
Heim >Technologie-Peripheriegeräte >KI >Aufmerksamkeit ist nicht alles, was Sie brauchen! Mamba-Hybrid-Großmodell Open Source: dreifacher Transformer-Durchsatz
Aufmerksamkeit ist nicht alles, was Sie brauchen! Mamba-Hybrid-Großmodell Open Source: dreifacher Transformer-Durchsatz

- WBOYnach vorne
- 2024-03-30 09:41:16923Durchsuche
Mamba-Zeit ist gekommen?
Seit der Veröffentlichung der wegweisenden Forschungsarbeit „Attention is All You Need“ im Jahr 2017 dominiert die Transformer-Architektur das Feld der generativen künstlichen Intelligenz.
Allerdings hat die Transformer-Architektur tatsächlich zwei wesentliche Nachteile:
Der Speicherbedarf von Transformer variiert mit der Kontextlänge. Dies macht es schwierig, lange Kontextfenster oder umfangreiche Parallelverarbeitung ohne erhebliche Hardware-Ressourcen auszuführen, wodurch weitreichende Experimente und Bereitstellungen eingeschränkt werden. Der Speicherbedarf von Transformer-Modellen skaliert mit der Kontextlänge, wodurch es schwierig wird, lange Kontextfenster oder stark parallele Verarbeitung ohne nennenswerte Hardwareressourcen auszuführen, wodurch weitreichende Experimente und Bereitstellungen eingeschränkt werden.
Der Aufmerksamkeitsmechanismus im Transformer-Modell passt die Geschwindigkeit entsprechend der Zunahme der Kontextlänge an. Dieser Mechanismus erweitert die Sequenzlänge zufällig und reduziert den Rechenaufwand, da jedes Token von der gesamten Sequenz davor abhängt Reduzieren des Kontexts Wird außerhalb des Rahmens einer effizienten Produktion angewendet.
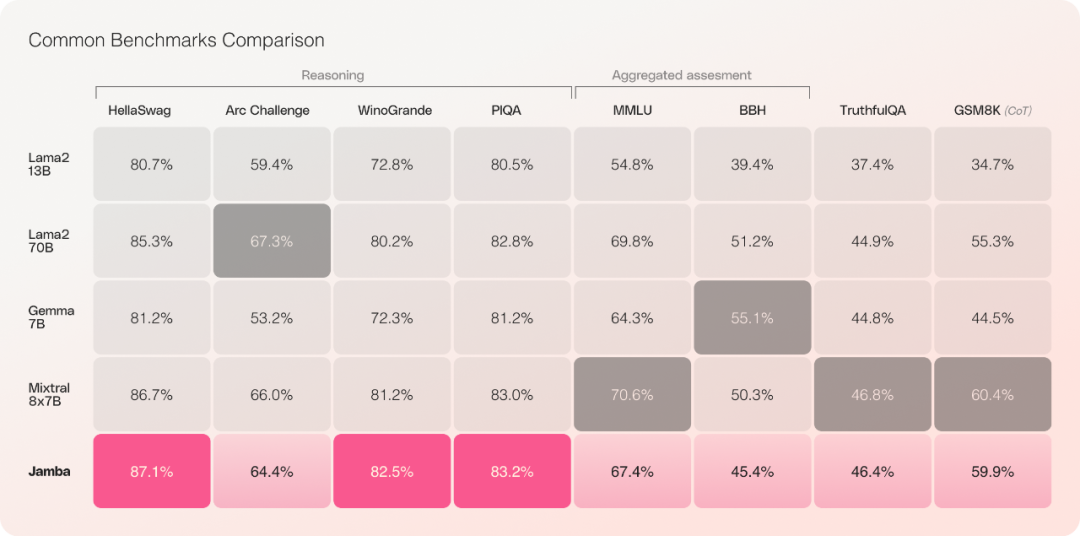
Transformer ist nicht der einzige Weg nach vorne für künstliche Intelligenz in der Produktion. Kürzlich haben AI21 Labs eine neue Methode namens „Jamba“ eingeführt und als Open-Source-Lösung bereitgestellt, die den Transformer in mehreren Benchmarks übertrifft.

Hugging Face-Adresse: https://huggingface.co/ai21labs/Jamba-v0.1
Mambas SSM-Architektur kann die Speicherressourcen und Kontextprobleme des Transformators gut lösen. Allerdings hat der Mamba-Ansatz Schwierigkeiten, das gleiche Leistungsniveau wie das Transformer-Modell zu liefern.
