
Heim >Technologie-Peripheriegeräte >KI >Tsinghua: Microsoft hat ein neues Komprimierungstool für Eingabeaufforderungsworte als Open-Source-Lösung bereitgestellt, dessen Länge um 80 % gesunken ist! GitHub erhält 3,1K Sterne
Tsinghua: Microsoft hat ein neues Komprimierungstool für Eingabeaufforderungsworte als Open-Source-Lösung bereitgestellt, dessen Länge um 80 % gesunken ist! GitHub erhält 3,1K Sterne

- 王林nach vorne
- 2024-03-26 18:36:02510Durchsuche
Bei der Verarbeitung natürlicher Sprache werden viele Informationen tatsächlich wiederholt.
Wenn die Aufforderungswörter effektiv komprimiert werden können, entspricht dies einer gewissen Erweiterung der Länge des vom Modell unterstützten Kontexts.
Bestehende Informationsentropiemethoden reduzieren diese Redundanz, indem sie bestimmte Wörter oder Phrasen entfernen.
Die auf der Informationsentropie basierende Berechnung deckt jedoch nur den einseitigen Textkontext ab und ignoriert möglicherweise wichtige Informationen, die für die Komprimierung erforderlich sind. Darüber hinaus stimmt die Berechnungsmethode der Informationsentropie nicht vollständig mit dem tatsächlichen Zweck der Komprimierungsaufforderung überein Wörter.
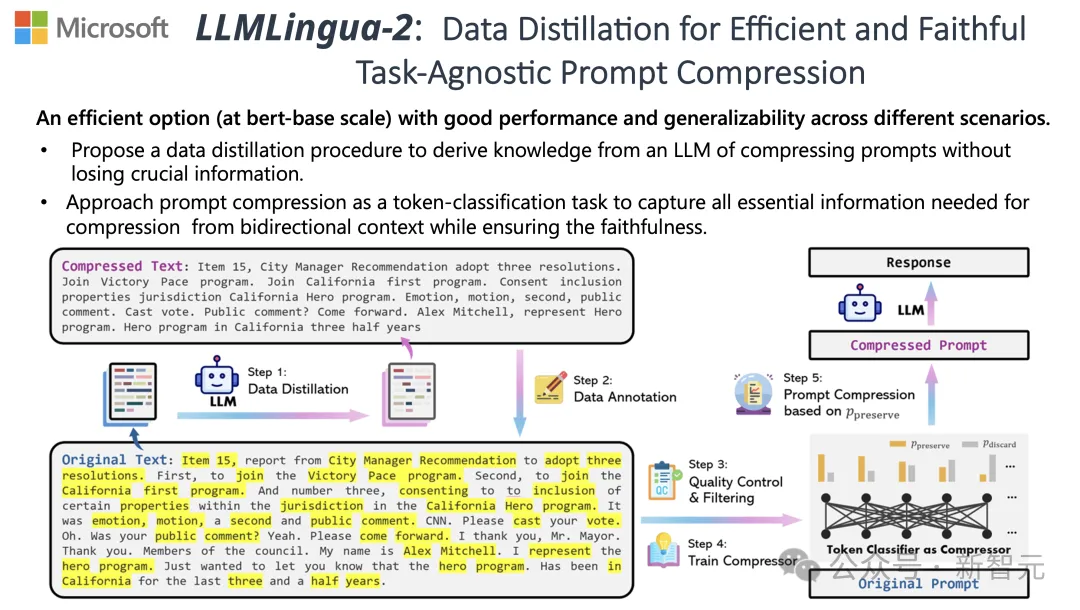
Um diesen Herausforderungen zu begegnen, haben Forscher der Tsinghua-Universität und Microsoft gemeinsam einen neuen Datenverarbeitungsprozess namens LLMLingua-2 vorgeschlagen. Ziel ist es, Wissen aus großen Sprachmodellen (LLM) zu extrahieren und eine Verfeinerung der Informationen durch die Komprimierung von Eingabeaufforderungen zu erreichen und gleichzeitig sicherzustellen, dass wichtige Informationen nicht verloren gehen.
Das Projekt hat 3,1.000 Sterne auf GitHub erhalten
Die Ergebnisse zeigen, dass LLMLingua-2 die Textlänge erheblich auf die ursprünglichen 20 % reduzieren kann, wodurch Verarbeitungszeit und Kosten effektiv reduziert werden.
