
Heim >Technologie-Peripheriegeräte >KI >CLIP-BEVFormer: Überwacht explizit die BEVFormer-Struktur, um die Leistung der Long-Tail-Erkennung zu verbessern
CLIP-BEVFormer: Überwacht explizit die BEVFormer-Struktur, um die Leistung der Long-Tail-Erkennung zu verbessern

- 王林nach vorne
- 2024-03-26 12:41:28932Durchsuche
Vorab geschrieben und das persönliche Verständnis des Autors
Derzeit spielt das Wahrnehmungsmodul im gesamten autonomen Fahrsystem eine entscheidende Rolle. Das autonome Fahrzeug, das auf der Straße fährt, kann nur durch das Wahrnehmungsmodul genaue Informationen erhalten Anhand der Ergebnisse können die nachgeschalteten Regelungs- und Steuerungsmodule im autonomen Fahrsystem rechtzeitig korrekte Urteile und Verhaltensentscheidungen treffen. Derzeit sind Autos mit autonomen Fahrfunktionen in der Regel mit einer Vielzahl von Dateninformationssensoren ausgestattet, darunter Rundumsichtkamerasensoren, Lidar-Sensoren und Millimeterwellenradarsensoren, um Informationen in verschiedenen Modalitäten zu sammeln und so genaue Wahrnehmungsaufgaben zu erfüllen.
Der auf reinem Sehen basierende BEV-Wahrnehmungsalgorithmus hat aufgrund seiner geringen Hardwarekosten und einfachen Bereitstellung große Aufmerksamkeit in Industrie und Wissenschaft gefunden und seine Ausgabeergebnisse können problemlos auf verschiedene nachgelagerte Aufgaben angewendet werden. In den letzten Jahren sind nacheinander viele auf dem BEV-Raum basierende visuelle Wahrnehmungsalgorithmen entstanden, die in öffentlichen Datensätzen eine hervorragende Wahrnehmungsleistung gezeigt haben. 🔜 Das Wahrnehmungsalgorithmusmodell wird zunächst verwendet. Das Tiefenschätzungsnetzwerk im Wahrnehmungsmodell wird verwendet, um die semantischen Merkmalsinformationen und die diskrete Tiefenwahrscheinlichkeitsverteilung jedes Pixels der Merkmalskarte vorherzusagen, und dann werden die erhaltenen semantischen Merkmalsinformationen und die diskrete Tiefenwahrscheinlichkeit zum Konstruieren verwendet Semantische Kegelstumpfmerkmale werden mithilfe eines BEV-Poolings und anderer Methoden endgültig abgeschlossen, um den Konstruktionsprozess von BEV-Raummerkmalen abzuschließen.
Der andere Typ ist die umgekehrte BEV-Merkmalskonstruktionsmethode, die durch den BEVFormer-Algorithmus dargestellt wird. Diese Art von Wahrnehmungsalgorithmusmodell generiert zunächst explizit 3D-Voxelkoordinatenpunkte im wahrgenommenen BEV-Raum und verwendet dann die internen und externen Parameter der Kamera zur Konvertierung Die 3D-Voxelkoordinatenpunkte werden zurück in das Bildkoordinatensystem projiziert und die Pixelmerkmale an den entsprechenden Merkmalspositionen werden extrahiert und aggregiert, um die BEV-Merkmale im BEV-Raum zu erstellen.
