
Heim >Technologie-Peripheriegeräte >KI >DeepMind beendet die Illusion großer Modelle? Die Kennzeichnung von Fakten ist zuverlässiger als Menschen, 20-mal billiger und vollständig Open Source
DeepMind beendet die Illusion großer Modelle? Die Kennzeichnung von Fakten ist zuverlässiger als Menschen, 20-mal billiger und vollständig Open Source

- PHPznach vorne
- 2024-03-30 18:01:32665Durchsuche
Die Illusion großer Models hat endlich ein Ende?
Heute löste ein Beitrag auf der Social-Media-Plattform Reddit heftige Diskussionen unter Internetnutzern aus. In dem Beitrag wird ein von Google DeepMind gestern eingereichter Artikel „Langform-Faktizität in großen Sprachmodellen“ erörtert. Die in dem Artikel vorgeschlagenen Methoden und Ergebnisse lassen die Menschen zu dem Schluss kommen, dass die Illusion großer Sprachmodelle kein Problem mehr darstellt.

Wir wissen, dass große Sprachmodelle bei der Beantwortung faktensuchender Fragen zu offenen Themen häufig Inhalte mit sachlichen Fehlern generieren. DeepMind hat einige explorative Untersuchungen zu diesem Phänomen durchgeführt.
Um die lange Faktizität eines Modells im offenen Bereich zu bewerten, verwendeten Forscher GPT-4, um LongFact zu generieren, einen Eingabeaufforderungssatz mit 38 Themen und Tausenden von Fragen. Anschließend schlugen sie vor, den Search Augmented Fact Evaluator (SAFE) zu verwenden, um den LLM-Agenten als automatischen Evaluator für Fakten in Langform zu nutzen. Der Zweck von SAFE besteht darin, die Genauigkeit von Sachverständigen zur Beurteilung der Glaubwürdigkeit zu verbessern.
