
Heim >Technologie-Peripheriegeräte >KI >DifFlow3D: Neues SOTA zur Szenenflussschätzung, das Diffusionsmodell hat einen weiteren Erfolg!
DifFlow3D: Neues SOTA zur Szenenflussschätzung, das Diffusionsmodell hat einen weiteren Erfolg!

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2024-03-28 14:00:09474Durchsuche
Originaltitel: DifFlow3D: Toward Robust Uncertainty-Aware Scene Flow Estimation with Iterative Diffusion-Based Refinement
Papierlink: https://arxiv.org/pdf/2311.17456.pdf
Codelink: https://github. com/IRMVLab/DifFlow3D
Autorenzugehörigkeit: Shanghai Jiao Tong University Cambridge University Zhejiang University Intelligent Robot

Thesis-Idee:
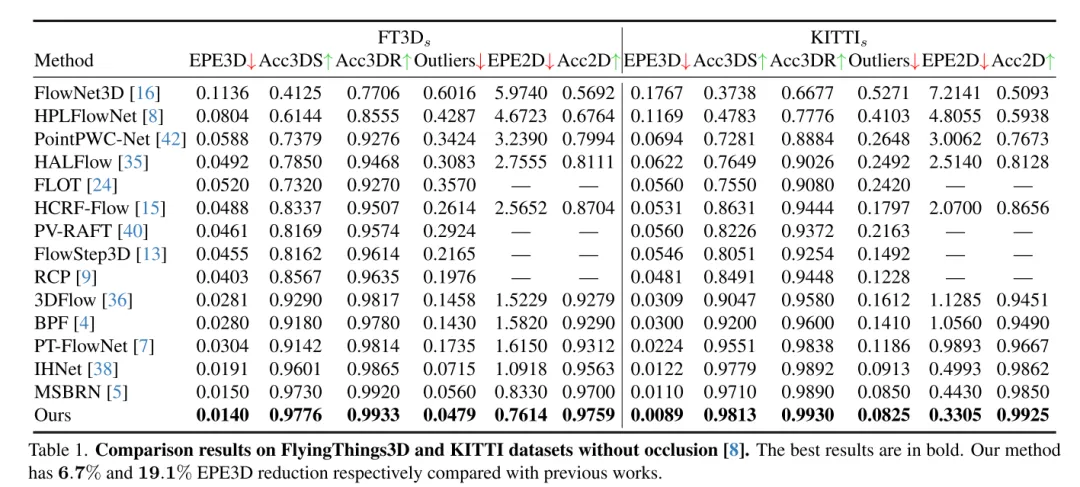
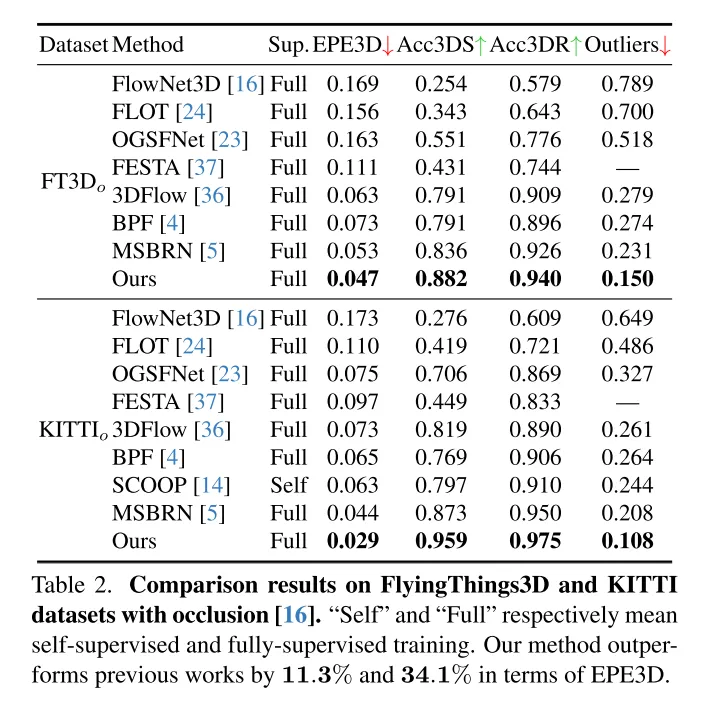
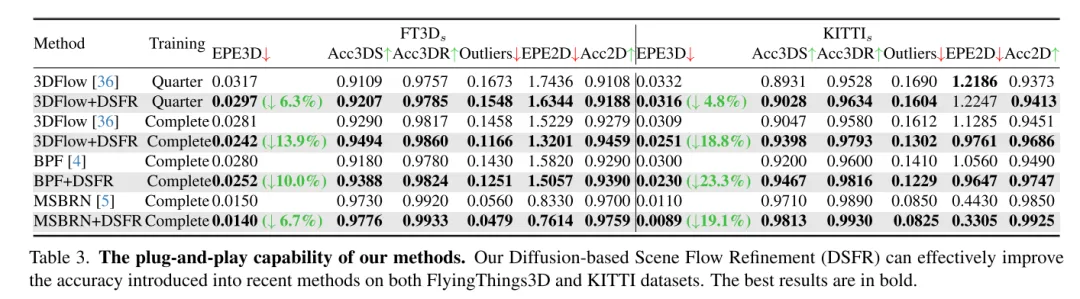
Szenenflussschätzung zielt darauf ab, die 3D-Verschiebungsänderung jedes Punktes in einer dynamischen Szene vorherzusagen. Es ist eine grundlegende Aufgabe im Bereich Computer Vision. Frühere Arbeiten leiden jedoch häufig unter unzuverlässigen Korrelationen, die durch lokal begrenzte Suchbereiche verursacht werden, und häufen Ungenauigkeiten in groben bis feinen Strukturen an. Um diese Probleme zu lindern, schlägt dieser Artikel ein neuartiges, unsicherheitsbewusstes Netzwerk zur Schätzung des Szenenflusses (DifFlow3D) vor, das ein Diffusions-Wahrscheinlichkeitsmodell verwendet. Die iterative diffusionsbasierte Verfeinerung soll die Robustheit der Korrelation verbessern und eine starke