- Obwohl beide Algorithmen Merkmale im BEV-Raum genau generieren und 3D-Wahrnehmungsergebnisse erzielen können, gibt es bei aktuellen 3D-Zielwahrnehmungsalgorithmen, die auf dem BEV-Raum basieren, wie dem BEVFormer-Algorithmus, die folgenden zwei Probleme:
- Problem 1: Da die Der Gesamtrahmen des BEVFormer-Wahrnehmungsalgorithmusmodells übernimmt die Encoder-Decoder-Netzwerkstruktur. Die Hauptidee besteht darin, das Encoder-Modul zu verwenden, um die Merkmale im BEV-Raum zu erhalten, und dann das Decoder-Modul zu verwenden, um das endgültige Wahrnehmungsergebnis vorherzusagen und zu vergleichen Ausgabewahrnehmungsergebnis mit Der Prozess der Berechnung des Verlusts, um die vom Modell vorhergesagten räumlichen BEV-Merkmale zu erreichen. Die Parameteraktualisierungsmethode dieses Netzwerkmodells hängt jedoch zu sehr von der Wahrnehmungsleistung des Decoder-Moduls ab, was zu dem Problem führen kann, dass die vom Modell ausgegebenen BEV-Merkmale nicht mit den BEV-Merkmalen mit wahrem Wert übereinstimmen, was zu einer weiteren Einschränkung führt die endgültige Leistung des Wahrnehmungsmodells.
Frage 2: Da das Decoder-Modul des BEVFormer-Wahrnehmungsalgorithmusmodells immer noch die Schritte des Selbstaufmerksamkeitsmoduls ->Cross-Attention-Modul->Feedforward-Neuronales Netzwerk im Transformer verwendet, um die Konstruktion der Abfragefunktion abzuschließen und Geben Sie das endgültige Erkennungsergebnis aus. Der gesamte Prozess ist immer noch ein Black-Box-Modell, dem es an guter Interpretierbarkeit mangelt. Gleichzeitig besteht auch eine große Unsicherheit im Eins-zu-eins-Abgleichsprozess zwischen der Objektabfrage und dem wahren Wertziel während des Modelltrainingsprozesses.
- Um die Probleme des BEVFormer-Wahrnehmungsalgorithmusmodells zu lösen, haben wir es verbessert und ein 3D-Erkennungsalgorithmusmodell CLIP-BEVFormer basierend auf Surround-Bildern vorgeschlagen. Durch die Einführung der kontrastiven Lernmethode haben wir die Fähigkeit des Modells zur Konstruktion von BEV-Merkmalen verbessert und eine erstklassige Wahrnehmungsleistung für den nuScenes-Datensatz erreicht.
- Artikellink: https://arxiv.org/pdf/2403.08919.pdf
Gesamtarchitektur und Details des Netzwerkmodells
Bevor wir die Details des in diesem Artikel vorgeschlagenen CLIP-BEVFormer-Wahrnehmungsalgorithmusmodells vorstellen, werden die Die folgende Abbildung zeigt die allgemeine Netzwerkstruktur des CLIP-BEVFormer-Algorithmus.Gesamtflussdiagramm des in diesem Artikel vorgeschlagenen CLIP-BEVFormer-Wahrnehmungsalgorithmusmodells
Aus dem Gesamtflussdiagramm des Algorithmus ist ersichtlich, dass das in diesem Artikel vorgeschlagene CLIP-BEVFormer-Algorithmusmodell auf der Grundlage des BEVFormer-Algorithmusmodells verbessert wurde. Hier ist ein kurzer Überblick über den Implementierungsprozess des BEVFormer-Wahrnehmungsalgorithmusmodells . Zunächst gibt das BEVFormer-Algorithmusmodell die vom Kamerasensor erfassten Surround-Bilddaten ein und verwendet das 2D-Bildmerkmalsextraktionsnetzwerk, um die mehrskaligen semantischen Merkmalsinformationen des eingegebenen