
Heim >Technologie-Peripheriegeräte >KI >Ist die Llama-Architektur GPT2 unterlegen? Magischer Token erhöht den Speicher um das Zehnfache?
Ist die Llama-Architektur GPT2 unterlegen? Magischer Token erhöht den Speicher um das Zehnfache?

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2024-04-10 15:13:131518Durchsuche
Wie viel menschliches Wissen kann ein LLM-Sprachmodell im Maßstab 7B speichern? Wie lässt sich dieser Wert quantifizieren? Wie wirken sich Unterschiede in der Trainingszeit und der Modellarchitektur auf diesen Wert aus? Welche Auswirkungen werden Gleitkommakomprimierungsquantisierung, MoE mit gemischten Expertenmodellen und Unterschiede in der Datenqualität (Enzyklopädiewissen vs. Internetmüll) auf die Wissenskapazität von LLM haben?
Die neueste Forschung „Language Model Physics Part 3.3: Scaling Laws of Knowledge“ von Zhu Zeyuan (Meta AI) und Li Yuanzhi (MBZUAI) nutzte umfangreiche Experimente (50.000 Aufgaben, insgesamt 4.200.000 GPU-Stunden), um 12 Gesetze zusammenzufassen Die Wissenskapazität von LLM unter verschiedenen Dateien bietet eine genauere Messmethode.

Der Autor wies zunächst darauf hin, dass es unrealistisch sei, das Skalierungsgesetz von LLM anhand der Leistung des Open-Source-Modells im Benchmark-Datensatz (Benchmark) zu messen. Beispielsweise schneidet LLaMA-70B beim Wissensdatensatz 30 % besser ab als LLaMA-7B. Dies bedeutet nicht, dass eine Erweiterung des Modells um das Zehnfache die Kapazität nur um 30 % erhöhen kann. Wenn ein Modell mithilfe von Netzwerkdaten trainiert wird, ist es außerdem schwierig, die darin enthaltene Gesamtmenge an Wissen abzuschätzen.
Ein weiteres Beispiel: Wenn wir die Qualität der Mistral- und Llama-Modelle vergleichen: Liegt der Unterschied an deren unterschiedlichen Modellarchitekturen oder an der unterschiedlichen Vorbereitung ihrer Trainingsdaten?
Basierend auf den obigen Überlegungen übernimmt der Autor die Kernidee seiner Aufsatzreihe „Language Model Physics“, die darin besteht, künstlich synthetisierte Daten zu erstellen und die Wissensbits in den Daten durch Kontrolle der Menge und streng zu kontrollieren Art des Wissens in den Daten). Gleichzeitig verwendet der Autor LLMs unterschiedlicher Größe und Architektur, um auf synthetischen Daten zu trainieren, und gibt mathematische Definitionen an, um genau zu berechnen, wie viele Wissensbits das trainierte Modell aus den Daten gelernt hat. ??
 Für diese Studie sagten einige Leute, dass diese Richtung vernünftig erscheint. Wir können das Skalierungsgesetz auf sehr wissenschaftliche Weise analysieren.
Für diese Studie sagten einige Leute, dass diese Richtung vernünftig erscheint. Wir können das Skalierungsgesetz auf sehr wissenschaftliche Weise analysieren.
- Manche Leute glauben auch, dass diese Forschung das Skalierungsgesetz auf eine andere Ebene hebt. Auf jeden Fall ein Pflichtlektüre für Praktiker.
- Forschungsüberblick
Die Autoren untersuchten drei Arten synthetischer Daten: bioS, bioR, bioD. bioS ist eine Biografie, die mit englischen Vorlagen geschrieben wurde, bioR ist eine Biografie, die mit Hilfe des LlaMA2-Modells geschrieben wurde (insgesamt 22 GB), bioD ist eine Art virtuelle Wissensdaten, die die Details weiter steuern können (z. B. die Länge des Wissens usw.). Der Wortschatz kann kontrolliert werden. Warten Sie auf Details). Der Autor
konzentriert sich auf die Sprachmodellarchitektur basierend auf GPT2, LlaMA und Mistral, wobei GPT2 die aktualisierte Rotary Position Embedding (RoPE)-Technologie verwendet. 
