
Heim >Technologie-Peripheriegeräte >KI >CMU Zhu Junyan und Adobes neue Arbeit: 512 x 512 Bildinferenz, A100 dauert nur 0,11 Sekunden
CMU Zhu Junyan und Adobes neue Arbeit: 512 x 512 Bildinferenz, A100 dauert nur 0,11 Sekunden

- PHPznach vorne
- 2024-03-21 16:31:25902Durchsuche
Eine einfache Skizze kann mit einem Klick in ein Gemälde mit mehreren Stilen umgewandelt und zusätzliche Beschreibungen hinzugefügt werden. Dies wurde in einer gemeinsam von CMU und Adobe gestarteten Studie erreicht.
CMU-Assistenzprofessor Junyan Zhu ist Autor der Studie, und sein Team veröffentlichte eine verwandte Studie auf der ICCV-Konferenz 2021. Diese Studie zeigt, wie ein bestehendes GAN-Modell mit einer oder mehreren handgezeichneten Skizzen angepasst werden kann, um Bilder zu erzeugen, die der Skizze entsprechen.

- Papieradresse: https://arxiv.org/pdf/2403.12036.pdf
- GitHub-Adresse: https://github.com/GaParmar/img2img-turbo
- Probeadresse: https://huggingface.co/spaces/gparmar/img2img-turbo-sketch
- Papiertitel: One-Step Image Translation with Text-to-Image Models
Wie ist die Wirkung? Wir haben es ausprobiert und sind zu dem Schluss gekommen, dass es sehr gut spielbar ist. Die ausgegebenen Bildstile sind vielfältig, darunter Filmstil, 3D-Modelle, Animation, digitale Kunst, Fotografiestil, Pixelkunst, Fantasy-Schule, Neon-Punk und Comics.
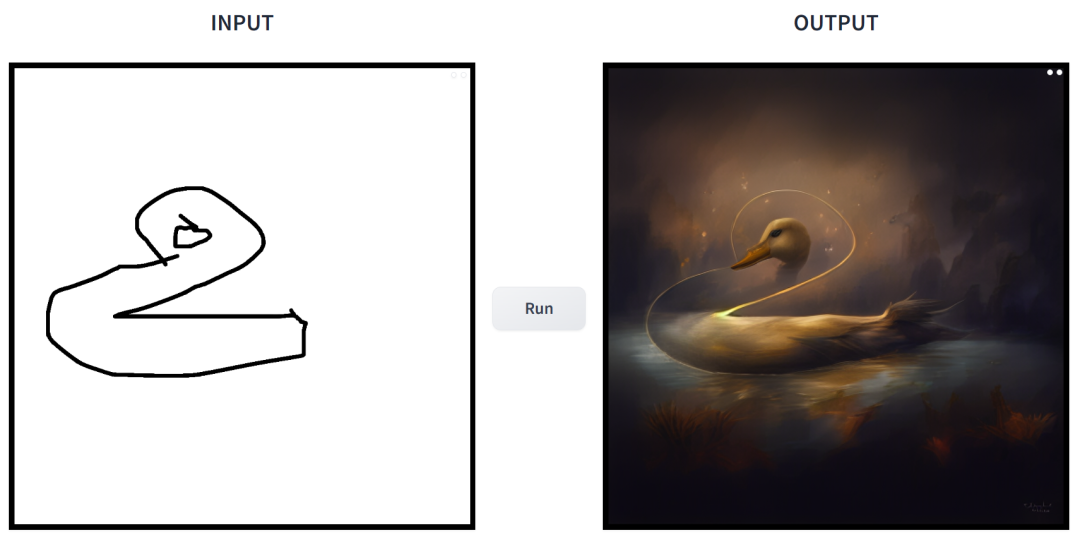
Eingabeaufforderung ist „Ente“.
