
Heim >Technologie-Peripheriegeräte >KI >Yuanxiangs erstes MoE-Großmodell ist Open Source: 4,2B Aktivierungsparameter, der Effekt ist mit dem 13B-Modell vergleichbar
Yuanxiangs erstes MoE-Großmodell ist Open Source: 4,2B Aktivierungsparameter, der Effekt ist mit dem 13B-Modell vergleichbar

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2024-04-02 13:25:081311Durchsuche
Yuanxiang hat das große Modell XVERSE-MoE-A4.2B veröffentlicht, das die branchenweit modernste Mixture of Experts-Modellarchitektur (Mixture of Experts) übernimmt, Parameter 4.2B aktiviert und der Effekt mit dem 13B-Modell vergleichbar ist. Dieses Modell ist vollständig Open Source und für die kommerzielle Nutzung bedingungslos kostenlos, sodass eine große Anzahl kleiner und mittlerer Unternehmen, Forscher und Entwickler es bei Bedarf im leistungsstarken „Familien-Bucket“ von Yuanxiang nutzen können, was eine kostengünstige Bereitstellung fördert .

Die Entwicklung gängiger großer Modelle wie GPT3, Llama und XVERSE folgt dem Skalierungsgesetz. Während des Modelltrainings und der Inferenz werden alle Parameter während einer einzigen Vorwärts- und Rückwärtsberechnung aktiviert Aktivierung (dicht aktiviert). Wenn der Modellmaßstab zunimmt, werden die Kosten für Rechenleistung stark ansteigen.
Da immer mehr Forscher glauben, dass das spärlich aktivierte MoE-Modell eine effektivere Methode sein kann, ohne den Rechenaufwand für Training und Inferenz bei Vergrößerung der Modellgröße wesentlich zu erhöhen. Da die Technologie relativ neu ist, erfreuen sich die meisten Open-Source-Modelle oder akademischen Forschungen in China noch nicht großer Beliebtheit. In der elementaren Selbstforschung hat XVERSE-MoE-A4.2B unter Verwendung desselben Korpus zum Trainieren von 2,7 Billiarden Token eine tatsächliche Aktivierungsparametermenge von 4,2 B, und die Leistung „springt“ über XVERSE-13B-2 hinaus, nur die Der Berechnungsaufwand wird um 50 % der Trainingszeit reduziert. Im Vergleich zu mehreren Open-Source-Benchmarks von Llama übertrifft dieses Modell Llama2-13B deutlich und liegt nahe an Llama1-65B (unten).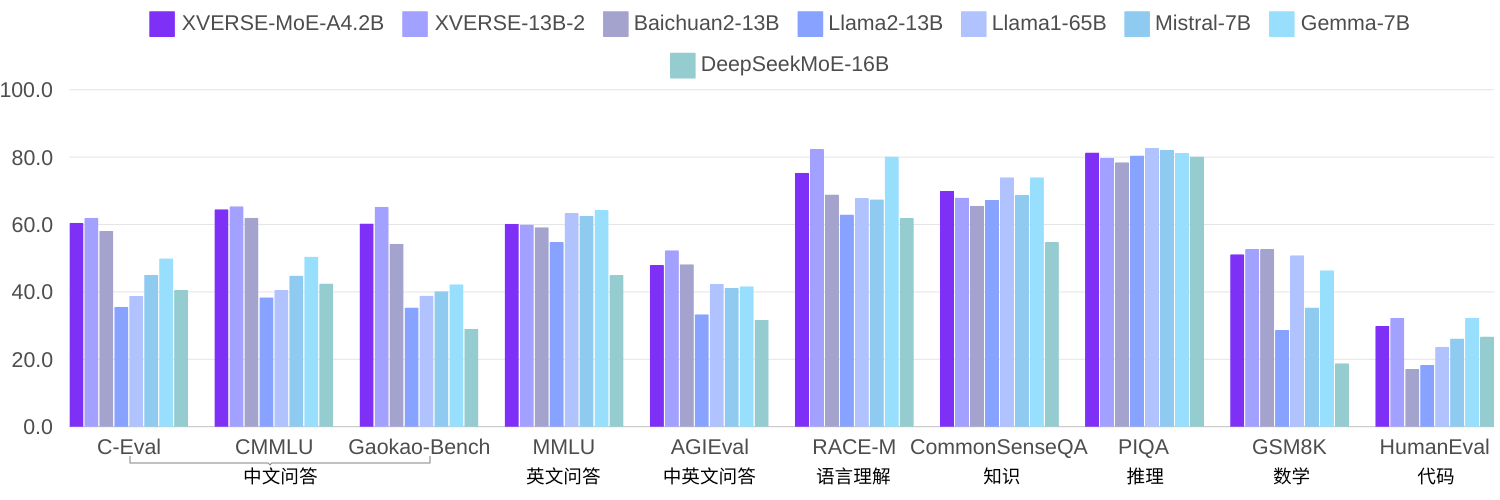