Das Bild links zeigt Skalierungsgesetze mit ausreichender Trainingszeit, und das Bild rechts zeigt Skalierungsgesetze mit unzureichender Trainingszeit
Abbildung 1 oben skizziert kurz die ersten 5 vom Autor vorgeschlagenen Gesetze , wobei links/rechts jeweils „Training“ entsprechen. Die beiden Situationen „ausreichende Zeit“ und „unzureichende Trainingszeit“ entsprechen jeweils allgemeinem Wissen (zum Beispiel ist Peking die Hauptstadt Chinas) und weniger allgemeinem Wissen (zum Beispiel Die Abteilung für Physik der Tsinghua-Universität wurde 1926 gegründet.
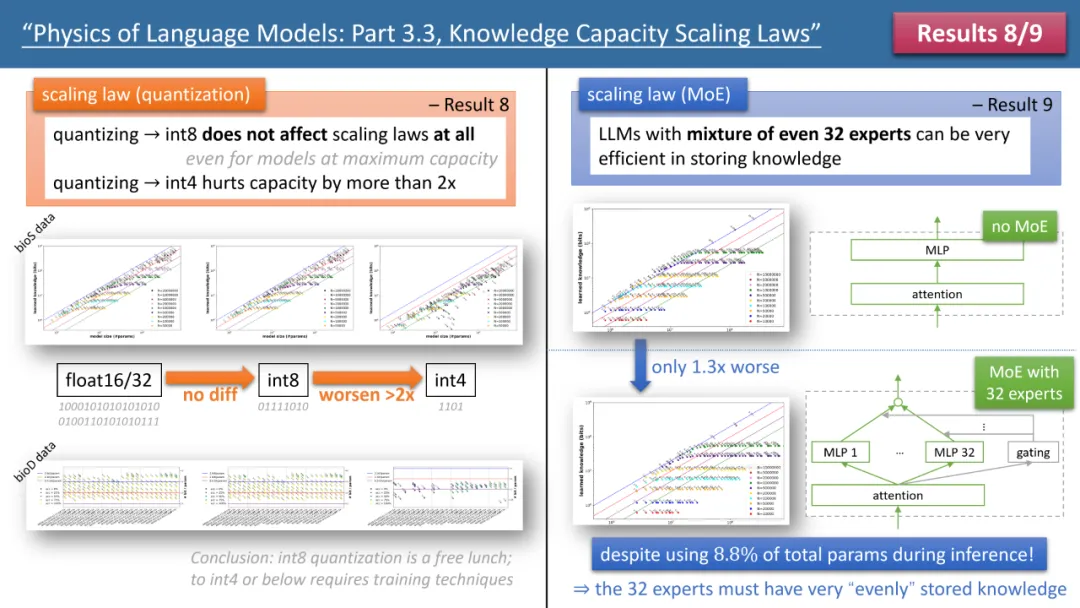
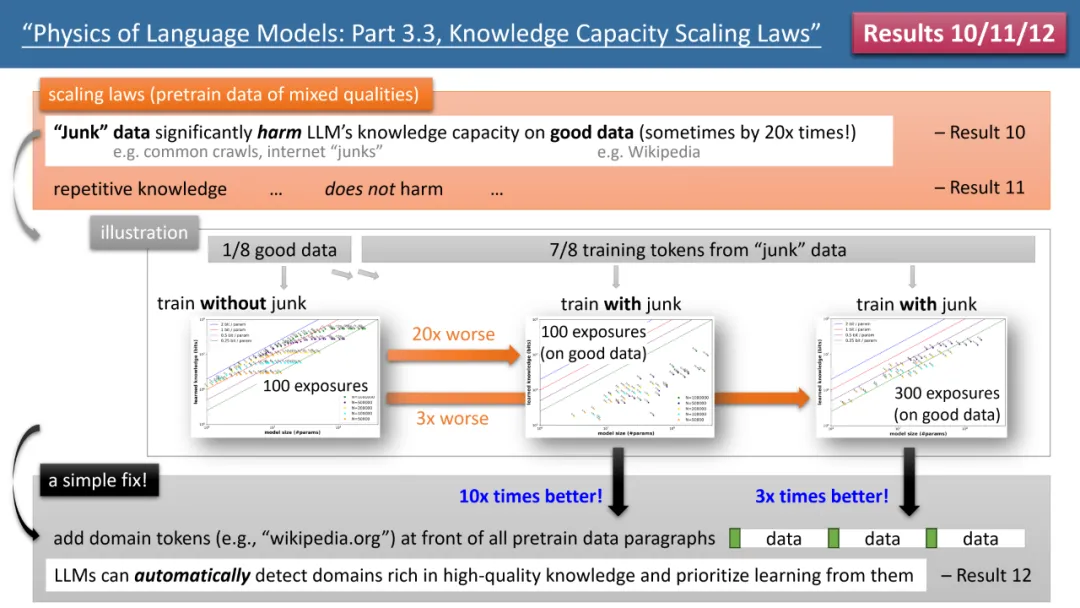
Wenn die Trainingszeit ausreicht, stellte der Autor fest, dass unabhängig von der verwendeten Modellarchitektur, GPT2 oder LlaMA/Mistral, die Speichereffizienz des Modells 2 Bit/Param erreichen kann – das heißt, jeder Modellparameter kann 2 speichern im Durchschnitt nur wenige Informationen. Dies hat nichts mit der Modelltiefe zu tun, sondern nur mit der Modellgröße. Mit anderen Worten: Ein 7B-Modell kann bei entsprechender Schulung 14 Milliarden Bits an Wissen speichern, was mehr ist als das menschliche Wissen in Wikipedia und allen englischen Lehrbüchern zusammen! Was noch überraschender ist, ist, dass die Forschung des Autors diese Ansicht widerlegt, obwohl die traditionelle Theorie besagt, dass das Wissen im Transformatormodell hauptsächlich in der MLP-Schicht gespeichert ist. Sie fanden heraus, dass das Modell dies auch dann noch tun kann, wenn alle MLP-Schichten entfernt werden Erreichen Sie 2 Bit/ Speichereffizienz der Parameter. Abbildung 2: Skalierungsgesetze bei unzureichender Trainingszeit Betrachten wir jedoch den Fall unzureichender Trainingszeit, werden die Unterschiede zwischen den Modellen deutlich. Wie in Abbildung 2 oben dargestellt, kann das GPT2-Modell in diesem Fall mehr als 30 % mehr Wissen speichern als LlaMA/Mistral, was bedeutet, dass das Modell von vor einigen Jahren das heutige Modell in einigen Aspekten übertrifft. Warum passiert das? Der Autor