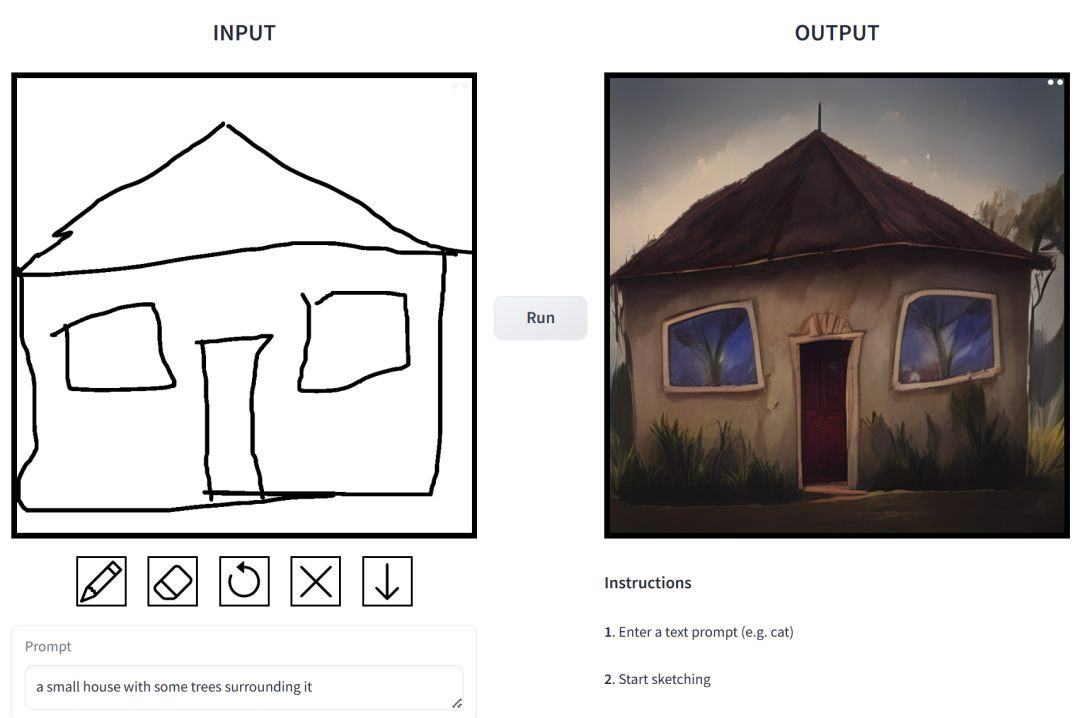
prompt ist „ein kleines Haus, umgeben von Vegetation“.
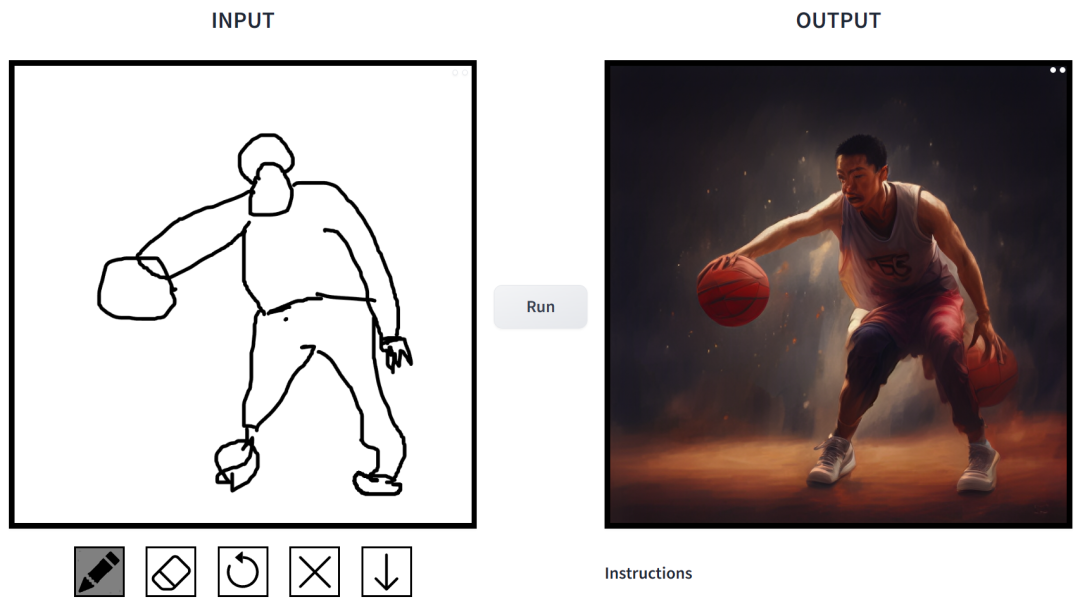
Eingabeaufforderung ist „Chinesische Jungs spielen Basketball“.
