
Heim >Technologie-Peripheriegeräte >KI >Zusätzlich zu CNN, Transformer und Uniformer verfügen wir endlich über eine effizientere Technologie zum Verstehen von Videos
Zusätzlich zu CNN, Transformer und Uniformer verfügen wir endlich über eine effizientere Technologie zum Verstehen von Videos

- PHPznach vorne
- 2024-03-25 09:16:53739Durchsuche
Das Hauptziel des Videoverständnisses besteht darin, die räumlich-zeitliche Darstellung genau zu verstehen, steht jedoch vor zwei großen Herausforderungen: In kurzen Videoclips gibt es viele räumlich-zeitliche Redundanzen und komplexe räumlich-zeitliche Abhängigkeiten. Dreidimensionale Faltungs-Neuronale Netze (CNN) und Videotransformatoren haben bei der Lösung einer dieser Herausforderungen gute Leistungen erbracht, weisen jedoch gewisse Mängel bei der gleichzeitigen Bewältigung beider Herausforderungen auf. UniFormer versucht, die Vorteile beider Ansätze zu kombinieren, stößt jedoch bei der Modellierung langer Videos auf Schwierigkeiten.
Das Aufkommen kostengünstiger Lösungen wie S4, RWKV und RetNet im Bereich der Verarbeitung natürlicher Sprache hat neue Möglichkeiten für visuelle Modelle eröffnet. Mamba zeichnet sich durch sein Selective State Space Model (SSM) aus, das ein Gleichgewicht zwischen der Beibehaltung linearer Komplexität und der Erleichterung einer langfristigen dynamischen Modellierung erreicht. Diese Innovation treibt ihre Anwendung bei Bildverarbeitungsaufgaben voran, wie Vision Mamba und VMamba demonstrieren, die multidirektionales SSM nutzen, um die 2D-Bildverarbeitung zu verbessern. Diese Modelle sind in ihrer Leistung mit aufmerksamkeitsbasierten Architekturen vergleichbar und reduzieren gleichzeitig die Speichernutzung erheblich.
Angesichts der Tatsache, dass die von Videos erzeugten Sequenzen selbst länger sind, stellt sich natürlich die Frage: Funktioniert Mamba gut für das Videoverständnis?
Inspiriert von Mamba stellt dieser Artikel VideoMamba vor, ein SSM (Selective State Space Model), das speziell auf das Videoverständnis zugeschnitten ist. VideoMamba greift auf die Designphilosophie von Vanilla ViT auf und kombiniert Faltungs- und Aufmerksamkeitsmechanismen. Es bietet eine lineare Komplexitätsmethode für die dynamische räumlich-zeitliche Hintergrundmodellierung, die sich besonders für die Verarbeitung hochauflösender langer Videos eignet. Die Bewertung konzentriert sich hauptsächlich auf vier Schlüsselfunktionen von VideoMamba:
Skalierbarkeit im visuellen Bereich: Dieser Artikel untersucht die Skalierbarkeit von VideoMamba und stellt fest, dass das reine Mamba-Modell tendenziell leicht zu bestehen ist, wenn es weiter expandiert Passend dazu stellt dieses Dokument eine einfache, aber effektive Selbstdestillationsstrategie vor, die es VideoMamba ermöglicht, bei steigenden Modell- und Eingabegrößen erhebliche Leistungssteigerungen zu erzielen, ohne dass ein umfangreiches Vortraining für Datensätze erforderlich ist.
Sensibilität für die Erkennung kurzfristiger Aktionen: Die Analyse in diesem Artikel erstreckt sich auf die Bewertung der Fähigkeit von VideoMamba, kurzfristige Aktionen genau zu unterscheiden, insbesondere solche mit subtilen Bewegungsunterschieden, wie z. B. Öffnen und Schließen. Forschungsergebnisse zeigen, dass VideoMamba im Vergleich zu bestehenden aufmerksamkeitsbasierten Modellen eine hervorragende Leistung aufweist. Noch wichtiger ist, dass es sich auch für die Maskenmodellierung eignet, wodurch die zeitliche Empfindlichkeit weiter verbessert wird.
