Die erste Domain-Anpassungsstrategie für das große Modell „Segment Anything“ ist da! Verwandte Beiträge wurden vom CVPR 2024 angenommen. Der Erfolg großer Sprachmodelle (LLMs) hat das Gebiet der Computer Vision dazu inspiriert, grundlegende Modelle für die Segmentierung zu erforschen. Diese grundlegenden Segmentierungsmodelle werden normalerweise für die Null-/Wenige-Bildsegmentierung durch Prompt Engineer verwendet. Unter diesen ist das Segment Anything Model (SAM) das fortschrittlichste Grundmodell für die Bildsegmentierung.个 Picture SAM hat bei mehreren Downstream-Aufgaben eine schlechte Leistung erbracht, aber neuere Untersuchungen zeigen, dass SAM bei vielen Downstream-Aufgaben nicht sehr leistungsfähig und verallgemeinert ist, wie z. B. schlechte Leistung bei medizinischen Bildern, getarnten Objekten, natürlichen Bildern mit zusätzlichen Interferenzen usw. Dies kann auf die große „Domänenverschiebung“ zwischen dem Trainingsdatensatz und dem Downstream-Testdatensatz zurückzuführen sein. Daher ist eine sehr wichtige Frage: Wie kann ein Domänenanpassungsschema entworfen werden, um SAM robuster gegenüber der realen Welt und verschiedenen nachgelagerten Aufgaben zu machen?
Die Anpassung von vorab trainiertem SAM an nachgelagerte Aufgaben steht hauptsächlich vor drei Herausforderungen: Erstens erfordert das traditionelle unbeaufsichtigte Domänenanpassungsparadigma
Quelldatensatz und Zieldatensatz, da der Datenschutz und die Rechenkosten geringer sind machbar. Zweitens ist bei der Domänenanpassung die Aktualisierung aller Gewichtungen in der Regel leistungsstärker, wird aber auch durch  teure Speicherkosten
teure Speicherkosten
eingeschränkt.
Schließlich kann SAM vielfältige Segmentierungsfähigkeiten für Eingabeaufforderungen unterschiedlicher Art und Granularität demonstrieren, sodass wenn es an Eingabeaufforderungsinformationen für nachgelagerte Aufgaben mangelt, eine unbeaufsichtigte Anpassung eine große Herausforderung darstellen wird.大 Abbildung 1 SAM führt ein Vortraining für große Datensätze durch, es gibt jedoch Probleme bei der Verallgemeinerung. Wir verwenden schwache Überwachung, um SAM an verschiedene nachgelagerte Aufgaben anzupassen. Überwachte Selbsttrainingsarchitektur
zur Verbesserung der adaptiven
Robustheit und Recheneffizienz .
Konkret wenden wir zunächst eine Selbsttrainingsstrategie im passiven Bereich an, um eine Abhängigkeit von Quelldaten zu vermeiden. Selbsttraining generiert Pseudo-Labels zur Überwachung von Modellaktualisierungen, sie sind jedoch anfällig für falsche Pseudo-Labels. Wir führen ein „eingefrorenes Quellmodell“ als Ankernetzwerk ein, um Modellaktualisierungen zu standardisieren.
Um den hohen Rechenaufwand für die Aktualisierung der vollständigen Modellgewichte weiter zu reduzieren, wenden wir die
Gewichtungszerlegung mit niedrigem Rang auf den Encoder an und führen eine Rückausbreitung über einen Verknüpfungspfad mit niedrigem Rang durch.
- Um den Effekt der passiven Domänenanpassung weiter zu verbessern, führen wir in der Zieldomäne eine schwache Überwachung ein, z. B. Annotationen mit geringer Punktdichte, um gleichzeitig stärkere Domänenanpassungsinformationen bereitzustellen Eine Art schwache Überwachung ist natürlich mit dem Cue-Encoder in SAM kompatibel.
- Mit schwacher Aufsicht als Prompt erhalten wir mehr lokale und explizite selbst trainierte Pseudo-Labels. Das abgestimmte Modell zeigt eine stärkere Generalisierungsfähigkeit bei mehreren nachgelagerten Aufgaben.
