
Heim >Technologie-Peripheriegeräte >KI >Um den Video-Pose-Transformer schnell zu machen, schlägt die Peking-Universität ein effizientes 3D-Framework zur Schätzung menschlicher Posen (HoT) vor
Um den Video-Pose-Transformer schnell zu machen, schlägt die Peking-Universität ein effizientes 3D-Framework zur Schätzung menschlicher Posen (HoT) vor

- 王林nach vorne
- 2024-04-01 11:31:32856Durchsuche
Derzeit hat Video Pose Transformer (VPT) die führende Leistung im Bereich der videobasierten 3D-Posenschätzung von Menschen erzielt. In den letzten Jahren ist der Rechenaufwand dieser VPTs immer größer geworden, und dieser enorme Rechenaufwand hat auch die weitere Entwicklung in diesem Bereich eingeschränkt. Es ist sehr unfreundlich für Forscher mit unzureichenden Rechenressourcen. Beispielsweise dauert das Training eines 243-Frame-VPT-Modells in der Regel mehrere Tage, was den Fortschritt der Forschung erheblich verlangsamt und zu einem großen Problem auf diesem Gebiet wird, das dringend gelöst werden muss.
Wie kann man also die Effizienz von VPT effektiv verbessern, ohne die Genauigkeit nahezu zu verlieren?
Ein Team der Peking-Universität schlug ein effizientes 3D-Framework zur Schätzung menschlicher Posen (HoT) basierend auf dem Sanduhr-Tokenizer vor, um das Problem der hohen Rechenanforderungen des bestehenden Video Pose Transformer (VPT) zu lösen. Das Framework kann Plug-and-Play-fähig sein und nahtlos in Modelle wie MHFormer, MixSTE und MotionBERT integriert werden, wodurch die Berechnungen des Modells um fast 40 % reduziert werden, ohne an Genauigkeit zu verlieren. Der Code ist Open Source.

- Titel: Hourglass Tokenizer for Efficient Transformer-Based 3D Human Pose Estimation
- Papieradresse: https://arxiv.org/abs/2311.1202. 8
- Codeadresse: https://github.com/NationalGAILab/HoT


Forschungsmotivation
Im VPT-Modell wird normalerweise jedes Videobild verarbeitet Ein eigenständiges Pose-Token, das eine überlegene Leistung durch die Verarbeitung von Videosequenzen mit einer Länge von Hunderten von Frames (typischerweise 243 bis 351 Frames) erzielt und die Sequenzdarstellung in voller Länge über alle Ebenen des Transformers hinweg beibehält. Da jedoch die Rechenkomplexität des Selbstaufmerksamkeitsmechanismus in VPT proportional zum Quadrat der Anzahl der Token (d. h. der Anzahl der Videobilder) ist, bringen diese Modelle zwangsläufig enorme Ineffizienzen mit sich, wenn Videoeingaben mit höherer Zeitreihenauflösung verarbeitet werden. Der Rechenaufwand macht es schwierig, sie in praktischen Anwendungen mit begrenzten Rechenressourcen umfassend einzusetzen. Darüber hinaus berücksichtigt diese Art der Verarbeitung der gesamten Sequenz nicht die Redundanz innerhalb der Videosequenz, insbesondere die Redundanz zwischen aufeinanderfolgenden Bildern, bei denen visuelle Änderungen nicht offensichtlich sind, sodass die Duplizierung dieser Informationen nicht nur unnötigen Rechenaufwand mit sich bringt, und trägt weitgehend nicht wesentlich zur Verbesserung der Modellleistung bei.
Um eine effiziente VPT zu erreichen, müssen in diesem Artikel daher zunächst zwei Faktoren berücksichtigt werden:
-
Das zeitaufnehmende Feld sollte groß sein: Obwohl eine direkte Verkürzung der Länge der Eingabesequenz die verbessern kann Die Effizienz von VPT verringert dadurch das Zeitaufnahmefeld des Modells, wodurch das Modell auf die Erfassung umfangreicher räumlich-zeitlicher Informationen beschränkt wird, was die Leistungsverbesserung einschränkt. Daher ist die Aufrechterhaltung eines großen zeitlichen Empfangsfeldes von entscheidender Bedeutung, um bei der Verfolgung effizienter Designstrategien eine genaue Schätzung zu erreichen.
- Videoredundanz muss entfernt werden: Aufgrund der Ähnlichkeit der Aktionen zwischen benachbarten Bildern enthalten Videos oft eine große Menge redundanter Informationen. Darüber hinaus haben bestehende Untersuchungen darauf hingewiesen, dass in der Transformer-Architektur mit zunehmender Schichtentiefe die Unterschiede zwischen Tokens immer kleiner werden. Daher kann gefolgert werden, dass die Verwendung des Pose-Tokens in voller Länge in den tiefen Schichten von Transformer zu unnötigen redundanten Berechnungen führt und diese redundanten Berechnungen nur einen begrenzten Beitrag zu den endgültigen Schätzergebnissen leisten.