In Bezug auf SAFE kann die Verwendung von LLM die Genauigkeit jeder Instanz genauer erklären. Bei diesem mehrstufigen Argumentationsprozess wird eine Suchanfrage an die Google-Suche gesendet und ermittelt, ob die Suchergebnisse eine bestimmte Instanz unterstützen.

Papieradresse: https://arxiv.org/pdf/2403.18802.pdf
GitHub-Adresse: https://github.com/google-deepmind/long-form-factuality
Darüber hinaus schlugen die Forscher vor, den F1-Score (F1@K) zu einem praktischen Aggregatindikator in Langform zu erweitern. Sie gleichen den Prozentsatz der in der Antwort unterstützten Fakten (Präzision) mit dem Prozentsatz der bereitgestellten Fakten im Verhältnis zu einem Hyperparameter aus, der die bevorzugte Antwortlänge des Benutzers darstellt (Rückruf).
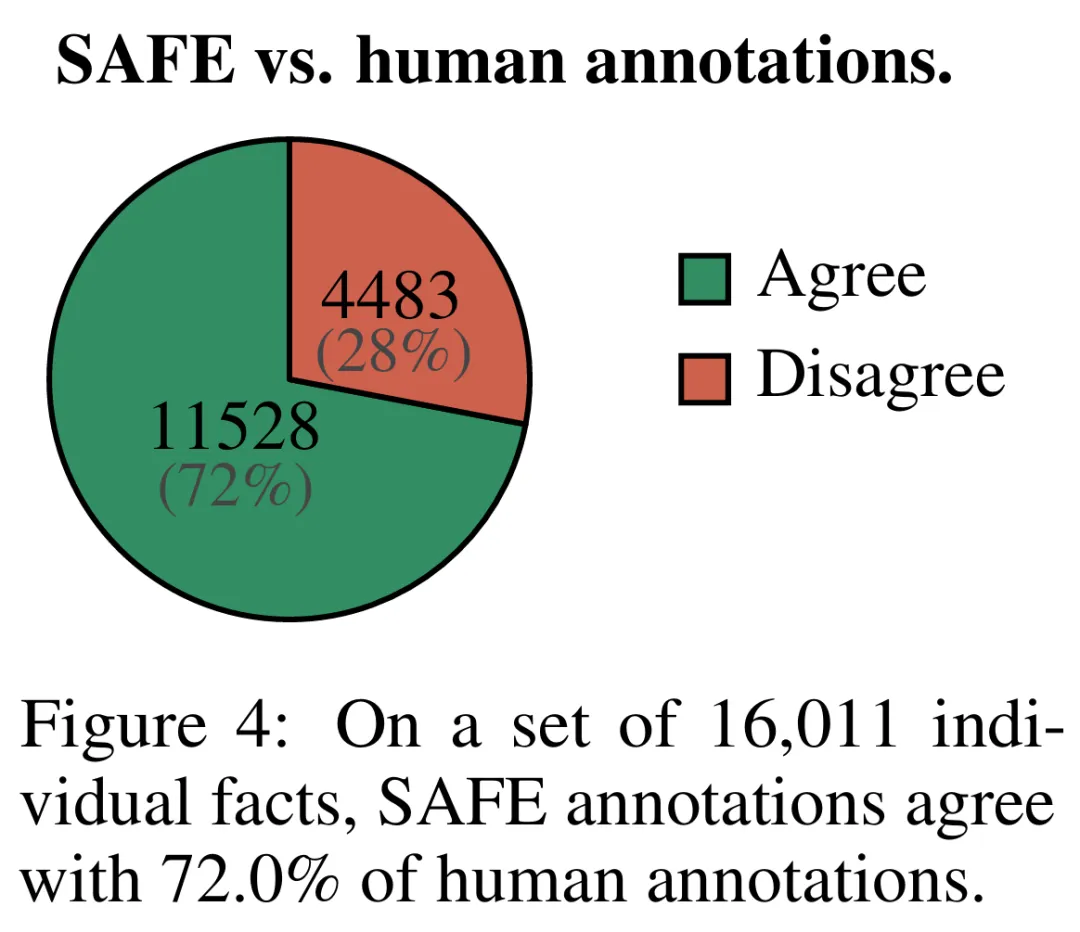
Empirische Ergebnisse zeigen, dass LLM-Agenten eine Bewertungsleistung erreichen können, die die von Menschen übertrifft. Bei einer Reihe von ca. 16.000 Einzelfakten stimmte SAFE in 72 % der Fälle mit menschlichen Annotatoren überein, und bei einer zufälligen Teilmenge von 100 Fällen von Meinungsverschiedenheiten erreichte SAFE eine Erfolgsquote von 76 %. Gleichzeitig ist SAFE mehr als 20-mal günstiger als menschliche Annotatoren.
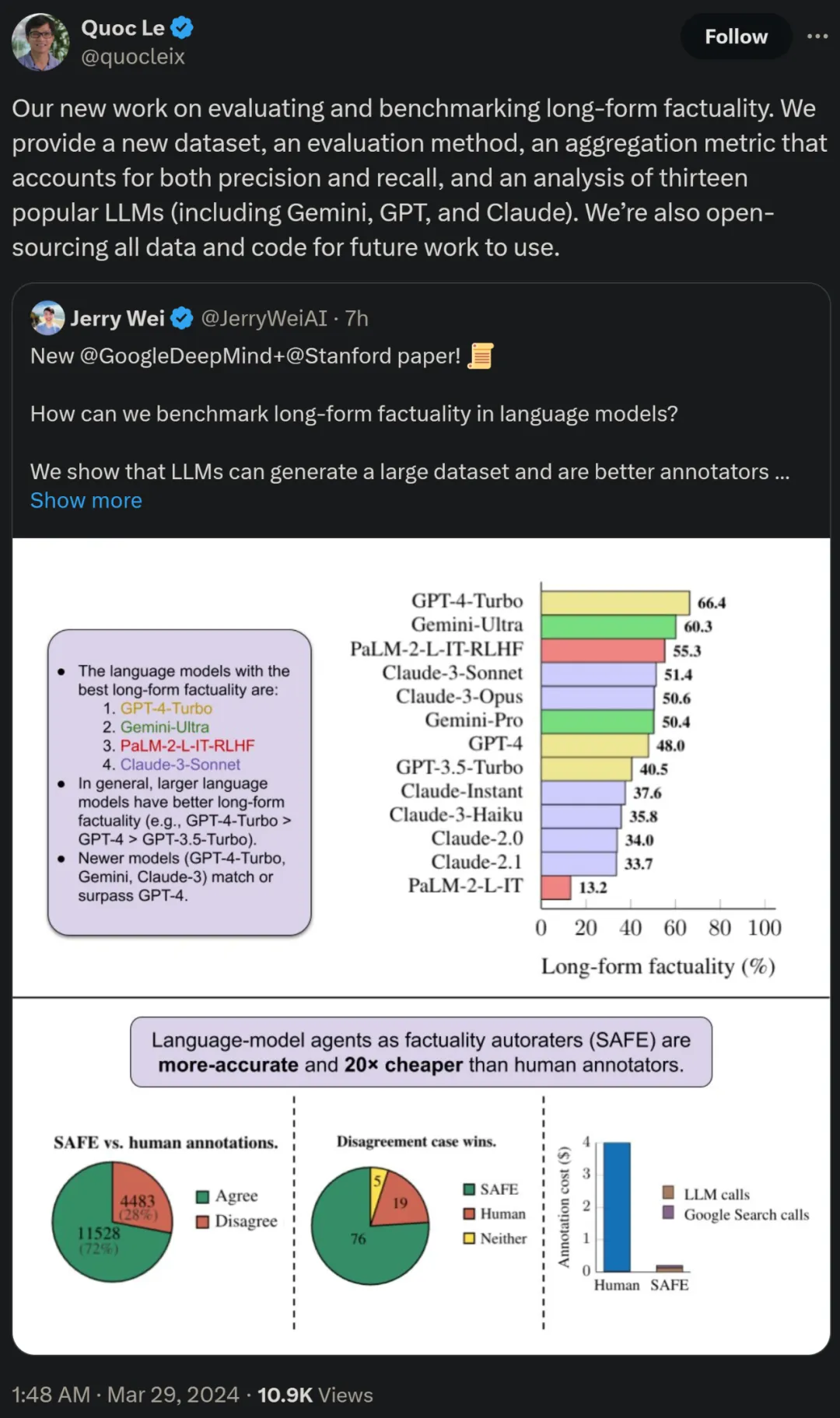
Die Forscher verwendeten LongFact auch zum Benchmarking von 13 beliebten Sprachmodellen in vier großen Modellreihen (Gemini, GPT, Claude und PaLM-2) und stellten fest, dass größere Sprachmodelle im Allgemeinen bessere Ergebnisse erzielen können.
