
Heim >Technologie-Peripheriegeräte >KI >Tiefenschätzung SOTA! Adaptive Fusion von Monokular- und Surround-Tiefe für autonomes Fahren
Tiefenschätzung SOTA! Adaptive Fusion von Monokular- und Surround-Tiefe für autonomes Fahren

- PHPznach vorne
- 2024-03-23 13:06:021415Durchsuche
Vorher geschrieben & persönliches Verständnis
Die Multi-View-Tiefenschätzung hat in verschiedenen Benchmark-Tests eine hohe Leistung erzielt. Allerdings basieren fast alle aktuellen Multi-View-Systeme auf einer vorgegebenen idealen Kameraposition, die in vielen realen Szenarien, wie etwa beim autonomen Fahren, nicht verfügbar ist. Diese Arbeit schlägt einen neuen Robustheits-Benchmark zur Bewertung von Tiefenschätzungssystemen unter verschiedenen verrauschten Poseneinstellungen vor. Überraschenderweise wurde festgestellt, dass aktuelle Multi-View-Tiefenschätzungsmethoden oder Single-View- und Multi-View-Fusion-Methoden bei verrauschten Poseneinstellungen versagen. Um dieser Herausforderung zu begegnen, schlagen wir hier AFNet vor, ein System zur fusionierten Tiefenschätzung mit Einzelansicht und Mehrfachansicht, das hochzuverlässige Mehrfachansichts- und Einzelansichtsergebnisse adaptiv integriert, um eine robuste und genaue Tiefenschätzung zu erreichen. Das adaptive Fusionsmodul führt die Fusion durch, indem es basierend auf der Paketkonfidenzkarte dynamisch hochzuverlässige Regionen zwischen den beiden Zweigen auswählt. Daher wählt das System tendenziell den zuverlässigeren Zweig, wenn es mit texturlosen Szenen, ungenauer Kalibrierung, dynamischen Objekten und anderen beeinträchtigten oder herausfordernden Bedingungen konfrontiert wird. Bei Robustheitstests übertrifft die Methode modernste Multiview- und Fusionsverfahren. Darüber hinaus wird bei anspruchsvollen Benchmarks (KITTI und DDAD) eine hochmoderne Leistung erzielt.
Link zum Papier: https://arxiv.org/pdf/2403.07535.pdf
Name des Papiers: Adaptive Fusion of Single-View and Multi-View Depth for Autonomous Driving
Feldhintergrund
Die Schätzung der Bildtiefe hat schon immer funktioniert Eine Herausforderung im Bereich Computer Vision mit einem breiten Anwendungsspektrum. Für visionsbasierte autonome Fahrsysteme ist die Tiefenwahrnehmung von entscheidender Bedeutung. Sie hilft dabei, Objekte auf der Straße zu verstehen und 3D-Karten der Umgebung zu erstellen. Mit der Anwendung tiefer neuronaler Netze bei verschiedenen visuellen Problemen sind Methoden, die auf Faltungs-Neuronalen Netzen (CNN) basieren, zum Mainstream für Tiefenschätzungsaufgaben geworden.