Basierend auf diesen beiden Beobachtungen schlägt der Autor vor, das Pose-Token des Deep Transformer zu beschneiden, um die Redundanz von Videobildern zu reduzieren und gleichzeitig die Gesamteffizienz von VPT zu verbessern. Dies stellt jedoch eine neue Herausforderung dar: Der Beschneidungsvorgang führt zu einer Reduzierung der Anzahl der Token. Zu diesem Zeitpunkt kann das Modell die Anzahl der dreidimensionalen Posenschätzungsergebnisse, die mit der ursprünglichen Videosequenz übereinstimmen, nicht direkt schätzen. Dies liegt daran, dass im herkömmlichen VPT-Modell jedes Token normalerweise einem Bild im Video entspricht und die verbleibende Sequenz nach dem Beschneiden nicht ausreicht, um alle Bilder des Originalvideos abzudecken. Dies ist problematisch bei der Schätzung der Dreidimensionalität Die menschliche Pose aller Bilder im Video wird zu einem erheblichen Hindernis. Um eine effiziente VPT zu erreichen, muss daher ein weiterer wichtiger Faktor berücksichtigt werden:
- Seq2seq-Begründung: Ein tatsächliches 3D-System zur Schätzung menschlicher Posen sollte in der Lage sein, schnelle Überlegungen über seq2seq durchzuführen, d. h. die 3D-menschlichen Posen aller Frames aus dem Eingabevideo auf einmal zu schätzen. Um eine nahtlose Integration in das bestehende VPT-Framework zu erreichen und eine schnelle Inferenz zu erreichen, ist es daher notwendig, die Integrität der Token-Sequenz sicherzustellen, d. h. ein Token voller Länge wiederherzustellen, das der Anzahl der eingegebenen Videobilder entspricht.
Basierend auf den oben genannten drei Überlegungen schlägt der Autor ein effizientes dreidimensionales Framework zur Schätzung der menschlichen Pose vor, das auf der Sanduhrstruktur basiert: ⏳ Hourglass Tokenizer (HoT). Im Allgemeinen weist diese Methode zwei große Highlights auf:
- Simple Baseline, ein universelles und effizientes Framework basierend auf Transformer
HoT ist die erste effiziente 3D-menschliche Posenschätzung basierend auf Transformer A Plug-in. und-Play-Framework. Wie in der folgenden Abbildung dargestellt, verwendet herkömmliches VPT ein „rechteckiges“ Paradigma, das heißt, die volle Länge des Pose-Tokens wird in allen Schichten des Modells beibehalten, was hohe Rechenkosten und Funktionsredundanz mit sich bringt. Im Gegensatz zu herkömmlichem VPT führt HoT zunächst eine Bereinigung durch, um überflüssige Token zu entfernen, und stellt dann die gesamte Token-Sequenz wieder her (ähnlich einer „Sanduhr“), sodass effektiv nur eine kleine Menge an Token in der mittleren Schicht des Transformers zurückgehalten wird Verbesserung der Effizienz des Modells. HoT weist außerdem eine äußerst hohe Vielseitigkeit auf und lässt sich nicht nur nahtlos in herkömmliche VPT-Modelle integrieren, unabhängig davon, ob es sich um VPT auf Basis von seq2seq oder seq2frame handelt, sondern kann auch an verschiedene Token-Bereinigungs- und Wiederherstellungsstrategien angepasst werden.