Quoc V. Le, einer der Autoren des Papiers und Forschungswissenschaftler bei Google, sagte, dass diese neue Arbeit zur Bewertung und zum Benchmarking von Langform-Faktizitäten einen neuen Datensatz, eine neue Bewertungsmethode und eine Methode vorschlägt das die Genauigkeit und die aggregierte Erinnerungsmetrik in Einklang bringt. Gleichzeitig werden alle Daten und Codes für zukünftige Arbeiten Open Source sein.
Methodenübersicht
LONGFACT: Verwendung von LLM zum Generieren langer, faktischer Mehrthemen-Benchmarks
Schauen Sie sich zunächst den mit GPT-4 generierten LongFact-Eingabeaufforderungssatz an, der 2280 Eingabeaufforderungen für die Faktensuche enthält das erforderte ausführliche Antworten zu 38 manuell ausgewählten Themen. Den Forschern zufolge handelt es sich bei LongFact um die erste Reihe von Eingabeaufforderungen zur Bewertung der Faktizität in Langform in verschiedenen Bereichen.
LongFact enthält zwei Aufgaben: LongFact-Concepts und LongFact-Objects, unterschieden dadurch, ob die Frage nach Konzepten oder Objekten fragt. Die Forscher generierten 30 einzigartige Hinweise für jedes Thema, was zu 1140 Hinweisen für jede Aufgabe führte.

SAFE: LLM-Agent als sachlicher automatischer Bewerter
Die Forscher schlugen den Search Augmented Fact Evaluator (SAFE) vor, dessen Funktionsprinzip wie folgt ist:
a) Split lange Antworten in separate unabhängige Fakten aufteilen;
b) Bestimmen Sie, ob jeder einzelne Fakt für die Beantwortung der Aufforderung im Kontext relevant ist
c) Stellen Sie für jeden relevanten Fakt iterativ in einem mehrstufigen Prozess eine Google-Suchanfrage und überlegen Sie, ob die Suchergebnisse diesen Fakt unterstützen.