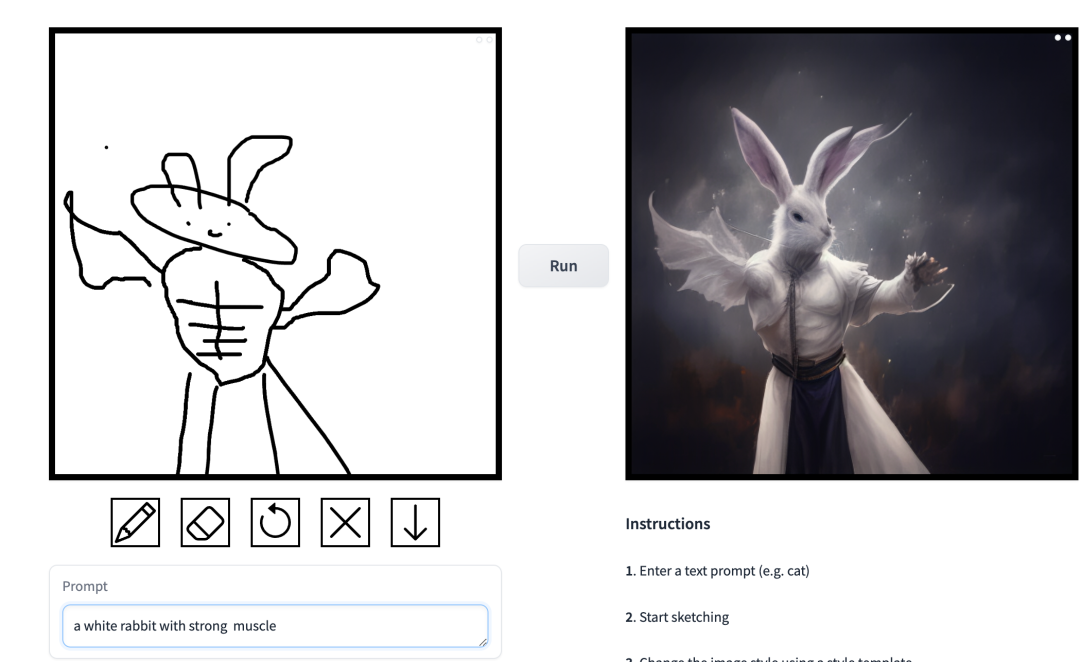
prompt ist „Muscle Man Rabbit“. In dieser Arbeit verbesserten die Forscher gezielt die Probleme des bedingten Diffusionsmodells in Bildsyntheseanwendungen. Mit solchen Modellen können Benutzer Bilder basierend auf räumlichen Bedingungen und Textaufforderungen erstellen und das Szenenlayout, Benutzerskizzen und menschliche Posen präzise steuern.