Anpassungsfähigkeit an schwierige Situationen (z. B. Dynamik, verrauschte Eingaben, wiederholte Muster usw.) bieten. Um die Vielfalt der Erzeugung zu begrenzen, werden in unserem Diffusionsmodell drei wichtige strömungsbezogene Merkmale als Bedingungen ausgenutzt. Darüber hinaus wird in diesem Artikel ein Unsicherheitsschätzungsmodul für die Diffusion entwickelt, um die Zuverlässigkeit des geschätzten Szenenflusses zu bewerten. DifFlow3D dieses Artikels erreicht eine Reduzierung der dreidimensionalen Endpunktfehler (EPE3D) um 6,7 % bzw. 19,1 % bei den Datensätzen FlyingThings3D und KITTI 2015 und erreicht eine beispiellose Genauigkeit auf Millimeterebene beim KITTI-Datensatz (0,0089 Meter für EPE3D). Darüber hinaus kann unser diffusionsbasiertes Verfeinerungsparadigma problemlos als Plug-and-Play-Modul in bestehende Szenenflussnetzwerke integriert werden, wodurch deren Schätzgenauigkeit erheblich verbessert wird.
Hauptbeiträge:
Um eine robuste Szenenflussschätzung zu erreichen, schlägt diese Studie einen neuen diffusionsbasierten Plug-and-Play-Verfeinerungsprozess vor. Nach unserem besten Wissen ist dies das erste Mal, dass ein Diffusions-Wahrscheinlichkeitsmodell in einer Szenenflussaufgabe eingesetzt wurde.
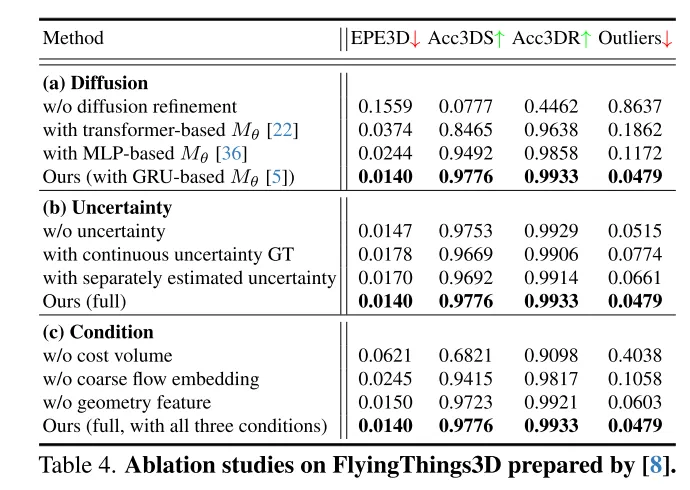
Der Autor kombiniert Techniken wie grobe Flusseinbettung, geometrische Kodierung und Cross-Frame-Kostenvolumina, um eine effektive bedingte Führungsmethode zur Steuerung der Vielfalt der generierten Ergebnisse zu entwerfen.
