
Heim >Technologie-Peripheriegeräte >KI >Was ist der Unterschied zwischen KI-Inferenz und Training? wissen Sie?
Was ist der Unterschied zwischen KI-Inferenz und Training? wissen Sie?

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2024-03-26 14:40:151282Durchsuche
Wenn Sie den Unterschied zwischen KI-Training und Argumentation in einem Satz zusammenfassen möchten, ist „eine Minute auf der Bühne, zehn Jahre harte Arbeit abseits der Bühne“ meiner Meinung nach am besten geeignet.
Xiao Ming ist seit vielen Jahren mit der Göttin zusammen, die er seit langem bewundert, und er hat ziemlich viel Erfahrung darin, sie um ein Date zu bitten, aber er ist immer noch verwirrt über das Geheimnis.
Können mithilfe der KI-Technologie genaue Vorhersagen getroffen werden?
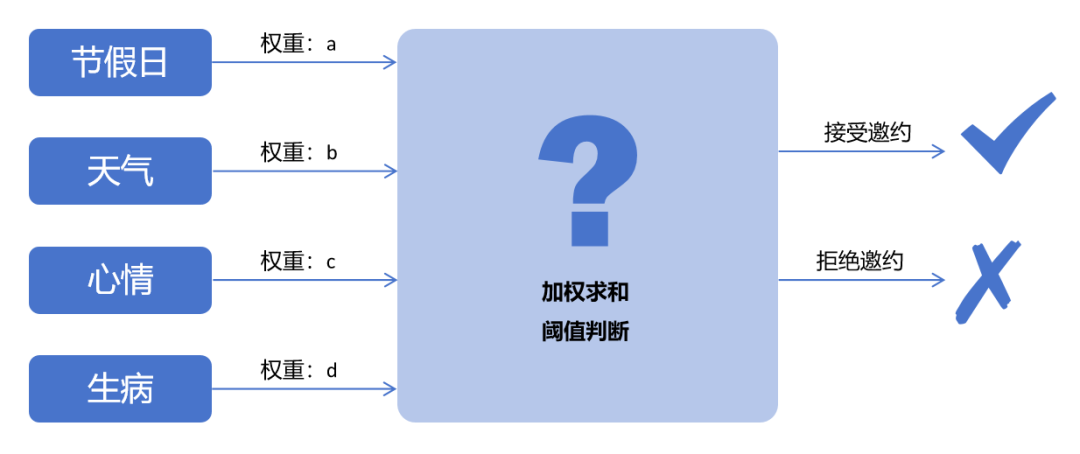
Xiao Ming dachte immer wieder nach und fasste die Variablen zusammen, die beeinflussen können, ob die Göttin die Einladung annimmt: ob es ein Feiertag ist, das Wetter schlecht ist, zu heiß/zu kalt, schlecht gelaunt, krank, er hat einen anderen Termin, und Verwandte kommen ins Haus ... usw.
 Bilder
Bilder
Wenn die gewichtete Summe dieser Variablen einen bestimmten Schwellenwert überschreitet, wird die Göttin die Einladung definitiv annehmen. Wie viel Gewicht haben diese Variablen und wie hoch sind die Schwellenwerte?
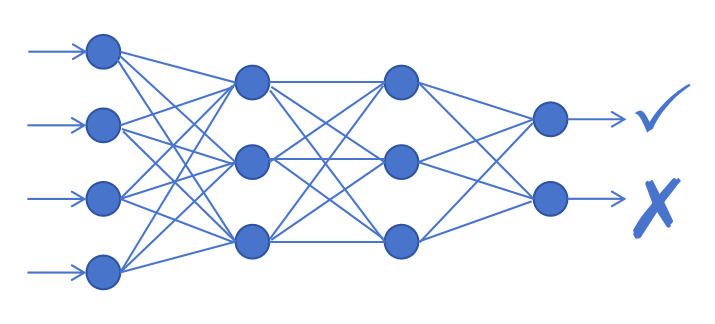
Dies ist ein sehr komplexes Problem, das mit einfachen Methoden nur schwer genau zu lösen ist. Daher plant Xiao Ming, Forschungen mit tiefen neuronalen Netzen durchzuführen und diese für das Training auf große Mengen gesammelter Daten anzuwenden, damit das Modell der künstlichen Intelligenz die Muster selbst lernen kann.
