
Heim >Technologie-Peripheriegeräte >KI >WorldGPT ist da: Erstellen Sie einen Sora-ähnlichen Video-KI-Agenten, der Grafiken und Texte „wiederbeleben' kann
WorldGPT ist da: Erstellen Sie einen Sora-ähnlichen Video-KI-Agenten, der Grafiken und Texte „wiederbeleben' kann

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2024-03-22 08:30:441443Durchsuche
Sora von OpenAI feierte im Februar dieses Jahres ein atemberaubendes Debüt und brachte einen neuen Durchbruch bei textgenerierten Videos. Es kann auf der Grundlage von Texteingaben erstaunlich realistische und fantasievolle Videos erstellen, die aussehen, als kämen sie aus Hollywood. Viele Menschen staunten über diese Innovation und glauben, dass die Leistung von OpenAI den Höhepunkt erreicht hat.
Der von Sora verursachte Hype hält ungebrochen an. Gleichzeitig haben Forscher begonnen, das enorme Potenzial der KI-Videogenerierungstechnologie zu erkennen, und dieser Bereich erregt immer mehr Aufmerksamkeit.
Im aktuellen Bereich der KI-Videogenerierung konzentrieren sich die meisten Algorithmenforschungen jedoch auf die Generierung von Videos durch Texteingaben, insbesondere auf Szenarien, in denen Bilder und Text kombiniert werden, und wurden noch nicht ausführlich diskutiert oder umfassend angewendet. Diese Voreingenommenheit verringert die Vielfalt und Kontrollierbarkeit der generierten Videos und schränkt die Möglichkeit ein, statische Bilder in dynamische Videos umzuwandeln.
Andererseits fehlt den meisten bestehenden Videogenerierungsmodellen die Unterstützung für die Bearbeitung generierter Videoinhalte und sie können den Bedarf der Benutzer an personalisierten Anpassungen an generierten Videos nicht erfüllen.


Tipps: Verwandle den Panda in einen Bären und lass ihn tanzen. (Verwandeln Sie den Panda in einen Bären und lassen Sie ihn tanzen.)
In diesem Artikel haben Forscher von SEEKING AI, der Harvard University, der Stanford University und der Peking University gemeinsam ein innovatives einheitliches Framework für die Bild-Text-basierte Videogenerierung und -bearbeitung vorgeschlagen. mit dem Namen WorldGPT. Dieses Framework basiert auf dem von SEEKING AI und den oben genannten Top-Universitäten gemeinsam entwickelten VisionGPT-Framework. Es kann nicht nur die Funktion der direkten Generierung von Videos aus Bildern und Texten realisieren, sondern auch die Stilübertragung und den Hintergrundaustausch der generierten Videos unterstützen einfache Textaufforderungen (Eingabeaufforderung) und eine Reihe von Bearbeitungsvorgängen für das Erscheinungsbild von Videos.
Ein weiterer wesentlicher Vorteil dieses Frameworks besteht darin, dass keine Schulung erforderlich ist, was die technische Hürde erheblich senkt und außerdem die Bereitstellung und Verwendung sehr komfortabel macht. Benutzer können das Modell direkt zum Erstellen verwenden, ohne auf den mühsamen Trainingsprozess dahinter achten zu müssen.

- Papieradresse: https://arxiv.org/pdf/2403.07944.pdf
- Papiertitel: WorldGPT: A Sora-Inspired Video AI Agent as Rich World Models from Text and Image Inputs
Next Let's Schauen Sie sich die Beispieldemonstrationen von WorldGPT in verschiedenen komplexen Steuerungsszenarien für die Videogenerierung an.
Hintergrundaustausch + Video erstellen
Eingabeaufforderung: „Eine Flotte von Schiffen drängte durch den heulenden Sturm, ihre Segel segelten auf den riesigen Wellen des rücksichtslosen Sturms, ihre Segel blähten sich, als sie durch die gewaltigen Wellen des Sturms navigierten unerbittlicher Sturm.)》


Hintergrundersetzung + Stilisierung + Video generieren
Eingabeaufforderung: „Ein süßer Drache auf den Straßen der Stadt, der Feuer spuckt. (Ein süßer Drache spuckt Feuer auf einer städtischen Straße.)“ "