Um die Zuverlässigkeit der Flüsse in diesem Artikel zu bewerten und ungenaue Punktübereinstimmungen zu identifizieren, führen die Autoren auch Unsicherheitsschätzungen für jeden Punkt im Diffusionsmodell ein.
Die Forschungsergebnisse zeigen, dass die in diesem Artikel vorgeschlagene Methode bei den FlyingThings3D- und KITTI-Datensätzen eine gute Leistung erbringt und andere bestehende Methoden übertrifft. Insbesondere erreicht DifFlow3D zum ersten Mal einen Endpunktfehler auf Millimeterebene (EPE3D) im KITTI-Datensatz. Im Vergleich zu früheren Untersuchungen ist unsere Methode robuster im Umgang mit herausfordernden Situationen wie lauten Eingaben und dynamischen Änderungen.
Netzwerkdesign:
Als grundlegende Aufgabe in der Bildverarbeitung bezeichnet Szenenfluss die Schätzung eines dreidimensionalen Bewegungsfelds aus kontinuierlichen Bildern oder Punktwolken. Es liefert Informationen für die Wahrnehmung dynamischer Szenen auf niedriger Ebene und verfügt über verschiedene nachgelagerte Anwendungen, wie etwa autonomes Fahren [21], Posenschätzung [9] und Bewegungssegmentierung [1]. Frühe Arbeiten konzentrierten sich auf die Verwendung von Stereo- [12] oder RGB-D-Bildern [10] als Eingabe. Mit der zunehmenden Beliebtheit von 3D-Sensoren wie Lidar verwenden neuere Arbeiten häufig Punktwolken direkt als Eingabe.
Als Pionierarbeit verwendet FlowNet3D[16] PointNet++[25], um hierarchische Merkmale zu extrahieren, und führt dann eine iterative Regression des Szenenflusses durch. PointPWC [42] verbessert es weiter durch Pyramiden-, Verformungs- und Kostenvolumenstrukturen [31]. HALFlow [35] folgt ihnen und führt einen Aufmerksamkeitsmechanismus zur besseren Flusseinbettung ein. Diese regressionsbasierten Arbeiten leiden jedoch häufig unter unzuverlässigen Korrelationen und lokalen Optimaproblemen [17]. Dafür gibt es zwei Hauptgründe: (1) In ihrem Netzwerk werden K nächste Nachbarn (KNN) zur Suche nach Punktkorrespondenzen verwendet, wobei korrekte, aber entfernte Punktpaare nicht berücksichtigt werden, und es gibt auch Übereinstimmungsrauschen [7]. (2) Ein weiteres potenzielles Problem ergibt sich aus der in früheren Arbeiten weit verbreiteten Grob-Fein-Struktur [16, 35, 36, 42]. Grundsätzlich wird der anfängliche Fluss auf der gröbsten Schicht geschätzt und dann iterativ in höheren Auflösungen verfeinert. Die Leistung der Strömungsverfeinerung hängt jedoch stark von der Zuverlässigkeit der anfänglichen Grobströmung ab, da nachfolgende Verfeinerungen normalerweise auf eine kleine räumliche Ausdehnung um die Initialisierung herum beschränkt sind.
