
Heim >Technologie-Peripheriegeräte >KI >Lightning NeRF wurde für autonomes Fahren entwickelt: 10-mal schneller
Lightning NeRF wurde für autonomes Fahren entwickelt: 10-mal schneller

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2024-03-19 18:19:08871Durchsuche
Oben geschrieben und das persönliche Verständnis des Autors
Neueste Forschungen haben die Anwendungsaussichten von NeRF in autonomen Fahrumgebungen hervorgehoben. Allerdings erschwert die Komplexität von Außenumgebungen in Verbindung mit eingeschränkten Blickwinkeln in Fahrszenen die Aufgabe, die Szenengeometrie genau zu rekonstruieren. Diese Herausforderungen führen häufig zu einer verminderten Rekonstruktionsqualität und längeren Trainings- und Rendering-Dauern. Um diesen Herausforderungen zu begegnen, haben wir Lightning NeRF ins Leben gerufen. Es verwendet eine effiziente Hybridszenendarstellung, die die geometrischen Prioritäten von Lidar in autonomen Fahrszenarien effektiv nutzt. Lightning NeRF verbessert die neuartige Ansichtssyntheseleistung von NeRF erheblich und reduziert den Rechenaufwand. Durch die Auswertung realer Datensätze wie KITTI-360, Argoverse2 und unseres privaten Datensatzes zeigen wir, dass unsere Methode nicht nur den aktuellen Stand der Technik in der Qualität der Synthese neuer Ansichten übertrifft, sondern auch die Trainingsgeschwindigkeit Five verbessert Mal schneller und zehnmal schnelleres Rendern. H-Code-Link: https://gision-sjtu/lightning-insf. Detaillierte Erklärung von Lightning Nerf MLP. Es ist in der Lage, den Farbwert c und die Volumendichtevorhersage σ eines 3D-Punktes x in der Szene basierend auf der Blickrichtung d zurückzugeben.
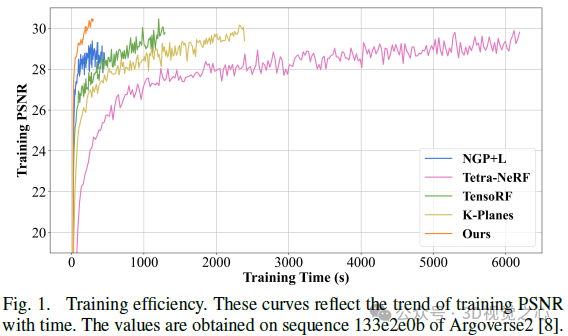
Obwohl NeRF bei der Synthese neuer Perspektiven eine gute Leistung erbringt, sind seine lange Trainingszeit und langsame Rendergeschwindigkeit hauptsächlich auf die Ineffizienz der Sampling-Strategie zurückzuführen. Um die Effizienz des Modells zu verbessern, behalten wir während des Trainings eine grobe Gitterbelegung bei und probieren nur Standorte innerhalb des belegten Volumens aus. Diese Stichprobenstrategie ähnelt bestehenden Arbeiten und trägt dazu bei, die Modellleistung zu verbessern und das Training zu beschleunigen.
Hybride Szenendarstellung
Die hybride Volumendarstellung wurde optimiert und mithilfe kompakter Modelle schnell gerendert. Vor diesem Hintergrund verwenden wir eine Hybrid-Voxel-Gitterdarstellung, um das Strahlungsfeld zu modellieren und die Effizienz zu verbessern. Kurz gesagt modellieren wir die volumetrische Dichte explizit, indem wir σ an den Netzeckpunkten speichern und gleichzeitig ein flaches MLP verwenden, um die Farbeinbettung f implizit in die endgültige Farbe c zu dekodieren. Um der grenzenlosen Natur von Außenumgebungen gerecht zu werden, teilen wir die Szenendarstellung in zwei Teile, Vordergrund und Hintergrund, wie in Abbildung 2 dargestellt. Insbesondere untersuchen wir den Kamerakegelstumpf in jedem Bild aus der Trajektoriensequenz und definieren den Vordergrundbegrenzungsrahmen so, dass er alle Kegelstumpfe im ausgerichteten Koordinatensystem eng umschließt. Das Hintergrundfeld wird durch Skalieren des Vordergrundfelds entlang jeder Dimension erhalten.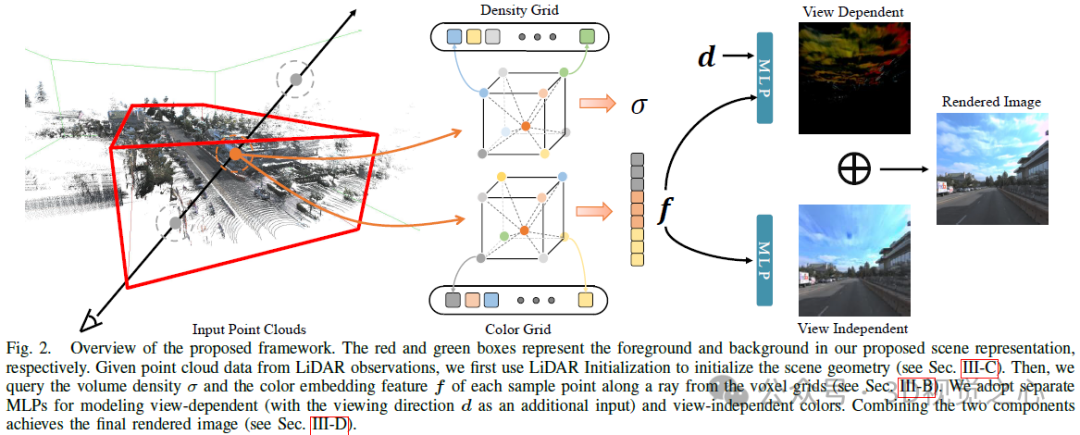
