
Heim >Technologie-Peripheriegeräte >KI >Kommt die 3D-Version von Sora? UMass, MIT und andere schlagen 3D-Weltmodelle vor, und verkörperte intelligente Roboter erreichen neue Meilensteine
Kommt die 3D-Version von Sora? UMass, MIT und andere schlagen 3D-Weltmodelle vor, und verkörperte intelligente Roboter erreichen neue Meilensteine

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2024-03-25 16:10:121193Durchsuche
In neueren Forschungen handelt es sich bei der Eingabe des Vision-Language-Action-Modells (VLA, Vision-Language-Action) im Wesentlichen um 2D-Daten, ohne die allgemeinere 3D-Physik zu integrieren.
Darüber hinaus führen bestehende Modelle eine Aktionsvorhersage durch, indem sie die „direkte Abbildung wahrgenommener Aktionen“ lernen und dabei die Dynamik der Welt und die Beziehung zwischen Aktionen und Dynamik ignorieren.
Im Gegensatz dazu führen Menschen beim Denken Weltmodelle ein, die ihre Vorstellungen von Zukunftsszenarien beschreiben und ihre nächsten Handlungen planen können.
Zu diesem Zweck haben Forscher der University of Massachusetts Amherst, des MIT und anderer Institutionen das 3D-VLA-Modell vorgeschlagen. Durch die Einführung einer neuen Klasse verkörperter Grundmodelle kann es nahtlos mit dem generierten Weltmodell verbunden werden. Denken und Handeln. 
Projekthomepage: https://vis-www.cs.umass.edu/3dvla/
Papieradresse: https://arxiv.org/abs/2403.09631
Konkret basiert 3D-VLA auf einem 3D-basierten Large Language Model (LLM) und führt eine Reihe von Interaktionstoken ein, um an verkörperten Umgebungen teilzunehmen.
Das Qianchuang-Team trainierte eine Reihe verkörperter Diffusionsmodelle, fügte generative Fähigkeiten in die Modelle ein und ordnete sie in LLM ein, um Zielbilder und Punktwolken vorherzusagen.
Um das 3D-VLA-Modell zu trainieren, haben wir eine große Menge 3D-bezogener Informationen aus dem vorhandenen Roboterdatensatz extrahiert und einen riesigen 3D-Datensatz mit verkörperten Anweisungen erstellt.
Forschungsergebnisse zeigen, dass 3D-VLA bei der Bewältigung von Argumentations-, multimodalen Generierungs- und Planungsaufgaben in verkörperten Umgebungen gute Leistungen erbringt, was seinen potenziellen Anwendungswert in realen Szenarien unterstreicht.
3D Embodied Instruction Tuning Dataset
Aufgrund der milliardenschweren Datensätze im Internet hat VLM eine hervorragende Leistung bei mehreren Aufgaben und Millionen von Videoaktionsdaten gezeigt. Der Satz legt auch den Grundstein für konkretes VLM zur Robotersteuerung .
Allerdings können die meisten aktuellen Datensätze keine ausreichende Tiefe oder 3D-Annotation und präzise Steuerung für Roboteroperationen bieten. Dies erfordert, dass der Datensatz dreidimensionales räumliches Denken und Interaktionsinhalte enthält. Der Mangel an 3D-Informationen macht es für Roboter schwierig, Anweisungen zu verstehen und auszuführen, die räumliches 3D-Begreifen erfordern, wie zum Beispiel „Stellen Sie die am weitesten entfernte Tasse in die mittlere Schublade.“

Um diese Lücke zu schließen, haben Forscher einen umfangreichen 3D-Anweisungs-Tuning-Datensatz erstellt, der ausreichend „3D-bezogene Informationen“ und „entsprechende Textanweisungen“ zum Trainieren des Modells bereitstellt.
Die Forscher entwarfen eine Pipeline, um 3D-Sprachaktionspaare aus vorhandenen verkörperten Datensätzen zu extrahieren und so Anmerkungen zu Punktwolken, Tiefenkarten, 3D-Begrenzungsrahmen, 7D-Aktionen des Roboters und Textbeschreibungen zu erhalten.
3D-VLA-Basismodell
3D-VLA ist ein Weltmodell, das für dreidimensionales Denken, Zielgenerierung und Entscheidungsfindung in einer verkörperten Umgebung verwendet wird.
