
Was muss während der Ethereum Purge-Phase geklärt werden?

- 王林nach vorne
- 2024-04-08 09:25:21777Durchsuche
Eines der weniger bekannten EIPs aus der jüngsten Dencun-Hardfork ist EIP-6780, das die meisten Funktionen des Opcodes SELFDESTRUCT entfernte.
Dieses EIP ist ein wichtiges Beispiel für einen oft unterschätzten Teil der Ethereum-Protokollentwicklung: das Bemühen, das Protokoll zu vereinfachen, indem Komplexität beseitigt und neue Sicherheitsgarantien hinzugefügt werden. Dies ist ein wichtiger Teil dessen, was ich „PURGE“ nenne: Projekte zur Rationalisierung von Ethereum und zur Beseitigung technischer Schulden. Es wird weitere EIPs in einem ähnlichen Sinne geben, daher lohnt es sich zu verstehen, wie EIP-6780 seine Ziele erreicht und welche anderen EIPs bei zukünftigen Säuberungen möglicherweise gelöscht werden.
Wie vereinfacht EIP-6780 das Ethereum-Protokoll?
EIP-6780 optimiert die Funktionalität von SELFDESTRUCT, wodurch der Opcode zum Zerstören eines Vertrags darauf beschränkt wird, nur dann ausgeführt zu werden, wenn der Vertrag während einer Transaktion existiert. Dies verhindert den Missbrauch der SELFDESTRUCT-Vertragsvernichtungsfunktion und potenzielle Probleme durch das Löschen von Code und Speicherung. Dies erzwingt zwar keine strengere Spezifikation, führt jedoch zwei neue Variablen ein, um dies zu erreichen: ob sie während der Transaktion vorhanden ist und ob der Vertrag aufgerufen wird. Durch diese Änderung wird sichergestellt, dass Verträge nur innerhalb desselben Handelszeitraums erstellt und Vereinbarungen unterzeichnet werden können, um die Zuverlässigkeit zu erhöhen.
1. Nach EIP-6780 gibt es eine maximale Anzahl von Speicherplätzen, die in einem einzelnen Block bearbeitet werden können (ungefähr: Gaslimit / 5000).
2. Wenn der Vertrag zu Beginn einer Transaktion oder eines Blocks einen nicht leeren Code hat, hat er am Ende dieser Transaktion oder dieses Blocks denselben Code.
Zuvor war keine dieser Invarianten wahr:
1 SELFDESTRUCTVerträge mit einer großen Anzahl von Speicherplätzen können eine unbegrenzte Anzahl von Speicherplätzen innerhalb eines einzelnen Blocks freimachen. Dadurch wird die Implementierung von Verkle-Bäumen schwieriger und die Implementierung von Ethereum-Clients komplexer, da sie zusätzlichen Code benötigen, um diesen Sonderfall effizient zu handhaben. 1、SELFDESTRUCT拥有大量存储槽的合约可以在单个区块内清除无限数量的存储槽。这将使Verkle树的实现变得更加困难,并且使以太坊客户端的实现变得更加复杂,因为它们需要额外的代码来有效地处理这种特殊情况。
合约的代码可以通过SELFDESTRUCT从非空变为为空,实际上合约甚至可以在之后立即使用不同的代码重新创建。这使得账户抽象中的交易验证更加困难,因为交易验证需要使用交易中的代码库而不容易受到DoS攻击的影响。
现在,这些不变量都是True,使得构建以太坊客户端和其他类型的基础设施变得更加容易。几年后,希望未来的EIP能够完成这项工作并SELFDESTRUCT完全消除。
哪些其他“purges”正在进行?
Geth 最近删除了数千行代码,删除了对pre-merge PoW网络的支持。
这个 EIP正式体现了这样一个事实:我们不再需要代码来担心“空帐户”(请参阅:EIP-161 ,它引入了这个概念作为上海 DoS 攻击修复的一部分)
Dencun 中 blob 的存储窗口为 18 天,这意味着以太坊节点只需要约 50 GB 来存储 blob 数据,并且此数量不会随着时间的推移而增加
前两个显著改善了客户端开发人员的体验。后者显著提高了节点运营商的寿命。
还有哪些其他可能需要Purge的东西?
预编译(Precompiles)
预编译是以太坊合约,它没有 EVM 代码,而是具有必须由客户端自己直接实现的逻辑。这个想法是,预编译可用于实现无法在 EVM 中有效实现的复杂形式的密码学。
如今,预编译的使用非常成功,特别是通过椭圆曲线预编译启用基于 ZK-SNARK 的应用程序。然而,还有其他很少使用的预编译:
RIPEMD-160:引入哈希函数是为了支持与比特币更好的兼容性Identity:返回与其输入相同的输出的预编译BLAKE2:引入哈希函数是为了支持与 Zcash 更好的兼容性MODEXP引入非常大的模幂以支持基于 RSA 的加密
事实证明,对这些预编译的需求远远低于预期。Identity
SELFDESTRUCT vollständig beseitigen. - Welche anderen „Säuberungen“ finden statt?