Je nach Eingabeformat wird es hauptsächlich in Tiefenschätzungen mit mehreren Ansichten und Tiefenschätzungen mit Einzelansichten unterteilt. Die Annahme hinter Multi-View-Methoden zur Tiefenschätzung ist, dass bei korrekter Tiefe, Kamerakalibrierung und Kameraposition die Pixel aller Ansichten ähnlich sein sollten. Sie verlassen sich auf die epipolare Geometrie, um qualitativ hochwertige Tiefenmessungen zu triangulieren. Allerdings hängen die Genauigkeit und Robustheit von Multi-View-Methoden stark von der geometrischen Konfiguration der Kamera und der entsprechenden Übereinstimmung zwischen den Ansichten ab. Zunächst muss die Kamera ausreichend verschoben werden, um eine Triangulation zu ermöglichen. In einem selbstfahrenden Szenario kann es sein, dass das selbstfahrende Fahrzeug an einer Ampel anhält oder abbiegt, ohne vorwärts zu fahren, was dazu führen kann, dass die Triangulation fehlschlägt. Darüber hinaus leiden Multi-View-Methoden unter den Problemen dynamischer Ziele und texturloser Bereiche, die in autonomen Fahrszenarien vorherrschen. Ein weiteres Problem ist die Optimierung der SLAM-Lage bei fahrenden Fahrzeugen. Bei bestehenden SLAM-Methoden ist Rauschen unvermeidlich, ganz zu schweigen von herausfordernden und unvermeidbaren Situationen. Beispielsweise kann ein Roboter oder ein selbstfahrendes Auto jahrelang ohne Neukalibrierung eingesetzt werden, was zu lauten Posen führt. Da Single-View-Methoden im Gegensatz dazu auf semantischem Verständnis der Szene und perspektivischen Projektionshinweisen beruhen, sind sie robuster gegenüber texturlosen Regionen und dynamischen Objekten und verlassen sich nicht auf die Kameraposition. Aufgrund der Mehrdeutigkeit des Maßstabs bleibt seine Leistung jedoch immer noch weit hinter Multi-View-Methoden zurück. Hier neigen wir dazu zu überlegen, ob die Vorteile dieser beiden Methoden für eine robuste und genaue monokulare Videotiefenschätzung in autonomen Fahrszenarien gut kombiniert werden können.
AFNet-Netzwerkstruktur
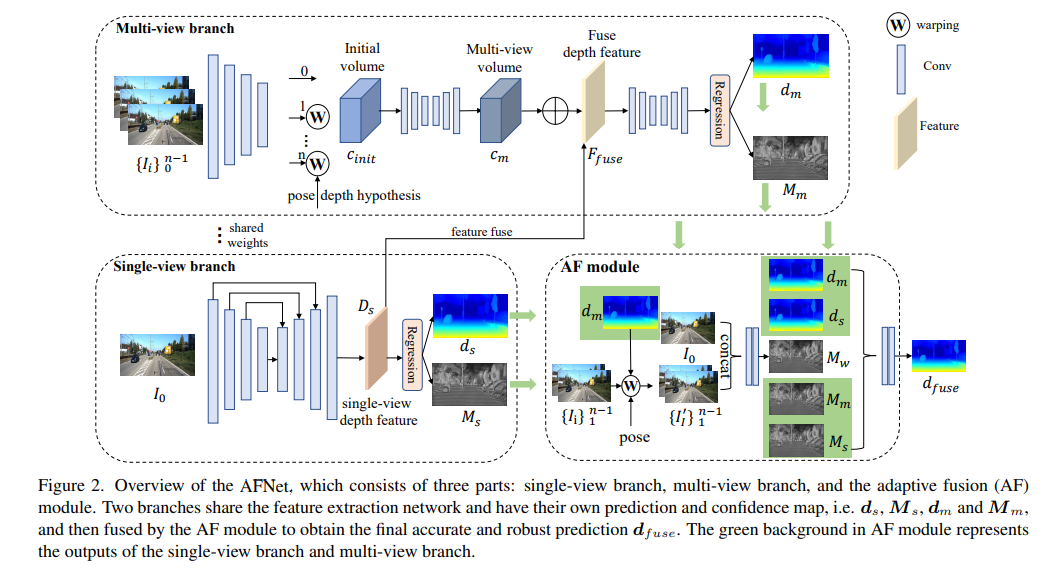
AFNet-Struktur ist unten dargestellt. Sie besteht aus drei Teilen: Single-View-Zweig, Multi-View-Zweig und adaptives Fusionsmodul (AF). Die beiden Zweige teilen sich das Merkmalsextraktionsnetzwerk und verfügen über ihre eigenen Vorhersage- und Konfidenzkarten, d. h. , und , und werden dann vom AF-Modul zusammengeführt, um die endgültige genaue und robuste Vorhersage zu erhalten. Der grüne Hintergrund im AF-Modul stellt die einzelne dar -view-Zweig und Die Ausgabe des Multi-View-Zweigs.
