
Heim >Technologie-Peripheriegeräte >KI >Google ist begeistert: JAX-Leistung übertrifft Pytorch und TensorFlow! Es könnte die schnellste Wahl für das GPU-Inferenztraining werden
Google ist begeistert: JAX-Leistung übertrifft Pytorch und TensorFlow! Es könnte die schnellste Wahl für das GPU-Inferenztraining werden

- 王林nach vorne
- 2024-04-01 19:46:111455Durchsuche
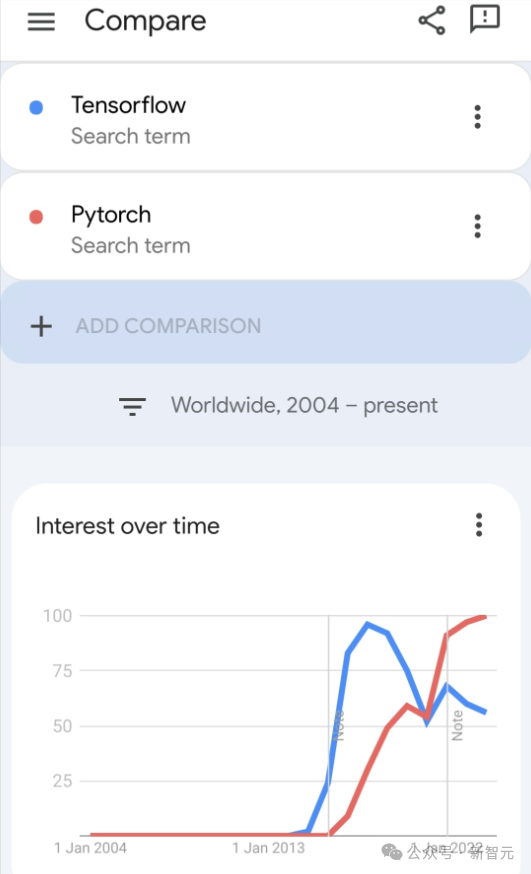
JAX, gefördert von Google, hat in jüngsten Benchmark-Tests Pytorch und TensorFlow übertroffen und belegt bei 7 Indikatoren den ersten Platz.

Und der Test wurde nicht auf der TPU mit der besten JAX-Leistung durchgeführt.

Obwohl Pytorch bei Entwicklern mittlerweile immer noch beliebter ist als Tensorflow.
Aber in Zukunft werden vielleicht noch mehr große Modelle auf Basis der JAX-Plattform trainiert und betrieben.
Modell
Kürzlich führte das Keras-Team Benchmarks für drei Backends (TensorFlow, JAX, PyTorch) mit der nativen PyTorch-Implementierung und Keras 2 mit TensorFlow durch.
Zuerst wählten sie eine Reihe gängiger Modelle für Computer Vision und Verarbeitung natürlicher Sprache für generative und nicht generative Aufgaben der künstlichen Intelligenz aus:

Für die Keras-Version des Modells wurden KerasCV und KerasNLP Build übernommen über die bestehende Umsetzung. Für die native PyTorch-Version haben wir die beliebtesten Optionen im Internet ausgewählt:
– BERT, Gemma, Mistral von HuggingFace Transformers
– StableDiffusion von HuggingFace Diffusers
- Segment Alles von Meta
Sie nennen diesen Modellsatz „Native PyTorch“, um ihn von der Keras 3-Version zu unterscheiden, die das PyTorch-Backend verwendet.
Sie verwendeten synthetische Daten für alle Benchmarks und verwendeten bfloat16-Präzision in allen LLM-Trainings und Inferenzen, während sie LoRA (Feinabstimmung) in allen LLM-Trainings verwendeten.
Gemäß dem Vorschlag des PyTorch-Teams verwendeten sie Torch.compile(model, mode="reduce-overhead") in der nativen PyTorch-Implementierung (mit Ausnahme des Gemma- und Mistral-Trainings aufgrund von Inkompatibilität).
Um die Leistung sofort zu messen, verwenden sie High-Level-APIs (wie Trainer() von HuggingFace, Standard-PyTorch-Trainingsschleifen und Keras model.fit()) mit so wenig Konfiguration wie möglich.