- Geth hat kürzlich Tausende von Codezeilen entfernt und damit die Unterstützung für Pre-Merge-PoW-Netzwerke entfernt. 🎜🎜Diese EIP verkörpert offiziell die Tatsache, dass wir keinen Code mehr benötigen, um uns um „leere Konten“ zu kümmern (siehe: EIP-161, das dieses Konzept als Teil der Shanghai DoS-Angriffsbehebung eingeführt hat) 🎜🎜🎜🎜Dencun Der Speicher Das Fenster für Blobs beträgt 18 Tage, was bedeutet, dass Ethereum-Knoten nur etwa 50 GB zum Speichern von Blob-Daten benötigen, und diese Menge wird sich mit der Zeit nicht erhöhen 🎜🎜
Vorkompilierungen
🎜Vorkompilierungen sind Ethereum-Verträge, die keinen EVM-Code, aber eine Logik haben, die direkt vom Client selbst implementiert werden muss. Die Idee ist, dass durch Vorkompilierung komplexe Formen der Kryptographie implementiert werden können, die im EVM nicht effizient implementiert werden können. 🎜🎜Der Einsatz der Vorkompilierung ist heutzutage sehr erfolgreich, insbesondere um ZK-SNARK-basierte Anwendungen über die Vorkompilierung elliptischer Kurven zu ermöglichen. Es gibt jedoch auch andere selten verwendete Vorkompilierungen: 🎜🎜🎜🎜RIPEMD-160: Hash-Funktionen wurden eingeführt, um eine bessere Kompatibilität mit Bitcoin zu unterstützen 🎜🎜🎜🎜Identity : Eine Vorkompilierung, die gibt eine mit der Eingabe identische Ausgabe zurück 🎜🎜🎜🎜BLAKE2: Hash-Funktionen wurden eingeführt, um eine bessere Kompatibilität mit Zcash zu unterstützen 🎜🎜🎜🎜MODEXPEinführung einer sehr großen modularen Exponentiation zur Unterstützung von RSA -basierte Verschlüsselung 🎜🎜🎜 Es stellte sich heraus, dass der Bedarf an diesen Vorkompilierungen viel geringer war als erwartet. <code>Identity wird häufig verwendet, da es der einfachste Weg ist, Daten zu kopieren, aber seit Dencun wurde es durch den Opcode MCOPY ersetzt. Leider sind diese Vorkompilierungen eine große Quelle von Konsensfehlern und eine große Quelle von Problemen für neue EVM-Implementierungen, einschließlich ZK-SNARK-Schaltungen, formal verifizierungsfreundlicher Implementierungen usw. 🎜🎜Es gibt zwei Möglichkeiten, diese Vorkompilierungen zu entfernen: 🎜🎜🎜🎜 Entfernen Sie einfach die Vorkompilierungen, z. EIP-7266 hat BLAKE2 entfernt. Das ist einfach, führt jedoch dazu, dass jede Anwendung, die es noch verwendet, kaputt geht. 🎜🎜🎜🎜Ersetzen Sie die Vorkompilierung durch einen Block EVM-Code, der das Gleiche tut (allerdings zwangsläufig zu höheren Gaskosten), z. B. Dieser EIP-Entwurf dient der Identitätsvorkompilierung. Dies ist schwieriger, wird aber mit ziemlicher Sicherheit keine Anwendungen beschädigen, die es verwenden (es sei denn, in seltenen Fällen übersteigen die Gaskosten des neuen EVM-Codes das Blockgaslimit für einige Eingaben) 🎜Historische Blöcke (EIP-4444)
Heutzutage wird von jedem Ethereum-Knoten erwartet, dass er alle historischen Blöcke dauerhaft speichert. Dies galt lange Zeit als sehr verschwenderischer Ansatz und erschwert den Betrieb eines Ethereum-Knotens aufgrund des hohen Speicherbedarfs unnötig. In Dencun haben wir Blobs eingeführt, die nur etwa 18 Tage gelagert werden müssen. Mit EIP-4444 werden nach einer gewissen Zeit auch Ethereum-Blöcke vom Standard-Ethereum-Knoten entfernt.
Eine Schlüsselfrage, die gelöst werden muss, lautet: Wenn der alte Verlauf nicht von jedem Knoten gespeichert wird, womit wird er dann gespeichert? Tatsächlich werden dies große Entitäten wie Block-Explorer tun. Es ist jedoch auch möglich und nicht schwierig, ein P2P-Protokoll zum Speichern und Übertragen dieser Informationen zu erstellen, das für die Aufgabe optimierter ist.
Die Ethereum-Blockchain ist dauerhaft, aber von jedem Knoten zu verlangen, dass er alle Daten für immer speichert, ist ein sehr „übertriebener“ Weg, um diese Dauerhaftigkeit zu erreichen.
Ein Ansatz ist ein einfaches Peer-to-Peer-Torrent-Netzwerk für die alte Geschichte. Das andere ist ein Protokoll, das expliziter für die Verwendung mit Ethereum optimiert ist, beispielsweise das Portal Network.