Darüber hinaus ist die Verarbeitungsgeschwindigkeit von LLMLingua 2 im Vergleich zur Vorgängerversion von LLMLingua und anderen ähnlichen Technologien um das Drei- bis Sechsfache erhöht.

Papieradresse: https://arxiv.org/abs/2403.12968
Bei diesem Prozess wird zunächst der Originaltext in das Modell eingegeben.
Das Modell bewertet die Wichtigkeit jedes Wortes und entscheidet, ob es beibehalten oder gelöscht werden soll, wobei auch die Beziehung zwischen Wörtern berücksichtigt wird.
Abschließend wählt das Modell die Wörter mit den höchsten Punktzahlen aus, um ein kürzeres Aufforderungswort zu bilden.
Das Team testete das LLMLingua-2-Modell an mehreren Datensätzen, darunter MeetingBank, LongBench, ZeroScrolls, GSM8K und BBH.
Obwohl dieses Modell klein ist, erzielte es in Benchmark-Tests deutliche Leistungsverbesserungen und hat seine Leistung in verschiedenen großen Sprachmodellen (von GPT-3.5 bis Mistral-7B) und Sprachen (von Englisch bis Chinesisch) unter Beweis gestellt ausgezeichnete Generalisierungsfähigkeit.
Systemaufforderung:
Als herausragender Linguist sind Sie gut darin, längere Absätze in kurze Ausdrücke zu komprimieren, indem Sie unwichtige Wörter entfernen und so viele Informationen wie möglich behalten.
Benutzertipps:
Bitte komprimieren Sie den angegebenen Text in einen kurzen Ausdruck, damit Sie (GPT-4) den Originaltext so genau wie möglich wiederherstellen können. Anders als bei der normalen Textkomprimierung müssen Sie die folgenden fünf Bedingungen befolgen:
1. Entfernen Sie nur diese unwichtigen Wörter.
2. Behalten Sie die Reihenfolge der ursprünglichen Wörter bei.
3. Behalten Sie den ursprünglichen Wortschatz bei.
4. Verwenden Sie keine Abkürzungen oder Emoticons.
5. Fügen Sie keine neuen Wörter oder Symbole hinzu.
Bitte komprimieren Sie den Originaltext so weit wie möglich und behalten Sie dabei so viele Informationen wie möglich bei. Wenn Sie es verstanden haben, komprimieren Sie bitte den folgenden Text: {Zu komprimierender Text}
Der komprimierte Text ist: [...]
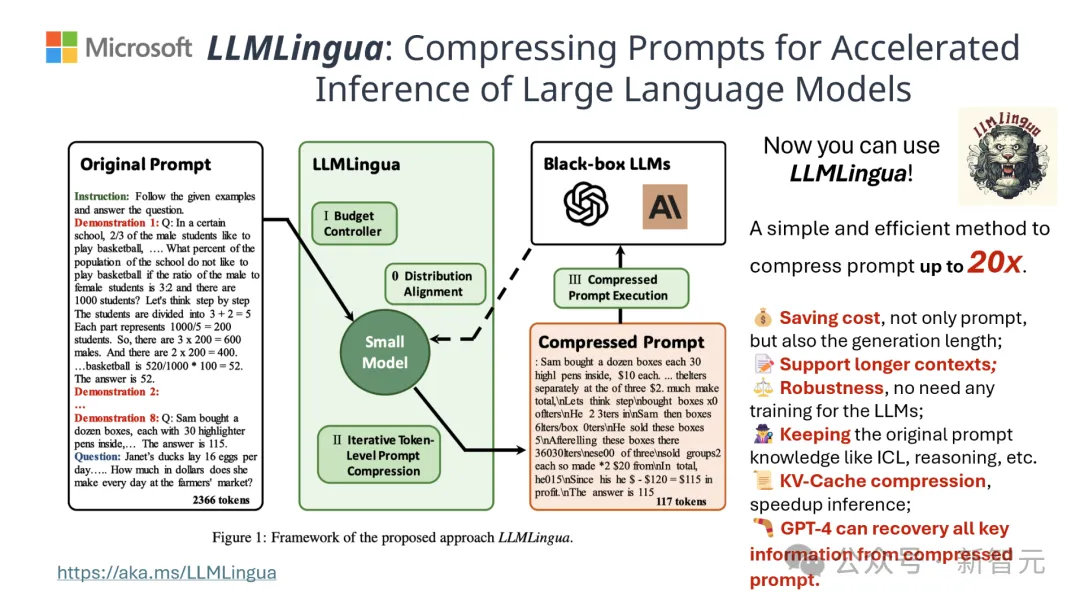
Die Ergebnisse zeigen, dass in Fragen und Antworten, abstraktem Schreiben und logischem Denken In Bei einer Vielzahl von Sprachaufgaben übertrifft LLMLlingua-2 das ursprüngliche LLMLingua-Modell und andere selektive Kontextstrategien deutlich.