Hardwarekonfiguration
Alle Benchmark-Tests wurden mit der Google Cloud Compute Engine durchgeführt, konfiguriert als: eine NVIDIA A100 GPU mit 40 GB Videospeicher, 12 virtuellen CPUs und 85 GB Hostspeicher.
Benchmark-Ergebnisse
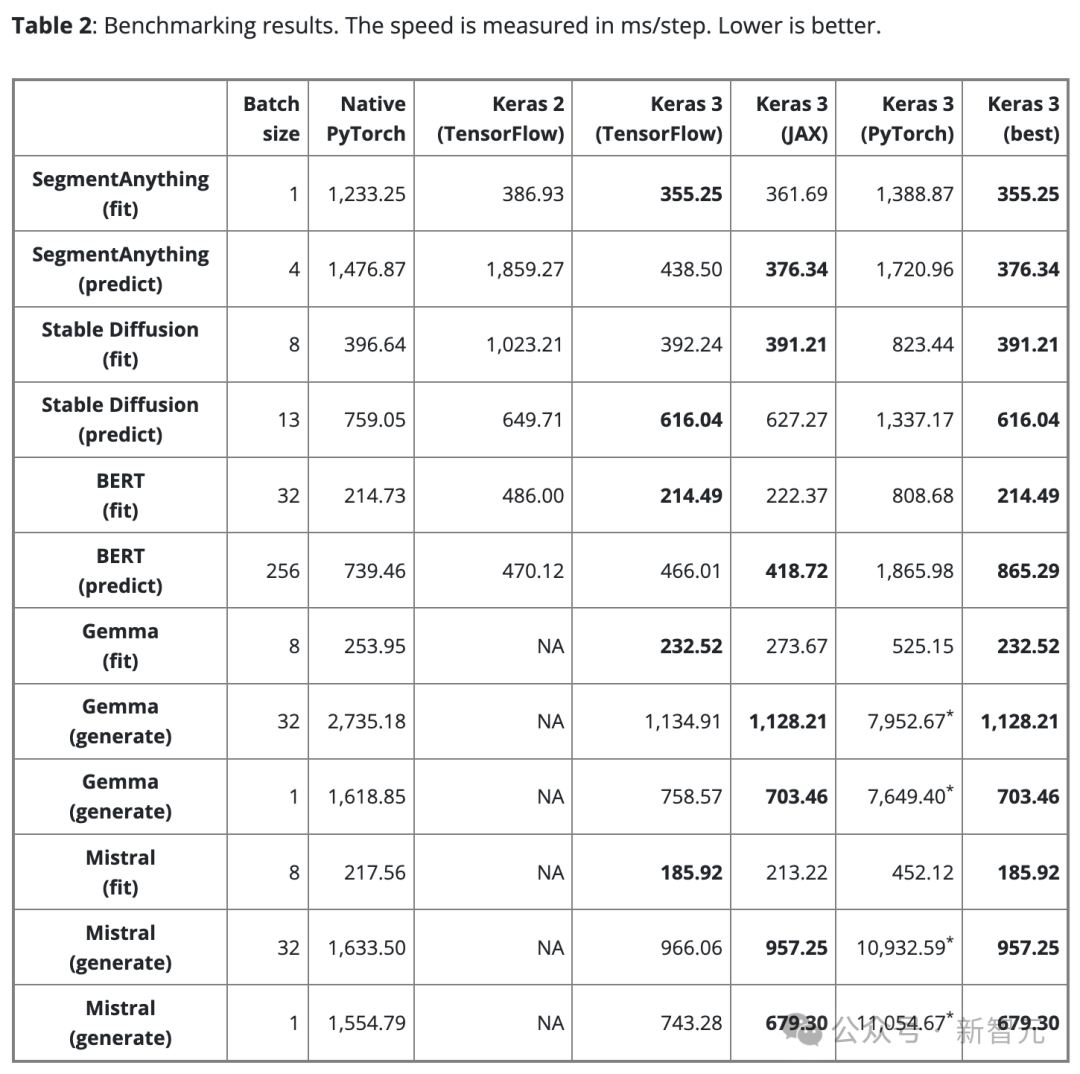
Tabelle 2 zeigt die Benchmark-Ergebnisse in Schritten/ms. Jeder Schritt umfasst das Training oder die Vorhersage anhand eines einzelnen Datenstapels.
