städten, Energie, Transport, Fernerkundung usw. von Vorteil.
Seitdem wird erwartet, dass große Modelle Zeitreihen-/spatiotemporale Data-Mining-Methoden revolutionieren werden.
Universeller Rahmen für die Neuprogrammierung großer Sprachmodelle
Das Forschungsteam schlug einen allgemeinen Rahmen vor, um große Sprachmodelle einfach und ohne Schulung für die allgemeine Zeitreihenvorhersage zu verwenden.
Es werden hauptsächlich zwei Schlüsseltechnologien vorgeschlagen: Neuprogrammierung der Zeiteingabe;
Time-LLM verwendet zunächst Textprototypen (Textprototypen), um die eingegebenen Zeitdaten neu zu programmieren, und verwendet die Darstellung in natürlicher Sprache, um die semantischen Informationen der Zeitdaten darzustellen, wodurch zwei unterschiedliche Datenmodalitäten ausgerichtet werden, sodass keine großen Sprachmodelle erforderlich sind Jede Änderung, um die Informationen hinter einer anderen Datenmodalität zu verstehen. Gleichzeitig erfordert das große Sprachmodell keinen spezifischen Trainingsdatensatz, um die Informationen hinter verschiedenen Datenmodalitäten zu verstehen. Diese Methode verbessert nicht nur die Genauigkeit des Modells, sondern vereinfacht auch den Datenvorverarbeitungsprozess.
Um die eingegebenen Zeitreihendaten und die Analyse der entsprechenden Aufgaben besser handhaben zu können, schlug der Autor das Prompt-as-Prefix (PaP)-Paradigma vor. Dieses Paradigma aktiviert die Verarbeitungsfähigkeiten von LLM für zeitliche Aufgaben vollständig, indem vor der Darstellung zeitlicher Daten zusätzliche Kontextinformationen und Aufgabenanweisungen hinzugefügt werden. Diese Methode kann eine verfeinerte Analyse von Timing-Aufgaben ermöglichen und die Verarbeitungsfähigkeiten von LLM für Timing-Aufgaben vollständig aktivieren, indem zusätzliche Kontextinformationen und Aufgabenanweisungen vor der Timing-Datentabelle hinzugefügt werden.
Zu den Hauptbeiträgen gehören:
- Vorschlag für ein neues Konzept zur Neuprogrammierung großer Sprachmodelle für die Zeitanalyse ohne Änderung des Backbone-Sprachmodells.
- Schlagen Sie Time-LLM vor, ein allgemeines Framework zur Neuprogrammierung von Sprachmodellen, das darin besteht, zeitliche Eingabedaten in eine natürlichere Textprototypdarstellung umzuprogrammieren und den Eingabekontext mit deklarativen Hinweisen wie Domänenexpertenwissen und Aufgabenbeschreibungen zu erweitern, um LLM anzuleiten für effektives domänenübergreifendes Denken.

- Die Leistung bei Mainstream-Vorhersageaufgaben übertrifft durchweg die Leistung der besten vorhandenen Modelle, insbesondere in Szenarien mit wenigen und null Stichproben. Darüber hinaus ist Time-LLM in der Lage, eine höhere Leistung zu erzielen und gleichzeitig eine hervorragende Effizienz bei der Neuprogrammierung des Modells beizubehalten. Erschließen Sie das ungenutzte Potenzial von LLM für Zeitreihen und andere sequentielle Daten.
