
Heim >Technologie-Peripheriegeräte >KI >Das neue Framework der Shanghai Jiao Tong University erschließt CLIP-Langtextfunktionen, erfasst die Details der multimodalen Generierung und verbessert die Bildabruffunktionen erheblich
Das neue Framework der Shanghai Jiao Tong University erschließt CLIP-Langtextfunktionen, erfasst die Details der multimodalen Generierung und verbessert die Bildabruffunktionen erheblich

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2024-04-01 09:26:33710Durchsuche
Die Langtextfunktion von CLIP ist freigeschaltet und die Leistung von Bildabrufaufgaben ist erheblich verbessert!
Einige wichtige Details können ebenfalls erfasst werden. Die Shanghai Jiao Tong University und das Shanghai AI Laboratory haben ein neues Framework Long-CLIP vorgeschlagen.
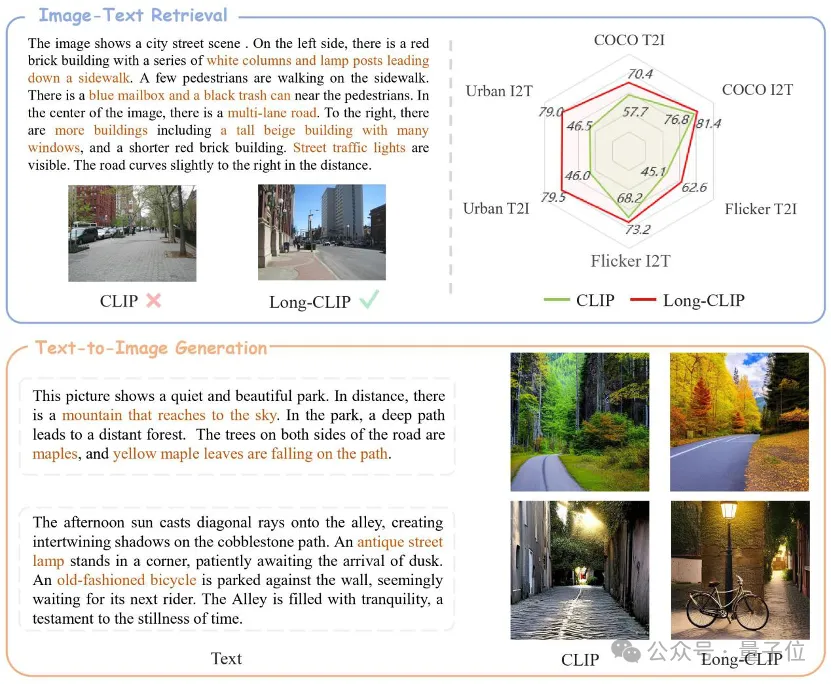
△Der braune Text ist das wichtigste Detail, das die beiden Bilder unterscheidet.
Long-CLIP basiert auf der Beibehaltung des ursprünglichen Funktionsraums von CLIP und lässt sich in nachgelagerte Aufgaben wie die Bildgenerierung integrieren, um eine gute Leistung zu erzielen -körnige Bilderzeugung von Langtexten.
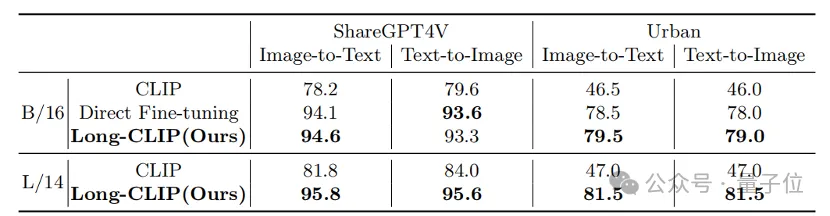
Der Abruf von langen Texten und Bildern stieg um 20 %, der Abruf von kurzen Texten und Bildern um 6 %.
Entsperren Sie die Langtextfunktionen von CLIP.
CLIP richtet visuelle und Textmodalitäten aus und verfügt über leistungsstarke Zero-Shot-Generalisierungsfunktionen. Daher wird CLIP häufig für verschiedene multimodale Aufgaben verwendet, z. B. für die Bildklassifizierung, das Abrufen von Textbildern, die Bildgenerierung usw.