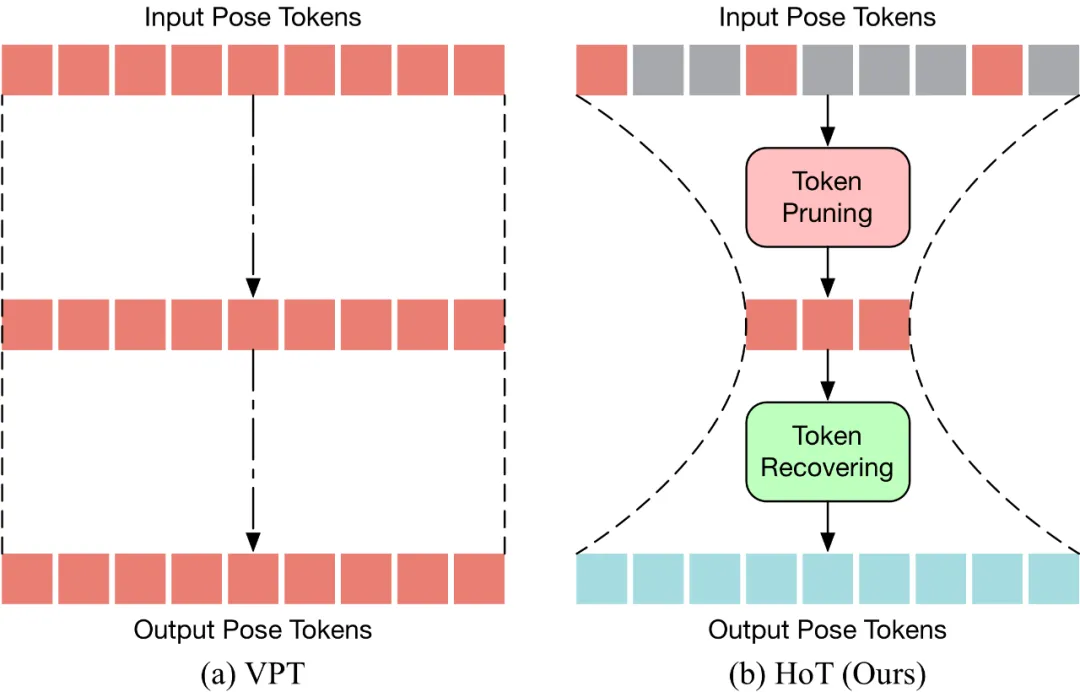
- Sowohl Effizienz als auch Genauigkeit
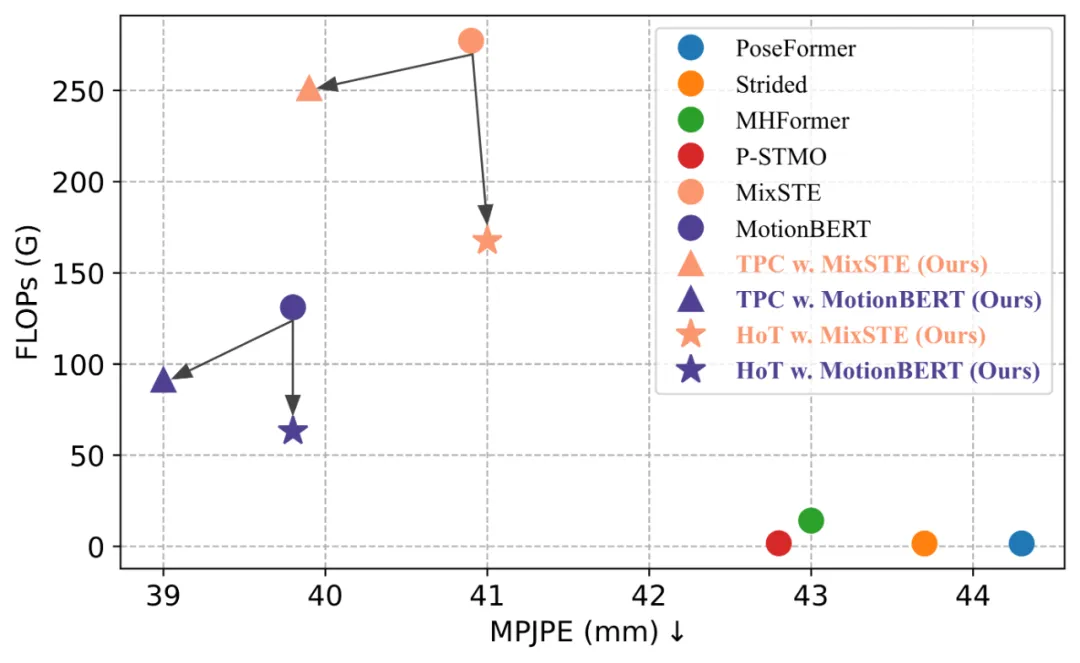
HoT hat gezeigt, dass die Beibehaltung der Posensequenz in voller Länge überflüssig ist und die Verwendung einer kleinen Anzahl repräsentativer Frames von Pose Token gleichzeitig hohe Ergebnisse erzielen kann Effizienz und hohe Leistung. Im Vergleich zum traditionellen VPT-Modell verbessert HoT nicht nur die Verarbeitungseffizienz deutlich, sondern erzielt auch wettbewerbsfähige oder sogar bessere Ergebnisse. So können beispielsweise die FLOPs von MotionBERT ohne Leistungseinbußen um fast 50 % reduziert werden, während die FLOPs von MixSTE um fast 40 % reduziert werden, bei nur einem leichten Leistungsabfall von 0,2 %. Der Gesamtrahmen von HoT, der von der
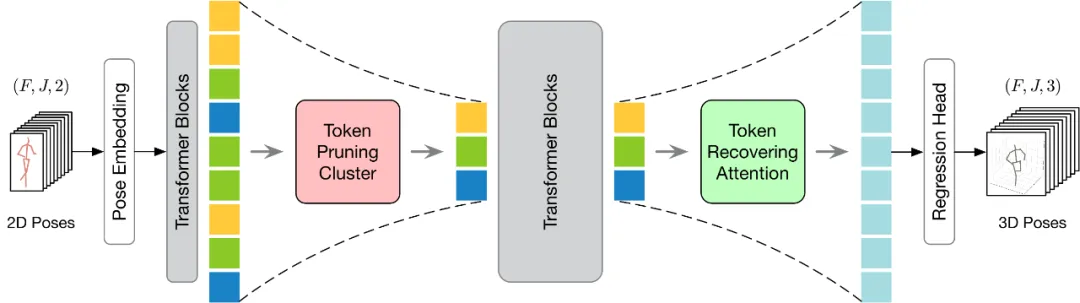
Modellmethode
vorgeschlagen wird, ist in der folgenden Abbildung dargestellt. Um die Token-Bereinigung und -Wiederherstellung effektiver durchzuführen, werden in diesem Artikel zwei Module vorgeschlagen: Token Pruning Cluster (TPC) und Token Recovering Attention (TRA). Unter diesen wählt das TPC-Modul dynamisch eine kleine Anzahl repräsentativer Token mit hoher semantischer Vielfalt aus und verringert gleichzeitig die Redundanz von Videobildern. Das TRA-Modul stellt detaillierte raumzeitliche Informationen basierend auf ausgewählten Token wieder her und erweitert so die Netzwerkausgabe auf die ursprüngliche zeitliche Auflösung in voller Länge, um eine schnelle Schlussfolgerung zu ermöglichen.