Aber das Problem besteht darin, dass die Iteration des Diffusionsmodells zu einer Verlangsamung der Inferenzgeschwindigkeit führt, was Echtzeitanwendungen wie interaktives Sketch2Photo einschränkt. Darüber hinaus erfordert das Modelltraining in der Regel große gepaarte Datensätze, was für viele Anwendungen enorme Kosten verursacht und für einige andere Anwendungen nicht durchführbar ist. 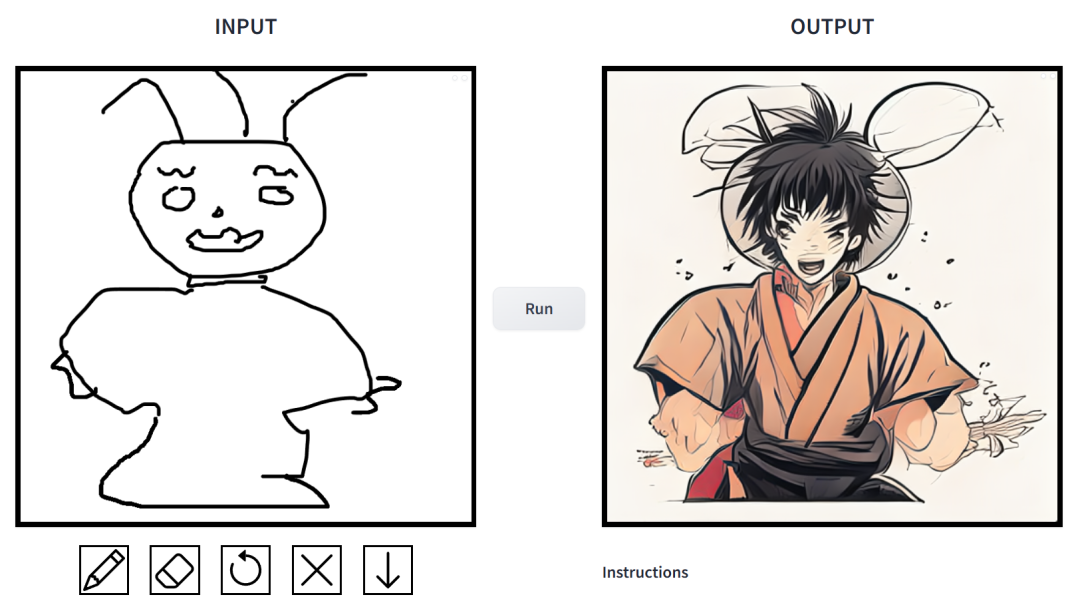
Um die Probleme des bedingten Diffusionsmodells zu lösen, haben Forscher eine allgemeine Methode eingeführt, die kontradiktorische Lernziele verwendet, um das einstufige Diffusionsmodell an neue Aufgaben und neue Bereiche anzupassen. Insbesondere integrieren sie einzelne Module eines latenten Vanilla-Diffusionsmodells in ein einziges End-to-End-Generatornetzwerk mit kleinen trainierbaren Gewichten und verbessern so die Fähigkeit des Modells, die Struktur des Eingabebildes beizubehalten und gleichzeitig eine Überanpassung zu reduzieren.
Forscher haben das CycleGAN-Turbo-Modell auf den Markt gebracht, das in einer ungepaarten Umgebung bestehende GAN- und diffusionsbasierte Methoden bei verschiedenen Szenenkonvertierungsaufgaben, wie z. B. Tag- und Nachtkonvertierung, Hinzufügen oder Entfernen von Nebel, Schnee, Regen und anderen Wetterbedingungen, übertreffen kann Auswirkungen. 
Gleichzeitig führten die Forscher Experimente in gepaarten Umgebungen durch, um die Vielseitigkeit ihrer eigenen Architektur zu überprüfen. Die Ergebnisse zeigen, dass ihr Modell pix2pix-Turbo visuelle Effekte erzielt, die mit Edge2Image und Sketch2Photo vergleichbar sind, und den Inferenzschritt auf einen Schritt reduziert.
Zusammenfassend zeigt diese Arbeit, dass in einem Schritt vorab trainierte Text-zu-Bild-Modelle als leistungsstarkes, vielseitiges Rückgrat für viele nachgelagerte Bildgenerierungsaufgaben dienen können.