. Eine Voxel-Mesh-Darstellung speichert Szeneneigenschaften (z. B. Dichte, RGB-Farbe oder Features) explizit in ihren Mesh-Scheitelpunkten, um effiziente Feature-Abfragen zu unterstützen. Auf diese Weise können wir für eine gegebene 3D-Position das entsprechende Attribut durch trilineare Interpolation dekodieren:
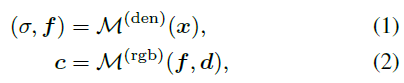
. Wir erstellen zwei unabhängige Feature-Netze, um die Dichte und Farbeinbettung des Vordergrundbereichs zu modellieren. Insbesondere ordnet die Dichtenetzzuordnung Positionen einem Dichteskalar σ für die volumetrische Darstellung zu. Für die farblich eingebettete Netzzuordnung instanziieren wir mehrere Voxelnetze mit unterschiedlichen Auflösungs-Backups über eine Hash-Tabelle, um feinere Details bei erschwinglichem Speicheraufwand zu erhalten. Die endgültige Farbeinbettung f wird durch Verkettung der Ausgaben mit L Auflösungsstufen erhalten. 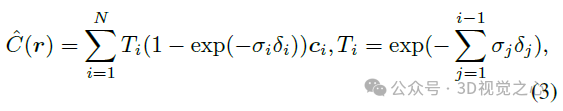
Dazu richten wir ein zusätzliches Hintergrundnetzmodell ein, um die Auflösung des Vordergrundteils konstant zu halten. Als Hintergrund verwenden wir die Szenenparametrisierung in [9], die sorgfältig entworfen wurde. Erstens verwenden wir im Gegensatz zur inversen sphärischen Modellierung die inverse kubische Modellierung mit der ℓ∞-Norm, da wir eine Voxelgitterdarstellung verwenden. Zweitens instanziieren wir kein zusätzliches MLP, um die Hintergrundfarbe abzufragen und so Speicherplatz zu sparen. Konkret verzerren wir 3D-Hintergrundpunkte in 4D durch:
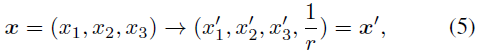
LiDAR-Initialisierung
Bei Verwendung unserer hybriden Szenendarstellung ist es rechenintensiv, wenn wir direkt von einer effizienten Voxelgitterdarstellung ausgehen. Dieses Modell spart Rechenaufwand und Speicher beim MLP fragt Dichtewerte ab. Angesichts der Großräumigkeit und Komplexität städtischer Szenen kann diese leichtgewichtige Darstellung jedoch aufgrund der begrenzten Auflösung des Dichtegitters während der Optimierung leicht in lokalen Minima stecken bleiben. Glücklicherweise sind beim autonomen Fahren die meisten selbstfahrenden Fahrzeuge (SDVs) mit LiDAR-Sensoren ausgestattet, die grobe geometrische Prioritäten für die Szenenrekonstruktion liefern. Zu diesem Zweck schlagen wir vor, Lidar-Punktwolken zu verwenden, um unser Dichtenetz zu initialisieren und die Hindernisse einer gemeinsamen Optimierung von Szenengeometrie und Radioaktivität zu beseitigen.