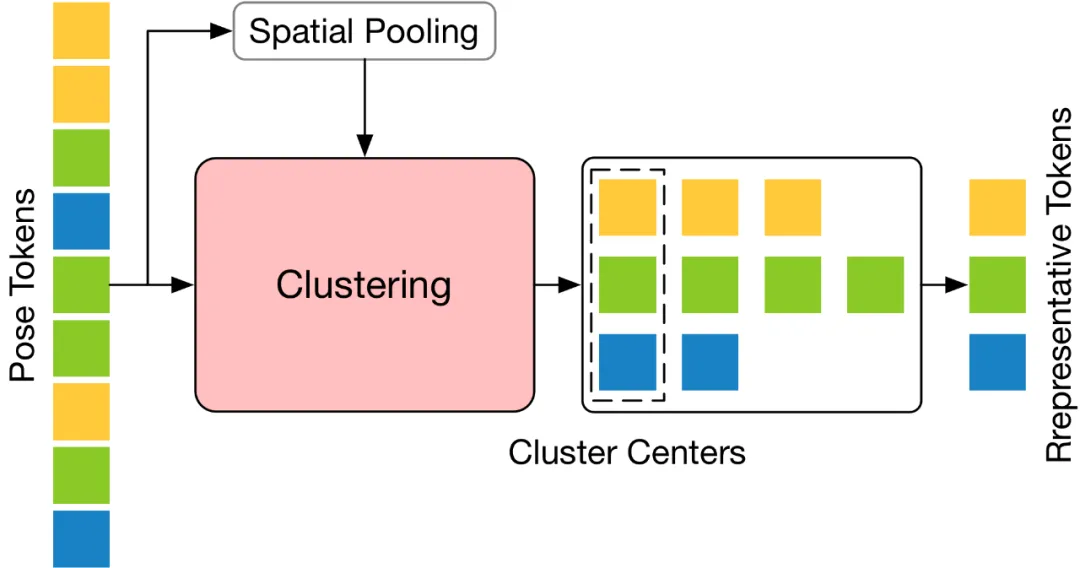
Token-Beschneidungs- und Clustering-Modul
In diesem Artikel wird davon ausgegangen, dass es ein schwieriges Problem ist, eine kleine Anzahl von Pose-Tokens mit umfangreichen Informationen für eine genaue dreidimensionale Schätzung der menschlichen Pose auszuwählen.
Um dieses Problem zu lösen, ist dieser Artikel davon überzeugt, dass der Schlüssel darin liegt, jene repräsentativen Token mit hoher semantischer Vielfalt auszuwählen, da solche Token die notwendigen Informationen behalten und gleichzeitig die Videoredundanz reduzieren können. Basierend auf diesem Konzept schlägt dieser Artikel ein einfaches, effektives Token Pruning Cluster (TPC)-Modul vor, das keine zusätzlichen Parameter erfordert. Der Kern dieses Moduls besteht darin, diejenigen Token zu identifizieren und zu entfernen, die wenig semantischen Beitrag leisten, und sich auf diejenigen Token zu konzentrieren, die wichtige Informationen für die endgültige dreidimensionale Schätzung der menschlichen Pose liefern können. Mithilfe eines Clustering-Algorithmus wählt TPC dynamisch das Clusterzentrum als repräsentatives Token aus und nutzt so die Eigenschaften des Clusterzentrums, um die reichhaltige Semantik der Originaldaten beizubehalten. Die Struktur von
TPC ist in der folgenden Abbildung dargestellt. Es bündelt zunächst das Eingabe-Pose-Token in der räumlichen Dimension und verwendet dann die Merkmalsähnlichkeit des gepoolten Tokens, um das Eingabe-Token zu gruppieren und das Clusterzentrum auszuwählen repräsentativer Token.