Surround-Bilds zu extrahieren. Zweitens wird das Encoder-Modul, das zeitliche Selbstaufmerksamkeit und räumliche Queraufmerksamkeit enthält, verwendet, um den Konvertierungsprozess von 2D-Bildmerkmalen in BEV-Raummerkmale abzuschließen. Anschließend wird eine Reihe von Objektabfragen in Form einer Normalverteilung im 3D-Wahrnehmungsraum generiert und an das Decoder-Modul gesendet, um die interaktive Nutzung räumlicher Merkmale mit den vom Encoder-Modul ausgegebenen BEV-Raummerkmalen abzuschließen. Schließlich wird das Feedforward-Neuronale Netzwerk verwendet, um die von Object Query abgefragten semantischen Merkmale vorherzusagen, und die endgültigen Klassifizierungs- und Regressionsergebnisse des Netzwerkmodells werden ausgegeben. Gleichzeitig wird während des Trainingsprozesses des BEVFormer-Algorithmusmodells die ungarische Eins-zu-eins-Matching-Strategie verwendet, um den Verteilungsprozess positiver und negativer Stichproben abzuschließen, und Klassifizierungs- und Regressionsverluste werden verwendet, um den Aktualisierungsprozess abzuschließen die Gesamtparameter des Netzwerkmodells. Der gesamte Erkennungsprozess des BEVFormer-Algorithmusmodells kann durch die folgende mathematische Formel ausgedrückt werden:
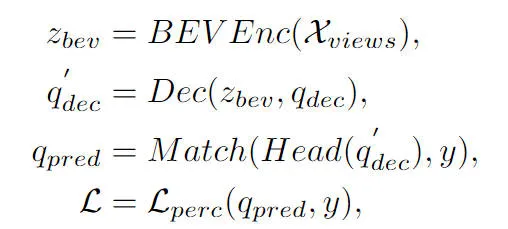
wobei in der Formel das Encoder-Merkmalsextraktionsmodul im BEVFormer-Algorithmus, das Decoder-Dekodierungsmodul im BEVFormer-Algorithmus und dargestellt werden stellt den wahren Wert im Datensatz dar und stellt das 3D-Wahrnehmungsergebnis dar, das vom aktuellen BEVFormer-Algorithmusmodell ausgegeben wird.
Generierung des echten BEV-Werts
Wie oben erwähnt, überwachen die meisten vorhandenen 3D-Zielerkennungsalgorithmen auf Basis des BEV-Raums die generierten BEV-Raummerkmale nicht explizit, was dazu führen kann, dass BEV-Merkmale bei der Modellgenerierung nicht mit echten BEV-Merkmalen übereinstimmen Dieser Unterschied in der Verteilung der räumlichen BEV-Merkmale schränkt die endgültige Wahrnehmungsleistung des Modells ein. Basierend auf dieser Überlegung haben wir das Ground Truth BEV-Modul vorgeschlagen. Unsere Kernidee beim Entwurf dieses Moduls besteht darin, die vom Modell generierten BEV-Merkmale mit den aktuellen BEV-Merkmalen mit wahrem Wert in Einklang zu bringen und so die Leistung des Modells zu verbessern.
Wie im Gesamtnetzwerk-Framework-Diagramm gezeigt, verwenden wir insbesondere einen Ground-Truth-Encoder (), um die Kategoriebezeichnung und die Positionsinformationen des räumlichen Begrenzungsrahmens jeder Ground-Truth-Instanz auf der BEV-Feature-Map zu codieren. Der Prozess kann wie folgt ausgedrückt werden :
Die Feature-Dimension in der Formel hat die gleiche Größe wie die generierte BEV-Feature-Map und stellt die codierten Feature-Informationen eines echten Wertziels dar. Während des Codierungsprozesses haben wir zwei Formen übernommen, eine ist ein großes Sprachmodell (LLM) und die andere ist ein mehrschichtiges Perzeptron (MLP). Durch experimentelle Ergebnisse haben wir festgestellt, dass die beiden Methoden grundsätzlich die gleiche Leistung erzielen.