Verlustfunktion:

Single-View- und Multi-View-Tiefenmodule
Um die Backbone-Features zusammenzuführen und die Deep-Features-DS zu erhalten, erstellt AFNet einen Multi-Scale-Decoder. In diesem Prozess wird eine Softmax-Operation an den ersten 256 Kanälen von Ds durchgeführt, um das Tiefenwahrscheinlichkeitsvolumen Ps zu erhalten. Der letzte Kanal in der Tiefenfunktion wird als Einzelansicht-Tiefenkonfidenzkarte Ms verwendet. Abschließend wird die Einzelansichtstiefe durch weiche Gewichtung berechnet.
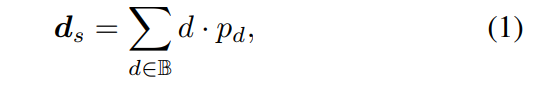
Multi-View-Zweig
Der Multi-View-Zweig teilt das Rückgrat mit dem Single-View-Zweig, um Merkmale des Referenzbilds und des Quellbilds zu extrahieren. Wir verwenden die Entfaltung, um die Merkmale mit niedriger Auflösung auf eine Viertelauflösung zu entfalten und sie mit den anfänglichen Viertelmerkmalen zu kombinieren, die zur Erstellung des Kostenvolumens verwendet werden. Ein Merkmalsvolumen wird gebildet, indem die Quellmerkmale in eine hypothetische Ebene eingewickelt werden, gefolgt von der Referenzkamera. Für ein robustes Matching, das nicht zu viele Informationen erfordert, wird die Kanaldimension des Merkmals in der Berechnung beibehalten und ein 4D-Kostenvolumen erstellt. Anschließend wird die Anzahl der Kanäle durch zwei 3D-Faltungsschichten auf 1 reduziert.
Die Stichprobenmethode der Tiefenhypothese stimmt mit der Einzelansichtsverzweigung überein, die Anzahl der Stichproben beträgt jedoch nur 128 und wird dann mithilfe eines gestapelten 2D-Sanduhrnetzwerks reguliert, um das endgültige Kostenvolumen für mehrere Ansichten zu erhalten. Um die umfangreichen semantischen Informationen von Einzelansichtsmerkmalen und die aufgrund der Kostenregulierung verlorenen Details zu ergänzen, wird eine Reststruktur verwendet, um Einzelansichts-Tiefenmerkmale Ds und Kostenvolumen zu kombinieren, um fusionierte Tiefenmerkmale wie folgt zu erhalten:
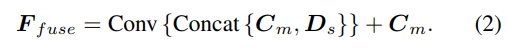
Adaptives Fusionsmodul
Um die endgültige genaue und robuste Vorhersage zu erhalten, ist das AF-Modul so konzipiert, dass es adaptiv die genaueste Tiefe zwischen den beiden Zweigen als endgültige Ausgabe auswählt, wie in Abbildung 2 dargestellt. Die Fusionszuordnung erfolgt über drei Konfidenzen, von denen zwei die von den beiden Zweigen generierten Konfidenzkarten Ms und Mm sind. Die kritischste ist die durch Vorwärtsumbruch generierte Konfidenzkarte Mw, um zu bestimmen, ob die Vorhersage des Multi-View-Zweigs stimmt zuverlässig. .