Farbzerlegung
Das ursprüngliche NeRF verwendete ein ansichtsabhängiges MLP, um die Farbe im Strahlungsfeld zu modellieren, eine Vereinfachung der physischen Welt, in der Strahlung aus diffuser (ansichtsunabhängiger) Farbe und spiegelnder (ansichtsbezogener) Farbe besteht Komposition. Da außerdem die endgültige Ausgabefarbe c vollständig mit der Blickrichtung d verknüpft ist, ist es schwierig, hochauflösende Bilder in unsichtbaren Ansichten wiederzugeben. Wie in Abbildung 3 dargestellt, schlägt unsere Methode, die ohne Farbzerlegung (CD) trainiert wurde, bei der Synthese neuer Ansichten in der Extrapolationseinstellung fehl (d. h. beim Verschieben der Blickrichtung um 2 Meter nach links basierend auf der Trainingsansicht), während unsere Methode in Farbe zerlegt wurde case liefert vernünftige Rendering-Ergebnisse.

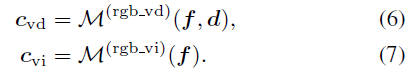
Die endgültige Farbe am abgetasteten Ort ist die Summe dieser beiden Faktoren:

Trainingsverlust
Wir modifizieren den photometrischen Verlust mithilfe neu skalierter Gewichte, um unser Modell zu optimieren. Machen Sie es Konzentrieren Sie sich auf harte Proben, um eine schnelle Konvergenz zu erreichen. Der Gewichtskoeffizient ist definiert als:

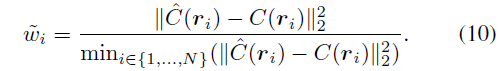
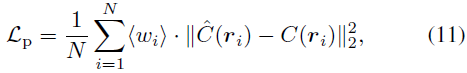 Bild
Bild
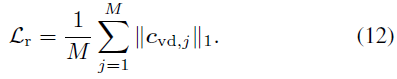

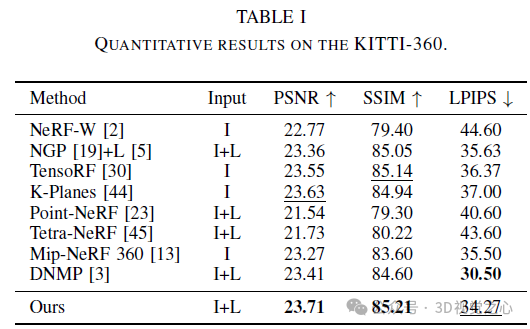
Experiment
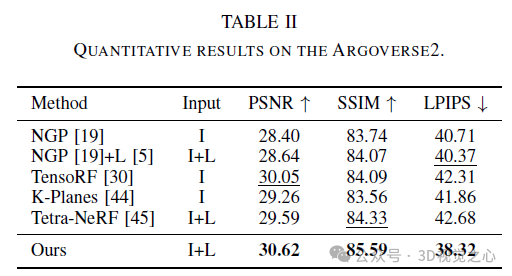
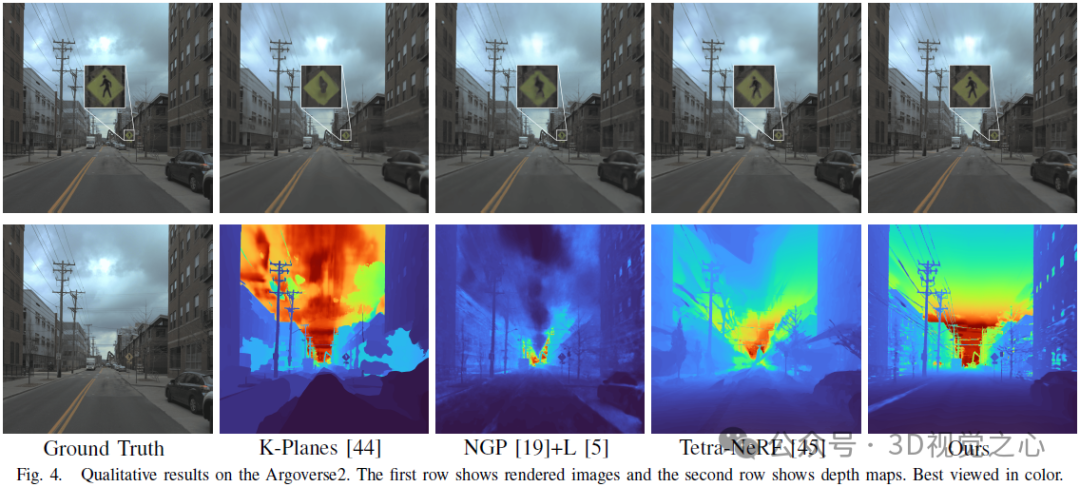
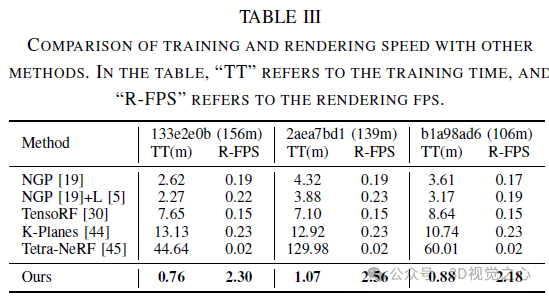
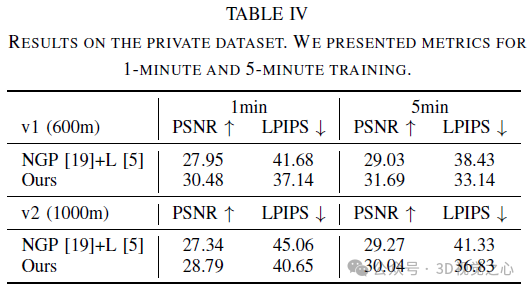

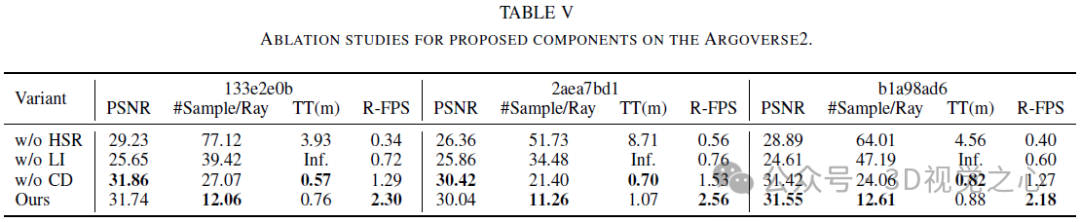
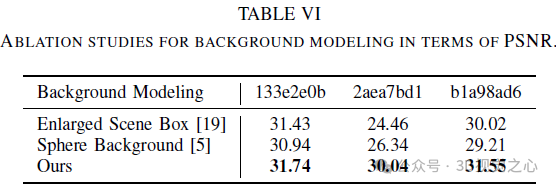