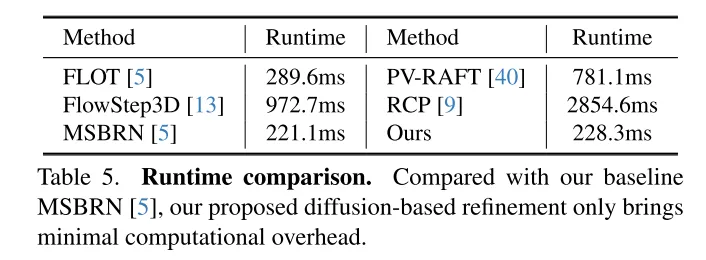
Um das Problem der Unzuverlässigkeit zu lösen, hat 3DFlow[36] ein All-to-All-Punkteerfassungsmodul entwickelt und eine umgekehrte Überprüfung hinzugefügt. In ähnlicher Weise schlagen Bi-PointFlowNet [4] und seine Erweiterung MSBRN [5] ein bidirektionales Netzwerk mit Vorwärts-Rückwärts-Korrelation vor. IHNet [38] nutzt ein wiederkehrendes Netzwerk mit einem hochauflösenden Bootstrapping- und Resampling-Schema. Allerdings leiden die meisten dieser Netzwerke aufgrund ihrer bidirektionalen Korrelationen oder Schleifeniterationen unter Rechenkosten. In diesem Artikel wird festgestellt, dass Diffusionsmodelle dank ihrer entrauschenden Natur (dargestellt in Abbildung 1) auch die Zuverlässigkeit von Korrelationen und die Widerstandsfähigkeit gegenüber Anpassungsrauschen verbessern können. Inspiriert von der Entdeckung in [30], dass die Injektion von zufälligem Rauschen dazu beiträgt, aus dem lokalen Optimum herauszuspringen, rekonstruiert dieser Artikel die deterministische Flussregressionsaufgabe mithilfe eines probabilistischen Diffusionsmodells, wie in Abbildung 2 dargestellt. Darüber hinaus kann unsere Methode als Plug-and-Play-Modul verwendet werden, um das vorherige Szenenflussnetzwerk zu bedienen, das allgemeiner ist und fast keine Rechenkosten verursacht (Abschnitt 4.5).
Allerdings ist die Nutzung generativer Modelle in der Aufgabe dieser Arbeit aufgrund der inhärenten generativen Vielfalt von Diffusionsmodellen eine ziemliche Herausforderung. Im Gegensatz zur Punktwolkengenerierungsaufgabe, die verschiedene Ausgabebeispiele erfordert, ist die Szenenflussvorhersage eine deterministische Aufgabe, die präzise Bewegungsvektoren pro Punkt berechnet. Um dieses Problem zu lösen, nutzt dieser Artikel starke bedingte Informationen, um die Diversität zu begrenzen und den erzeugten Fluss effektiv zu steuern. Insbesondere wird zunächst ein grober, spärlicher Szenenfluss initialisiert, und dann werden durch Diffusion iterativ Flussreste generiert. In jeder diffusionsbasierten Verfeinerungsschicht nutzen wir Grobströmungseinbettung, Kostenvolumen und geometrische Kodierung als Bedingungen. In diesem Fall wird Diffusion angewendet, um tatsächlich eine probabilistische Zuordnung von bedingten Eingaben zu Stream-Residuen zu lernen.
Darüber hinaus haben nur wenige frühere Arbeiten die Zuverlässigkeit und Zuverlässigkeit der Szenenflussschätzung untersucht. Wie in Abbildung 1 dargestellt, ist das Dense-Flow-Matching jedoch bei Vorhandensein von Rauschen, dynamischen Änderungen, kleinen Objekten und sich wiederholenden Mustern fehleranfällig. Daher ist es sehr wichtig zu wissen, ob jede geschätzte Punktkorrespondenz zuverlässig ist. Inspiriert durch den jüngsten Erfolg der Unsicherheitsschätzung bei optischen Flussaufgaben [33] schlagen wir eine punktweise Unsicherheit im Diffusionsmodell vor, um die Zuverlässigkeit unserer Szenenflussschätzung zu bewerten.