MoETechnologische Selbstforschung und Innovation
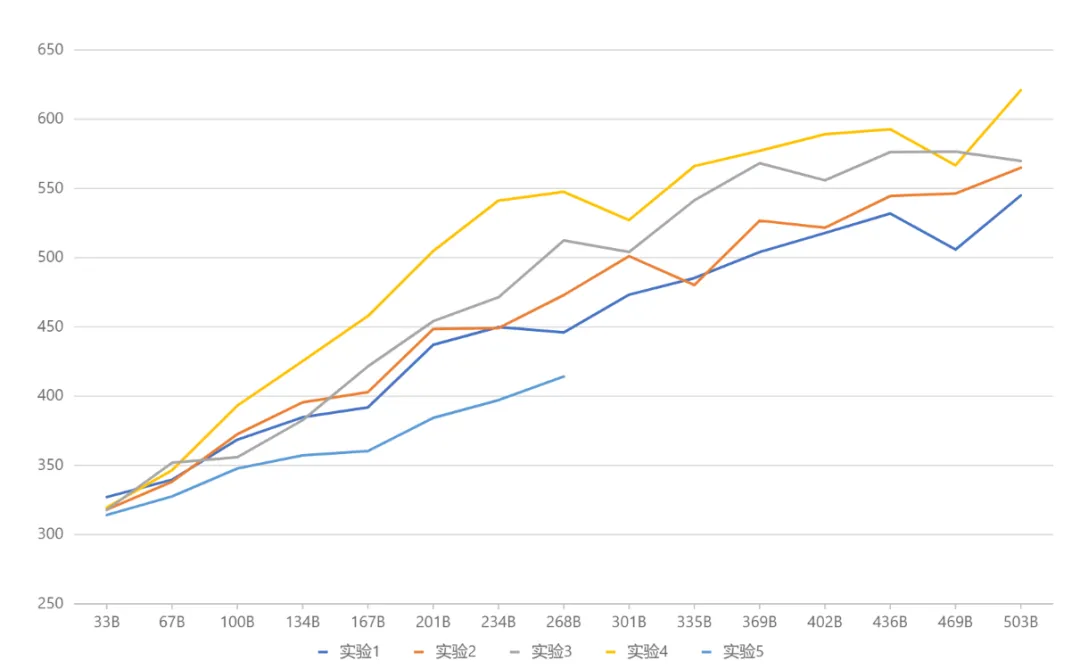
Das Ministerium für Bildung (MoE) ist derzeit das modernste Modell-Framework in der Branche. Aufgrund der neueren Technologie sind inländische Open-Source-Modelle oder akademische Forschung nicht vorhanden dennoch populär geworden. MetaObject hat das effiziente Trainings- und Inferenz-Framework von MoE unabhängig entwickelt und in drei Richtungen innoviert: In Bezug auf die Leistung wurde eine Reihe effizienter Fusionsoperatoren basierend auf der einzigartigen Experten-Routing- und Gewichtsberechnungslogik in der MoE-Architektur entwickelt, was die Datenverarbeitung erheblich verbesserte Effizienz: Um den Herausforderungen einer hohen Speichernutzung und eines großen Kommunikationsvolumens im MoE-Modell gerecht zu werden, sollen überlappende Rechen-, Kommunikations- und Speicherauslagerungsvorgänge den gesamten Verarbeitungsdurchsatz effektiv verbessern. In Bezug auf die Architektur verwendet Yuanxiang im Gegensatz zu herkömmlichen MoE (wie Mixtral 8x7B), bei denen die Größe jedes Experten dem Standard-FFN entspricht, ein feinkörnigeres Expertendesign, und die Größe jedes Experten beträgt nur ein Viertel das Standard-FFN, das die Flexibilität und Leistung des Modells verbessert; Experten werden ebenfalls in zwei Kategorien unterteilt: Gemeinsam genutzte Experten und Nicht-gemeinsam genutzte Experten. Gemeinsam genutzte Experten bleiben während der Berechnungen aktiv, während nicht gemeinsam genutzte Experten bei Bedarf selektiv aktiviert werden. Dieses Design trägt dazu bei, allgemeines Wissen in gemeinsam genutzte Expertenparameter zu komprimieren und die Wissensredundanz zwischen nicht gemeinsam genutzten Expertenparametern zu reduzieren. In Bezug auf das Training führt