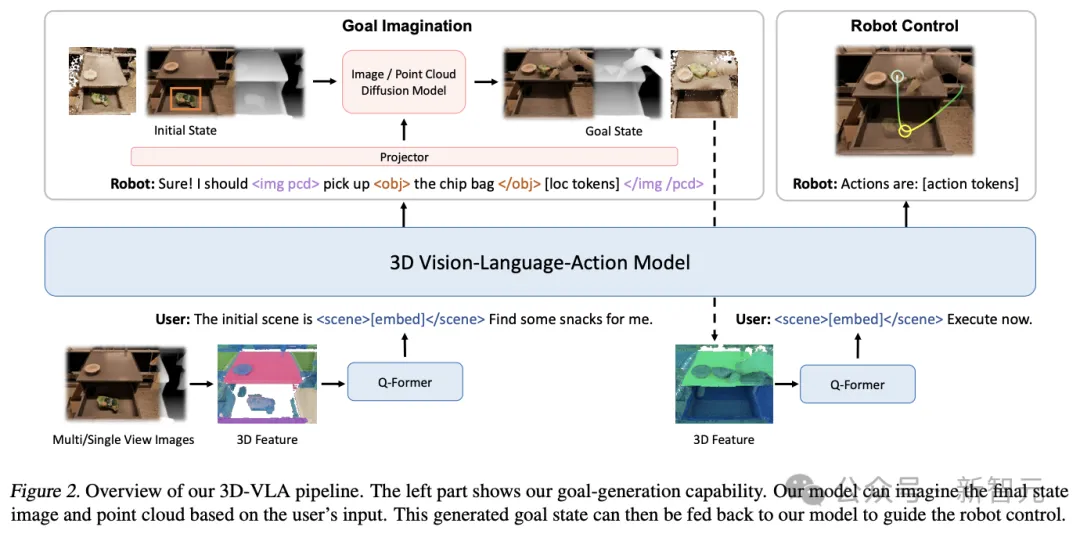
Bauen Sie zunächst das Backbone-Netzwerk auf der Grundlage von 3D-LLM auf und verbessern Sie die Fähigkeit des Modells, mit der 3D-Welt zu interagieren, indem Sie eine Reihe von Interaktionstoken hinzufügen. Trainieren Sie dann das Diffusionsmodell und verwenden Sie die Projektion dazu Richten Sie LLM und Diffusionsmodell aus und integrieren Sie Fähigkeiten zur Zielgenerierung in das 3D-VLA Der gesammelte Datensatz erreichte nicht den Milliardenbereich, der für das Training des multimodalen LLM von Grund auf erforderlich ist, und erfordert die Verwendung von Multi-View-Funktionen zur Generierung von 3D-Szenenfunktionen, sodass visuelle Funktionen nahtlos in das vorab trainierte VLM integriert werden können, ohne dass dies erforderlich ist zur Anpassung.
Gleichzeitig umfasst der Trainingsdatensatz von 3D-LLM hauptsächlich Objekte und Innenszenen, die nicht direkt mit den spezifischen Einstellungen übereinstimmen, weshalb sich die Forscher für die Verwendung von BLIP2-PlanT5XL als Vortrainingsmodell entschieden haben.
Entsperren Sie während des Trainingsprozesses die Eingabe- und Ausgabeeinbettungen von Token und die Gewichte von Q-Former.
Interaktionstoken
Um das Verständnis des Modells für 3D-Szenen und Interaktion in der Umgebung zu verbessern, führten die Forscher einen neuen Satz von Interaktionstoken ein
Zuerst wurden der Eingabe Objekttoken hinzugefügt, einschließlich Objektnomen in analysierten Sätzen (wie < ; obj> ein Schokoriegel auf dem Tisch), damit das Modell die manipulierten oder erwähnten Objekte besser erfassen kann.
Zweitens, um räumliche Informationen besser in der Sprache auszudrücken, entwarfen die Forscher eine Reihe von Positions-Tokens
Drittens wird
Die Architektur wird durch die Erweiterung des Satzes spezialisierter Marker, die Roboteraktionen darstellen, weiter verbessert. Die Aktion des Roboters verfügt über 7 Freiheitsgrade wie
Injizieren Sie Fähigkeiten zur Zielgenerierung
Menschen können den Endzustand der Szene vorab visualisieren, um die Genauigkeit der Aktionsvorhersage oder Entscheidungsfindung zu verbessern, was auch ein Schlüsselaspekt beim Aufbau eines Weltmodells ist In vorläufigen Experimenten stellten die Forscher außerdem fest, dass die Bereitstellung realistischer Endzustände die Argumentations- und Planungsfähigkeiten des Modells verbessern kann.
Aber das Trainieren von MLLM zum Generieren von Bildern, Tiefen- und Punktwolken ist nicht einfach:
Erstens ist das Videodiffusionsmodell nicht auf verkörperte Szenen wie Runway bei der Generierung zukünftiger Frames der „offenen Schublade“ zugeschnitten. In der Szene treten Probleme wie Ansichtsänderungen, Objektverformungen, seltsame Texturersetzungen und Layoutverzerrungen auf.
Und die Integration von Diffusionsmodellen verschiedener Moden in ein einziges Grundmodell ist immer noch ein schwieriges Problem.