nahm architektonische Anpassungen am LlaMA-Modell vor, indem er jeden Unterschied zwischen dem Modell und GPT2 addierte oder subtrahierte, und stellte schließlich fest, dass GatedMLP den Verlust von 30 % verursachte. Um es zu betonen: GatedMLP führt nicht zu einer Änderung der „endgültigen“ Speicherrate des Modells – denn Abbildung 1 sagt uns, dass sie sich bei ausreichendem Training nicht unterscheiden werden. GatedMLP führt jedoch zu einem instabilen Training, sodass dasselbe Wissen eine längere Trainingszeit erfordert. Mit anderen Worten: Bei Wissen, das selten im Trainingssatz vorkommt, verringert sich die Speichereffizienz des Modells. Abbildung 3: Der Einfluss von Quantisierung und MoE auf Modellskalierungsgesetze Die Gesetze 8 und 9 des Autors untersuchen jeweils den Einfluss von Quantisierung und MoE auf Modellskalierungsgesetze. Die Schlussfolgerung ist in Abbildung dargestellt 3 oben. Ein Ergebnis ist, dass die Komprimierung des trainierten Modells von float32/16 auf int8 keine Auswirkungen auf die Wissensspeicherung hat, selbst für Modelle, die die Speichergrenze von 2 Bit/Parameter erreicht haben. Das bedeutet, dass LLM 1/4 der „Grenze der Informationstheorie“ erreichen kann – denn der int8-Parameter beträgt nur 8 Bit, aber im Durchschnitt kann jeder Parameter 2 Bit Wissen speichern. Der Autor weist darauf hin, dass dies ein universelles Gesetz ist und nichts mit der Form des Wissensausdrucks zu tun hat. Die auffälligsten Ergebnisse stammen aus den Gesetzen 10-12 der Autoren (siehe Abbildung 4). Wenn unsere (Vor-)Trainingsdaten stammen, stammen 1/8 aus hochwertigen Wissensdatenbanken (z. B. der Baidu-Enzyklopädie) und 7/8 aus Daten geringer Qualität (z. B. allgemeine Crawl- oder Forumsgespräche oder sogar völlig zufälliger Müll). Daten). Wird sich also minderwertige Daten auf die Aufnahme von qualitativ hochwertigem Wissen durch LLM auswirken? Die Ergebnisse sind überraschend. Selbst wenn die Trainingszeit für qualitativ hochwertige Daten konstant bleibt, kann die „Existenz“ von Daten mit