Experimentelle Ergebnisse
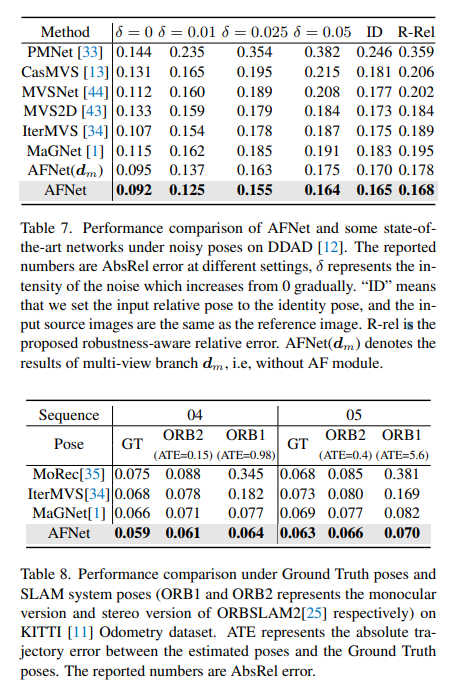
DDAD (Dense Depth for Autonomous Driving) ist ein neuer Benchmark für autonomes Fahren zur Schätzung dichter Tiefen unter anspruchsvollen und vielfältigen städtischen Bedingungen. Es wird von 6 synchronisierten Kameras erfasst und enthält eine genaue Bodentiefe (gesamtes 360-Grad-Sichtfeld), die durch hochdichtes Lidar generiert wird. Es verfügt über 12650 Trainingsbeispiele und 3950 Validierungsbeispiele in einer einzigen Kameraansicht mit einer Auflösung von 1936 x 1216. Alle Daten von 6 Kameras werden für Training und Tests verwendet. Der KITTI-Datensatz liefert stereoskopische Bilder von Außenszenen, die mit fahrenden Fahrzeugen aufgenommen wurden, und entsprechende 3D-Laserscans mit einer Auflösung von etwa 1241×376.
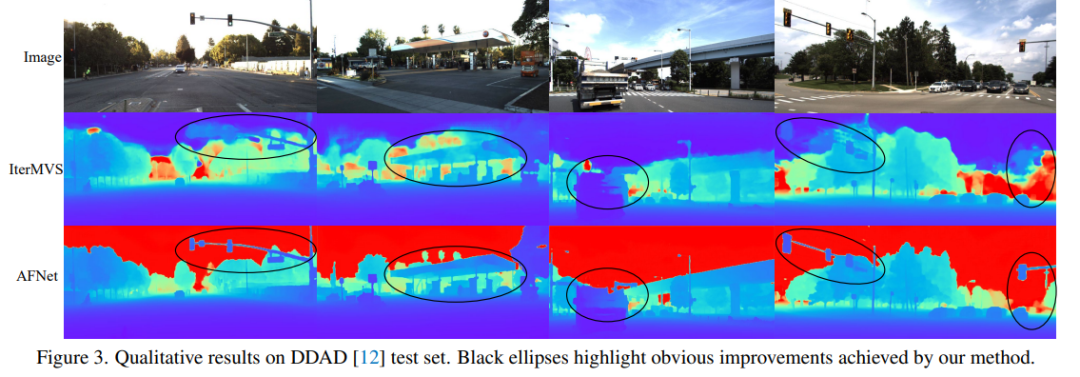
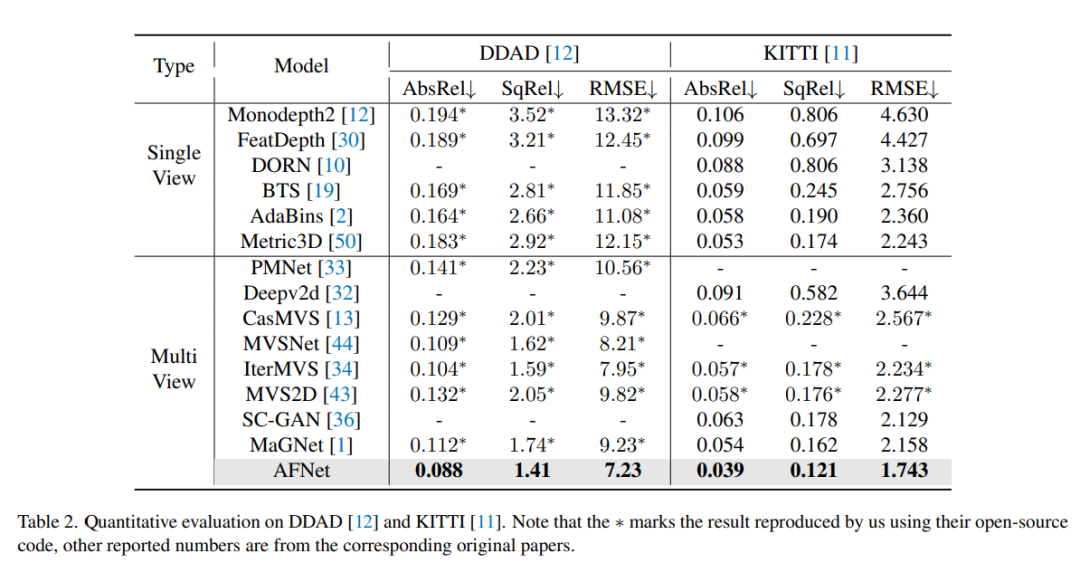
Vergleich der Bewertungsergebnisse zu DDAD und KITTI. Beachten Sie, dass * Ergebnisse kennzeichnet, die mit ihrem Open-Source-Code repliziert wurden, andere gemeldete Zahlen stammen aus den entsprechenden Originalarbeiten.