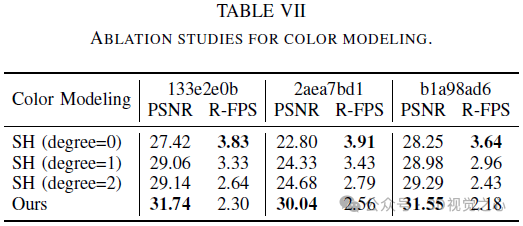
Fazit
In diesem Artikel wird Lightning NeRF vorgestellt, ein effizientes Synthese-Framework für Szenenansichten im Freien, das Punktwolken und Bilder integriert. Die vorgeschlagene Methode nutzt Punktwolken, um schnell eine spärliche Darstellung der Szene zu initialisieren und so erhebliche Leistungs- und Geschwindigkeitsverbesserungen zu erzielen. Indem wir den Hintergrund effizienter modellieren, reduzieren wir die Darstellungsbelastung im Vordergrund. Schließlich werden durch Farbzerlegung ansichtsbezogene und ansichtsunabhängige Farben separat modelliert, was die Extrapolationsfähigkeit des Modells verbessert. Umfangreiche Experimente mit verschiedenen Datensätzen zum autonomen Fahren zeigen, dass unsere Methode bisherige State-of-the-Art-Techniken in Bezug auf Leistung und Effizienz übertrifft.
Das obige ist der detaillierte Inhalt vonLightning NeRF wurde für autonomes Fahren entwickelt: 10-mal schneller. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Von der Science-Fiction bis zur Realität: Vor welchen Problemen steht die Entwicklung des autonomen Fahrens noch?
- Huawei Cloud und eine Reihe von Unternehmen haben eine Aktionsinitiative gestartet: Gemeinsam ein offenes industrielles Ökosystem für autonomes Fahren aufbauen
- Tesla nutzt künstliche Intelligenz, um das autonome Fahren zu verbessern
- Waymo und Uber gestalten ihre Partnerschaft neu, um gemeinsam die Anwendung autonomer Fahrtechnologie im Bereich Online-Ride-Hailing zu erforschen
- Fengmi Laser TV belegt im Double 11 im sechsten Jahr in Folge den ersten Platz in China in Bezug auf Online-Verkäufe