- Wir fassen die Beiträge dieser Arbeit wie folgt zusammen:
1. Inspiriert durch das Generalisierungsproblem von SAM in nachgelagerten Aufgaben schlagen wir eine Lösung vor, die aufgabenunabhängig ist und keine Quelldaten erfordert Automatisch trainieren, um sich an SAM anzupassen.
 2. Wir verwenden schwache Überwachung, einschließlich Box-, Punkt- und anderen Etiketten, um den adaptiven Effekt zu verbessern. Diese schwach überwachten Etiketten sind vollständig kompatibel mit dem Prompt-Encoder von SAM.
2. Wir verwenden schwache Überwachung, einschließlich Box-, Punkt- und anderen Etiketten, um den adaptiven Effekt zu verbessern. Diese schwach überwachten Etiketten sind vollständig kompatibel mit dem Prompt-Encoder von SAM.
3. Wir führen umfangreiche Experimente zu 5 Arten von Downstream-Instanzsegmentierungsaufgaben durch, um die Wirksamkeit der vorgeschlagenen schwach überwachten adaptiven Methode zu demonstrieren.
- Papieradresse: https://arxiv.org/pdf/2312.03502.pdf
- Projektadresse: https://github.com/Zhang-Haojie/WeSAM
- Papiertitel: Improving the Generalization of Segmentierungsgrundmodell unter Verteilungsverschiebung durch schwach überwachte Anpassung
Die Methodeneinführung ist in vier Teile unterteilt:
-
- Basierend auf Selbsttraining Wie das adaptive Framework
- schwache Aufsicht dabei hilft, ein effektives Selbsttraining zu erreichen
-
Low-Rank-Gewichtsaktualisierung
1. Segmentieren Sie alles Modell SAM besteht Zusammensetzung aus drei Komponenten: Image Encoder (ImageEncoder), Prompt Encoder (PromptEncoder) und Decoder (MaskDecoder) . Der Bildencoder wird mit MAE vorab trainiert und das gesamte SAM wird auf dem Trainingssatz SA-1B mit 1,1 Milliarden Anmerkungen weiter verfeinert. Während des Trainings wird eine Kombination aus Fokusverlust und Würfelverlust verwendet. Zum Zeitpunkt der Inferenz wird ein Testbild x zunächst von einem Bildcodierer codiert. Anschließend führt ein leichtgewichtiger Decoder nach einer Eingabeaufforderung Vorhersagen auf drei Ebenen durch. C 2. Quellfreie Domänenanpassung an Selbsttraining Selbsttrainingsarchitektur mit Regularisierung und Vergleichsverlust des in Abbildung 2 vorgeschlagenen Ankernetzwerks Für den unbeschrifteten Zieldatensatz DT={xi} und den vorab trainiertes Segmentierungsmodell. Wir nutzen die Schüler-Lehrer-Architektur zur Selbstausbildung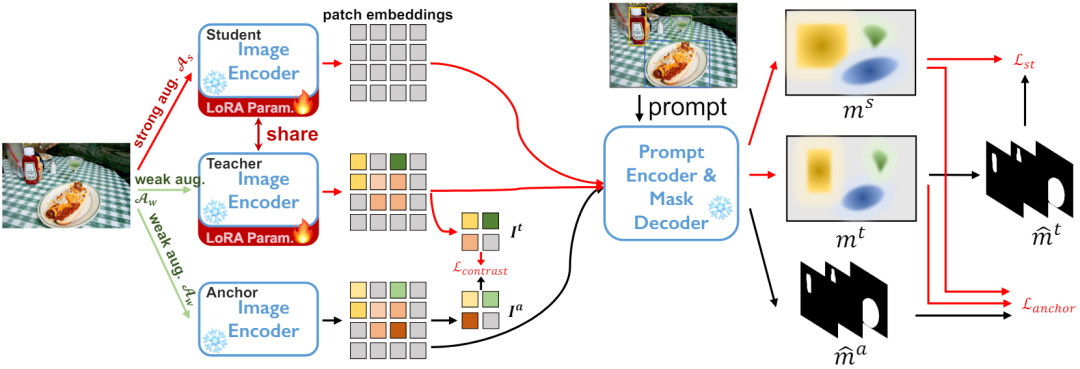 . Wie in Abbildung 2 dargestellt, unterhalten wir drei Encodernetzwerke, nämlich Ankermodell, Schülermodell und Lehrermodell, wobei die Schüler- und Lehrermodelle die gleiche Gewichtung haben.