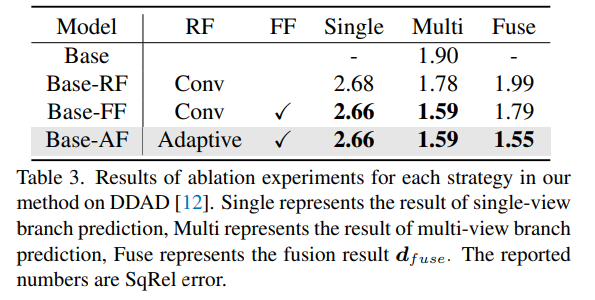
Ablationsexperimentelle Ergebnisse für jede Strategie in der Methode auf DDAD. Single stellt das Ergebnis der Einzelansicht-Zweigvorhersage dar, Multi- stellt das Ergebnis der Mehransicht-Zweigvorhersage dar und Fuse repräsentiert das Fusionsergebnis dfuse.
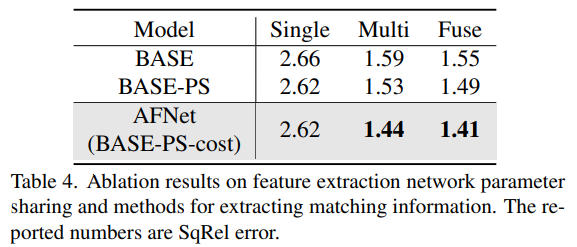
Eine Methode zum Teilen von Netzwerkparametern und zum Extrahieren passender Informationen für die Merkmalsextraktion von Ablationsergebnissen.
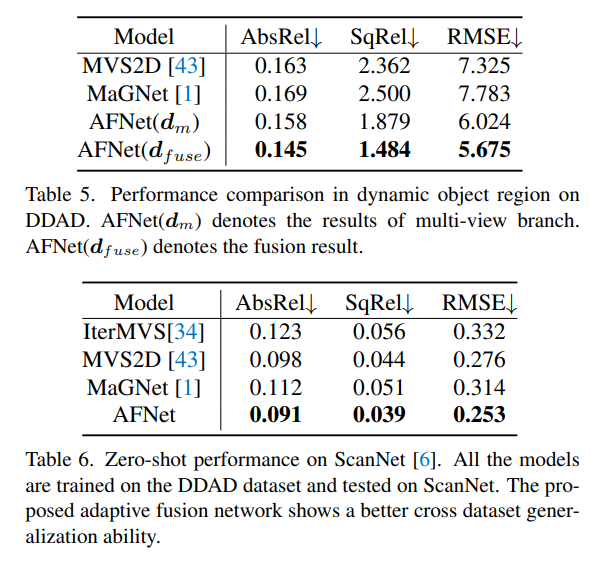

Das obige ist der detaillierte Inhalt vonTiefenschätzung SOTA! Adaptive Fusion von Monokular- und Surround-Tiefe für autonomes Fahren. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Was beinhaltet ein Computersoftwaresystem?
- Was sind die Merkmale des Systems?
- Umfassende Interpretation der Technologie zur Bewertung von Sicherheitsrisiken in Unternehmensnetzwerken
- Wie verwende ich Parallelitätstesttools in Java, um die Parallelitätsfähigkeiten eines Systems zu bewerten?
- Methoden und Leitprinzipien für die PHP-Sicherheitsbewertung