Das Ergebnis ist der Durchschnitt von 100 Schritten, der erste Schritt wird jedoch ausgeschlossen, da der erste Schritt die Modellerstellung und -kompilierung umfasst, was zusätzliche Zeit in Anspruch nimmt.
Um einen fairen Vergleich zu gewährleisten, wird dieselbe Chargengröße für dasselbe Modell und dieselbe Aufgabe (ob Training oder Inferenz) verwendet.
Allerdings kann die Datenstapelgröße für verschiedene Modelle und Aufgaben aufgrund ihrer unterschiedlichen Maßstäbe und Architekturen nach Bedarf angepasst werden, um einen Speicherüberlauf aufgrund zu großer Datenmengen oder eine unzureichende GPU-Auslastung aufgrund zu kleiner Datenmengen zu vermeiden.
Eine zu kleine Batchgröße kann auch dazu führen, dass PyTorch langsamer erscheint, da sie den Python-Overhead erhöht.
Für die großen Sprachmodelle (Gemma und Mistral) wurde beim Testen auch dieselbe Batchgröße verwendet, da es sich um denselben Modelltyp mit einer ähnlichen Anzahl von Parametern handelt (7B).
Unter Berücksichtigung der Anforderungen der Benutzer an die Textgenerierung in einem Stapel haben wir auch einen Benchmark-Test zur Textgenerierung mit einer Stapelgröße von 1 durchgeführt.
Wichtige Erkenntnisse
Discovery 1
Es gibt kein „optimales“ Backend.
Die drei Backends von Keras haben jeweils ihre eigenen Stärken. Wichtig ist, dass in Bezug auf die Leistung kein Backend immer gewinnen kann.
Die Wahl des schnellsten Backends hängt oft von der Architektur des Modells ab.
Dieser Punkt unterstreicht, wie wichtig es ist, verschiedene Frameworks auszuwählen, um eine optimale Leistung zu erzielen. Keras 3 erleichtert den Wechsel des Backends, um die beste Lösung für Ihr Modell zu finden.
Gefunden 2
Keras 3 übertrifft im Allgemeinen die Standardimplementierung von PyTorch.