. Wie in Abbildung 2 dargestellt, unterhalten wir drei Encodernetzwerke, nämlich Ankermodell, Schülermodell und Lehrermodell, wobei die Schüler- und Lehrermodelle die gleiche Gewichtung haben.
Konkret wird für jede Stichprobe xi eine zufällige schwache Datenerweiterung als Eingabe des Anker- und Lehrermodells angewendet, eine zufällige starke Datenerweiterung wird als Eingabe des Schülermodells angewendet und drei Encoder-Netzwerkcodierungen sind vorhanden generierte drei Feature-Maps. Im Decoder-Netzwerk wird bei einer bestimmten Anzahl Np von Eingabeaufforderungen, z. B. einer Box-, Punkt- oder Grobmaske, eine Reihe von Instanzsegmentierungsmasken abgeleitet. Basierend auf den oben genannten Erkenntnissen erläutern wir im Folgenden die drei Sätze von Optimierungszielen für das Selbsttraining.
1) Schüler-Lehrer-Selbsttraining
Wir aktualisieren zunächst das Schüler-/Lehrer-Modell unter Verwendung derselben Verlustfunktion, die beim Training von SAM als Optimierungsziel für das Selbsttraining verwendet wurde. Selbsttraining wird häufig beim halbüberwachten Lernen eingesetzt und hat sich kürzlich als sehr effektiv für die passive Domänenanpassung erwiesen. Insbesondere verwenden wir die vom Lehrermodell generierten Vorhersageergebnisse als Pseudoetiketten und verwenden Fokusverlust und Würfelverlust, um die Schülerausgabe zu überwachen.
2) Ankerverlust für robuste Regularisierung
Netzwerktraining, das nur Selbsttrainingsverluste verwendet, ist anfällig für die Anhäufung falscher Pseudobezeichnungen, die vom Lehrernetzwerk vorhergesagt werden, dem sogenannten Bestätigungsbias. Beobachtungen zeigen auch, dass die Leistung nach langen Iterationen, bei denen nur das Selbsttraining verwendet wird, nachlässt. Bestehende passive Domänenanpassungsmethoden nutzen häufig zusätzliche Einschränkungen, um die negativen Auswirkungen des Selbsttrainings zu verhindern, wie beispielsweise eine gleichmäßige Verteilung von Vorhersagen.
Wir führen eine Regularisierung durch Ankerverlust durch, wie in Gleichung 3 gezeigt, 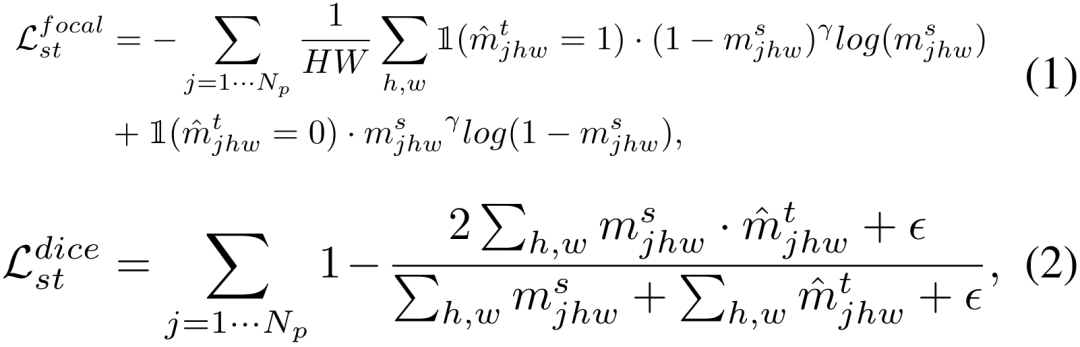 minimiert den Würfelverlust
minimiert den Würfelverlust
zwischen dem Ankermodell und dem Schüler-/Lehrermodell. Das eingefrorene Ankermodell fördert als aus der Quelldomäne geerbtes Wissen keine übermäßige Abweichung zwischen dem Quellmodell und dem selbstlernenden Aktualisierungsmodell und kann einen Modellkollaps verhindern. 3) Durch Kontrastverlust regulierter Encoder-Funktionsraum
下 Vergleichsverlust der beiden Zweige in Abbildung 3