Einführung in die Methode
Diese Studie schlägt eine allgemeine Methode vor, um einstufige Diffusionsmodelle (wie SD-Turbo) durch kontradiktorisches Lernen an neue Aufgaben und Domänen anzupassen. Dies nutzt das interne Wissen des vorab trainierten Diffusionsmodells und ermöglicht gleichzeitig eine effiziente Inferenz (z. B. 0,29 Sekunden auf A6000 und 0,11 Sekunden auf A100 für ein 512x512-Bild).
Darüber hinaus können die einstufigen bedingten Modelle CycleGAN-Turbo und pix2pix-Turbo eine Vielzahl von Bild-zu-Bild-Übersetzungsaufgaben ausführen, die sowohl für paarweise als auch für nicht paarweise Einstellungen geeignet sind. CycleGAN-Turbo übertrifft bestehende GAN-basierte und diffusionsbasierte Methoden, während pix2pix-Turbo neueren Arbeiten wie ControlNet für Sketch2Photo und Edge2Image ebenbürtig ist, jedoch den Vorteil der einstufigen Inferenz bietet.
Bedingte Eingabe hinzufügen
Um ein Text-zu-Bild-Modell in ein Bild-zu-Bild-Modell umzuwandeln, muss zunächst eine effiziente Möglichkeit gefunden werden, das Eingabebild x einzubinden in das Modell ein.
Eine gängige Strategie zur Integration bedingter Eingaben in Diffusionsmodelle besteht darin, zusätzliche Adapterzweige einzuführen, wie in Abbildung 3 dargestellt.
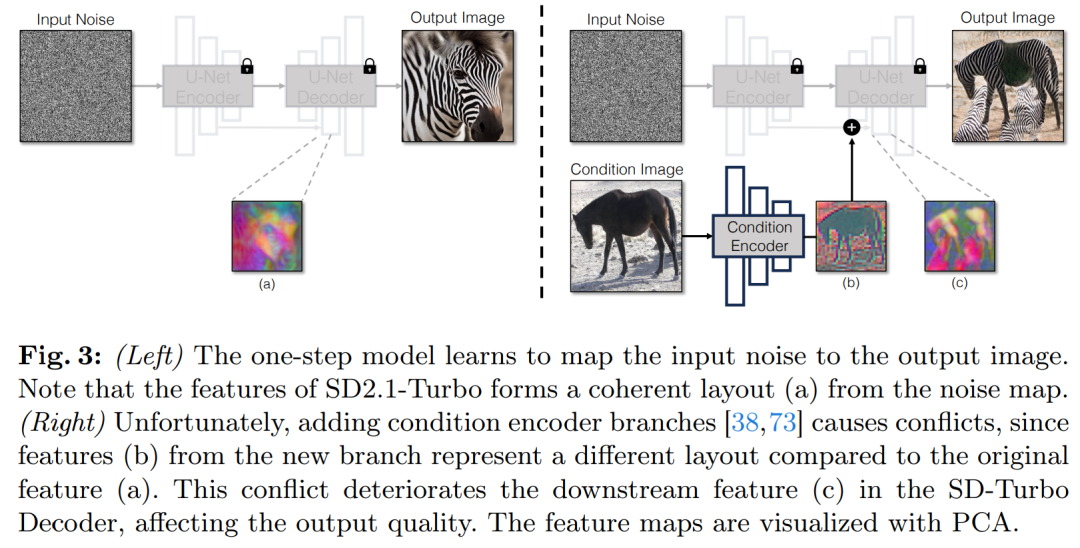
Konkret initialisiert diese Studie den zweiten Encoder und bezeichnet ihn als Bedingungsencoder. Der Control Encoder akzeptiert das Eingabebild x und gibt Feature-Maps mit mehreren Auflösungen über Restverbindungen an das vorab trainierte Stable Diffusion-Modell aus. Diese Methode erzielt bemerkenswerte Ergebnisse bei der Steuerung von Diffusionsmodellen.