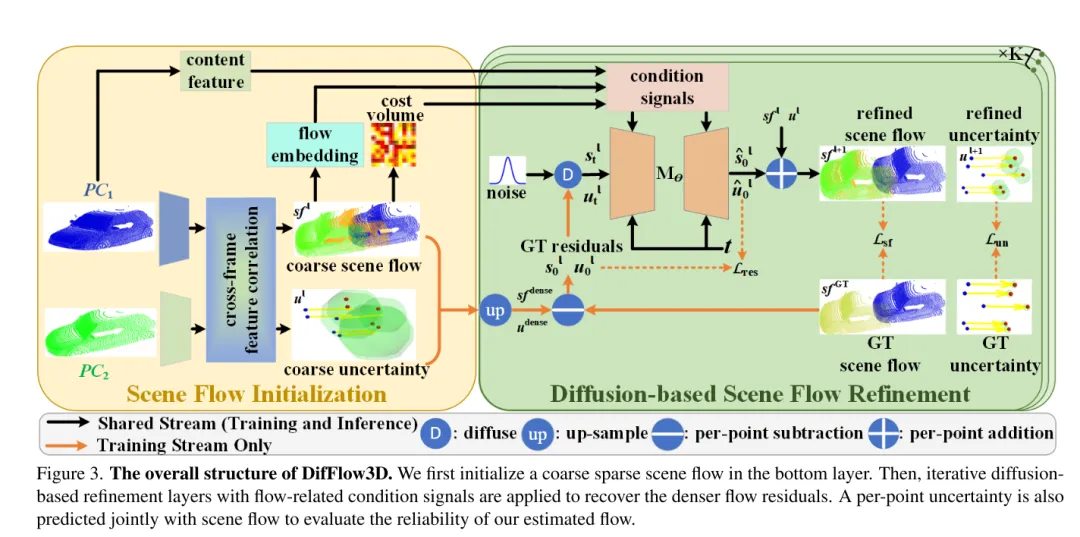
Bild 3. Die Gesamtstruktur von DifFlow3D. In diesem Artikel wird zunächst ein grober, spärlicher Szenenfluss in der unteren Ebene initialisiert. Anschließend werden iterative Diffusionsverfeinerungsschichten in Verbindung mit strömungsbezogenen bedingten Signalen verwendet, um dichtere Strömungsreste wiederherzustellen. Um die Zuverlässigkeit der in diesem Artikel geschätzten Flüsse zu bewerten, wird die Unsicherheit an jedem Punkt auch gemeinsam mit dem Szenenfluss vorhergesagt.
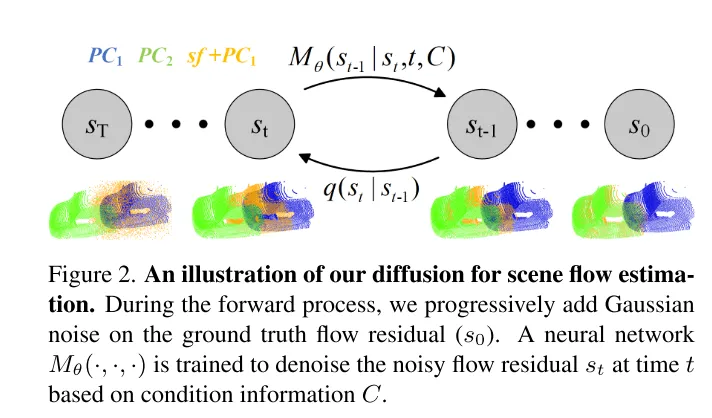
Bild 2. Schematische Darstellung des Diffusionsprozesses, der in diesem Artikel zur Szenenflussschätzung verwendet wird.
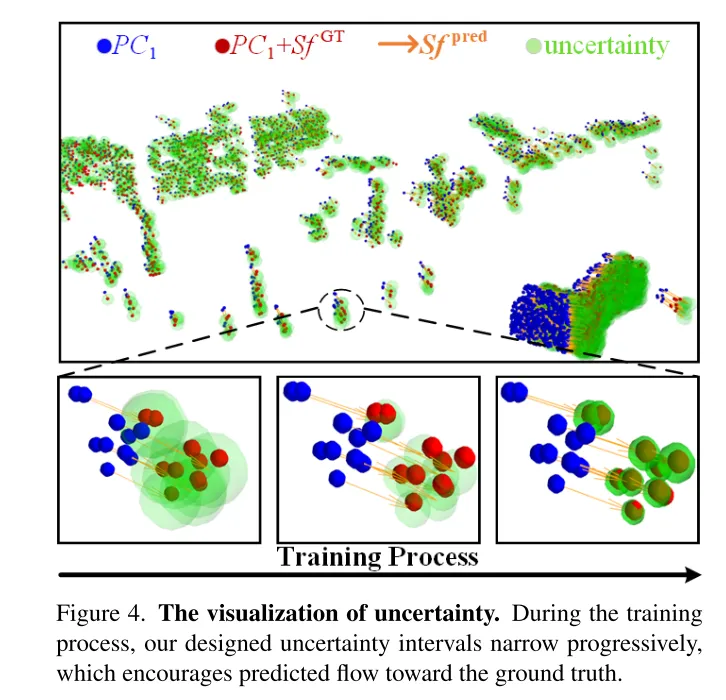
Bild 4. Unsicherheit visualisieren. Während des Trainingsprozesses schrumpft das in diesem Artikel entworfene Unsicherheitsintervall allmählich, was dazu führt, dass sich der vorhergesagte Fluss dem wahren Wert annähert.