Um die Grenzinformationen des wahren Ziels auf der BEV-Feature-Map weiter zu verbessern, beschneiden wir außerdem das wahre Ziel auf der BEV-Feature-Map entsprechend seiner räumlichen Position und verwenden zum Konstruieren die Pooling-Operation für die beschnittenen Features Die entsprechende Darstellung der Merkmalsinformationen kann in der folgenden Form ausgedrückt werden:
Um die vom Modell generierten BEV-Merkmale weiter an den BEV-Merkmalen mit wahrem Wert auszurichten, haben wir die kontrastive Lernmethode verwendet, um die beiden Kategorien zu optimieren Die Elementbeziehung und der Abstand zwischen BEV-Merkmalen und der Optimierungsprozess können in der folgenden Form ausgedrückt werden:
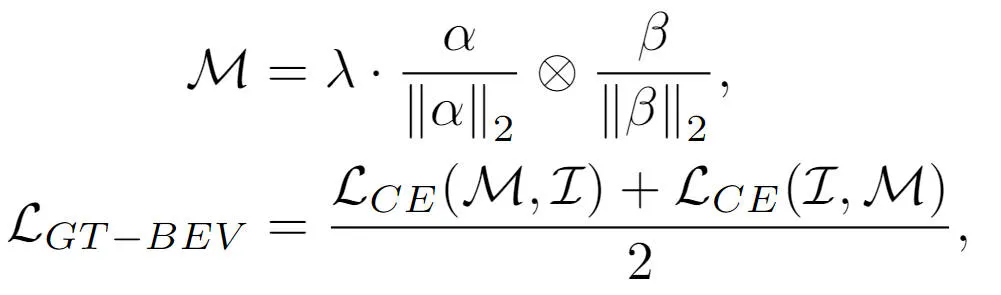
wobei die Summe in der Formel jeweils die Ähnlichkeitsmatrix zwischen den generierten BEV-Merkmalen und den wahren Wert-BEV-Merkmalen darstellt Vergleich Der logische Skalierungsfaktor beim Lernen stellt die Multiplikationsoperation zwischen Matrizen und die Kreuzentropieverlustfunktion dar. Durch die oben beschriebene kontrastive Lernmethode kann die von uns vorgeschlagene Methode eine klarere Merkmalsführung für die generierten BEV-Merkmale bereitstellen und die Wahrnehmungsfähigkeit des Modells verbessern.
True-Value-Zielabfrageinteraktion
Dieser Teil wurde auch im vorherigen Artikel erwähnt. Die Objektabfrage im BEVFormer-Wahrnehmungsalgorithmusmodell interagiert mit den generierten BEV-Funktionen über das Decoder-Modul, um die entsprechenden Zielabfragefunktionen zu erhalten Gesamtprozess Es handelt sich immer noch um einen Black-Box-Prozess, dem ein vollständiges Prozessverständnis fehlt. Um dieses Problem anzugehen, haben wir das Wahrheitswert-Abfrageinteraktionsmodul eingeführt, das das Wahrheitswertziel verwendet, um die BEV-Funktionsinteraktion des Decoder-Moduls auszuführen und den Lernprozess von Modellparametern zu stimulieren. Insbesondere führen wir die vom Truth Encoder ()-Modul ausgegebenen Wahrheitszielcodierungsinformationen in Object Query ein, um am Decodierungsprozess des Decoder-Moduls teilzunehmen. Wie normale Object Query nehmen wir am gleichen Selbstaufmerksamkeitsmodul, dem Cross-Attention-Modul, teil und Das vorwärtsgerichtete neuronale Netzwerk gibt das endgültige Wahrnehmungsergebnis aus. Es ist jedoch zu beachten, dass während des Decodierungsprozesses alle Objektabfragen parallele Berechnungen verwenden, um den Verlust von Zielinformationen mit echtem Wert zu verhindern. Der gesamte Interaktionsprozess der Wahrheitswertzielabfrage kann abstrakt in der folgenden Form ausgedrückt werden:
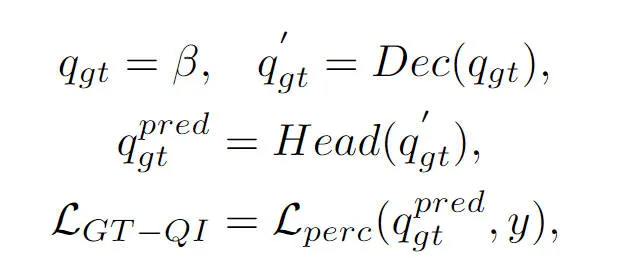
Unter diesen stellt die Formel die initialisierte Objektabfrage dar und stellt das Ausgabeergebnis der Objektabfrage mit wahrem Wert durch das Decodermodul bzw. den Erfassungserkennungskopf dar. Durch die Einführung des Interaktionsprozesses des wahren Wertziels in den Modelltrainingsprozess kann das von uns vorgeschlagene Interaktionsmodul für die Abfrage des Wahrheitswertziels die Interaktion zwischen der Abfrage des wahren Wertziels und dem BEV-Merkmal des wahren Werts realisieren und so den Parameteraktualisierungsprozess unterstützen Modell Decoder-Modul.