Es ist erwähnenswert, dass diese Komprimierungsmethode für verschiedene große Sprachmodelle (von GPT-3.5 bis Mistral-7B) und verschiedene Sprachen (von Englisch bis Chinesisch) gleichermaßen effektiv ist.
Darüber hinaus kann die Bereitstellung von LLMLingua-2 mit nur zwei Codezeilen erreicht werden.
Derzeit ist das Modell in die weit verbreiteten RAG-Frameworks LangChain und LlamaIndex integriert.
Implementierungsmethode
Um die Probleme bestehender auf Informationsentropie basierender Textkomprimierungsmethoden zu überwinden, wendet LLMLingua-2 eine innovative Datenextraktionsstrategie an.
Diese Strategie erreicht eine effiziente Textkomprimierung, ohne wichtige Inhalte zu verlieren und das Hinzufügen fehlerhafter Informationen zu vermeiden, indem wesentliche Informationen aus großen Sprachmodellen wie GPT-4 extrahiert werden.
Tipps Design
Um das Textkomprimierungspotenzial von GPT-4 voll auszuschöpfen, liegt der Schlüssel darin, genaue Komprimierungsanweisungen festzulegen.
Das heißt, wenn Sie Text komprimieren, weisen Sie GPT-4 an, nur die Wörter zu entfernen, die im Originaltext weniger wichtig sind, und dabei die Einführung neuer Wörter zu vermeiden.
Damit soll sichergestellt werden, dass der komprimierte Text die Authentizität und Integrität des Originaltextes so weit wie möglich beibehält.

Annotation und Filterung
Forscher haben einen neuartigen Datenannotationsalgorithmus entwickelt, der Wissen nutzt, das aus großen Sprachmodellen wie GPT-4 extrahiert wurde.
Dieser Algorithmus kann jedes Wort im Originaltext kennzeichnen und klar angeben, welche Wörter während des Komprimierungsprozesses beibehalten werden müssen.
Um die hohe Qualität des erstellten Datensatzes sicherzustellen, haben sie außerdem zwei Qualitätsüberwachungsmechanismen entwickelt, die speziell darauf abzielen, Datenproben mit schlechter Qualität zu identifizieren und zu eliminieren.

Kompressor
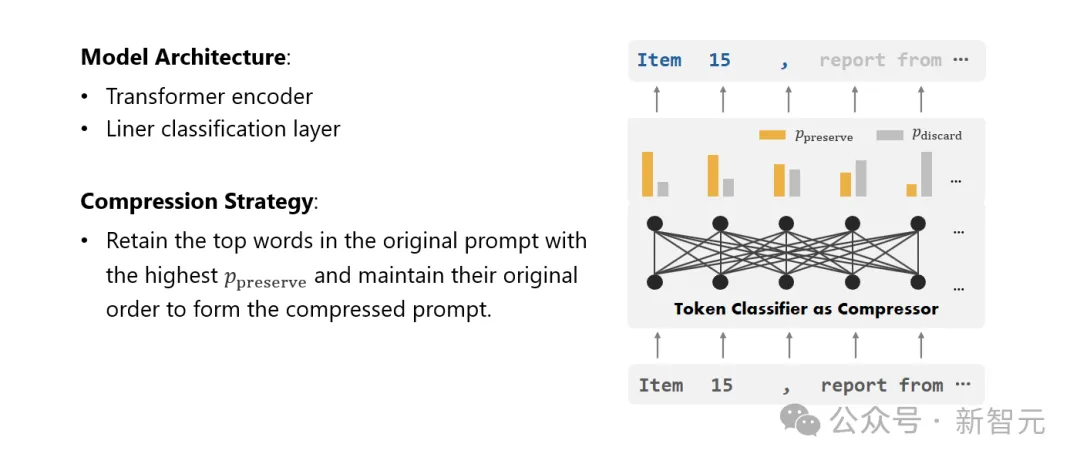
Schließlich wandelten die Forscher das Problem der Textkomprimierung in eine Aufgabe zur Klassifizierung jedes Vokabulars (Token) um und verwendeten einen leistungsstarken Transformer als Feature-Extraktor.