Die beiden oben genannten Trainingsziele werden im Ausgaberaum des Decoders ausgeführt. Der experimentelle Teil zeigt, dass die Aktualisierung des Encoder-Netzwerks die effizienteste Methode zur Anpassung von SAM ist. Daher ist es notwendig, die Regularisierung direkt auf die vom Encoder-Netzwerk ausgegebenen Features anzuwenden. Wie in Abbildung 3 dargestellt, schneiden wir die Features jeder Instanz aus der Feature-Map basierend auf der vorhergesagten Maske in den Anker- und Lehrerzweigen aus. Wir definieren weiterhin positive und negative Stichprobenpaare im Kontrastverlust. Positive Stichprobenpaare werden aus Instanzmerkmalen erstellt, die derselben Eingabeaufforderung in den beiden Zweigen entsprechen, während negative Stichprobenpaare aus Instanzmerkmalen erstellt werden, die unterschiedlichen Eingabeaufforderungen entsprechen . Der endgültige Kontrastverlust wird unten angezeigt, wobei der Temperaturkoeffizient ist. 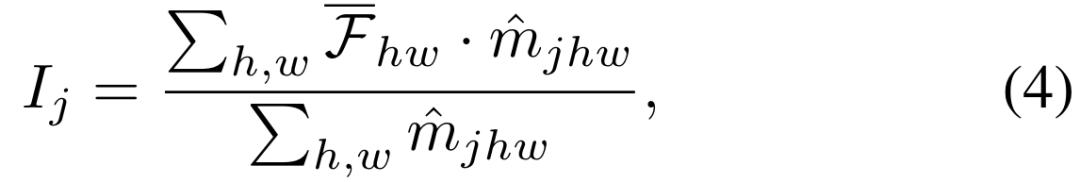
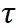 4) Totalverlust
4) Totalverlust 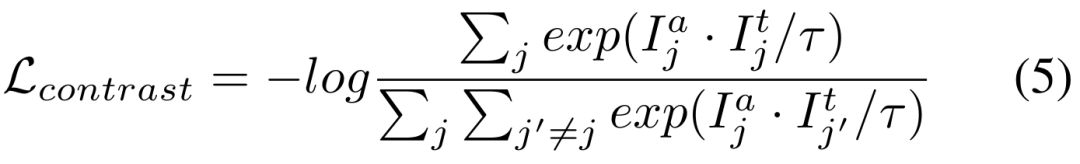
Wir kombinieren die oben genannten drei Verlustfunktionen zum endgültigen quellenfreien adaptiven Verlust. 3. Selbsttrainierte Eingabeaufforderungsgenerierung SAM-Segmentierung erfordert eine Eingabeaufforderung, um das zu segmentierende Zielobjekt anzugeben, es kann jedoch zu Problemen mit granularer Mehrdeutigkeit kommen. Zeitnahe Projekte können vollautomatisiert oder durch menschliche Interaktion umgesetzt werden. 1) Vollständig automatisch Eingabeaufforderung generieren. und fahren Sie dann fort. Um Segmentierungsergebnisse zu erhalten, wird eine nicht maximale Unterdrückung verwendet. Als nächstes wird aus den endgültigen Masken ein fester Satz von Eingabeaufforderungen als Eingabeaufforderung für alle drei Zweige generiert. Daher sind die Maskenlängen der drei Netzwerksegmentierungsausgänge gleich und weisen eine genaue Eins-zu-eins-Entsprechung auf. 2) Schwache Überwachung als Eingabeaufforderungen Eingabeaufforderungen können jedoch erhalten werden, indem Rasterproben auf dem Bild verwendet und minderwertige und doppelte Masken für die automatische Segmentierung herausgefiltert werden. Diese Segmentierungen sind jedoch von relativ schlechter Qualität, können viele falsch positive Vorhersagen enthalten und weisen eine unklare Granularität auf. Die daraus resultierende Qualität der Eingabeaufforderung ist ungleichmäßig, wodurch das Selbsttraining weniger effektiv ist. Ausgehend von früheren schwach überwachten Domänenanpassungsarbeiten schlagen wir daher die Verwendung von drei schwach überwachten Methoden vor, darunter Bounding-Box-Box, spärlicher Punkt-Annotationspunkt und grobe Segmentierungspolygon-Grobmaske. In SAM passen diese schwachen Überwachungsmethoden perfekt zu sofortigen Eingaben, und schwache Überwachung kann nahtlos integriert werden, um sich an SAM anzupassen. 4. Low-Rank-Gewichtsaktualisierung Das riesige Encoder-Netzwerk des Basismodells macht es extrem schwierig, die Gewichte aller Modelle zu aktualisieren. Viele bestehende Studien zeigen jedoch, dass die Aktualisierung der Encoder-Netzwerkgewichte eine effektive Möglichkeit ist, vorab trainierte Modelle zu optimieren.