Experimentelle Ergebnisse und Bewertungsindikatoren
Quantitativer Analyseteil
Um die Wirksamkeit des von uns vorgeschlagenen CLIP-BEVFormer-Algorithmusmodells zu überprüfen, haben wir anhand des nuScenes-Datensatzes den 3D-Wahrnehmungseffekt und die Länge von durchgeführt Die Zielkategorie im Datensatz wurde unter dem Gesichtspunkt der Schwanzverteilung und Robustheit durchgeführt. Die folgende Tabelle zeigt den Genauigkeitsvergleich zwischen dem von uns vorgeschlagenen Algorithmusmodell und anderen 3D-Wahrnehmungsalgorithmusmodellen im nuScenes-Datensatz.
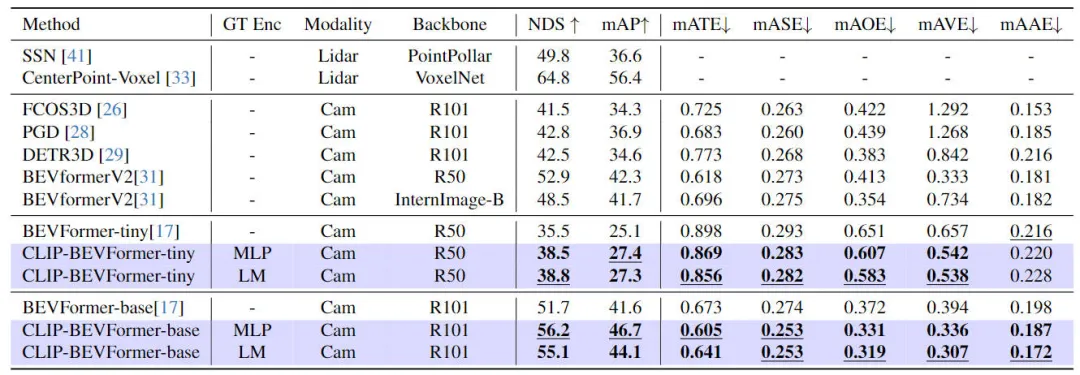
Vergleichsergebnisse zwischen der in diesem Artikel vorgeschlagenen Methode und anderen Wahrnehmungsalgorithmusmodellen
In diesem Teil des Experiments haben wir die Wahrnehmungsleistung unter verschiedenen Modellkonfigurationen bewertet. Insbesondere haben wir das CLIP-BEVFormer-Algorithmusmodell angewendet winzige und Basisvarianten von BEVFormer. Darüber hinaus haben wir auch die Auswirkungen der Verwendung vorab trainierter CLIP-Modelle oder MLP-Schichten als Ground-Truth-Zielkodierer auf die Wahrnehmungsleistung des Modells untersucht. Aus den experimentellen Ergebnissen ist ersichtlich, dass die NDS- und mAP-Indikatoren nach Anwendung des von uns vorgeschlagenen CLIP-BEVFormer-Algorithmus stabile Leistungsverbesserungen aufweisen, unabhängig davon, ob es sich um die ursprüngliche winzige Variante oder die Basisvariante handelt. Darüber hinaus können wir anhand der experimentellen Ergebnisse feststellen, dass das von uns vorgeschlagene Algorithmusmodell nicht davon abhängt, ob die MLP-Schicht oder das Sprachmodell für den Ground-Truth-Zielencoder ausgewählt wird. Diese Flexibilität kann den von uns vorgeschlagenen CLIP-BEVFormer-Algorithmus verbessern Effizient anpassbar und einfach am Fahrzeug einsetzbar. Zusammenfassend zeigen die Leistungsindikatoren verschiedener Varianten unseres vorgeschlagenen Algorithmusmodells durchweg, dass das vorgeschlagene CLIP-BEVFormer-Algorithmusmodell eine gute Wahrnehmungsrobustheit aufweist und bei unterschiedlicher Modellkomplexität und Parametermenge eine hervorragende Erkennungsleistung erzielen kann.