 Bilder
Bilder
Xiao Mings größter Vorteil ist, dass er über eine umfangreiche Datensammlung verfügt. Also organisierte und listete er alle Variablen genau auf und ordnete sie genau darauf zu, ob das Angebot erfolgreich war oder nicht. Diese Praxis wird als „Datenannotation“ bezeichnet.
 Bilder
Bilder
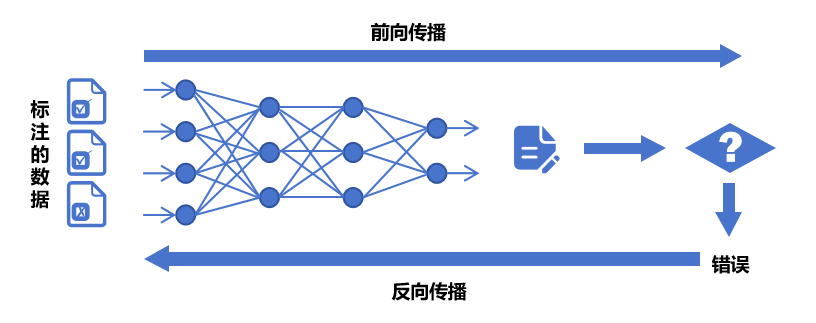
Sobald Sie die Daten haben, geben Sie sie an die KI weiter. KI liest jeden Datensatz, wertet ihn anhand der anfänglichen Standardgewichte aus und erhält dann die Ergebnisse ihrer eigenen Analyse. Dieser Vorgang wird als „Vorwärtspropagierung“ bezeichnet.
Überprüfen Sie anschließend, ob die KI-Ergebnisse korrekt sind.
Hier muss eine „Verlustfunktion“ eingeführt werden, um die Differenz zwischen dem Ergebnis und der richtigen Antwort zu berechnen. Wenn das Ergebnis nicht ideal ist, werden die Gewichte erneut optimiert und angepasst und die Ergebnisse werden erneut zur Auswertung abgerufen. Dieser Vorgang wird als „Rückausbreitung“ bezeichnet.
Nach dem Testen habe ich festgestellt, dass die Bewertungsergebnisse und die richtigen Antworten einen Schritt näher kommen. Nach mehreren Iterationsrunden wird die richtige Antwort schrittweise durch Anpassen der Parametergewichte erreicht. Dieser Vorgang wird als „Gradientenabstieg“ bezeichnet.
 Bilder
Bilder
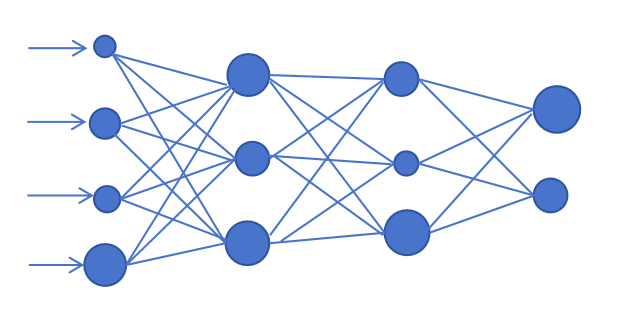
Nach vielen Runden eingehender Taufe bekannter Daten ist die Genauigkeit der KI-Auswertung bereits recht hoch. Also beendete Xiao Ming das Training, korrigierte die Parametergewichte, entfernte die redundanten Parameter, deren Gewichte nicht aktiviert waren, und erklärte, dass sie in die nächste Stufe eintreten würden.
Es ist Zeit, die Ergebnisse der harten Arbeit zu testen, die vor einiger Zeit geleistet wurde!
 Bilder
Bilder
Also wählte Xiao Ming einen guten und günstigen Tag, um alle neuen Parameter vorzubereiten und in die KI einzugeben. Die KI kam schnell zu ihrem eigenen Einschätzungsschluss: Die Göttin wird die Einladung annehmen!
Der obige Vorgang wird als „Begründung“ bezeichnet.