Token-Restore-Aufmerksamkeitsmodul
Das TPC-Modul reduziert effektiv die Anzahl der Pose-Tokens. Die durch den Bereinigungsvorgang verursachte Verringerung der Zeitauflösung schränkt jedoch die VPT für eine schnelle seq2seq-Inferenz ein. Daher muss das Token wiederhergestellt werden. Gleichzeitig sollte das Wiederherstellungsmodul unter Berücksichtigung von Effizienzfaktoren so konzipiert sein, dass es leichtgewichtig ist, um die Auswirkungen auf die Gesamtrechenkosten des Modells zu minimieren.
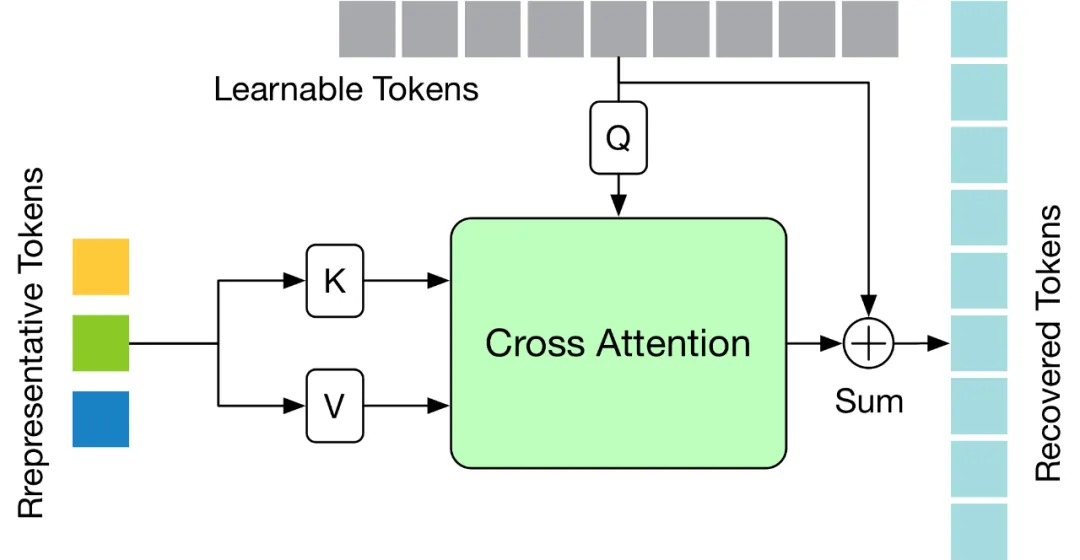
Um die oben genannten Herausforderungen zu lösen, wird in diesem Artikel ein leichtes Token Recovering Attention (TRA)-Modul entworfen, das detaillierte raumzeitliche Informationen basierend auf dem ausgewählten Token wiederherstellen kann. Auf diese Weise wird die durch den Beschneidungsvorgang verursachte niedrige zeitliche Auflösung effektiv auf die zeitliche Auflösung der ursprünglichen vollständigen Sequenz erweitert, sodass das Netzwerk die dreidimensionale menschliche Posensequenz aller Bilder auf einmal schätzen kann, wodurch eine schnelle seq2seq-Schlussfolgerung erreicht wird. Die Struktur des
TRA-Moduls ist in der folgenden Abbildung dargestellt. Es verwendet die repräsentativen Token in der letzten Ebene von Transformer und die lernbaren Token, die auf Null initialisiert werden, um die vollständige Token-Sequenz durch einen einfachen Kreuzaufmerksamkeitsmechanismus wiederherzustellen.
Angewandt auf bestehende VPT
Bevor erörtert wird, wie die vorgeschlagene Methode auf bestehende VPT angewendet werden kann, fasst dieses Dokument zunächst die bestehende VPT-Architektur zusammen. Wie in der folgenden Abbildung dargestellt, besteht die VPT-Architektur hauptsächlich aus drei Komponenten: einem Pose-Einbettungsmodul zum Kodieren der räumlichen und zeitlichen Informationen der Posensequenz, einem mehrschichtigen Transformer zum Erlernen der globalen räumlich-zeitlichen Darstellung und einem Regressionskopfmodul für die Regression Ausgabe von 3D-Ergebnissen zur menschlichen Körperhaltung.