Objektaustausch + Hintergrundaustausch + Video generieren
Tipps: „Ein von Neonlichtern beleuchteter Roboter im Cyberpunk-Stil. Ein Automat im Cyberpunk-Stil raste durch die neonbeleuchtete, dystopische Stadtlandschaft, Reflexionen von Hoch aufragende Hologramme und digitaler Verfall, der auf seinen schlanken Metallkörper projiziert wird.)》


Wie aus dem obigen Beispiel ersichtlich ist, bietet WorldGPT die folgenden Vorteile, wenn es mit komplexen Videos konfrontiert wird Generierungsanweisungen:
1) Es behält die ursprüngliche Eingabestruktur und Umgebung des Bildes besser bei
2) Generiert ein generiertes Video, das der Bildtextbeschreibung entspricht und leistungsstarke Anpassungsmöglichkeiten für die Videogenerierung bietet; Das generierte Video kann per Eingabeaufforderung angepasst und bearbeitet werden.
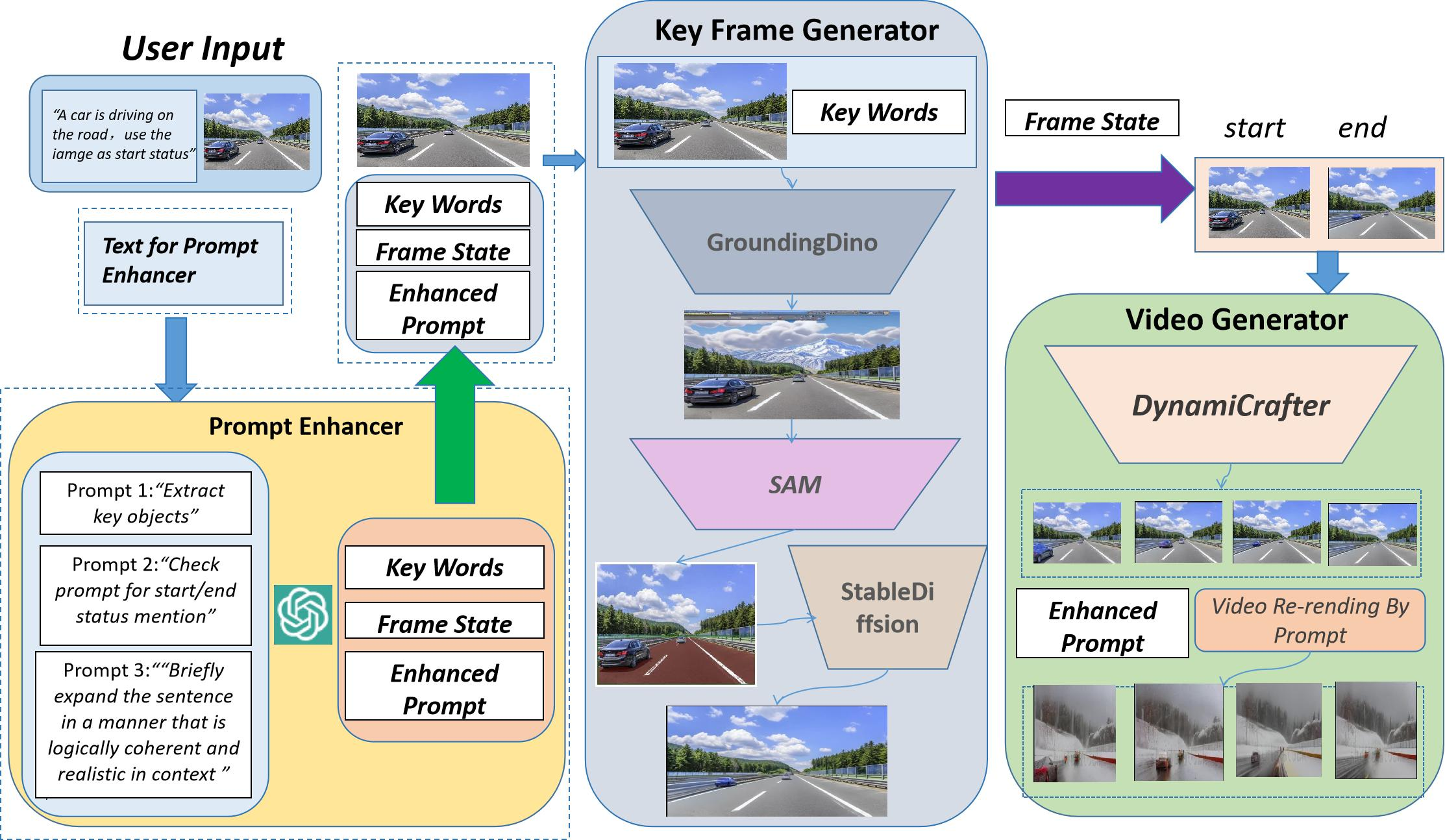
Um mehr über die Prinzipien, Experimente und Anwendungsfälle von WorldGPT zu erfahren, sehen Sie sich bitte das Originalpapier an.
VisonGPT
Wie bereits erwähnt, basiert das WorldGPT-Framework auf dem VisionGPT-Framework. Als nächstes stellen wir kurz Informationen zu VisionGPT vor.
VisionGPT wurde gemeinsam von SeekingAI, der Stanford University, der Harvard University, der Peking University und anderen weltweit führenden Institutionen entwickelt. Es handelt sich um ein bahnbrechendes Open-World-Framework für visuelle Wahrnehmungen. Das Framework bietet leistungsstarke multimodale KI-Bildverarbeitungsfunktionen durch intelligente Integration und Entscheidungsauswahl modernster SOTA-Großmodelle.
Die Innovation von VisionGPT spiegelt sich hauptsächlich in drei Aspekten wider:
- Erstens nimmt es ein großes Sprachmodell (wie LLaMA-2) als Kern, zerlegt die Eingabeaufforderung des Benutzers in detaillierte Schrittanforderungen und ruft automatisch die meisten auf geeignete große Modelle werden verarbeitet;
- Zweitens akzeptiert und fusioniert VisionGPT automatisch multimodale Ausgaben, die von mehreren SOTA-Großmodellen generiert werden, um Bildverarbeitungsergebnisse zu generieren, die auf die Benutzeranforderungen zugeschnitten sind.
- Schließlich verfügt VisionGPT über eine extrem hohe Flexibilität und Vielseitigkeit, ohne dass dies erforderlich ist Damit Benutzer das Modell verfeinern können, kann eine breite Palette von Anwendungsszenarien unterstützt werden, einschließlich textgesteuertem Bildverständnis, -generierung und -bearbeitung.