Überlegenheit beim Verständnis langer Videos: Dieser Artikel bewertet die Fähigkeit von VideoMamba, lange Videos zu interpretieren. Mit der End-to-End-Schulung zeigt es erhebliche Vorteile gegenüber herkömmlichen funktionsbasierten Methoden. Bemerkenswert ist, dass VideoMamba bei 64-Frame-Videos sechsmal schneller läuft als TimeSformer und 40-mal weniger GPU-Speicher benötigt (siehe Abbildung 1).

Kompatibilität mit anderen Modalitäten: Abschließend bewertet dieser Artikel die Anpassungsfähigkeit von VideoMamba mit anderen Modalitäten. Die Ergebnisse beim Abrufen von Videotexten zeigen eine verbesserte Leistung im Vergleich zu ViT, insbesondere bei langen Videos mit komplexen Szenarien. Dies unterstreicht seine Robustheit und multimodalen Integrationsfähigkeiten.
Die ausführlichen Experimente dieser Studie zeigen das enorme Potenzial von VideoMamba für das kurzfristige (K400 und SthSthV2) und langfristige (Breakfast, COIN und LVU) Verständnis von Videoinhalten. VideoMamba weist eine hohe Effizienz und Genauigkeit auf, was darauf hindeutet, dass es eine Schlüsselkomponente im Bereich des Verständnisses langer Videos werden wird. Um zukünftige Forschung zu erleichtern, wurden alle Codes und Modelle als Open Source bereitgestellt.

- Papieradresse: https://arxiv.org/pdf/2403.06977.pdf
- Projektadresse: https://github.com/OpenGVLab/VideoMamba
- Papier Titel: VideoMamba: State Space Model for Efficient Video Understanding
Einführung in die Methode
Abbildung 2a unten zeigt die Details des Mamba-Moduls.

Abbildung 3 veranschaulicht das Gesamtgerüst von VideoMamba. In diesem Artikel wird zunächst die 3D-Faltung (d. h. 1×16×16) verwendet, um das Eingabevideo Xv ∈ R 3×T ×H×W auf L nicht überlappende räumlich-zeitliche Patches Xp ∈ R L×C zu projizieren, wobei L=t×h ×w (t=T, h= H 16 und w= W 16). Die Token-Sequenzeingabe für den nächsten VideoMamba-Encoder ist 

Spatiotemporaler Scan: Um die B-Mamba-Ebene auf die räumlich-zeitliche Eingabe anzuwenden, wird der ursprüngliche 2D-Scan in Abbildung 4 von in verschiedene bidirektionale 3D-Scans erweitert dieser Artikel:
(a) Zuerst räumlich, räumliche Token nach Position organisieren und dann Bild für Bild stapeln;
(b) Zuerst zeitlich, Zeittoken nach Frames anordnen, dann entlang räumlicher Dimensionen stapeln;
( c) Raum-Zeit-Hybrid mit sowohl Raumpriorität als auch Zeitpriorität, wobei v1 die Hälfte davon ausführt und v2 alles ausführt (2-fache Berechnungsmenge).
Das Experiment in Abbildung 7a zeigt, dass das bidirektionale Scannen im Raum zuerst am effizientesten und zugleich am einfachsten ist. Aufgrund der linearen Komplexität von Mamba kann VideoMamba in diesem Artikel hochauflösende lange Videos effizient verarbeiten.