Dieses Tool versteht den Kontext von Text, um die Informationen, die für die Textkomprimierung entscheidend sind, genau zu erfassen.
Durch Training an einem sorgfältig erstellten Datensatz ist das Modell der Forscher in der Lage, einen Wahrscheinlichkeitswert basierend auf der Wichtigkeit jedes Wortes zu berechnen, um zu entscheiden, ob das Wort im endgültigen komprimierten Text beibehalten oder aufgegeben werden sollte.
Leistungsbewertung
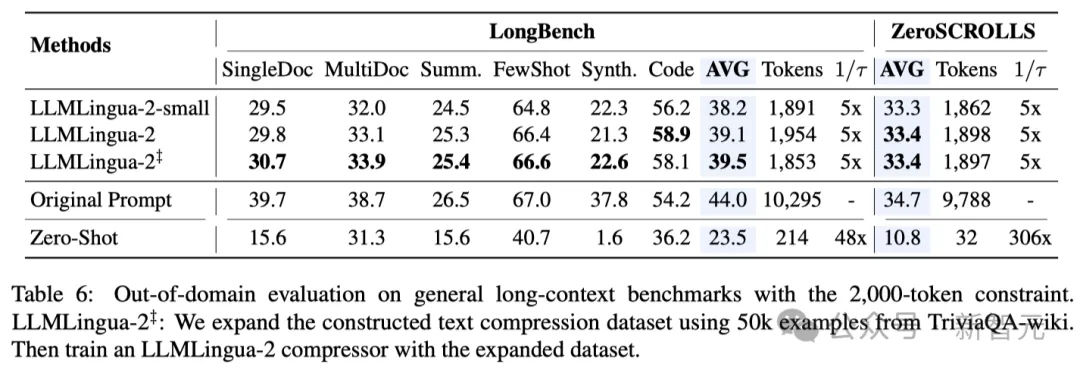
Die Forscher testeten die Leistung von LLMLingua-2 bei einer Reihe von Aufgaben, darunter Kontextlernen, Textzusammenfassung, Dialoggenerierung, Fragen und Antworten für mehrere und einzelne Dokumente, Codegenerierung usw Syntheseaufgaben umfassen sowohl domäneninterne als auch domänenexterne Datensätze.
Testergebnisse zeigen, dass die Methode der Forscher minimale Leistungsverluste bei gleichzeitig hoher Leistung reduziert und unter den aufgabenunspezifischen Textkomprimierungsmethoden eine hervorragende Leistung erbringt.
– In-Domain-Tests (MeetingBank)
Die Forscher verglichen die Leistung von LLMLingua-2 auf dem MeetingBank-Testsatz mit anderen leistungsstarken Basismethoden.
Obwohl ihre Modellgröße viel kleiner ist als die des LLaMa-2-7B, das in der Basislinie verwendet wurde, verbesserte die Methode der Forscher bei den Fragenbeantwortungs- und Textzusammenfassungsaufgaben nicht nur die Leistung deutlich, sondern schnitt auch fast genauso gut ab die Originaltextaufforderungen. ?? in der Verallgemeinerungsfähigkeit in verschiedenen Szenarien wie Langtext, logischem Denken und kontextbezogenem Lernen.
Es ist erwähnenswert, dass LLMLlingua-2 zwar nur an einem Datensatz trainiert wurde, seine Leistung jedoch bei Tests außerhalb der Domäne nicht nur mit den aktuellen aufgabenunspezifischen Komprimierungsmethoden auf dem neuesten Stand der Technik vergleichbar war, sondern sogar in manchen Fällen sogar noch schlimmer.