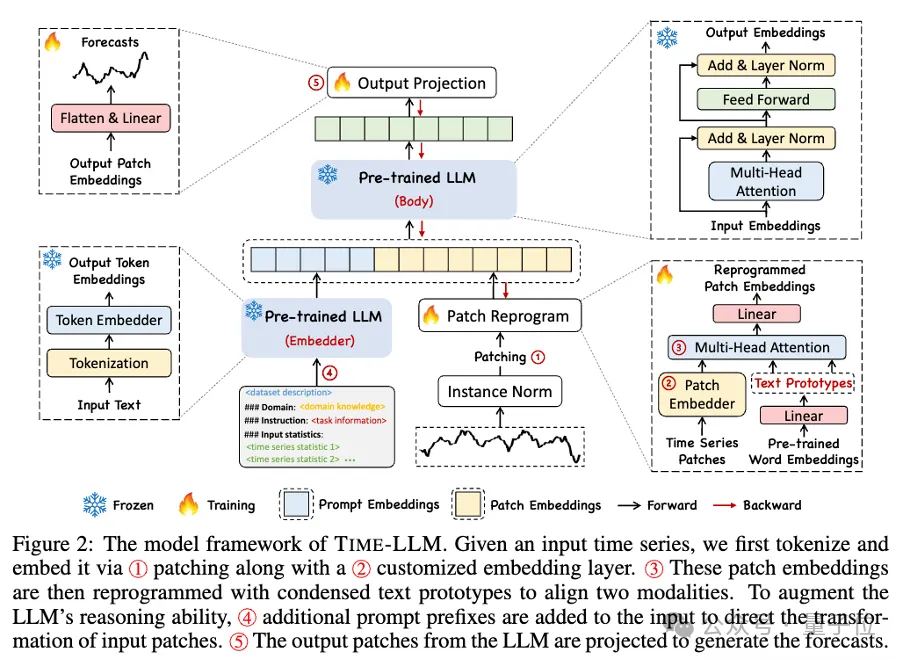
Wenn man sich dieses Framework genauer ansieht, werden zunächst die eingegebenen Zeitreihendaten zunächst durch RevIN normalisiert und dann in verschiedene Patches unterteilt und dem latenten Raum zugeordnet.
Es gibt erhebliche Unterschiede in den Ausdrucksmethoden zwischen Zeitreihendaten und Textdaten und sie gehören zu unterschiedlichen Modalitäten.
Zeitreihen können weder direkt bearbeitet noch verlustfrei in natürlicher Sprache beschrieben werden. Daher müssen wir zeitliche Eingabemerkmale an der Textdomäne natürlicher Sprache ausrichten.

Eine gängige Methode zur Ausrichtung verschiedener Modalitäten ist die Kreuzaufmerksamkeit, aber der inhärente Wortschatz von LLM ist sehr groß, so dass es unmöglich ist, zeitliche Merkmale direkt effektiv allen Wörtern zuzuordnen, und nicht alle Wörter stehen in Zusammenhang mit der Zeit. Sequenzen haben ausgerichtete semantische Beziehungen.
Um dieses Problem zu lösen, führt diese Arbeit eine lineare Kombination von Vokabeln durch, um Textprototypen zu erhalten. Die Anzahl der Textprototypen ist viel kleiner als die des ursprünglichen Vokabulars und die Kombination kann verwendet werden, um die sich ändernden Eigenschaften von Zeitreihendaten darzustellen .
Um die Fähigkeit von LLM bei bestimmten Timing-Aufgaben vollständig zu aktivieren, schlägt diese Arbeit ein Prompt-Prefixing-Paradigma vor.
Um es einfach auszudrücken: Einige Vorinformationen des Zeitreihendatensatzes werden in Form einer natürlichen Sprache als Präfix-Eingabeaufforderung an LLM weitergeleitet und die ausgerichteten Zeitreihenmerkmale werden an LLM gespleißt. Kann dies den Vorhersageeffekt verbessern? ?