Oder im Meme-Format:
Die Reduzierung der für den Betrieb eines Ethereum-Knotens erforderlichen Speichermenge könnte die Anzahl der Personen, die bereit sind, ein Knoten zu sein, erheblich erhöhen. EIP-4444 kann auch die Zeit für die Knotensynchronisierung verkürzen, was den Arbeitsablauf für viele Knotenbetreiber ebenfalls vereinfacht. Daher kann EIP-4444 die Dezentralisierung von Ethereum-Knoten erheblich verbessern. Wenn jeder Knoten standardmäßig einen kleinen Teil des Verlaufs speichern würde, könnten wir möglicherweise sogar ungefähr die gleiche Anzahl Kopien jedes einzelnen Verlaufs im Netzwerk speichern wie heute.
Protokollreform
Um direkt aus diesem EIP-Entwurf zu zitieren:
Protokolle wurden ursprünglich eingeführt, um Anwendungen die Aufzeichnung von Informationen über Ereignisse in der Kette zu ermöglichen, damit dezentrale Anwendungen (dapps) diese Informationen problemlos abfragen können. Mithilfe von Bloom-Filtern kann ein Dapp schnell den Verlauf durchsuchen, mehrere Blöcke identifizieren, die für seine Anwendung relevante Protokolle enthalten, und dann schnell identifizieren, welche einzelnen Transaktionen über die erforderlichen Protokolle verfügen.
Eigentlich ist dieser Mechanismus zu langsam. Fast alle Dapps, die auf den Verlauf zugreifen, gelangen nicht über RPC-Aufrufe an Ethereum-Knoten (oder sogar an entfernt gehostete Knoten), sondern über zentralisierte zusätzliche Protokolldienste.
Was können wir tun? Wir können den Bloom-Filter entfernen und vereinfachen LOG操作码,这样它所做的就是创建一个将哈希值放入状态的值。然后,我们可以构建单独的协议,使用 ZK-SNARK 和增量可验证计算(IVC)来生成可证明正确的“日志树”,它表示给定的所有日志的易于搜索的表topic, und Anwendungen, die eine Protokollierung benötigen und eine Dezentralisierung wünschen, können diese separaten Protokolle verwenden.
Umstellung auf SSZ
Heutzutage wird ein Großteil der Blockstruktur von Ethereum (einschließlich Transaktionen und Quittungen) immer noch in einem veralteten Format gespeichert, das auf RLP- und Merkle-Patricia-Bäumen basiert. Dies erschwert die Entwicklung von Anwendungen, die diese Daten nutzen, unnötig.
Die Ethereum-Konsensschicht ist auf das sauberere und effizientere SimpleSerialize (SSZ) umgestiegen:
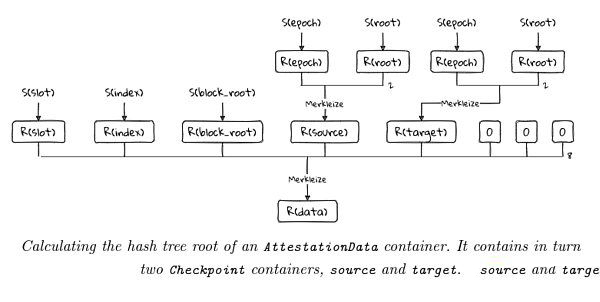
Quelle: https://eth2book.info/altair/part2/building_blocks/merkleization/
Wir benötigen jedoch weiterhin Complete Führen Sie die Konvertierung durch und verschieben Sie die Ausführungsschicht in die gleiche Struktur.
Zu den Hauptvorteilen von SSZ gehören:
Die Spezifikation ist einfacher und klarer
Im Vergleich zum Status-Quo-Merkle-Patricia-Baum mit sechs Gabeln ist die Länge der Merkle-Proofe in den meisten Fällen viermal kürzer
-
Im Vergleich zu den extremen Merkle-Proofs ist die Länge im Vergleich zu langen Worst-Case-Szenarien (z. B. Proof-Vertragscode oder lange Quittungsausgabe) begrenzt.
Es ist nicht erforderlich, komplexen Bitmanipulationscode zu implementieren (erforderlich für RLP).
Für ZK-SNARK-Anwendungsfälle. Es ist oft möglich, vorhandene Implementierungen, die auf binären Merkle-Bäumen basieren, wiederzuverwenden.
In Ethereum gibt es heute drei Arten von kryptografischen Datenstrukturen: SHA256-Binärbäume, SHA3-RLP-Hashlisten und hexadezimale Patricia-Bäume. Sobald wir den Übergang zu SSZ abgeschlossen haben, bleiben uns nur noch zwei übrig: SHA256-Binärbäume und Verkle-Bäume. Langfristig werden wir, sobald wir mit SNARKing-Hashes gut genug sind, wahrscheinlich SHA256-Binärbäume und Verkle durch binäre Merkle-Bäume ersetzen, die SNARK-freundliche Hashes (eine kryptografische Datenstruktur, die für alle Ethereum-Bäume funktioniert) verwenden.
Das obige ist der detaillierte Inhalt vonWas muss während der Ethereum Purge-Phase geklärt werden?. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!