Für SSM in der B-Mamba-Ebene verwendet dieser Artikel dieselben Standard-Hyperparametereinstellungen wie Mamba und legt die Zustandsdimension und das Erweiterungsverhältnis auf 16 bzw. 2 fest. In Anlehnung an den Ansatz von ViT werden in diesem Dokument die Tiefe und die Einbettungsabmessungen angepasst, um Modelle vergleichbarer Größe wie in Tabelle 1 zu erstellen, einschließlich VideoMamba-Ti, VideoMamba-S und VideoMamba-M. In Experimenten wurde jedoch beobachtet, dass größere VideoMamba in Experimenten häufig zu einer Überanpassung neigen, was zu einer suboptimalen Leistung führt, wie in Abbildung 6a dargestellt. Dieses Überanpassungsproblem besteht nicht nur in dem in diesem Artikel vorgeschlagenen Modell, sondern auch in VMamba, wo die beste Leistung von VMamba-B nach drei Vierteln der gesamten Trainingszeit erreicht wird. Um das Überanpassungsproblem größerer Mamba-Modelle zu bekämpfen, stellt dieser Artikel eine effektive Selbstdestillationsstrategie vor, die kleinere und gut ausgebildete Modelle als „Lehrer“ verwendet, um das Training größerer „Schüler“-Modelle zu leiten. Die in Abbildung 6a dargestellten Ergebnisse zeigen, dass diese Strategie zu der erwarteten besseren Konvergenz führt.


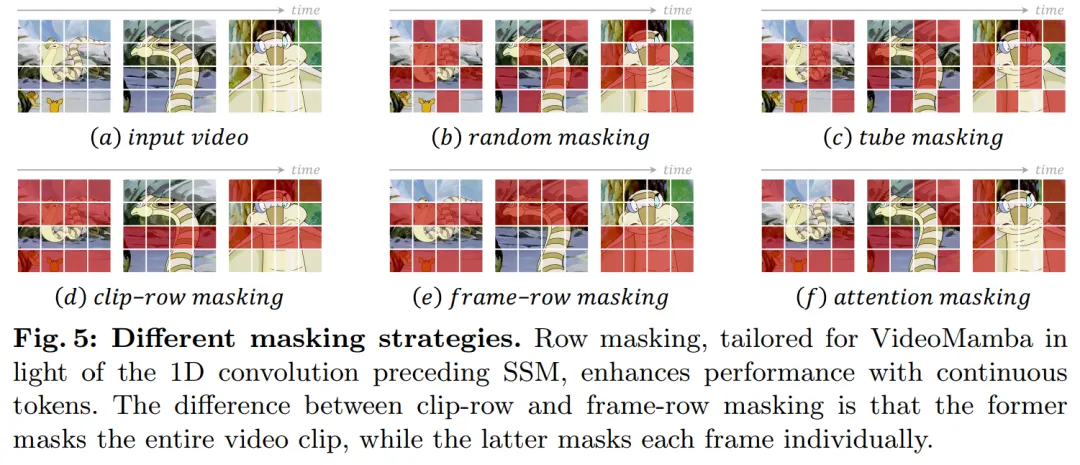
In Bezug auf die Maskierungsstrategie schlägt dieses Papier verschiedene Zeilenmaskierungstechniken vor, wie in Abbildung 5 dargestellt, die speziell auf die Präferenz des B-Mamba-Blocks für aufeinanderfolgende Token abzielen.
Experimente
Tabelle 2 zeigt die Ergebnisse des ImageNet-1K-Datensatzes. Bemerkenswert ist, dass VideoMamba-M andere isotrope Architekturen deutlich übertrifft und sich im Vergleich zu ConvNeXt-B um +0,8 % und im Vergleich zu DeiT-B um +2,0 % verbessert, während weniger Parameter verwendet werden. VideoMamba-M funktioniert auch in einer nicht-isotropen Backbone-Struktur gut, die geschichtete Funktionen für eine verbesserte Leistung verwendet. Angesichts der Effizienz von Mamba bei der Verarbeitung langer Sequenzen verbessert dieser Artikel die Leistung durch Erhöhung der Auflösung weiter und erreicht mit nur 74 Millionen Parametern eine Top-1-Genauigkeit von 84,0 %.