Experimentelle Ergebnisse:
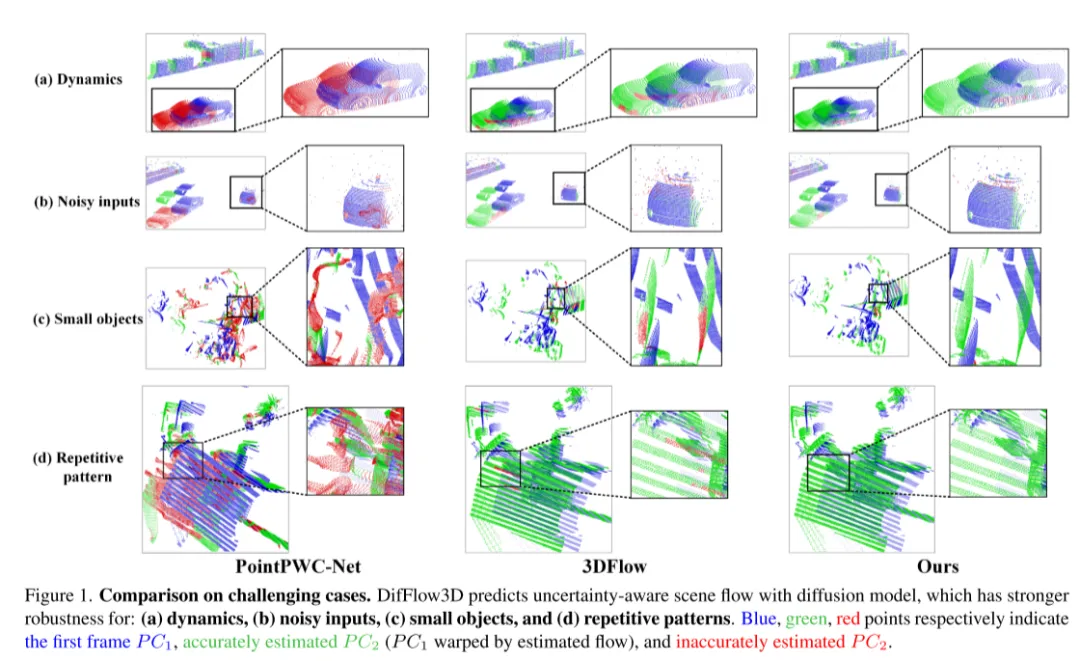
Abbildung 1. Vergleich in herausfordernden Situationen. DifFlow3D sagt einen unsicheren Szenenfluss mithilfe eines Diffusionsmodells voraus, das robuster ist gegenüber: (a) dynamischen Änderungen, (b) verrauschten Eingaben, (c) kleinen Objekten und (d)) sich wiederholenden Mustern.
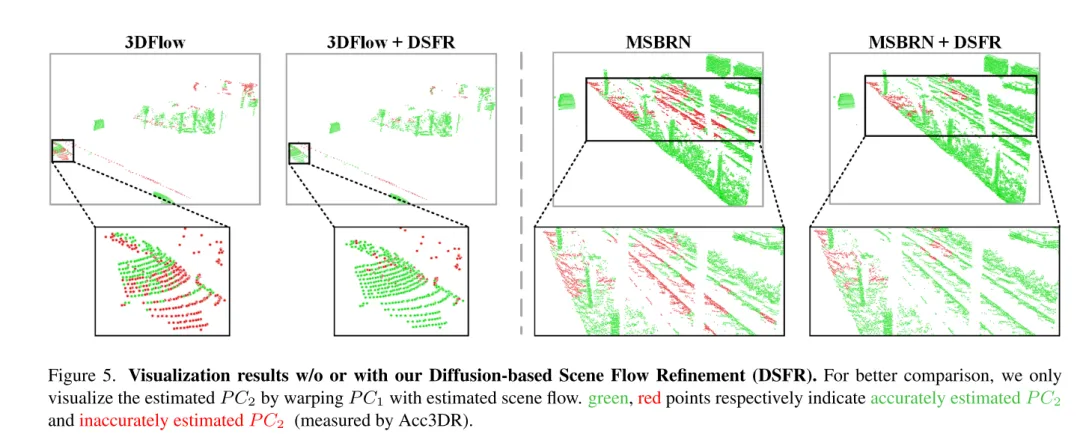
Abbildung 5. Visualisierungsergebnisse ohne oder mit diffusionsbasierter Szenenflussverfeinerung (DSFR).