Um das Encoder-Netzwerk effizienter und kostengünstiger aktualisieren zu können, wählen wir eine rechenfreundliche Low-Rank-Update-Methode. Für jedes Gewicht θ im Encodernetzwerk verwenden wir eine Näherung niedrigen Ranges ω = AB und legen ein Komprimierungsverhältnis r fest. Nur A und B werden über Backpropagation aktualisiert, um die Speichernutzung zu reduzieren. Während der Inferenzphase werden die Gewichte rekonstruiert, indem die Approximation mit niedrigem Rang mit den ursprünglichen Gewichten kombiniert wird, d. h. θ = θ + AB. ExperimenteIn den Experimenten liefern wir detaillierte Vergleiche mit modernsten Methoden und qualitative Ergebnisse. Abschließend analysieren wir die Wirksamkeit jedes Teils und das spezifische Design des Netzwerks.
1. Datensatz In dieser Arbeit bewerten wir fünf verschiedene Arten von Downstream-Segmentierungsaufgaben, von denen einige erhebliche Verteilungsverschiebungen gegenüber SA-1B aufweisen. Der Datensatz umfasst klare natürliche Bilder, natürliche Bilder mit zusätzlichen Interferenzen, medizinische Bilder, getarnte Objekte und Roboterbilder, insgesamt 10 Typen.
Datenpartitionierung: Jeder Downstream-Datensatz ist in nicht überlappende Trainingssätze und Testsätze unterteilt. Die für jede Art von nachgelagerter Aufgabe ausgewerteten Datensätze sind in Tabelle 1 aufgeführt, zusammen mit der Aufteilung in Trainings- und Testdatensätze. 