Aber ein großer Nachteil von CLIP ist das Mangel an Langtextfunktionen.
Erstens ist die Texteingabelänge von CLIP aufgrund der Verwendung der absoluten Positionskodierung auf 677 Token begrenzt. Darüber hinaus haben Experimente gezeigt, dass die tatsächliche effektive Länge von CLIP sogar weniger als 20 Token beträgt, was bei weitem nicht ausreicht, um feinkörnige Informationen darzustellen. Um diese Einschränkung zu überwinden, haben Forscher jedoch eine Lösung vorgeschlagen. Durch die Einführung spezifischer Tags in die Texteingabe kann sich das Modell auf die wichtigen Teile konzentrieren. Die Position und Anzahl dieser Token in der Eingabe wird im Voraus festgelegt und wird 20 Token nicht überschreiten. Auf diese Weise ist CLIP in der Lage, Texteingaben zu verarbeiten. Das Fehlen von Langtext auf der Textseite schränkt auch die Möglichkeiten der visuellen Seite ein. Da es nur kurzen Text enthält, extrahiert der visuelle Encoder von CLIP nur die wichtigsten Komponenten eines Bildes und ignoriert verschiedene Details. Dies ist für feinkörnige Aufgaben wie den
Cross-modal Retrievalsehr schädlich. Gleichzeitig führt das Fehlen von Langtext dazu, dass CLIP eine einfache Modellierungsmethode ähnlich der Bag-of-Feature (BOF) verwendet, die nicht über komplexe Funktionen wie Kausalschlussfolgerungen verfügt.
Um dieses Problem anzugehen, schlugen Forscher das Long-CLIP-Modell vor.
Konkret wurden zwei Strategien vorgeschlagen: Wissenserhaltendes Dehnen der Positionseinbettung und eine Feinabstimmungsstrategie, die die Ausrichtung der Kernkomponenten hinzufügt (Primärkomponenten-Matching). 
Wissenserhaltende Erweiterung der Positionskodierung
Eine einfache Methode, die Eingabelänge zu erweitern und die Fähigkeit von Langtexten zu verbessern, besteht darin, die Positionskodierung zunächst mit einem festen Verhältnis λ
1zu interpolieren und sie dann über die Länge hinweg zu optimieren Text. Forscher fanden heraus, dass der Trainingsgrad verschiedener Positionskodierungen von CLIP unterschiedlich ist. Da es sich bei dem Trainingstext wahrscheinlich hauptsächlich um kurzen Text handelt, ist die niedrigere Positionscodierung vollständiger trainiert und kann die absolute Position genau darstellen, während die höhere Positionscodierung nur ihre ungefähre relative Position darstellen kann. Daher sind die Kosten für die Interpolation von Codes an verschiedenen Positionen unterschiedlich.
Basierend auf den obigen Beobachtungen behielt der Forscher die ersten 20 Positionscodes bei und interpolierte sie mit einem größeren Verhältnis λ
2. Die Berechnungsformel kann wie folgt ausgedrückt werden:
Experiment Es zeigt das Im Vergleich zur direkten Interpolation kann diese Strategie die Leistung bei verschiedenen Aufgaben erheblich verbessern und gleichzeitig eine längere Gesamtlänge unterstützen. 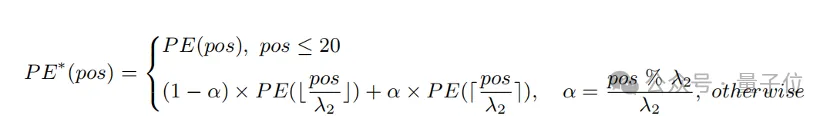
Fügen Sie eine Feinabstimmung der Kernattributausrichtung hinzu.
Nur die Einführung einer Feinabstimmung des Langtextes führt zu einem weiteren Missverständnis des Modells, das darin besteht, alle Details gleichermaßen einzubeziehen. Um dieses Problem anzugehen, führten Forscher bei der Feinabstimmung die Strategie der Ausrichtung von Kernattributen ein.