Zusätzlich zur Überprüfung der Leistung unseres vorgeschlagenen CLIP-BEVFormer bei 3D-Wahrnehmungsaufgaben haben wir auch Long-Tail-Verteilungsexperimente durchgeführt, um die Robustheit und Verallgemeinerung unseres Algorithmus angesichts des Vorhandenseins einer Long-Tail-Verteilung in den Daten zu bewerten Die experimentellen Ergebnisse sind in der folgenden Tabelle zusammengefasst. Die Leistung des vorgeschlagenen CLIP-BEVFormer-Algorithmusmodells für Long-Tail-Probleme ist aus den experimentellen Ergebnissen in der obigen Tabelle ersichtlich Der nuScenes-Datensatz zeigt eine große Anzahl von Kategorien. Das Problem des Mengenungleichgewichts besteht darin, dass einige Kategorien wie (Baufahrzeuge, Busse, Motorräder, Fahrräder usw.) einen sehr geringen Anteil haben, der Anteil an Autos jedoch sehr hoch ist. Wir bewerten die Wahrnehmungsleistung des vorgeschlagenen CLIP-BEVFormer-Algorithmusmodells für Merkmalskategorien, indem wir relevante Experimente mit Long-Tail-Verteilungen durchführen und so seine Verarbeitungsfähigkeit zur Lösung weniger häufiger Kategorien überprüfen. Aus den obigen experimentellen Daten ist ersichtlich, dass das vorgeschlagene CLIP-BEVFormer-Algorithmusmodell in allen Kategorien Leistungsverbesserungen erzielt hat, und in Kategorien, die einen sehr kleinen Anteil ausmachen, hat das CLIP-BEVFormer-Algorithmusmodell offensichtliche wesentliche Leistungsverbesserungen gezeigt.
In Anbetracht der Tatsache, dass autonome Fahrsysteme in realen Umgebungen mit Problemen wie Hardwareausfällen, extremen Wetterbedingungen oder Sensorausfällen konfrontiert sein müssen, die leicht durch künstliche Hindernisse verursacht werden, haben wir die Robustheit des vorgeschlagenen Algorithmusmodells weiter experimentell überprüft. Um das Problem des Sensorausfalls zu simulieren, haben wir während des Modellimplementierungsinferenzprozesses zufällig die Kamera einer Kamera blockiert, um die Szene zu simulieren, in der die Kamera ausfallen könnte. Die relevanten experimentellen Ergebnisse sind in der folgenden Tabelle aufgeführt 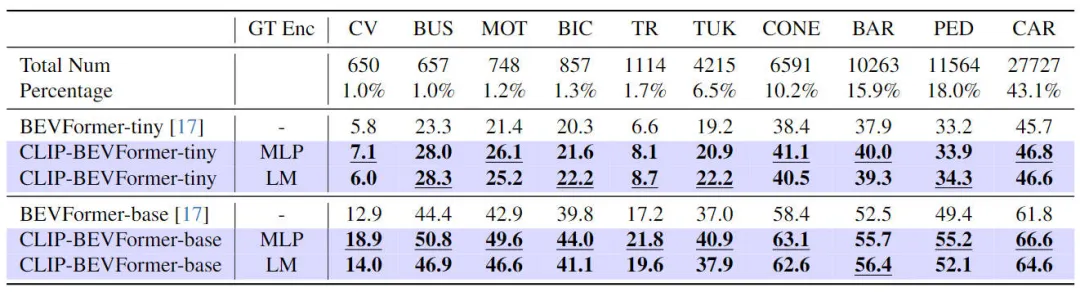 Die robusten experimentellen Ergebnisse des vorgeschlagenen CLIP-BEVFormer-Algorithmusmodells
Die robusten experimentellen Ergebnisse des vorgeschlagenen CLIP-BEVFormer-Algorithmusmodells
Aus den experimentellen Ergebnissen ist ersichtlich, dass das von uns vorgeschlagene CLIP-BEVFormer-Algorithmusmodell immer besser ist als BEVFormer, unabhängig von der Modellparameterkonfiguration von Tiny oder Base Modell mit der gleichen Konfiguration bestätigt die überlegene Leistung und ausgezeichnete Robustheit unseres Algorithmusmodells bei der Simulation von Sensorausfallbedingungen.