2. Experimentelle Details Segment-Anything-Modell: Aufgrund von Speicherbeschränkungen verwenden wir ViT-B als Encoder-Netzwerk. Verwenden Sie den Standard-Hinweis-Encoder und den Masken-Decoder. 
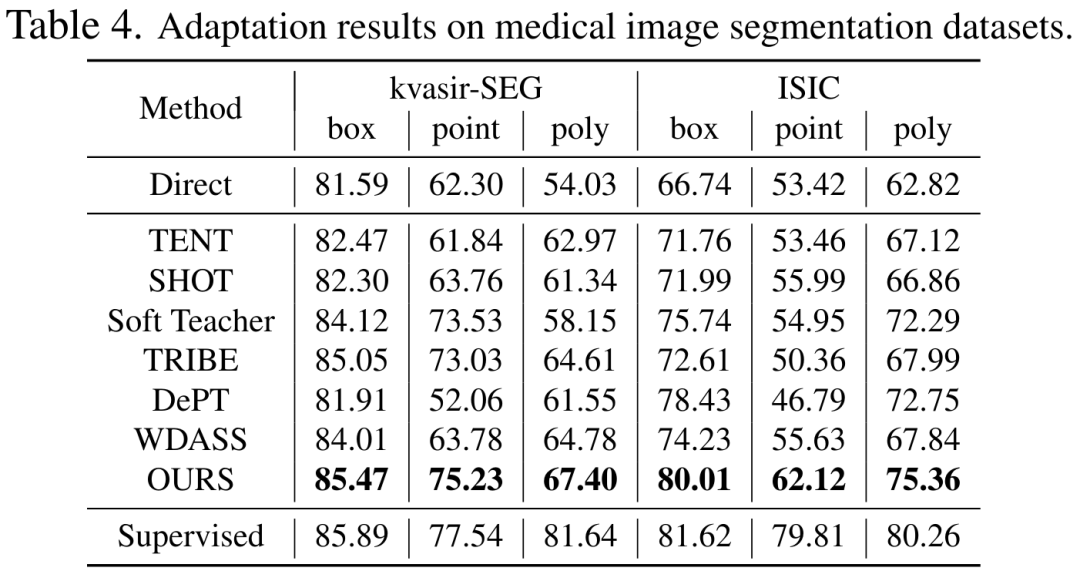
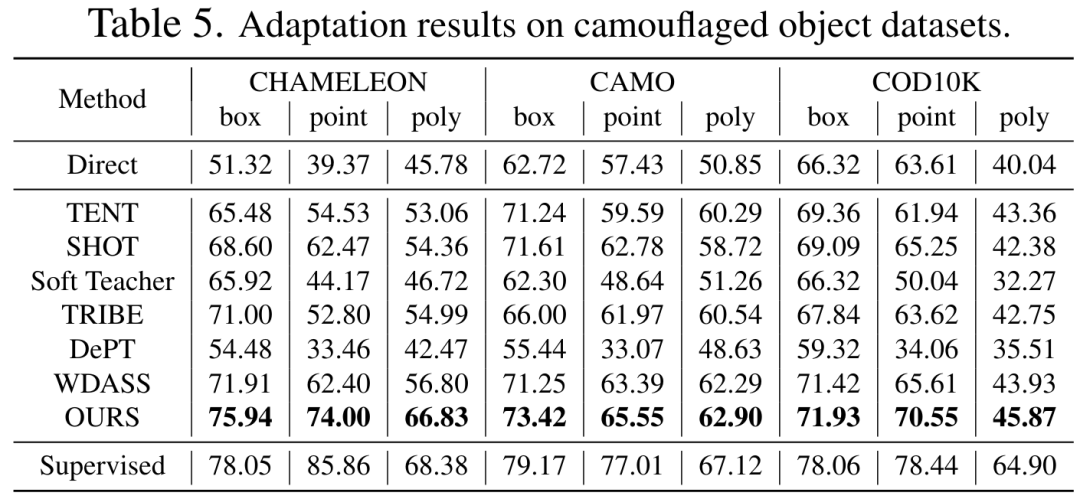
Prompte Generierung: Prompt-Eingaben für Trainings- und Evaluierungsphasen werden aus Instanzsegmentierungs-GT-Masken berechnet und simulieren menschliche Interaktion als schwache Aufsicht. Konkret extrahieren wir den Rahmen aus dem minimalen Begrenzungsrahmen der gesamten GT-Maske. Punkte werden durch zufällige Auswahl von 5 positiven Abtastpunkten innerhalb der GT-Maske und 5 negativen Abtastpunkten außerhalb der Maske erstellt. Grobe Masken werden durch Anpassen von Polygonen an GT-Masken simuliert. 3. Experimentelle ErgebnisseTabellen 2, 3, 4 und 5 sind die Testergebnisse für die natürlichen Bilder mit zusätzlichen Interferenzen, klaren natürlichen Bildern, medizinischen Bildern und getarnten Objektdatensätzen Die vollständigen experimentellen Ergebnisse finden Sie in der Arbeit. Experimente zeigen, dass unser Schema vorab trainiertes SAM und hochmoderne Domänenanpassungsschemata bei fast allen Downstream-Segmentierungsdatensätzen übertrifft.