Xiao Ming nahm ein Bad, zog sich um, räumte sorgfältig auf, buchte Kinokarten und fragte die Göttin vorsichtig nach ihrer Meinung. Tatsächlich stimmte die Göttin zu!
Von nun an lässt Xiao Ming vor jeder Einladung die KI gewissenhaft vorhersagen, ob sie erfolgreich sein wird oder nicht. Es stellt sich heraus, dass KI in den meisten Fällen alles richtig machen kann. Wir können sagen, dass der „Generalisierungseffekt“ der KI sehr gut ist.
 Bilder
Bilder
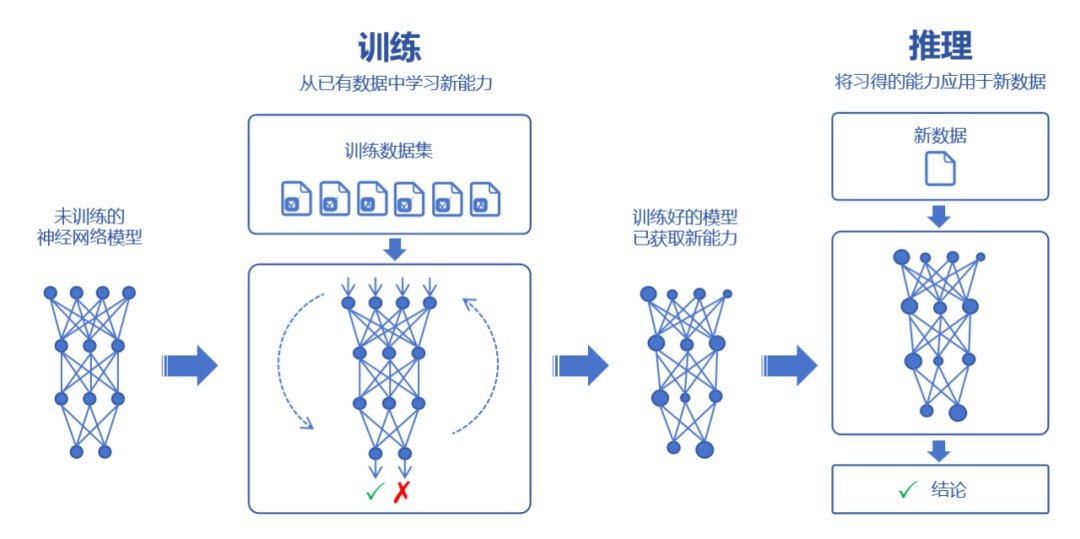
Zusammenfassend lässt sich sagen, dass es sich beim sogenannten KI-Training um den Prozess handelt, bei dem das neuronale Netzwerk neue Fähigkeiten aus vorhandenen Daten erlernen kann.
Dieser Prozess ist sehr kompliziert, genau wie neun Jahre Schulpflicht seit der Kindheit. Er erfordert eine enge Zusammenarbeit von Schulen, Büchern, Lehrern und anderen Faktoren. Der Datendurchsatz ist sehr notwendig Zeit mit Training verbringen.
Das sogenannte KI-Argumentation besteht darin, neue Daten in die trainierte KI einzugeben und diese neue Probleme der gleichen Art lösen zu lassen.
Das ist, als würde ein Student sein Studium abschließen, die Schule, Bücher und Lehrer verlassen und das erlernte Wissen nutzen, um selbstständig mit neuen Problemen umzugehen. Der Datendurchsatz ist relativ gering, aber er muss auf Abruf sein und Antworten geben schnell und gut.
Bei den KI-Anwendungen, mit denen wir grundsätzlich in Berührung kommen, handelt es sich um von Dienstleistern trainierte APPs. Wir schlagen oben verschiedene Aufgaben vor, und der Hintergrund reagiert schnell und gibt Antworten in Sekundenschnelle. Dies alles gehört zum KI-Denken.
Mit einer guten Kontrolle der KI können wir unsere Arbeit mit Leichtigkeit erledigen und mit halbem Aufwand das Doppelte des Ergebnisses erzielen.
Das obige ist der detaillierte Inhalt vonWas ist der Unterschied zwischen KI-Inferenz und Training? wissen Sie?. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!