Wie in Abbildung 3 dargestellt, verwendet diese Studie zwei Encoder (U-Net-Encoder und bedingter Encoder) in einem einstufigen Modell, um die Herausforderungen durch verrauschte Bilder und Eingabebilder zu bewältigen. Im Gegensatz zu mehrstufigen Diffusionsmodellen steuert die Rauschkarte in einstufigen Modellen direkt das Layout und die Pose des generierten Bildes, was häufig im Widerspruch zur Struktur des Eingabebilds steht. Daher erhält der Decoder zwei Sätze von Restmerkmalen, die unterschiedliche Strukturen darstellen, was den Trainingsprozess anspruchsvoller macht.
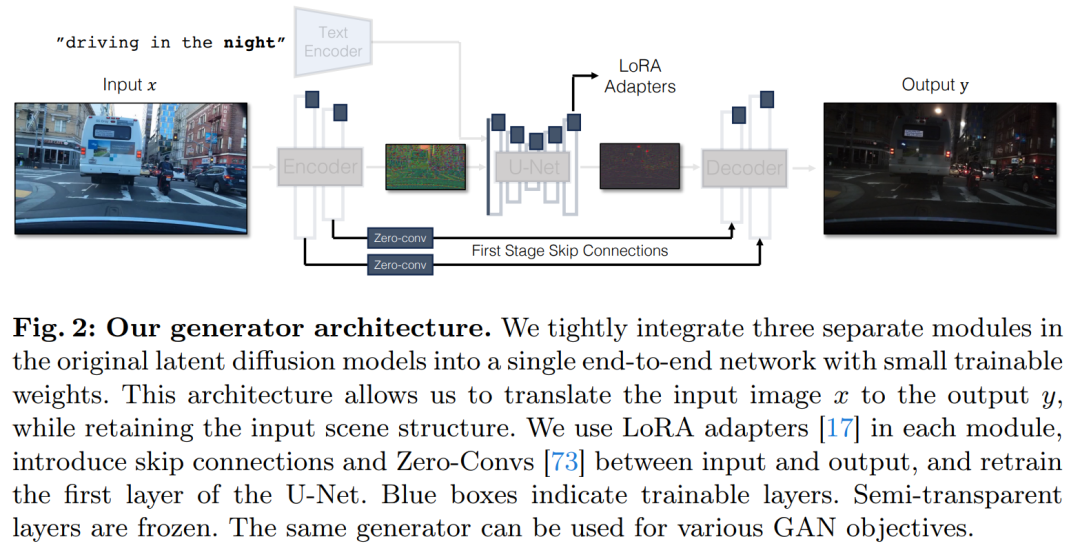
Direkte bedingte Eingabe. Abbildung 3 zeigt auch, dass die vom vorab trainierten Modell erzeugte Bildstruktur erheblich von der Rauschkarte z beeinflusst wird. Basierend auf dieser Erkenntnis empfiehlt die Studie, bedingte Eingaben direkt in das Netzwerk einzuspeisen. Um das Backbone-Modell an neue Bedingungen anzupassen, fügte die Studie verschiedenen Schichten von U-Net mehrere LoRA-Gewichte hinzu (siehe Abbildung 2).
Eingabedetails beibehalten
Der Bildencoder für Latent Diffusion Models (LDMs) beschleunigt das Training von Diffusionsmodellen, indem er die räumliche Auflösung des Eingabebilds um den Faktor 8 komprimiert und gleichzeitig die Anzahl der Kanäle erhöht 3 bis 4. Argumentationsprozess. Obwohl dieses Design das Training und die Inferenz beschleunigen kann, ist es möglicherweise nicht ideal für Bildtransformationsaufgaben, bei denen die Details des Eingabebilds erhalten bleiben müssen. Abbildung 4 veranschaulicht dieses Problem, indem wir ein Eingabebild des Fahrens bei Tag (links) aufnehmen und es in ein entsprechendes Bild des Fahrens bei Nacht umwandeln, wobei wir eine Architektur verwenden, die keine Sprungverbindungen verwendet (Mitte). Es ist zu beobachten, dass feinkörnige Details wie Texte, Straßenschilder und entfernte Autos nicht erhalten bleiben. Im Gegensatz dazu gelingt es dem resultierenden transformierten Bild, das eine Architektur mit übersprungenen Verbindungen (rechts) verwendet, diese komplexen Details besser zu bewahren.