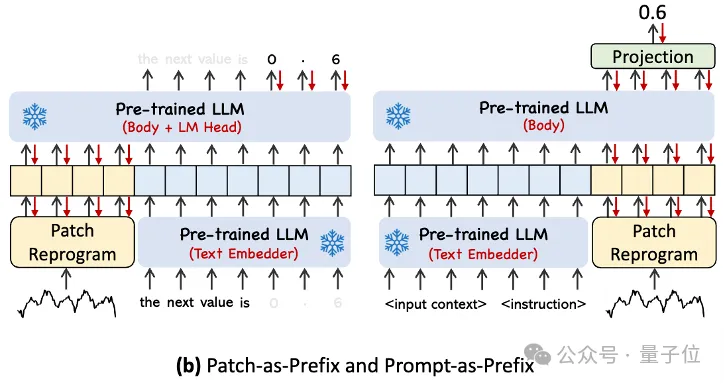
In der Praxis identifizierten die Autoren drei Schlüsselkomponenten für die Erstellung effektiver Eingabeaufforderungen:
Datensatzkontext; (2) Aufgabenanweisungen, die es LLM ermöglichen, sich an verschiedene nachgelagerte Aufgaben anzupassen, wie z. B. Trends, Verzögerungen; usw., wodurch LLM die Eigenschaften von Zeitreihendaten besser verstehen kann.

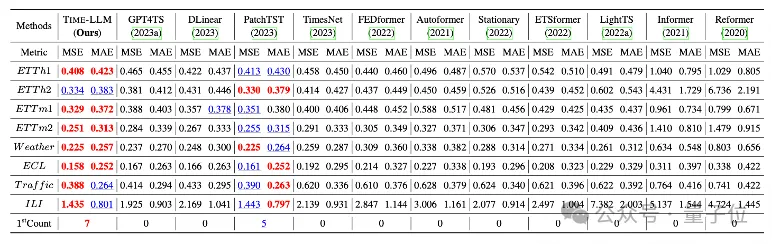
Das Team führte umfassende Tests an 8 klassischen öffentlichen Datensätzen für langfristige Vorhersagen durch.
Das Ergebnis ist, dass Time-LLM im Benchmark-Vergleich die bisherigen besten Ergebnisse auf diesem Gebiet deutlich übertrifft. Im Vergleich zu GPT4TS, das GPT-2 direkt verwendet, weist Time-LLM beispielsweise eine deutliche Verbesserung auf, was auf die Wirksamkeit dieser Methode hinweist .
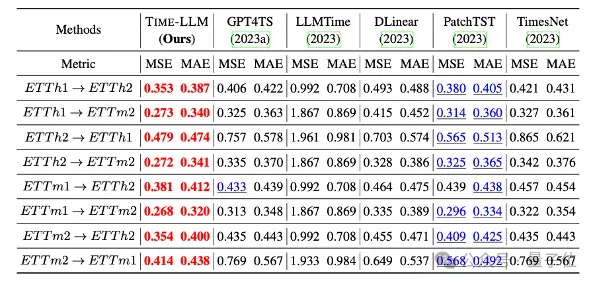
Darüber hinaus zeigt es auch eine starke Vorhersagefähigkeit in Zero-Shot-Szenarien.
Dieses Projekt wird von NextEvo unterstützt, der Forschungs- und Entwicklungsabteilung für KI-Innovation der Intelligent Engine Division der Ant Group.
Interessierte Freunde können auf den Link unten klicken, um mehr über das Papier zu erfahren~
Papier-Linkhttps://arxiv.org/abs/2310.01728.
Das obige ist der detaillierte Inhalt vonGroße Modelle sind auch bei der Vorhersage von Zeitreihen sehr leistungsstark! Das chinesische Team aktiviert neue LLM-Funktionen und erreicht SOTA über traditionelle Modelle hinaus. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Was ist ein Algorithmus für künstliche Intelligenz?
- Was sind die Entwicklungstrends der künstlichen Intelligenz?
- Die C-Sprache kann beim Aufrufen der Funktion in main keinen Bezeichner finden
- Der Einfluss künstlicher Intelligenz auf unser Leben
- Benchmarking von Bing Chat: Die kleine öffentliche Beta-„Konversations'-Funktion von Baidu Search, basierend auf dem Wenxin Yiyan-Sprachmodell