geringer Qualität die Speicherung von qualitativ hochwertigem Wissen durch das Modell um das Zwanzigfache reduzieren! Selbst wenn die Schulungszeit für hochwertige Daten um das Dreifache verlängert wird, wird die Wissensreserve immer noch um das Dreifache reduziert. Das ist, als würde man Gold in den Sand werfen, und hochwertige Daten werden verschwendet. Der Autor schlug ein einfaches Experiment zur Überprüfung vor: Wenn hochwertige Daten mit einem speziellen Token hinzugefügt werden (jeder spezielle Token reicht aus, das Modell muss nicht im Voraus wissen, um welchen Token es sich handelt), dann ist das Wissen des Modells wichtig Der Speicher kann sich sofort um das Zehnfache erhöhen, ist das nicht erstaunlich? Daher ist das Hinzufügen von Domänennamen-Tokens zu Vortrainingsdaten ein äußerst wichtiger Datenvorbereitungsvorgang. Abbildung 4: Skalierungsgesetze, Modellfehler und wie man sie repariert, wenn Daten vor dem Training eine „ungleichmäßige Wissensqualität“ aufweisen Fazit Der Autor glaubt, dass durch synthetische Daten die Berechnung Das Modell wird trainiert. Die dabei gewonnene Methode des Gesamtwissens kann ein systematisches und genaues Bewertungssystem für die „Bewertung der Modellarchitektur, Trainingsmethoden und Datenaufbereitung“ bereitstellen. Dies unterscheidet sich grundlegend von herkömmlichen Benchmark-Vergleichen und ist zuverlässiger. Sie hoffen, dass dies den Designern zukünftiger LLMs helfen wird, fundiertere Entscheidungen zu treffen. 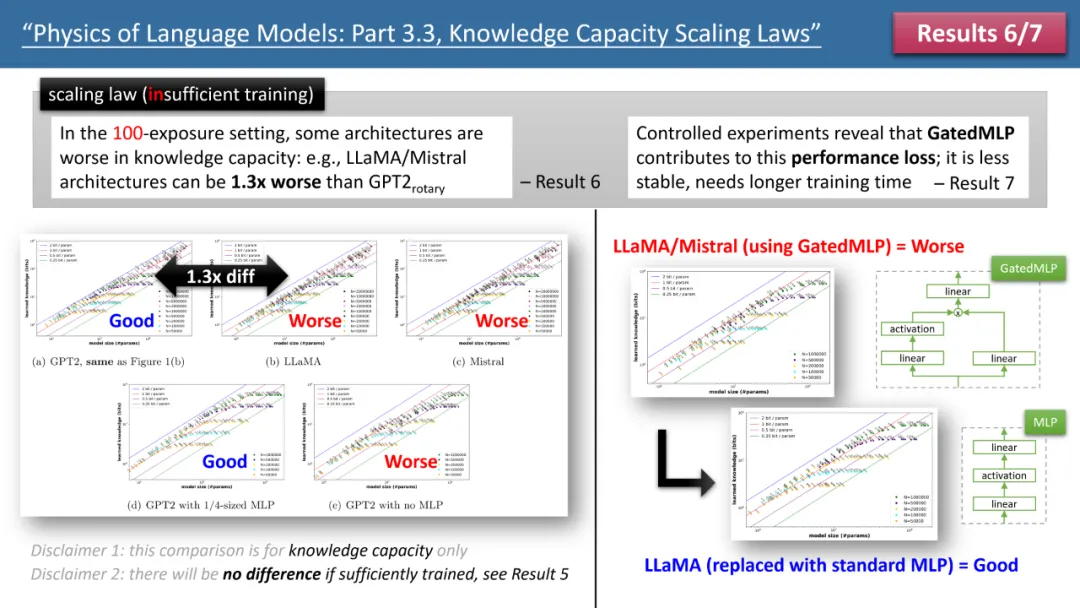
Das obige ist der detaillierte Inhalt vonIst die Llama-Architektur GPT2 unterlegen? Magischer Token erhöht den Speicher um das Zehnfache?. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- So erstellen und verwenden Sie ein Laravel-Framework-Modell
- Das CSS-Box-Modell verstehen: In 5 Minuten verstehen, was das CSS-Box-Modell ist?
- Welche Datenmodelle werden am häufigsten verwendet?
- Was sind die Gründe und Lösungen für einen Datenbankverbindungsfehler?
- Was sind die acht grundlegenden Datentypen?