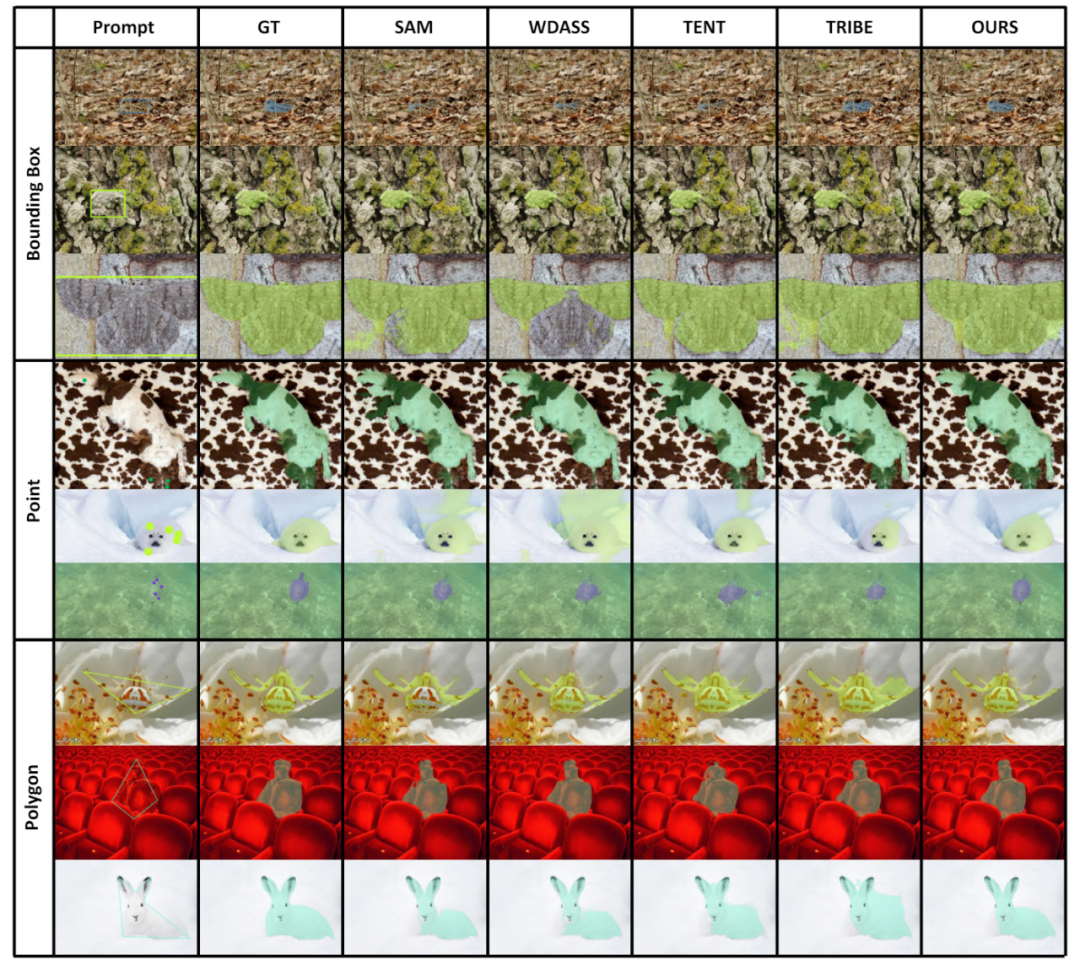
4. VisualisierungsergebnisseEin Teil der Visualisierungsergebnisse ist in Abbildung 4 dargestellt, weitere Visualisierungsergebnisse finden Sie im Artikel. Abbildung 4: Visualisierungsergebnisse einiger Beispiele . In Tabelle 7 analysieren wir auch die Auswirkung der vorgeschlagenen Methode auf die Anpassung, ohne schwache Überwachungsinformationen zu verwenden. 
Wir haben den Leistungsunterschied zwischen Training und Tests anhand verschiedener Kategorien von Eingabeaufforderungen analysiert, wie in Tabelle 8 dargestellt. Experimente zeigen, dass unser Schema unter Cross-Prompt-Bedingungen immer noch gut funktioniert. 