Im Vergleich zu nativem PyTorch weist Keras 3 eine deutliche Verbesserung des Durchsatzes (Schritte/ms) auf.
Insbesondere bei 5 der 10 Testaufgaben stieg die Geschwindigkeit um mehr als 50 %. Unter ihnen erreichte der höchste Wert 290 %.
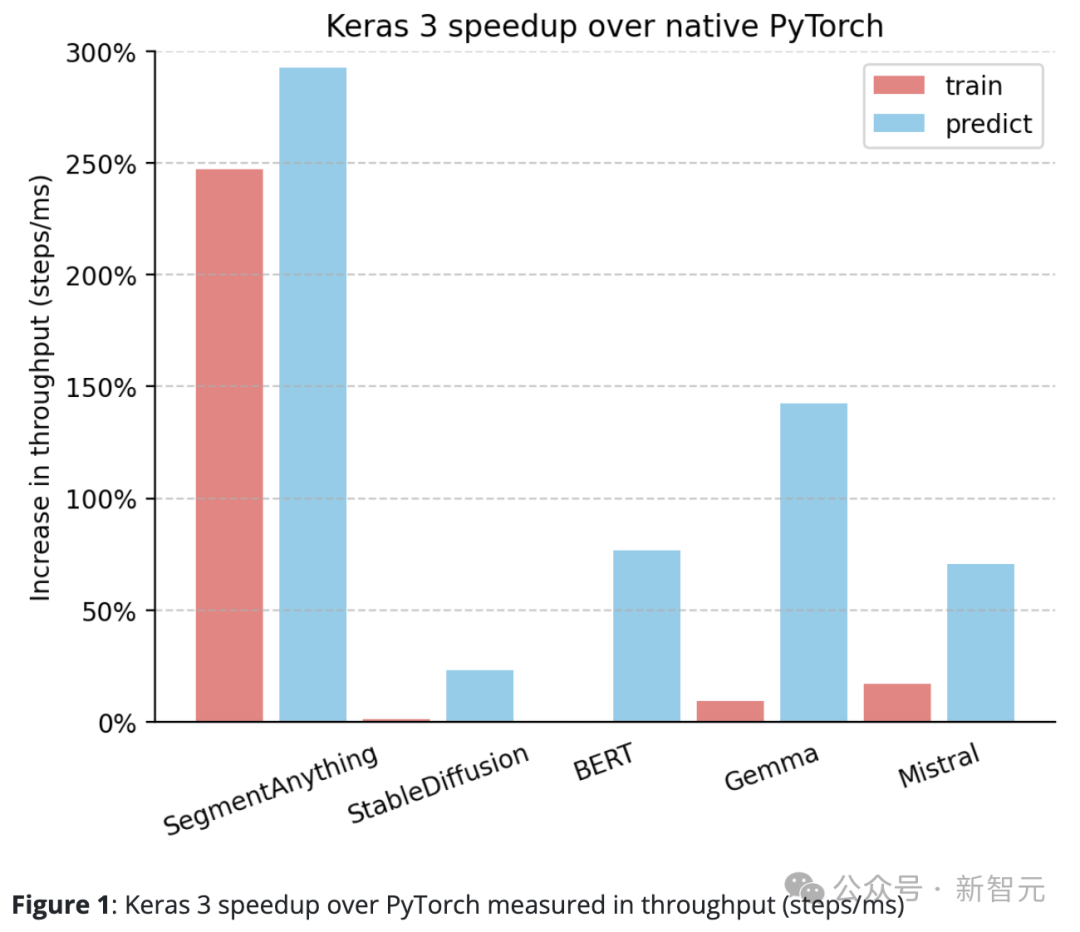
Wenn es 100 % ist, bedeutet dies, dass Keras 3 zweimal schneller ist als PyTorch; wenn es 0 % ist, bedeutet es, dass die Leistung der beiden gleichwertig ist
Discover 3
Keras 3 bietet erstklassige „out of the box“-Leistung.
Das heißt, alle am Test teilnehmenden Keras-Modelle wurden in keiner Weise optimiert. Im Gegensatz dazu müssen Benutzer bei Verwendung der nativen PyTorch-Implementierung normalerweise selbst mehr Leistungsoptimierungen durchführen.
Zusätzlich zu den oben geteilten Daten wurde während des Tests auch festgestellt, dass die Leistung der StableDiffusion-Inferenzfunktion von HuggingFace Diffusers beim Upgrade von Version 0.25.0 auf 0.3.0 um mehr als 100 % stieg.
Ähnlich hat auch in HuggingFace Transformers die Aktualisierung von Gemma von Version 4.38.1 auf 4.38.2 die Leistung deutlich verbessert.
Diese Leistungsverbesserungen unterstreichen den Fokus und die Bemühungen von HuggingFace bei der Leistungsoptimierung.
Für einige Modelle mit weniger manueller Optimierung, wie z. B. SegmentAnything, wird die vom Studienautor bereitgestellte Implementierung verwendet. In diesem Fall ist der Leistungsunterschied zu Keras größer als bei den meisten anderen Modellen.
Dies zeigt, dass Keras in der Lage ist, eine hervorragende Out-of-the-box-Leistung zu bieten, und Benutzer können sich über hohe Modelllaufgeschwindigkeiten freuen, ohne sich in alle Optimierungstechniken vertiefen zu müssen.