- Papieradresse: https://arxiv.org/pdf/2403.09027.pdf
- Papiertitel: VisionGPT: Vision-Language Understanding Agent Using Generalized Multimodal Framework
VisionGPT-Anwendungsfall

Wie oben zu sehen ist, kann VisionGPT problemlos 1) Instanzsegmentierung in der offenen Welt ohne Feinabstimmung erreichen; 2) aufforderungsbasierte Bildgenerierungs- und Bearbeitungsfunktionen usw. Der Workflow von VisionGPT ist in der folgenden Abbildung dargestellt.
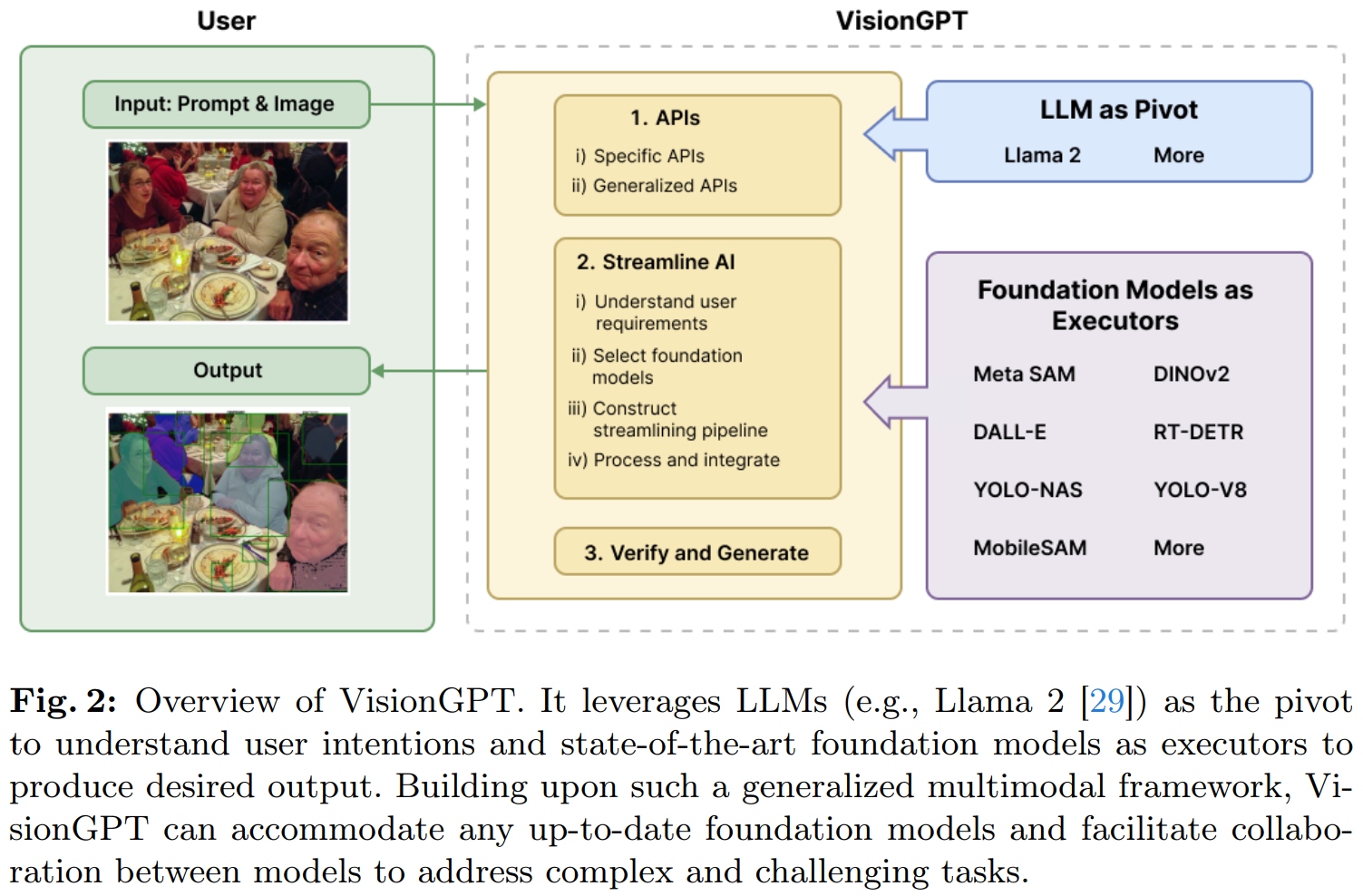
Weitere Einzelheiten finden Sie im Papier.
VisionGPT-3D
Darüber hinaus haben Forscher auch VisionGPT-3D ins Leben gerufen, das darauf abzielt, eine große Herausforderung bei der Umwandlung von Text in visuelle Elemente zu lösen: wie man 2D-Bilder effizient und genau in 3D-Darstellungen umwandelt. Bei diesem Prozess stehen wir häufig vor dem Problem, dass der Algorithmus nicht mit den tatsächlichen Anforderungen übereinstimmt und dadurch die Qualität des Endergebnisses beeinträchtigt wird. VisionGPT-3D schlägt ein multimodales Framework vor, das diesen Konvertierungsprozess durch die Integration mehrerer hochmoderner SOTA-Vision-Großmodelle optimiert. Die Kerninnovation liegt in der