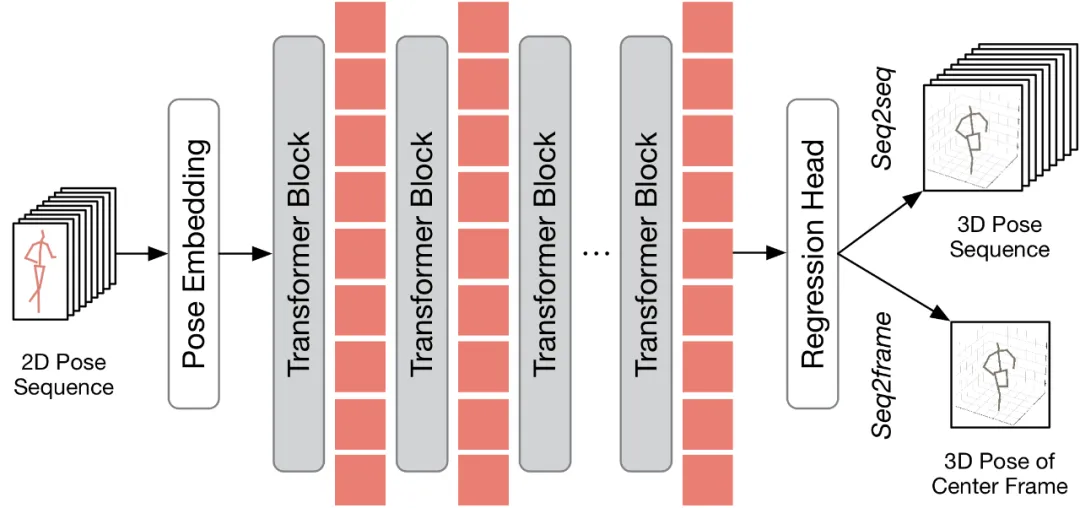
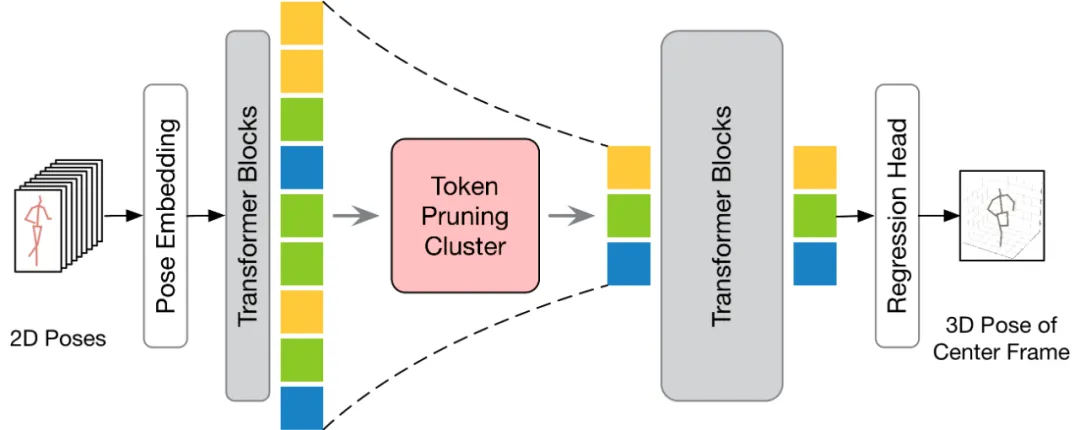
Entsprechend der Anzahl der Ausgaberahmen kann der vorhandene VPT in zwei Inferenzprozesse unterteilt werden: seq2frame und seq2seq. In der seq2seq-Pipeline besteht die Ausgabe aus allen Frames des Eingabevideos, sodass die ursprüngliche Timing-Auflösung in voller Länge wiederhergestellt werden muss. Wie im HoT-Framework-Diagramm gezeigt, sind sowohl TPC- als auch TRA-Module in VPT eingebettet. Beim seq2frame-Prozess ist die Ausgabe die 3D-Pose des mittleren Frames des Videos. Daher ist bei diesem Verfahren das TRA-Modul unnötig und nur das TPC-Modul in das VPT integriert. Sein Rahmen ist in der folgenden Abbildung dargestellt.
Experimentelle Ergebnisse
Ablationsexperiment
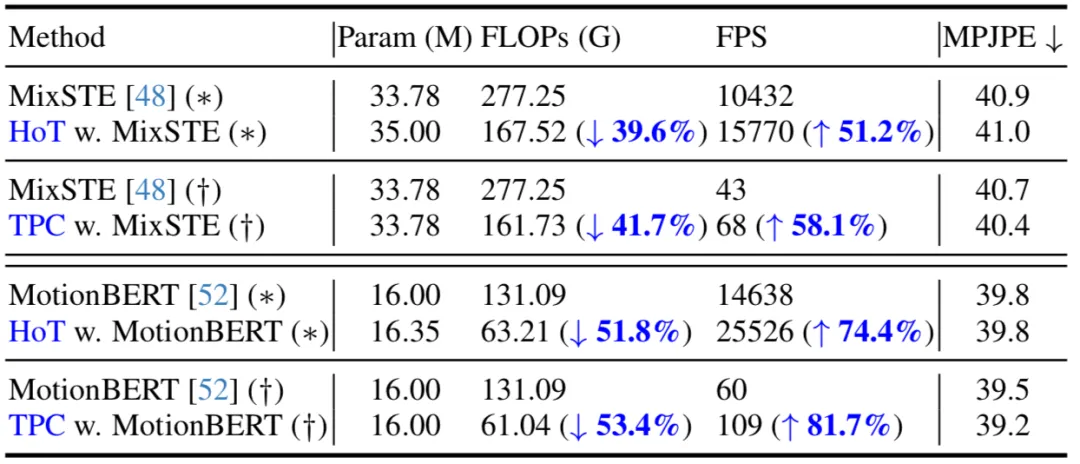
In der folgenden Tabelle gibt dieser Artikel einen Vergleich unter den Inferenzprozessen seq2seq (*) und seq2frame (†). Die Ergebnisse zeigen, dass durch die Anwendung der vorgeschlagenen Methode auf das vorhandene VPT diese Methode die FLOPs deutlich reduzieren und die FPS deutlich verbessern kann, während die Anzahl der Modellparameter nahezu unverändert bleibt. Darüber hinaus weist die vorgeschlagene Methode im Vergleich zum Originalmodell grundsätzlich die gleiche Leistung auf oder kann eine bessere Leistung erzielen.