Um die feinkörnigen visuellen Details des Eingabebildes zu erfassen, wurden in der Studie Sprungverbindungen zwischen den Encoder- und Decodernetzwerken hinzugefügt (siehe Abbildung 2). Konkret extrahiert die Studie vier Zwischenaktivierungen nach jedem Downsampling-Block im Encoder, verarbeitet sie durch eine 1 × 1-Null-Faltungsschicht und speist sie dann in den entsprechenden Upsampling-Block im Decoder ein. Dieser Ansatz stellt sicher, dass komplexe Details bei der Bildkonvertierung erhalten bleiben.
Experimente
Diese Studie verglich CycleGAN-Turbo mit früheren GAN-basierten, nicht paarweisen Bildtransformationsmethoden. Aus einer qualitativen Analyse geht aus Abbildung 5 und Abbildung 6 hervor, dass weder die GAN-basierte Methode noch die diffusionsbasierte Methode ein Gleichgewicht zwischen dem Realismus des Ausgabebildes und der Beibehaltung der Struktur erreichen können.


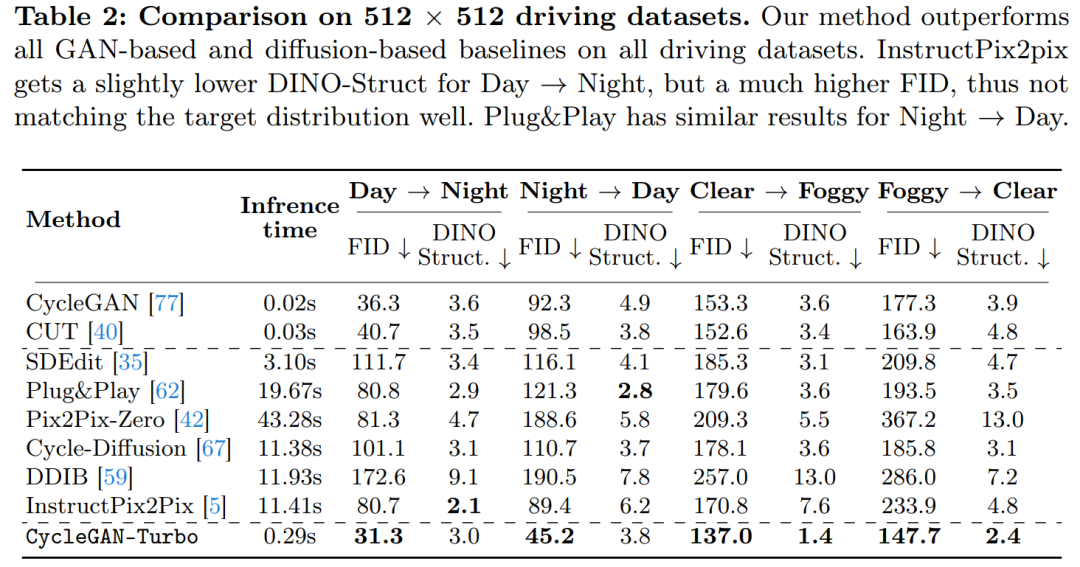
In der Studie wurde auch CycleGAN-Turbo mit CycleGAN und CUT verglichen. In den Tabellen 1 und 2 sind die Ergebnisse quantitativer Vergleiche zu acht ungepaarten Schaltaufgaben dargestellt.