Fähigkeit, automatisch das am besten geeignete visuelle SOTA-Modell und den Algorithmus zur Erstellung von 3D-Punktwolken auszuwählen und auf der Grundlage multimodaler Eingaben wie Textaufforderungen eine Ausgabe zu generieren, die den Benutzeranforderungen am besten entspricht.

- Papieradresse: https://arxiv.org/pdf/2403.09530v1.pdf
- Papiertitel: VisionGPT-3D: A Generalized Multimodal Agent for Enhanced 3D Vision Understanding
Weitere Informationen finden Sie unter zum Originalpapier.
Das obige ist der detaillierte Inhalt vonWorldGPT ist da: Erstellen Sie einen Sora-ähnlichen Video-KI-Agenten, der Grafiken und Texte „wiederbeleben' kann. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- h5-Tutorial zum Selbststudium: 6 empfohlene nullbasierte HTML5-Tutorials zum Selbststudium, die für Anfänger geeignet sind
- Einführungs-Tutorial zur Verwendung des Linux-Systems
- phpstudy v8 Schnellstart-Tutorial
- Erste Schritte: Sehen Sie, wie Sie in PS Verlaufseffekte zu Bildern hinzufügen (Wissensaustausch)
- Die KI-Stabilität hat sich erneut sprunghaft verbessert: erstaunliche Demonstration der neuen Videogeneration, die von den Internetnutzern einhellig anerkannt wird