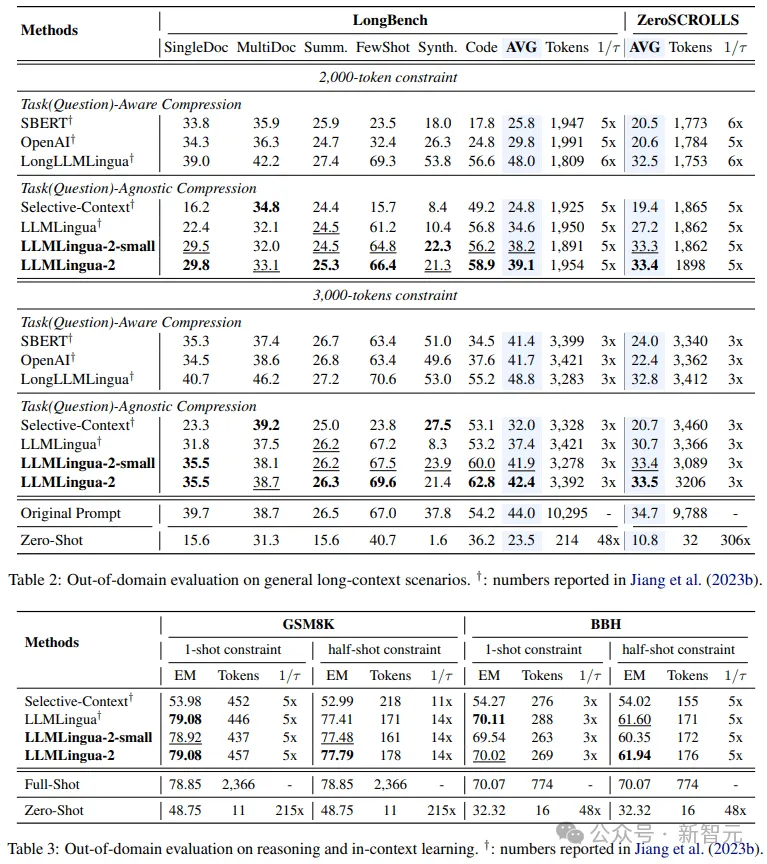
Sogar das kleinere Modell der Forscher (BERT-Basisgröße) konnte eine Leistung erzielen, die mit den ursprünglichen Hinweisen vergleichbar und in einigen Fällen sogar etwas besser war.
Obwohl der Ansatz der Forscher vielversprechende Ergebnisse erzielte, weist er im Vergleich zu anderen aufgabenbewussten Komprimierungsmethoden wie LongLLMlingua auf Longbench immer noch Mängel auf.
Die Forscher führen diese Leistungslücke auf die zusätzlichen Informationen zurück, die sie durch das Problem erhalten. Allerdings ist das Modell der Forscher aufgabenunabhängig, was es zu einer effizienten Option mit guter Generalisierbarkeit macht, wenn es in verschiedenen Szenarien eingesetzt wird.
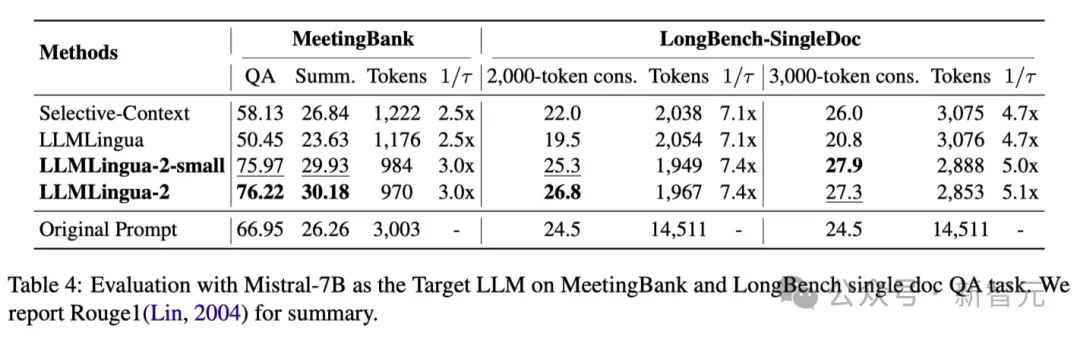
Tabelle 4 oben listet die Ergebnisse verschiedener Methoden unter Verwendung von Mistral-7Bv0.1 4 als Ziel-LLM auf.
Im Vergleich zu anderen Basismethoden weist die Methode der Forscher eine deutliche Leistungsverbesserung auf, was ihre gute Generalisierungsfähigkeit auf das Ziel-LLM demonstriert.
Es ist erwähnenswert, dass LLMLingua-2 sogar besser abschneidet als die ursprüngliche Eingabeaufforderung.
Forscher spekulieren, dass Mistral-7B bei der Verwaltung langer Kontexte möglicherweise nicht so gut ist wie GPT-3.5-Turbo.
Der Ansatz der Forscher verbessert effektiv die endgültige Inferenzleistung von Mistral7B, indem er kurze Hinweise mit höherer Informationsdichte liefert.