Das von den Forschern vorgeschlagene neue Framework trainiert also zunächst das spezifische Diffusionsmodell auf der Grundlage verschiedener Formen wie Bilder, Tiefen- und Punktwolken vor und richtet dann den Decoder des Diffusionsmodells auf den Einbettungsraum von 3D-VLA aus in der Ausrichtungsphase.

Experimentelle Ergebnisse
3D-VLA ist ein vielseitiges, 3D-basiertes generatives Weltmodell, das Überlegungen und Lokalisierungen in der 3D-Welt durchführen, sich multimodale Zielinhalte vorstellen und für Roboteroperationen Aktionen generieren kann, Forscher Hauptsächlich wurde 3D-VLA unter drei Aspekten bewertet: 3D-Argumentation und -Lokalisierung, multimodale Zielgenerierung und verkörperte Aktionsplanung.
3D-Inferenz und -Lokalisierung
3D-VLA übertrifft alle 2D-VLM-Methoden bei Aufgaben zum sprachlichen Denken, was die Forscher auf die Nutzung von 3D-Informationen zurückführen, die genauere räumliche Informationen zum Denken liefern.
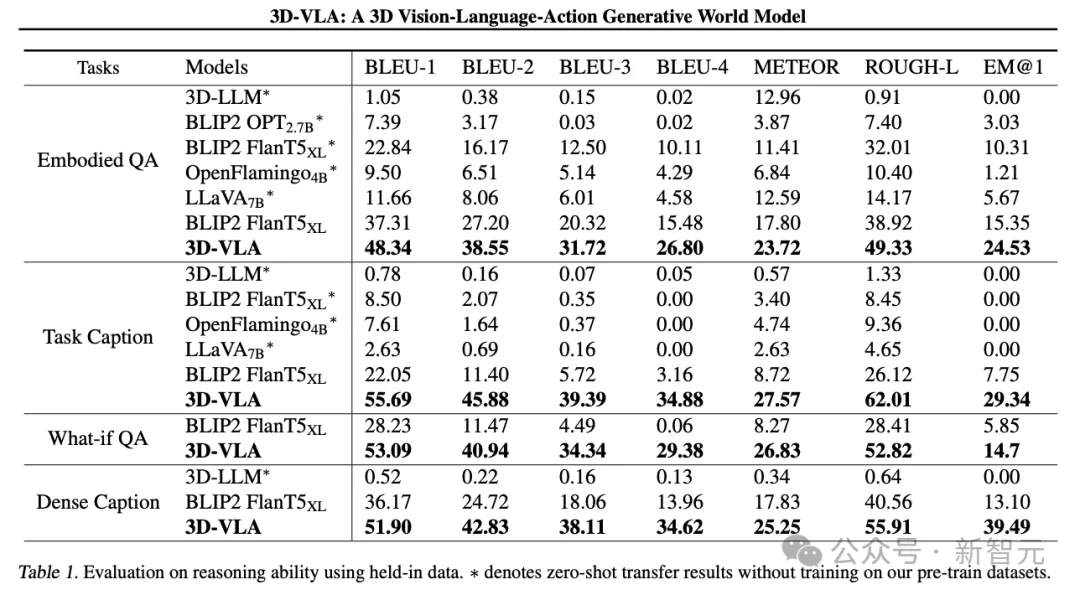
Da der Datensatz außerdem eine Reihe von 3D-Positionierungsanmerkungen enthält, lernt 3D-VLA, relevante Objekte zu lokalisieren, wodurch sich das Modell bei der Argumentation stärker auf Schlüsselobjekte konzentrieren kann.
Die Forscher fanden heraus, dass 3D-LLM bei diesen robotischen Inferenzaufgaben schlecht abschnitt, was die Notwendigkeit der Sammlung und des Trainings auf robotikbezogenen 3D-Datensätzen verdeutlicht.
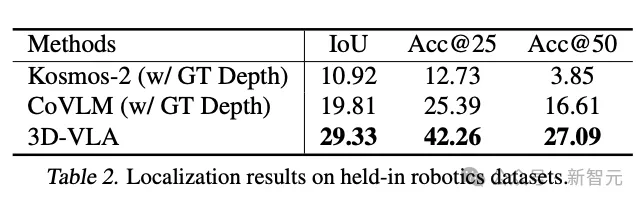
Und 3D-VLA schnitt bei der Lokalisierungsleistung deutlich besser ab als die 2D-Basismethode. Dieses Ergebnis liefert auch überzeugende Beweise für die Wirksamkeit des Annotationsprozesses und hilft dem Modell, leistungsstarke 3D-Positionierungsfunktionen zu erhalten.
Multimodale Zielgenerierung
Im Vergleich zu bestehenden Generierungsmethoden für die Zero-Shot-Übertragung in den Robotikbereich erzielt 3D-VLA in den meisten Metriken eine bessere Leistung, was die Verwendung von „speziell für Robotikanwendungen entwickelten“ Verwendungszwecken bestätigt Entwerfen von Datensätzen zum Trainieren von Weltmodellen.