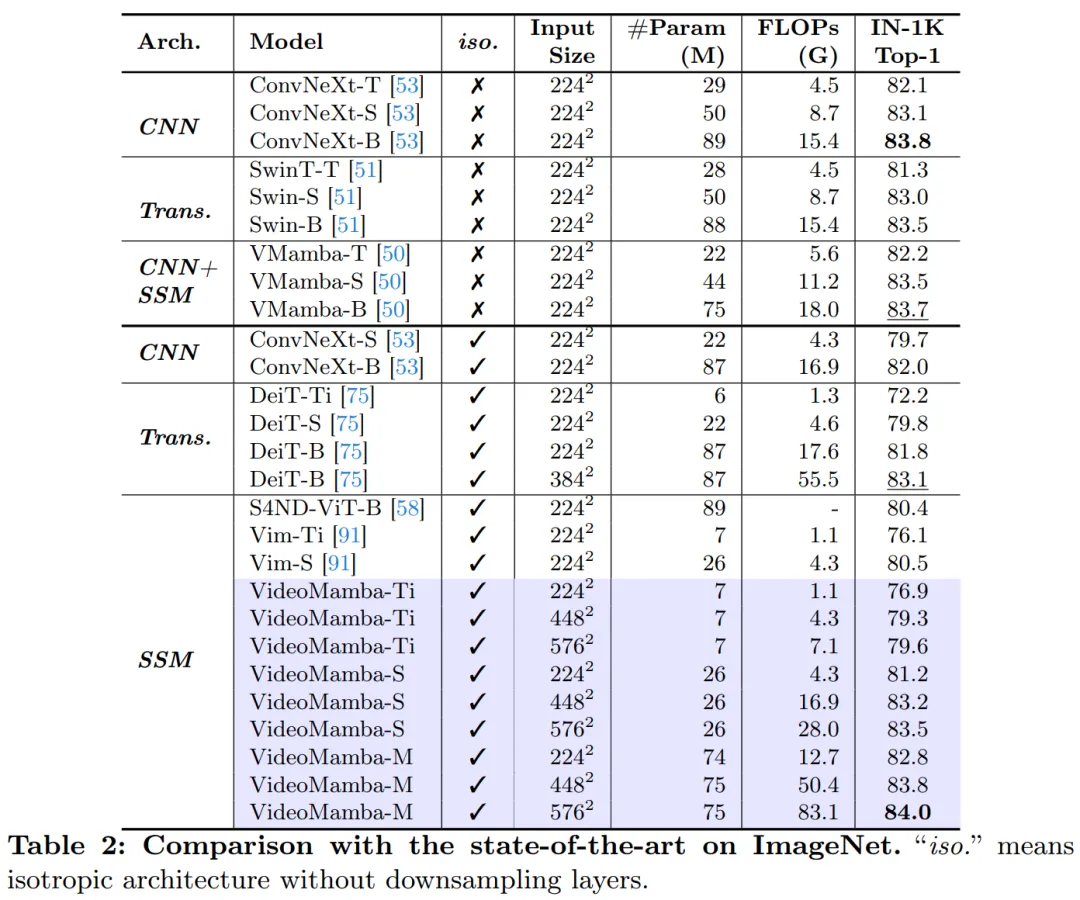
Tabelle 3 und Tabelle 4 listen die Ergebnisse des Kurzzeit-Videodatensatzes auf. (a) Überwachtes Lernen: Im Vergleich zu reinen Aufmerksamkeitsmethoden erzielte VideoMamba-M auf Basis von SSM offensichtliche Vorteile und übertraf ViViT-L bei den szenenbezogenen K400- und zeitbezogenen Sth-SthV2-Datensätzen um +2,0 % bzw. +3,0 %. Diese Verbesserung geht mit deutlich geringeren Rechenanforderungen und weniger Daten vor dem Training einher. Die Ergebnisse von VideoMamba-M sind mit denen von SOTA UniFormer vergleichbar, der Faltung und Aufmerksamkeit geschickt in eine nicht-isotrope Architektur integriert. (b) Selbstüberwachtes Lernen: Mit dem Masken-Vortraining übertrifft VideoMamba VideoMAE, das für seine Feinmotorik bekannt ist. Dieser Erfolg unterstreicht das Potenzial unseres reinen SSM-basierten Modells, Kurzzeitvideos effizient und effektiv zu verstehen, und unterstreicht seine Eignung sowohl für überwachte als auch für selbstüberwachte Lernparadigmen.