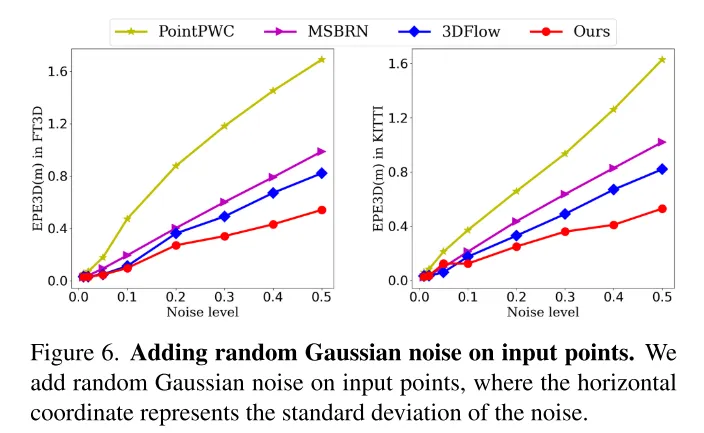
Bild 6. Fügen Sie den Eingabepunkten zufälliges Gaußsches Rauschen hinzu.
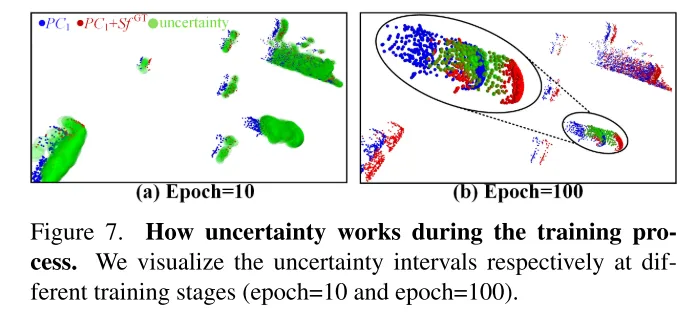
Bild 7. Die Rolle der Unsicherheit im Trainingsprozess. In diesem Artikel werden die Unsicherheitsintervalle in verschiedenen Trainingsstadien (10. Runde und 100. Runde) visualisiert.
Zusammenfassung:
Dieses Papier schlägt innovativ ein diffusionsbasiertes Szenenfluss-Verfeinerungsnetzwerk vor, das sich der Schätzungsunsicherheit bewusst ist. In diesem Artikel wird eine mehrskalige Diffusionsverfeinerung angewendet, um feinkörnige dichte Strömungsreste zu erzeugen. Um die Robustheit der Schätzung zu verbessern, führt dieser Artikel auch die punktuelle Unsicherheit ein, die gemeinsam mit dem Szenenfluss erzeugt wird. Umfangreiche Experimente belegen die Überlegenheit und Generalisierungsfähigkeit unseres DifFlow3D. Es ist erwähnenswert, dass die diffusionsbasierte Verfeinerung dieses Artikels als Plug-and-Play-Modul auf frühere Arbeiten angewendet werden kann und neue Implikationen für zukünftige Forschung liefert.
Zitat:
Liu J, Wang G, Ye W, et al. DifFlow3D: Toward Robust Uncertainty-Aware Scene Flow Estimation with Diffusion Model[J].
Das obige ist der detaillierte Inhalt vonDifFlow3D: Neues SOTA zur Szenenflussschätzung, das Diffusionsmodell hat einen weiteren Erfolg!. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Was ist ein Haufen? Was ist der Methodenbereich? Einführung in den Heap- und Methodenbereich im JVM-Speichermodell
- Welche Einsatzszenarien gibt es für Verschlüsse?
- Detaillierte Erläuterung der Merkmale, Prinzipien, Nutzungsszenarien und Anwendungsfälle von MongoDB
- Wovon ist das konzeptionelle Modell einer Datenbank unabhängig?
- Was sind die drei wichtigsten Anwendungsszenarien von 5g?