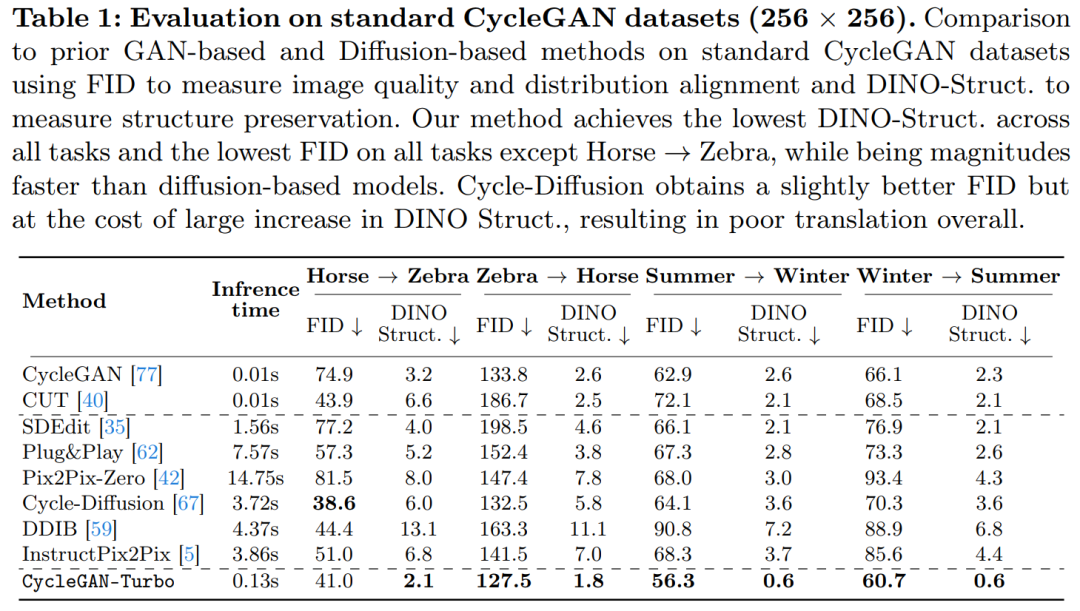
CycleGAN und CUT zeigen eine effektive Leistung bei einfacheren, objektzentrierten Datensätzen wie Pferd → Zebra (Abbildung 13) und erreichen einen niedrigen FID- und DINO-Struktur-Score. Unsere Methode übertrifft diese Methoden bei den FID- und DINO-Struktur-Abstandsmetriken geringfügig.

Wie in Tabelle 1 und Abbildung 14 gezeigt, können diese Methoden bei objektzentrierten Datensätzen (z. B. Pferd → Zebra) realistische Zebras generieren, leiden jedoch unter der Schwierigkeit, genau passende Objektposen herzustellen.
Im Fahrdatensatz schneiden diese Bearbeitungsmethoden aus drei Gründen deutlich schlechter ab: (1) Das Modell hat Schwierigkeiten, komplexe Szenen mit mehreren Objekten zu generieren, (2) Diese Methoden (außer Instruct-pix2pix) müssen zuerst das Bild erstellen in eine Lärmkarte umgewandelt, was zu potenziellem menschlichem Versagen führt, und (3) das vorab trainierte Modell kann keine Straßenansichtsbilder synthetisieren, die denen ähneln, die durch den Fahrdatensatz erfasst werden. Tabelle 2 und Abbildung 16 zeigen, dass diese Methoden bei allen vier Fahrübergangsaufgaben Bilder von schlechter Qualität ausgeben und nicht der Struktur des Eingabebildes folgen.


Das obige ist der detaillierte Inhalt vonCMU Zhu Junyan und Adobes neue Arbeit: 512 x 512 Bildinferenz, A100 dauert nur 0,11 Sekunden. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Eingehendes Studium von HTML5 zur Implementierung der Bildkomprimierungs-Upload-Funktion_html5-Tutorial-Fähigkeiten
- Implementierung von Bildfusion, Additionsoperation und Bildtypkonvertierung in Python (mit Code)
- So brechen Sie die Bildskalierung in PS ab
- Was sind die drei Hauptinhalte der Datenstrukturforschung?
- Was ist die übliche Einheit, um die Auflösung von Bitmap-Bildern auszudrücken?