Darüber hinaus haben wir auch die experimentellen Ergebnisse der Optimierung verschiedener Module, einschließlich Decoder, LayerNorm und verschiedener Feinabstimmungsschemata und deren Kombinationen, analysiert. Die Experimente haben gezeigt, dass das LoRA-Schema zur Feinabstimmung des Encoders die beste Wirkung hat. 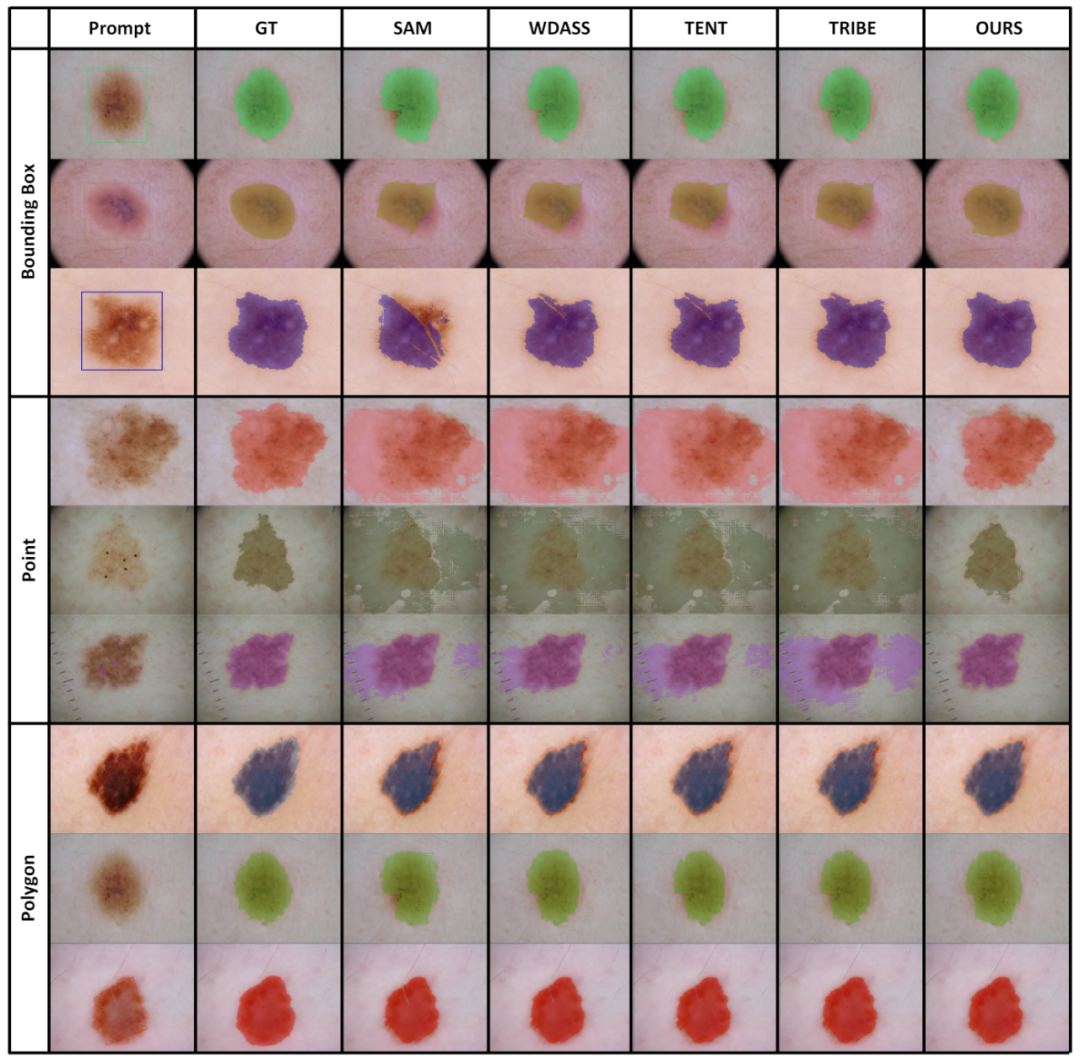
Obwohl das grundlegende Vision-Modell bei Segmentierungsaufgaben eine gute Leistung erbringen kann, leidet es immer noch unter einer schlechten Leistung bei nachgelagerten Aufgaben. Wir untersuchen die Generalisierungsfähigkeit des Segment-Anything-Modells in mehreren nachgelagerten Bildsegmentierungsaufgaben und schlagen eine Selbsttrainingsmethode vor, die auf Ankerregularisierung und Feinabstimmung mit niedrigem Rang basiert. Diese Methode erfordert keinen Zugriff auf den Quelldatensatz, hat geringe Speicherkosten, ist natürlich mit schwacher Überwachung kompatibel und kann den adaptiven Effekt erheblich verbessern. Nach umfassender experimenteller Überprüfung zeigen die Ergebnisse, dass unsere vorgeschlagene Domänenanpassungsmethode die Generalisierungsfähigkeit von SAM unter verschiedenen Verteilungsverschiebungen erheblich verbessern kann. Das obige ist der detaillierte Inhalt vonCVPR 2024 |. Hat die Segmentierung aller Modelle eine schlechte Generalisierungsfähigkeit von SAM? Strategie zur Domänenanpassung gelöst. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!