Jamba kombiniert das Mamba-Modell basierend auf dem Structured State Space Model (SSM) mit der Transformer-Architektur und zielt darauf ab, die besten Eigenschaften von SSM und Transformer zu kombinieren.

Jamba ist auch über den NVIDIA API-Katalog als NVIDIA NIM-Inferenz-Microservice zugänglich, den Entwickler von Unternehmensanwendungen mithilfe der NVIDIA AI Enterprise-Softwareplattform bereitstellen können.
Im Allgemeinen weist das Jamba-Modell die folgenden Merkmale auf:
Das erste auf Mamba basierende Modell auf Produktionsebene, das die neuartige SSM-Transformer-Hybridarchitektur verwendet.
Im Vergleich zu Mixtral 8x7B beträgt der Durchsatz um das Dreifache erhöht;
bietet Zugriff auf 256.000 Kontextfenster;
Das einzige Modell mit der gleichen Parameterskala, das bis zu 140.000 Kontexte auf einer einzelnen GPU aufnehmen kann.
- Modellarchitektur
Wie in der Abbildung unten dargestellt, verfolgt Jambas Architektur einen Block-und-Schichten-Ansatz, der es Jamba ermöglicht, die beiden Architekturen zu integrieren. Jeder Jamba-Block besteht aus einer Aufmerksamkeitsschicht oder einer Mamba-Schicht, gefolgt von einem mehrschichtigen Perzeptron (MLP), das eine Transformatorschicht bildet.
Jamba nutzt MoE, um die Gesamtzahl der Modellparameter zu erhöhen und gleichzeitig die Anzahl der in der Inferenz verwendeten aktiven Parameter zu vereinfachen, was zu einer höheren Modellkapazität ohne entsprechende Erhöhung der Rechenanforderungen führt. Um die Modellqualität und den Durchsatz auf einer einzelnen 80-GB-GPU zu maximieren, optimierte das Forschungsteam die Anzahl der verwendeten MoE-Schichten und Experten und ließ so genügend Speicher für gängige Inferenz-Workloads übrig.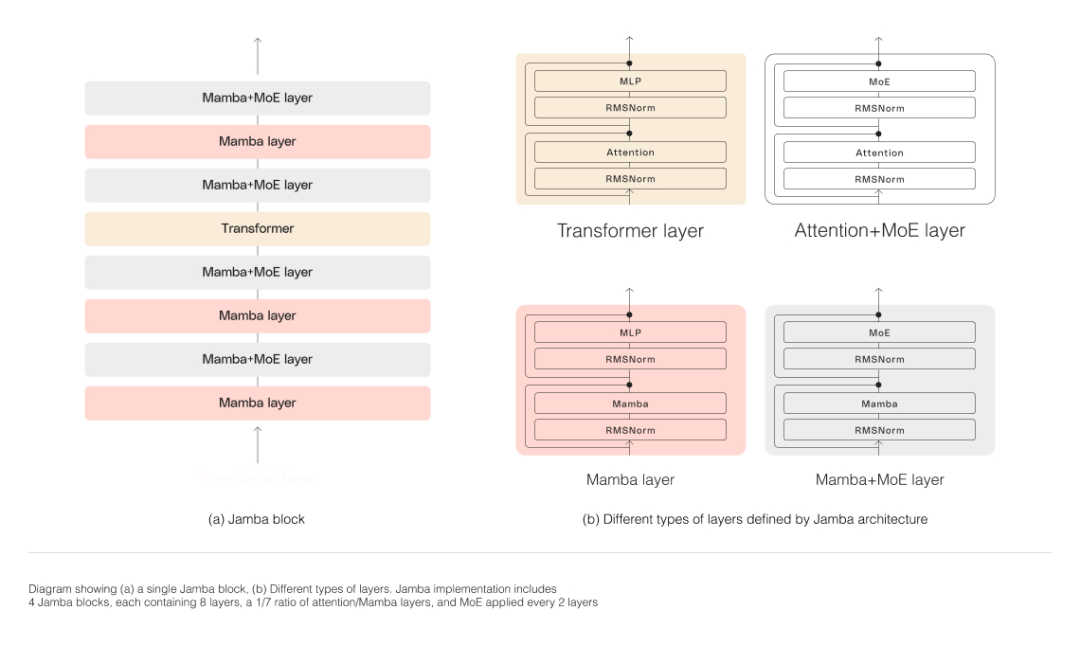 Jambas MoE-Schicht ermöglicht die Nutzung von nur 12B der verfügbaren 52B Parameter zur Inferenzzeit und seine Hybridarchitektur macht diese 12B aktiven Parameter effizienter als ein reines Transformatormodell derselben Größe.