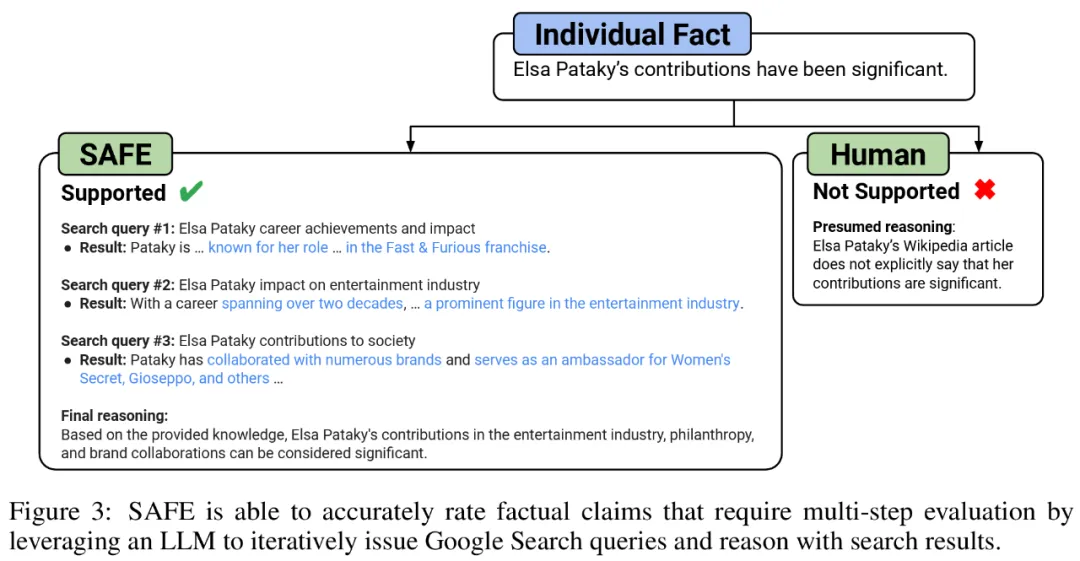
Sie glauben, dass die wichtigste Innovation von SAFE darin besteht, Sprachmodelle als Agenten zu verwenden, um mehrstufige Google-Suchanfragen zu generieren und sorgfältig zu prüfen, ob die Suchergebnisse die Fakten stützen. Abbildung 3 unten zeigt ein Beispiel der Argumentationskette.
Um die lange Antwort in separate unabhängige Fakten aufzuteilen, veranlassten die Forscher zunächst das Sprachmodell, jeden Satz in der langen Antwort in separate Fakten aufzuteilen, und wies das Modell dann an, mehrdeutige Referenzen wie Pronomen mit zu trennen die richtigen Entitäten, auf die sie im Antwortkontext verweisen, und modifizieren jeden einzelnen Fakt so, dass er unabhängig ist.
Um jede unabhängige Tatsache zu bewerten, verwenden sie ein Sprachmodell, um zu überlegen, ob diese Tatsache für die im Antwortkontext beantwortete Frage relevant ist, und verwenden dann eine mehrstufige Methode, um jede verbleibende relevante Tatsache als „unterstützt“ zu bewerten. oder „nicht unterstützt“. Die Details sind in Abbildung 1 unten dargestellt.
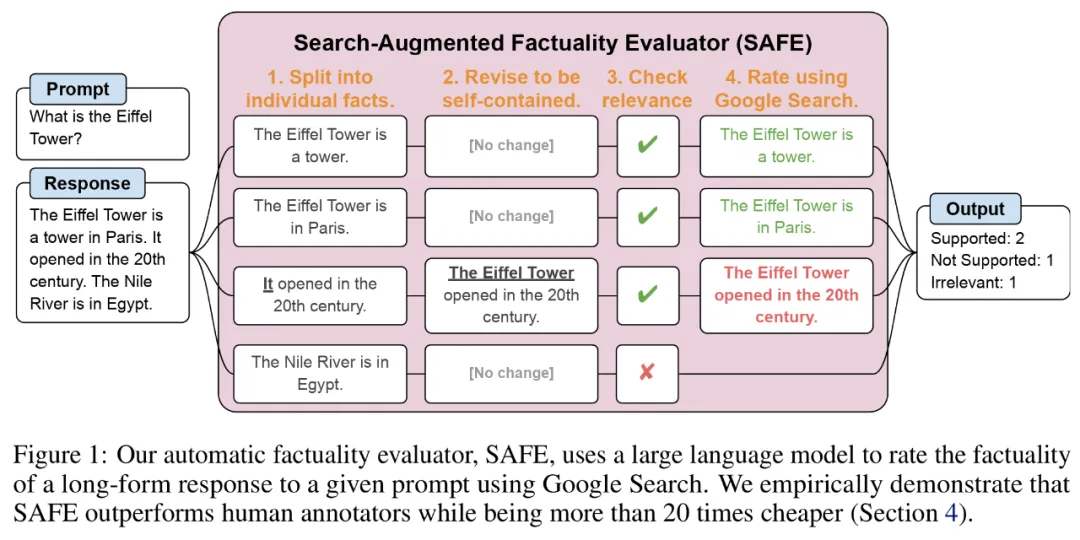
Bei jedem Schritt generiert das Modell eine Suchanfrage basierend auf den zu bewertenden Fakten und den zuvor erhaltenen Suchergebnissen. Nach einer bestimmten Anzahl von Schritten führt das Modell eine Inferenz durch, um zu bestimmen, ob die Suchergebnisse diese Tatsache unterstützen, wie in Abbildung 3 oben dargestellt. Nachdem alle Fakten bewertet wurden, sind die Ausgabemetriken von SAFE für ein bestimmtes Eingabeaufforderungs-Antwort-Paar die Anzahl „unterstützender“ Fakten, die Anzahl „irrelevanter“ Fakten und die Anzahl „nicht unterstützter“ Fakten.