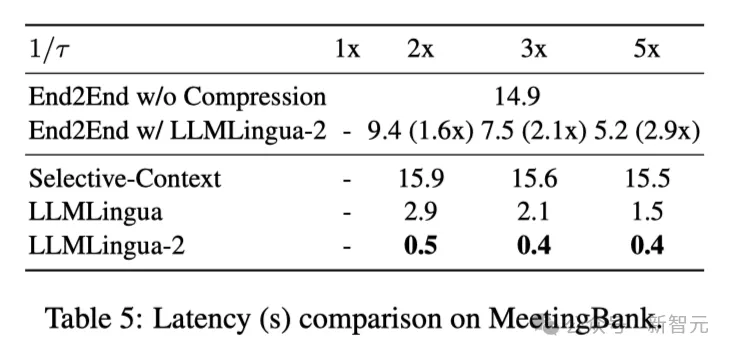
Tabelle 5 oben zeigt die Latenz verschiedener Systeme auf der V100-32G-GPU mit unterschiedlichen Komprimierungsverhältnissen.
Die Ergebnisse zeigen, dass LLMLingua2 im Vergleich zu anderen Komprimierungsmethoden viel weniger Rechenaufwand hat und eine End-to-End-Geschwindigkeitsverbesserung von 1,6x bis 2,9x erreichen kann.
Darüber hinaus kann die Methode der Forscher die GPU-Speicherkosten um das Achtfache senken und so den Bedarf an Hardware-Ressourcen reduzieren.
Kontextbewusste Beobachtung Die Forscher beobachteten, dass LLMLingua-2 mit zunehmender Komprimierungsrate die informativsten Wörter effektiv mit vollständigem Kontext beibehalten kann.
Dies ist der Einführung eines bidirektionalen kontextsensitiven Feature-Extraktors und einer Strategie zu verdanken, die explizit auf das Ziel einer zeitnahen Komprimierung hin optimiert.
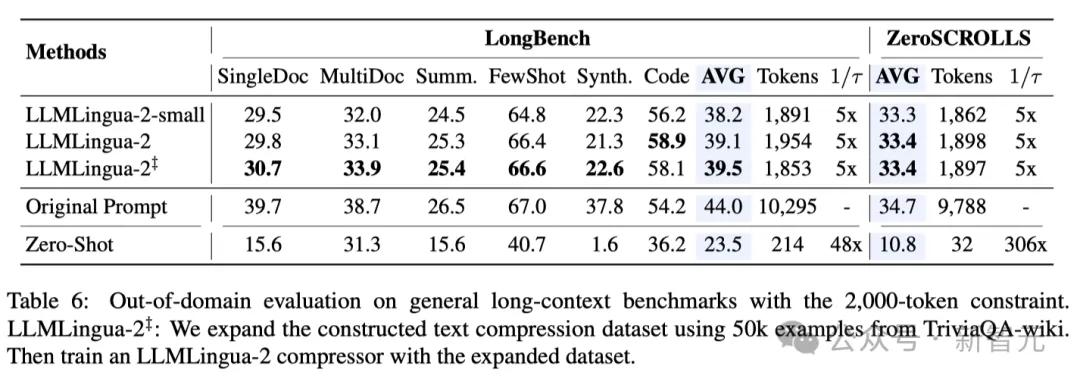
Die Forscher beobachteten, dass LLMLingua-2 mit zunehmendem Komprimierungsverhältnis effektiv die informativsten Wörter im Zusammenhang mit dem gesamten Kontext beibehalten kann.
Dies ist der Einführung eines bidirektionalen kontextsensitiven Feature-Extraktors und einer Strategie zu verdanken, die explizit auf das Ziel einer zeitnahen Komprimierung hin optimiert.
Schließlich baten die Forscher GPT-4, den Originalton aus dem LLMLlingua-2-Komprimierungshinweis zu rekonstruieren.
Die Ergebnisse zeigen, dass GPT-4 den ursprünglichen Tipp effektiv rekonstruieren kann, was darauf hinweist, dass während des LLMLlingua-2-Komprimierungsprozesses keine wesentlichen Informationen verloren gehen.
Das obige ist der detaillierte Inhalt vonTsinghua: Microsoft hat ein neues Komprimierungstool für Eingabeaufforderungsworte als Open-Source-Lösung bereitgestellt, dessen Länge um 80 % gesunken ist! GitHub erhält 3,1K Sterne. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!