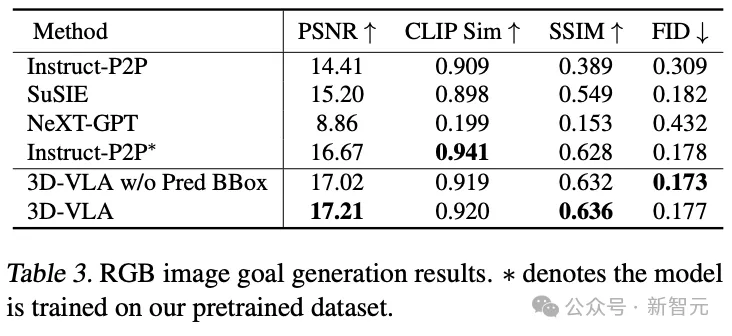
Selbst im direkten Vergleich mit Instruct-P2P* schneidet 3D-VLA durchweg besser ab, und die Ergebnisse zeigen, dass die Integration großer Sprachmodelle in 3D-VLA ein umfassenderes und tieferes Verständnis der Roboterbetriebsanweisungen ermöglicht und dadurch verbessert wird die angestrebte Bildgenerierungsleistung.
Darüber hinaus kann beim Ausschließen vorhergesagter Begrenzungsrahmen aus der Eingabeaufforderung ein leichter Leistungsabfall beobachtet werden, was die Wirksamkeit der Verwendung von vorhergesagten Zwischenrahmen bestätigt, die dem Modell helfen können, die gesamte Szene zu verstehen und die Integration in das Modell zu ermöglichen Den spezifischen Objekten, die in einer gegebenen Anweisung erwähnt werden, wird mehr Aufmerksamkeit gewidmet, was letztendlich seine Fähigkeit verbessert, sich das endgültige Zielbild vorzustellen.
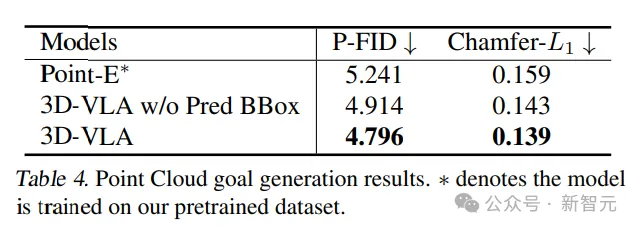
Bei einem Vergleich der aus Punktwolken generierten Ergebnisse schnitt 3D-VLA mit zwischenzeitlich vorhergesagten Begrenzungsrahmen am besten ab und bestätigte die Bedeutung der Kombination großer Sprachmodelle und präziser Objektlokalisierung im Kontext des Verständnisses von Anweisungen und Szenen.
Verkörperte Aktionsplanung
3D-VLA übertrifft die Leistung des Basismodells bei den meisten Aufgaben in der RLBench-Aktionsvorhersage und zeigt seine Planungsfähigkeiten.
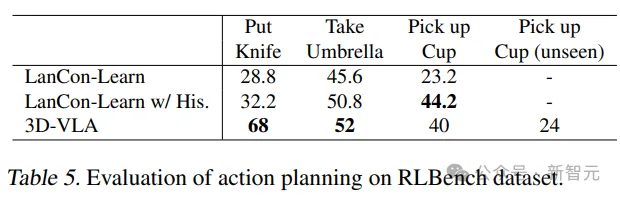
Es ist erwähnenswert, dass das Basismodell die Verwendung historischer Beobachtungen, Objektstatus und aktueller Statusinformationen erfordert, während das 3D-VLA-Modell nur durch Steuerung im offenen Regelkreis ausgeführt wird.
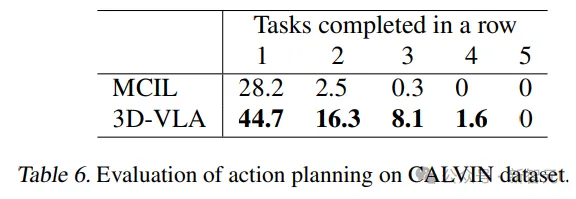
Darüber hinaus wurde die Generalisierungsfähigkeit des Modells auch in der Pick-up-Cup-Aufgabe nachgewiesen. Diesen Vorteil führten die Forscher auf die Fähigkeit zur Objektlokalisierung zurück von Interesse und imaginären Zielzuständen liefert umfassende Informationen für die Ableitung von Aktionen.
Das obige ist der detaillierte Inhalt vonKommt die 3D-Version von Sora? UMass, MIT und andere schlagen 3D-Weltmodelle vor, und verkörperte intelligente Roboter erreichen neue Meilensteine. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!