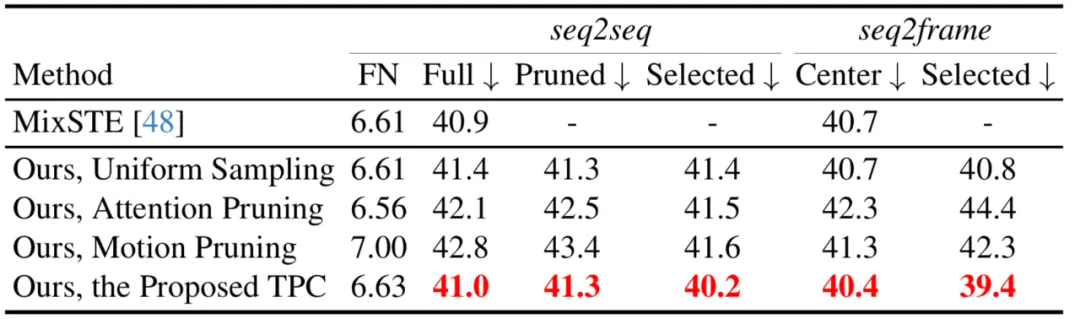
In diesem Artikel werden auch verschiedene Token-Pruning-Strategien verglichen, einschließlich Aufmerksamkeits-Score-Pruning, einheitliches Sampling und eine Motion-Pruning-Strategie, die die Top-k-Tokens mit größeren Bewegungsbeträgen auswählt. Es ist ersichtlich, dass der vorgeschlagene TPC gilt Der beste Auftritt.
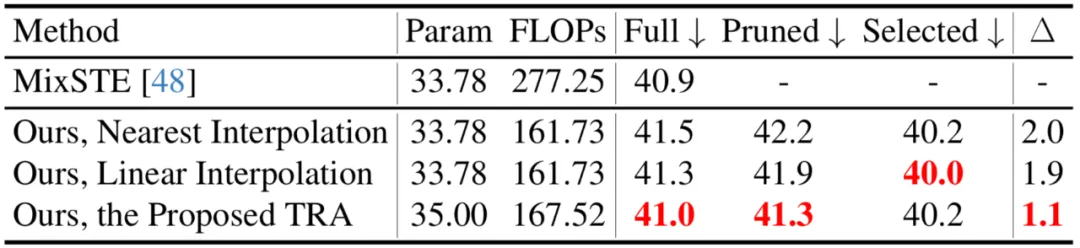
In diesem Artikel werden auch verschiedene Token-Wiederherstellungsstrategien verglichen, einschließlich der Interpolation des nächsten Nachbarn und der linearen Interpolation. Es ist ersichtlich, dass die vorgeschlagene TRA die beste Leistung erzielt.