Yuanxiang, inspiriert von Switch Transformers, ST-MoE und DeepSeekMoE, den Begriff „Load Balancing Loss“ ein, um die Last besser auszugleichen. Der Term „Router Z-Loss“ wird verwendet, um ein effizientes und stabiles Training sicherzustellen. Die Architekturauswahl wurde durch eine Reihe von Vergleichsexperimenten ermittelt (Bild unten). In Experiment 3 und Experiment 2 waren die Gesamtparametermenge und die Aktivierungsparametermenge gleich, aber das feinkörnige Expertendesign des ersteren brachte eine höhere Leistung . Auf dieser Grundlage unterteilte Experiment 4 die Experten weiter in zwei Typen: geteilte und nicht geteilte, was den Effekt deutlich verbesserte. In Experiment 5 wird die Methode zur Einführung gemeinsamer Experten untersucht, wenn die Expertengröße dem Standard-FFN entspricht, der Effekt jedoch nicht ideal ist.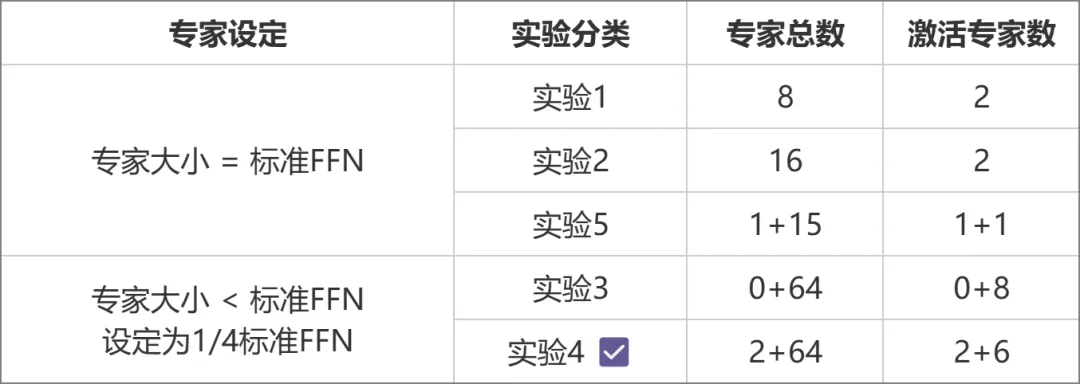
- Hugging Face: https://huggingface.co/xverse/XVERSE-MoE-A4.2B
- ModelScope: https://modelscope. cn /models/xverse/XVERSE-MoE-A4.2B
- Github: https://github.com/xverse-ai/XVERSE-MoE-A4.2B
- Für Anfragen senden Sie bitte: opensource@xverse.cn
Das obige ist der detaillierte Inhalt vonYuanxiangs erstes MoE-Großmodell ist Open Source: 4,2B Aktivierungsparameter, der Effekt ist mit dem 13B-Modell vergleichbar. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Huawei Cloud und eine Reihe von Unternehmen haben eine Aktionsinitiative gestartet: Gemeinsam ein offenes industrielles Ökosystem für autonomes Fahren aufbauen
- Tesla plant die Errichtung einer Elektrofahrzeugfabrik in Indien, um die indische Elektrofahrzeugindustrie anzukurbeln
- Xiaoyu Yilian trat auf der China International Intelligent Industry Expo auf
- Wie können kollaborative Roboter die intelligente Fertigung und Modernisierung der täglichen chemischen Industrie unterstützen? Hören Sie, was die Experten sagen
- Roboterindustrie: das nächste heiße Feld im KI-Zeitalter, eine der neun großen Industrien der Zukunft!