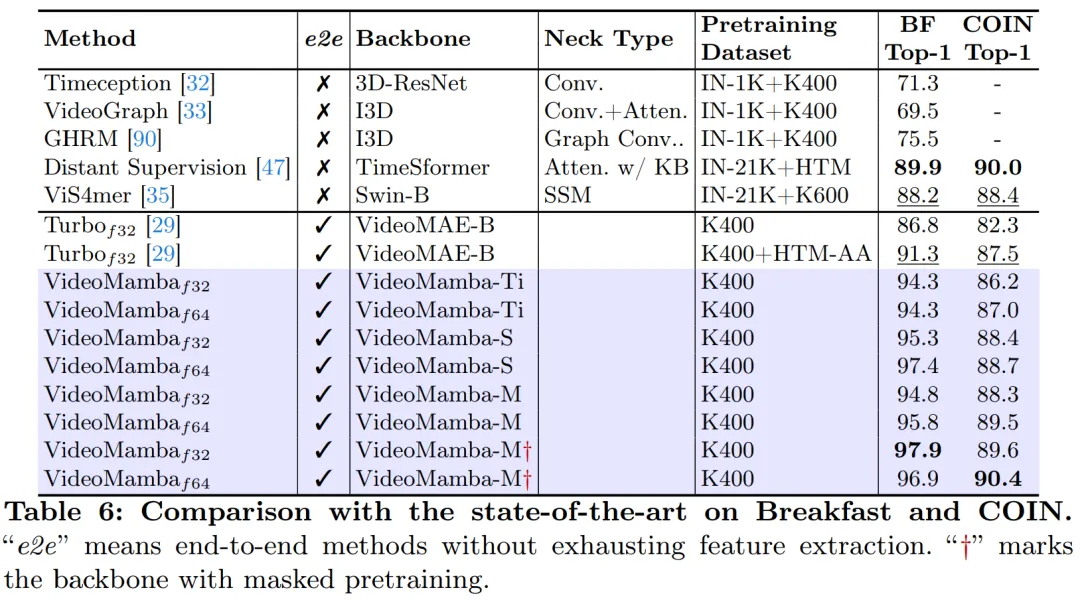
Wie in Abbildung 1 gezeigt, eignet sich VideoMamba aufgrund seiner linearen Komplexität sehr gut für End-to-End-Training mit Langzeitvideos. Der Vergleich in den Tabellen 6 und 7 verdeutlicht die Einfachheit und Effektivität von VideoMamba gegenüber herkömmlichen funktionsbasierten Methoden bei diesen Aufgaben. Es bringt erhebliche Leistungsverbesserungen mit sich und ermöglicht SOTA-Ergebnisse auch bei kleineren Modellgrößen. VideoMamba-Ti zeigt eine deutliche Verbesserung von +6,1 % gegenüber ViS4mer mit Swin-B-Funktionen und auch eine Verbesserung von +3,0 % gegenüber der multimodalen Ausrichtungsmethode von Turbo. Die Ergebnisse unterstreichen insbesondere die positiven Auswirkungen von Skalierungsmodellen und Bildraten für Langzeitaufgaben. In Bezug auf neun verschiedene und herausfordernde Aufgaben, die von der LVU vorgeschlagen wurden, verfolgt dieses Papier einen End-to-End-Ansatz zur Feinabstimmung von VideoMamba-Ti und erzielt Ergebnisse, die mit aktuellen SOTA-Methoden vergleichbar oder diesen überlegen sind. Diese Ergebnisse unterstreichen nicht nur die Wirksamkeit von VideoMamba, sondern zeigen auch sein großes Potenzial für das zukünftige Verständnis langer Videos.