Experimentelle Ergebnisse: LLM-Agenten werden zu besseren Faktenannotatoren als Menschen. Die Daten enthalten 496 Prompt-Response-Paare, wobei die Antworten manuell in einzelne Fakten aufgeteilt wurden (insgesamt 16.011 einzelne Fakten) und jede einzelne Tatsache manuell als unterstützt, irrelevant oder nicht unterstützt gekennzeichnet wurde.
Sie verglichen SAFE-Anmerkungen und menschliche Anmerkungen für jeden Fakt direkt und stellten fest, dass SAFE bei 72,0 % der einzelnen Fakten mit Menschen übereinstimmte, wie in Abbildung 4 unten dargestellt. Dies zeigt, dass SAFE bei den meisten einzelnen Fakten eine Leistung auf menschlichem Niveau erreicht. Anschließend wurde eine Teilmenge von 100 Einzelfakten aus Zufallsinterviews untersucht, bei denen die Anmerkungen von SAFE nicht mit denen menschlicher Bewerter übereinstimmten.
Die Forscher kommentierten jeden Sachverhalt manuell neu (was den Zugriff auf die Google-Suche und nicht nur auf Wikipedia für eine umfassendere Anmerkung ermöglichte) und verwendeten diese Bezeichnungen als Grundwahrheit. Sie fanden heraus, dass in diesen Fällen von Meinungsverschiedenheiten die SAFE-Anmerkungen in 76 % der Fälle korrekt waren, während menschliche Anmerkungen nur in 19 % der Fälle korrekt waren, was einer 4:1-Siegquote für SAFE entspricht. Die Details sind in Abbildung 5 unten dargestellt.
Hier lohnt es sich, auf die Preise der beiden Annotationspläne zu achten. Die Kosten für die Bewertung einer einzelnen Modellantwort mithilfe menschlicher Anmerkungen betragen 4 US-Dollar, während die SAFE-Bewertung mit GPT-3.5-Turbo und der Serper-API nur 0,19 US-Dollar beträgt.