Teil der qualitativen AnalyseDie folgende Abbildung zeigt den visuellen Vergleich der Wahrnehmungsergebnisse unseres vorgeschlagenen CLIP-BEVFormer-Algorithmusmodells und des BEVFormer-Algorithmusmodells. Aus den visuellen Ergebnissen ist ersichtlich, dass die Wahrnehmungsergebnisse des von uns vorgeschlagenen CLIP-BEVFormer-Algorithmusmodells näher am wahren Wertziel liegen, was auf die Wirksamkeit des von uns vorgeschlagenen BEV-Merkmalsgenerierungsmoduls für den wahren Wert und des Abfrageinteraktionsmoduls für das wahre Wertziel hinweist . 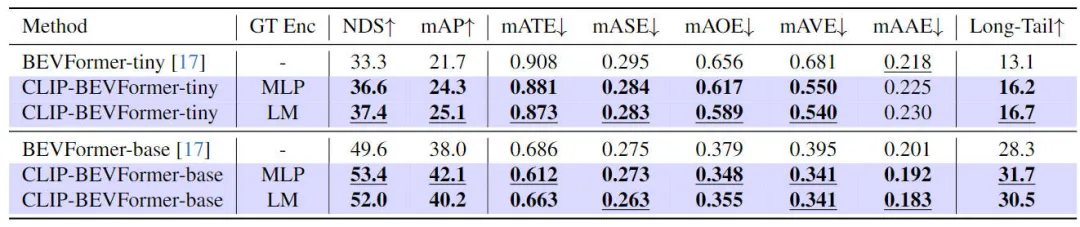

Visueller Vergleich der Wahrnehmungsergebnisse des vorgeschlagenen CLIP-BEVFormer-Algorithmusmodells und des BEVFormer-Algorithmusmodells
Fazit
In diesem Artikel konzentriert sich der ursprüngliche BEVFormer-Algorithmus auf die mangelnde Anzeigeüberwachung im Generierungsprozess BEV-Feature-Maps Neben der Unsicherheit der interaktiven Abfrage zwischen Objektabfrage und BEV-Features im Decoder-Modul haben wir das CLIP-BEVFormer-Algorithmusmodell vorgeschlagen und Experimente unter den Aspekten der 3D-Wahrnehmungsleistung des Algorithmusmodells und der Ziel-Long-Tail-Verteilung durchgeführt und Robustheit gegenüber Sensorausfällen. Eine große Anzahl experimenteller Ergebnisse zeigt die Wirksamkeit unseres vorgeschlagenen CLIP-BEVFormer-Algorithmusmodells.
Das obige ist der detaillierte Inhalt vonCLIP-BEVFormer: Überwacht explizit die BEVFormer-Struktur, um die Leistung der Long-Tail-Erkennung zu verbessern. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!