Vergleich mit SOTA-Methoden
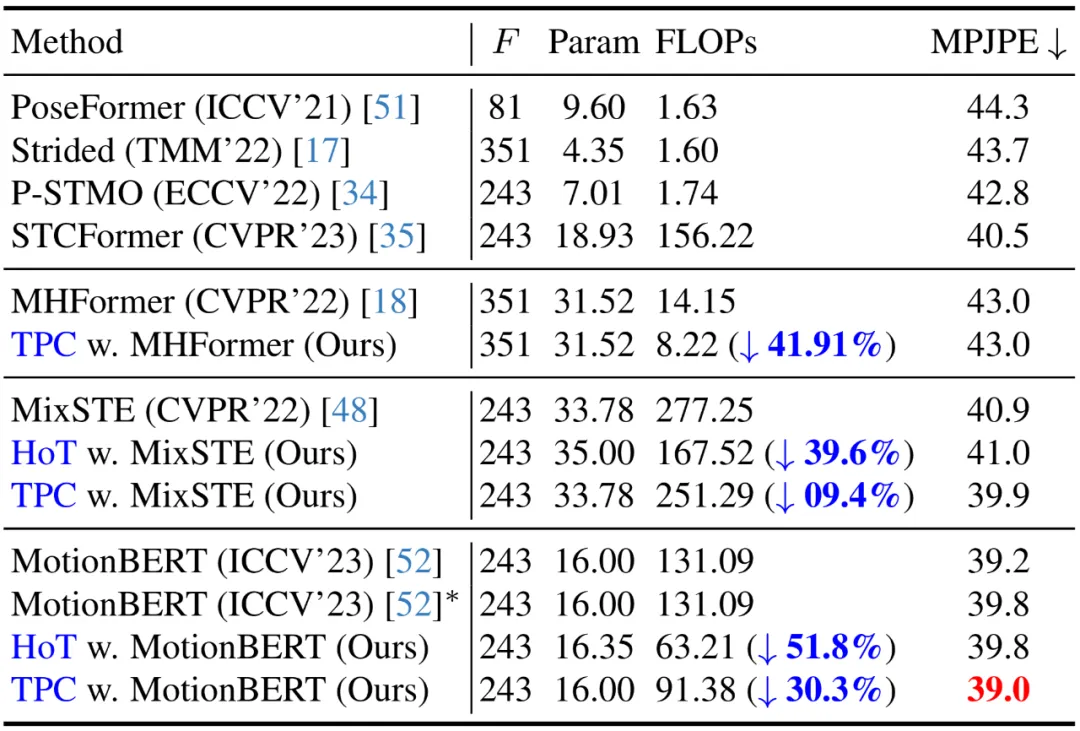
Derzeit verwenden im Human3.6M-Datensatz alle führenden Methoden zur 3D-Posenschätzung von Menschen Transformer-basierte Architekturen. Um die Wirksamkeit dieser Methode zu überprüfen, wenden die Autoren sie auf drei neueste VPT-Modelle an: MHForme, MixSTE und MotionBERT, und vergleichen sie mit ihnen hinsichtlich Parametermengen, FLOPs und MPJPE.
Wie in der folgenden Tabelle gezeigt, reduziert diese Methode den Berechnungsaufwand des SOTA VPT-Modells erheblich, während die ursprüngliche Genauigkeit erhalten bleibt. Diese Ergebnisse bestätigen nicht nur die Wirksamkeit und hohe Effizienz dieser Methode, sondern zeigen auch, dass es in bestehenden VPT-Modellen Rechenredundanzen gibt und diese Redundanzen wenig zur endgültigen Schätzleistung beitragen und sogar zu Leistungseinbußen führen können. Darüber hinaus kann diese Methode diese unnötigen Berechnungen eliminieren und gleichzeitig eine äußerst wettbewerbsfähige oder sogar bessere Leistung erzielen.
Codelauf
Der Autor stellt auch einen Demolauf zur Verfügung (https://github.com/NationalGAILab/HoT), der den YOlov3-Menschendetektor, den zweidimensionalen Haltungsdetektor HRNet und HoT w integriert. MixSTE 2D-zu-3D-Posenverstärker. Laden Sie einfach das vom Autor bereitgestellte vorab trainierte Modell herunter, geben Sie ein kurzes Video mit Personen ein und Sie können mit einer Codezeile direkt eine Demo der 3D-Posenschätzung eines Menschen ausgeben.
python demo/vis.py --video sample_video.mp4
Results erhalten durch Ausführen des Beispielvideos:

Summary
diesen Artikel vorschlägt den Hourglass -Tokenizer (Hourglass -Tokenizer) zur Lösung des Problems der hohen Rechenkosten der vorhandenen Video -Pose Transforme (VPT), HoT), ein Plug-and-Play-Framework zum Bereinigen und Wiederherstellen von Token für eine effiziente Transformer-basierte 3D-Posenschätzung von Menschen aus Videos. Die Studie ergab, dass die Aufrechterhaltung von Posensequenzen in voller Länge in VPT nicht erforderlich ist und die Verwendung einer kleinen Anzahl repräsentativer Frames von Pose-Tokens sowohl eine hohe Genauigkeit als auch Effizienz erreichen kann. Zahlreiche Experimente haben die hohe Kompatibilität und breite Anwendbarkeit dieser Methode bestätigt. Es lässt sich problemlos in verschiedene gängige VPT-Modelle integrieren, unabhängig davon, ob es sich um ein auf seq2seq oder seq2frame basierendes VPT handelt, und kann sich effektiv an eine Vielzahl von Token-Bereinigungs- und Wiederherstellungsstrategien anpassen, was sein großes Potenzial unter Beweis stellt. Die Autoren gehen davon aus, dass HoT die Entwicklung stärkerer und schnellerer VPTs vorantreiben wird.
Das obige ist der detaillierte Inhalt vonUm den Video-Pose-Transformer schnell zu machen, schlägt die Peking-Universität ein effizientes 3D-Framework zur Schätzung menschlicher Posen (HoT) vor. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!