Jambas MoE-Schicht ermöglicht die Nutzung von nur 12B der verfügbaren 52B Parameter zur Inferenzzeit und seine Hybridarchitektur macht diese 12B aktiven Parameter effizienter als ein reines Transformatormodell derselben Größe. Niemand hat Mamba bisher über die 3B-Parameter hinaus erweitert. Jamba ist die erste Hybridarchitektur ihrer Art, die den Produktionsmaßstab erreicht.
Durchsatz und EffizienzVorläufige Evaluierungsexperimente zeigen, dass Jamba bei wichtigen Kennzahlen wie Durchsatz und Effizienz gut abschneidet. In Bezug auf die Effizienz erreicht Jamba bei langen Kontexten den dreifachen Durchsatz von Mixtral 8x7B. Jamba ist effizienter als Transformer-basierte Modelle ähnlicher Größe wie Mixtral 8x7B.
Was die Kosten betrifft, kann Jamba 140.000 Kontexte auf einer einzigen GPU unterbringen. Jamba bietet mehr Bereitstellungs- und Experimentiermöglichkeiten als andere aktuelle Open-Source-Modelle ähnlicher Größe.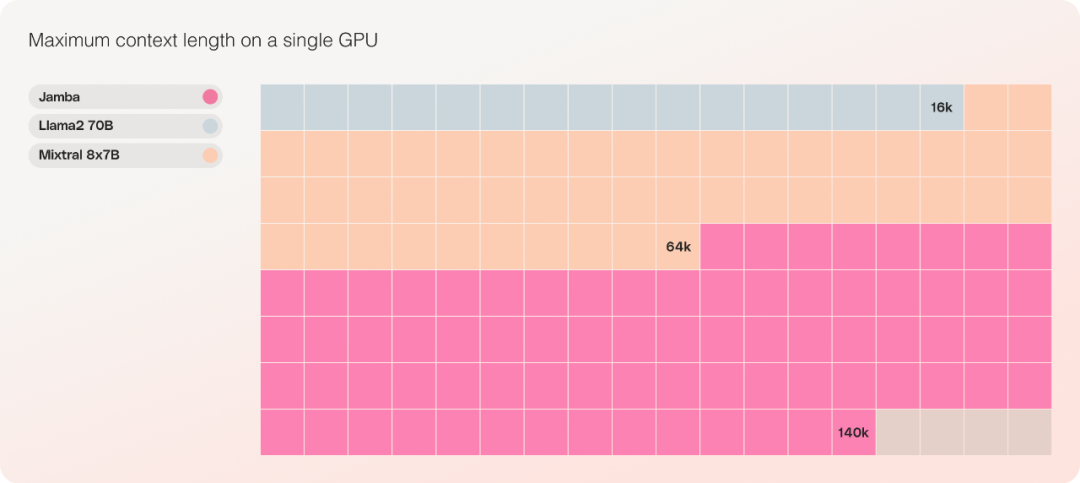
Es ist zu beachten, dass Jamba derzeit wahrscheinlich nicht die aktuellen Transformer-basierten Large Language Models (LLM) ersetzen wird, in einigen Bereichen jedoch möglicherweise eine Ergänzung darstellt.
Referenzlink:
https://www.ai21.com/blog/anncreasing-jamba
https://venturebeat.com/ai/ai21-labs-juices-up- gen-ai-transformers-with-jamba/
Das obige ist der detaillierte Inhalt vonAufmerksamkeit ist nicht alles, was Sie brauchen! Mamba-Hybrid-Großmodell Open Source: dreifacher Transformer-Durchsatz. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Künstliche Intelligenz bringt neuen Schwung in die Pharmaindustrie meines Landes
- Ein langer Artikel mit 10.000 Wörtern: Dekonstruktion der Kette, Lösungen und unternehmerischen Möglichkeiten der KI-Sicherheitsbranche
- Die 360 Group gewann die Auszeichnung „China Data Intelligence Industry AI Large Model Pioneer Enterprise' basierend auf 360 Intelligent Brain
- So lösen Sie das Problem der hohen Speichernutzung in Win10