Gefunden 4
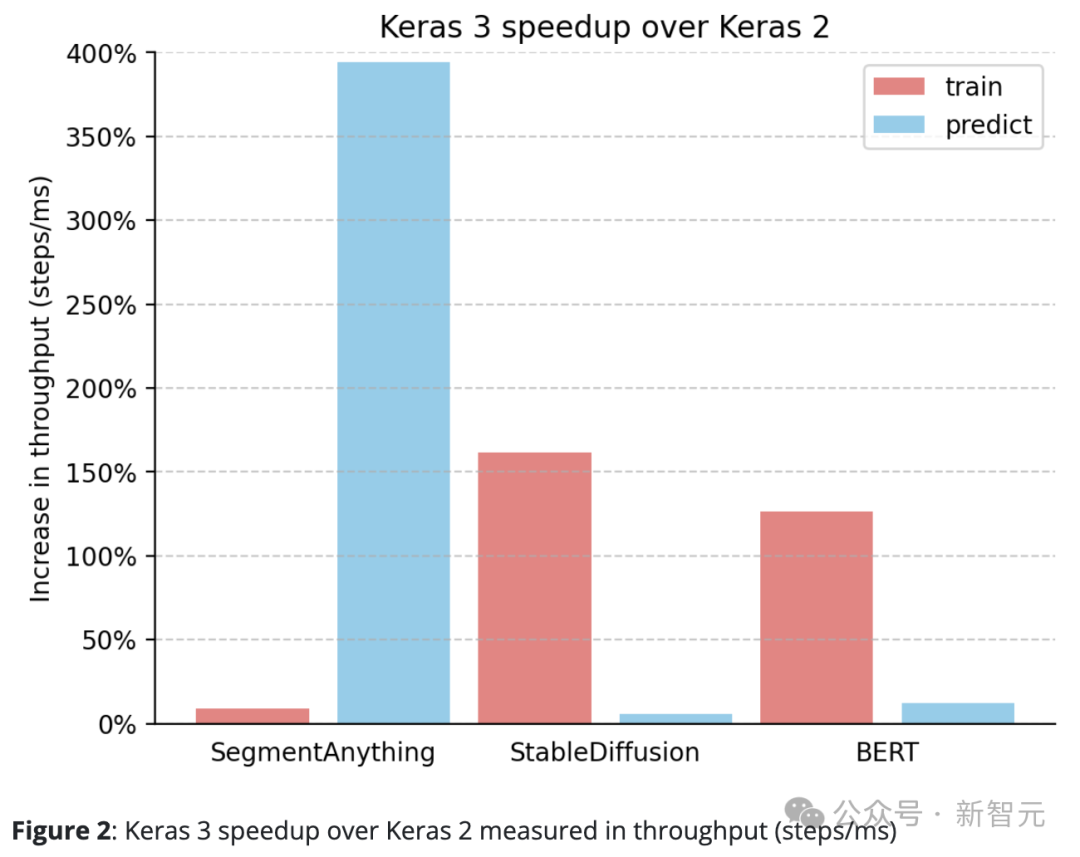
Keras 3 übertrifft Keras 2 durchweg.
Zum Beispiel ist die Inferenzgeschwindigkeit von SegmentAnything um erstaunliche 380 % gestiegen, die Trainingsverarbeitungsgeschwindigkeit von StableDiffusion ist um mehr als 150 % gestiegen und auch die Trainingsverarbeitungsgeschwindigkeit von BERT ist um mehr als 100 % gestiegen.
Dies liegt hauptsächlich daran, dass Keras 2 in einigen Fällen direkt mehr TensorFlow-Fusionsoperationen verwendet, was möglicherweise nicht die beste Wahl für die XLA-Kompilierung ist.
Es ist erwähnenswert, dass bereits das Upgrade auf Keras 3 und die weitere Verwendung des TensorFlow-Backends zu erheblichen Leistungsverbesserungen geführt haben.
Fazit
Die Leistung des Frameworks hängt stark vom konkret verwendeten Modell ab.
Keras 3 kann dabei helfen, das schnellste Framework für die Aufgabe auszuwählen, und diese Wahl übertrifft fast immer Keras 2- und PyTorch-Implementierungen.
Noch wichtiger ist, dass Keras 3-Modelle eine hervorragende Out-of-the-Box-Leistung ohne komplexe zugrunde liegende Optimierungen bieten.
Das obige ist der detaillierte Inhalt vonGoogle ist begeistert: JAX-Leistung übertrifft Pytorch und TensorFlow! Es könnte die schnellste Wahl für das GPU-Inferenztraining werden. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!