Benchmark-Tests für die Serien Gemini, GPT, Claude und PaLM-2
Abschließend führten die Forscher LongFact für die vier Modellreihen (Gemini, GPT, Claude und PaLM-2) in Tabelle 1 durch unten 2) Führte umfangreiche Benchmark-Tests an 13 großen Sprachmodellen durch. 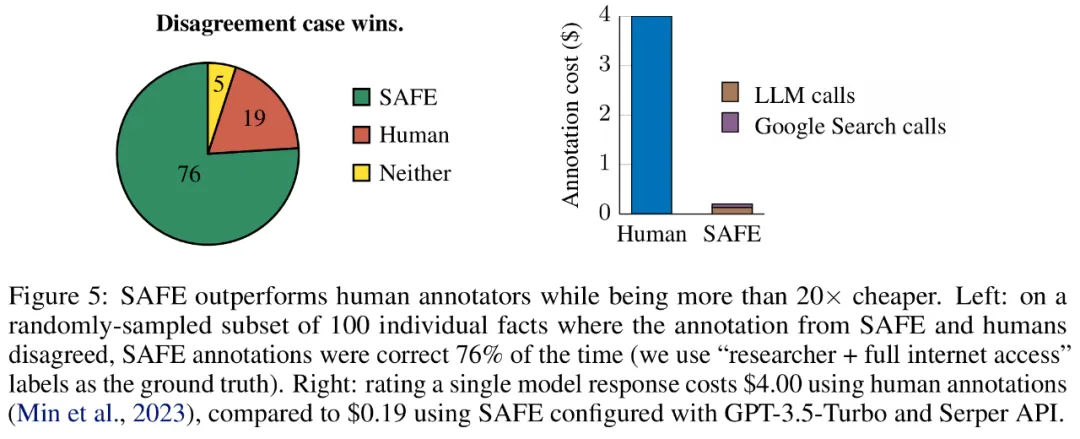
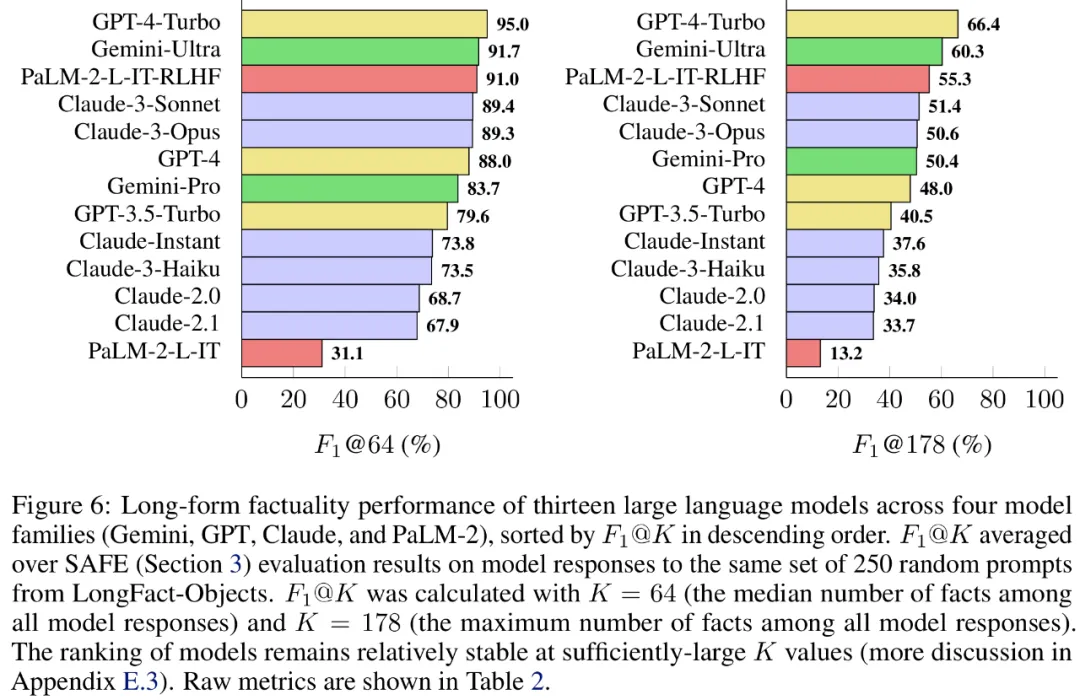
Konkret bewerteten sie jedes Modell anhand derselben zufälligen Teilmenge von 250 Hinweisen in LongFact-Objects, verwendeten dann SAFE, um die rohen Bewertungsmetriken der Reaktion jedes Modells zu erhalten, und verwendeten die F1@K-Polymerisation.
Es wurde festgestellt, dass größere Sprachmodelle im Allgemeinen eine bessere Langform-Faktizität erreichen. Wie in Abbildung 6 und Tabelle 2 unten gezeigt, ist GPT-4-Turbo besser als GPT-4, GPT-4 ist besser als GPT-3.5-Turbo, Gemini-Ultra ist besser als Gemini-Pro und PaLM-2-L -IT-RLHF Besser als PaLM-2-L-IT.
Weitere technische Details und experimentelle Ergebnisse finden Sie im Originalpapier.
Das obige ist der detaillierte Inhalt vonDeepMind beendet die Illusion großer Modelle? Die Kennzeichnung von Fakten ist zuverlässiger als Menschen, 20-mal billiger und vollständig Open Source. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Detaillierte Erläuterung der Verwendung des Orbit Controls-Plug-Ins (Orbit Control) durch Three.js zur Steuerung der Modellinteraktion
- Welche sind die am häufigsten verwendeten logischen Modelle in Datenbanken?
- So ändern Sie die Größe von ai
- Was ist ein Softwareentwicklungsmodell und welche gängigen Softwareentwicklungsmodelle gibt es?
- Routing ist die Hauptfunktion welcher Schicht im osi-Modell