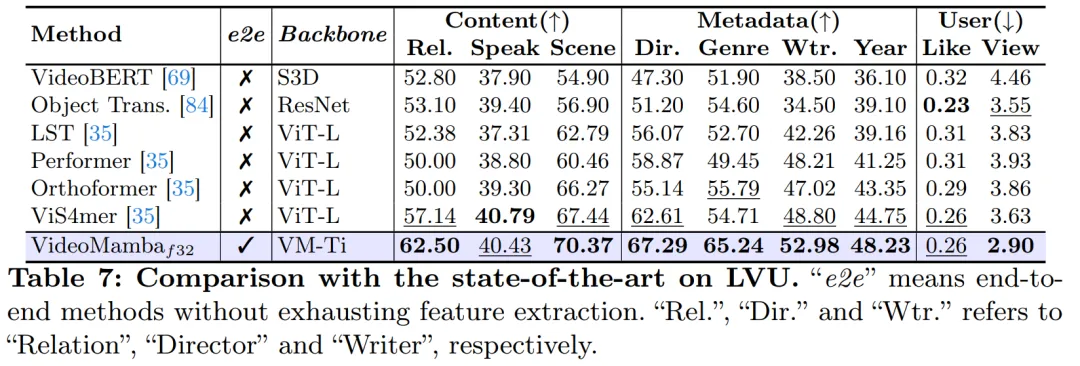
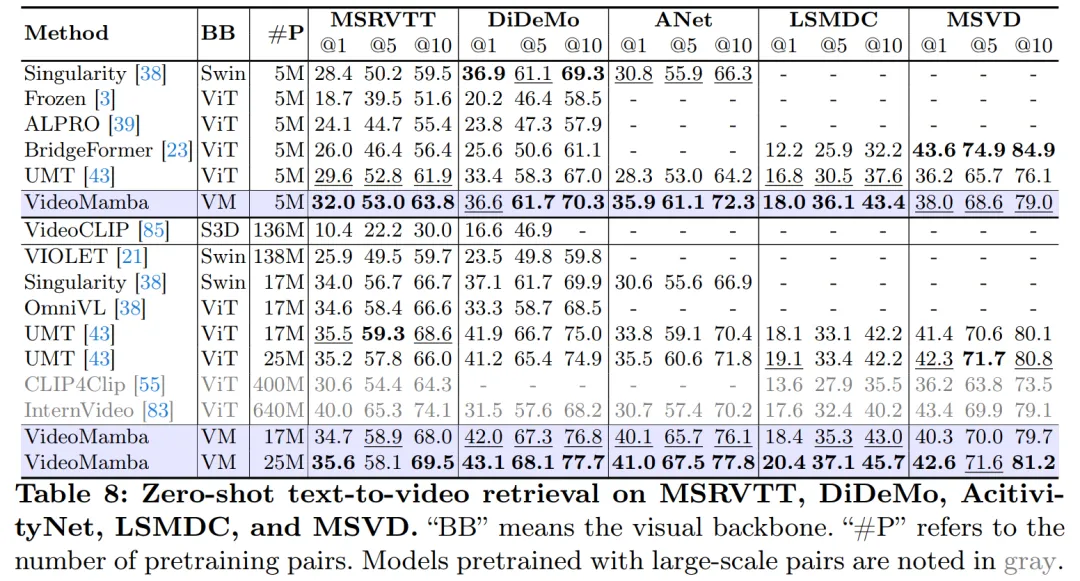
Wie in Tabelle 8 gezeigt, übertrifft VideoMamba mit demselben Pre-Training-Korpus und einer ähnlichen Trainingsstrategie die ViT-basierte UMT bei der Leistung beim Zero-Shot-Videoabruf. Dies unterstreicht die vergleichbare Effizienz und Skalierbarkeit von Mamba im Vergleich zu ViT bei der Verarbeitung multimodaler Videoaufgaben. Insbesondere zeigt VideoMamba erhebliche Verbesserungen für Datensätze mit längeren Videolängen (z. B. ANet und DiDeMo) und komplexeren Szenarien (z. B. LSMDC). Dies zeigt die Fähigkeiten von Mamba in anspruchsvollen multimodalen Umgebungen, selbst wenn eine modalübergreifende Ausrichtung erforderlich ist.
Weitere Forschungsdetails finden Sie im Originalpapier.
Das obige ist der detaillierte Inhalt vonZusätzlich zu CNN, Transformer und Uniformer verfügen wir endlich über eine effizientere Technologie zum Verstehen von Videos. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!