Konkret verwendeten die Forscher den Algorithmus der Hauptkomponentenanalyse (PCA), um Kernattribute aus feinkörnigen Bildmerkmalen zu extrahieren, die verbleibenden Attribute zu filtern, um grobkörnige Bildmerkmale zu rekonstruieren, und sie mit zusammengefassten Kurztexten zu vergleichen. Diese Strategie erfordert, dass das Modell nicht nur mehr Details enthält (feinkörnige Ausrichtung), sondern auch die wichtigsten Kernattribute identifiziert und modelliert (Kernkomponentenextraktion und grobkörnige Ausrichtung).
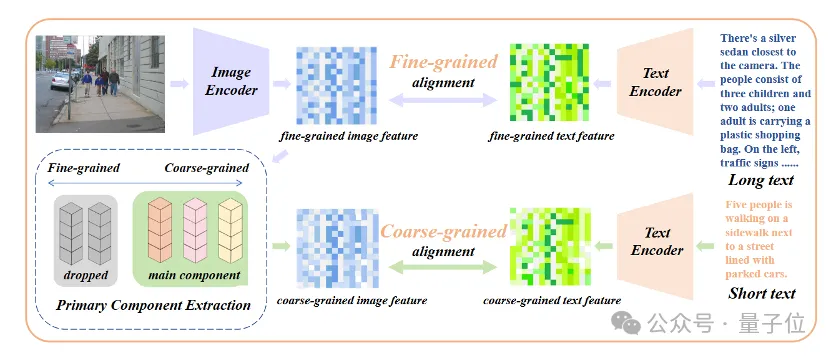 △Fügen Sie den Feinabstimmungsprozess der Kernattributausrichtung hinzu
△Fügen Sie den Feinabstimmungsprozess der Kernattributausrichtung hinzu
Plug-and-Play für verschiedene multimodale Aufgaben
In den Bereichen Bild- und Textabruf, Bildgenerierung und anderen Bereichen kann Long-CLIP Plug-and-Play-fähig sein abspielen, um CLIP zu ersetzen.
Beim Bild- und Textabruf kann Long-CLIP beispielsweise feinkörnigere Informationen im Bild- und Textmodus erfassen, wodurch die Fähigkeit zur Unterscheidung ähnlicher Bilder und Texte verbessert und die Leistung des Bild- und Textabrufs erheblich verbessert wird.
Ob es sich um herkömmliche Kurztext-Retrieval-Aufgaben (COCO, Flickr30k) oder Langtext-Retrieval-Aufgaben handelt, Long-CLIP hat die Erinnerungsrate deutlich verbessert. Experimentelle Ergebnisse zum Abrufen von kurzen Texten und Bildern Bilder
Darüber hinaus wird der Text-Encoder von CLIP häufig in Text-zu-Bild-Generierungsmodellen wie der Stable Diffusion-Serie usw. verwendet. Allerdings sind die Textbeschreibungen, die zur Generierung von Bildern verwendet werden, aufgrund fehlender Langtextfunktionen meist sehr kurz und können nicht mit verschiedenen Details angepasst werden. 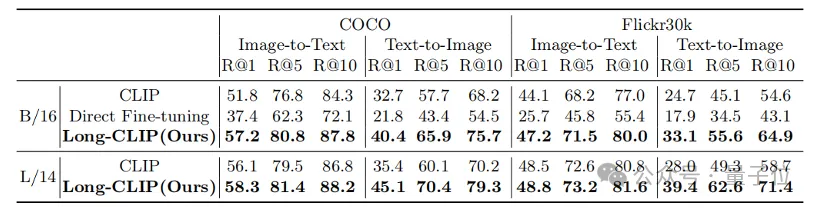
Papierlink:
Codelink:
https://github.com/beichenzbc/Long-CLIP
Das obige ist der detaillierte Inhalt vonDas neue Framework der Shanghai Jiao Tong University erschließt CLIP-Langtextfunktionen, erfasst die Details der multimodalen Generierung und verbessert die Bildabruffunktionen erheblich. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!