
Heim >Technologie-Peripheriegeräte >KI >Der neueste Testbericht zur steuerbaren Bilderzeugung! Die Universität für Post und Telekommunikation Peking hat 20 Seiten mit 249 Dokumenten geöffnet, die verschiedene „Bedingungen' im Bereich der Text-zu-Bild-Verbreitung abdecken.
Der neueste Testbericht zur steuerbaren Bilderzeugung! Die Universität für Post und Telekommunikation Peking hat 20 Seiten mit 249 Dokumenten geöffnet, die verschiedene „Bedingungen' im Bereich der Text-zu-Bild-Verbreitung abdecken.

- 王林nach vorne
- 2024-03-19 17:00:04656Durchsuche
Im Prozess der schnellen Entwicklung im Bereich der visuellen Generierung hat das Diffusionsmodell den Entwicklungstrend in diesem Bereich völlig verändert, und die Einführung der textgesteuerten Generierungsfunktion markiert eine tiefgreifende Änderung der Fähigkeiten.
Wenn man sich jedoch ausschließlich auf Text zur Regulierung dieser Modelle verlässt, kann man die vielfältigen und komplexen Anforderungen verschiedener Anwendungen und Szenarien nicht vollständig erfüllen.
Angesichts dieses Mangels zielen viele Studien darauf ab, vorab trainierte Text-to-Image-Modelle (T2I) zu steuern, um neue Bedingungen zu unterstützen.
Forscher der Universität für Post und Telekommunikation Peking führten eine eingehende Untersuchung der steuerbaren Erzeugung von T2I-Diffusionsmodellen durch und skizzierten die theoretischen Grundlagen und praktischen Fortschritte auf diesem Gebiet. Diese Übersicht deckt die neuesten Forschungsergebnisse ab und bietet eine wichtige Referenz für die Entwicklung und Anwendung dieses Fachgebiets.

Papier: https://arxiv.org/abs/2403.04279 Code: https://github.com/PRIV-Creation/Awesome-Controllable-T2I-Diffusion-Models
Unsere Rezension beginnt mit a Kurzbeschreibung Beginnt mit der Einführung in die Grundlagen der Denoised Diffusion Probabilistic Models (DDPMs) und des weit verbreiteten T2I-Diffusionsmodells.
Wir haben den Kontrollmechanismus des Diffusionsmodells weiter untersucht und durch theoretische Analyse die Wirksamkeit der Einführung neuer Bedingungen in den Entrauschungsprozess ermittelt.
Darüber hinaus haben wir die Forschung in diesem Bereich detailliert zusammengefasst und aus Sicht der Bedingungen in verschiedene Kategorien unterteilt, z. B. die Generierung spezifischer Bedingungen, die Generierung mehrerer Bedingungen und die Generierung allgemeiner Steuerbarkeit.
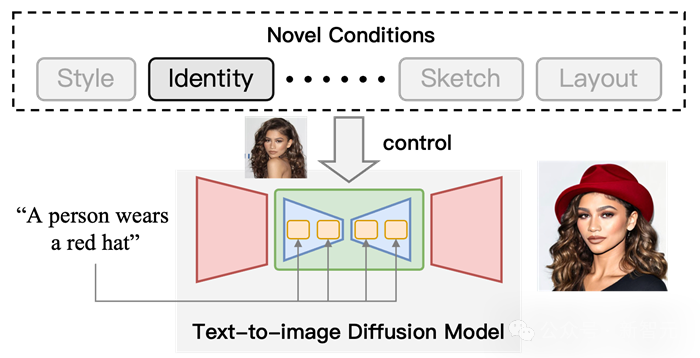
Abbildung 1 Schematische Darstellung der steuerbaren Erzeugung mithilfe des T2I-Diffusionsmodells. Fügen Sie auf der Grundlage von Textbedingungen „Identitäts“-Bedingungen hinzu, um die Ausgabeergebnisse zu steuern.
Klassifizierungssystem
Die Aufgabe der bedingten Generierung mithilfe von Textdiffusionsmodellen stellt ein vielschichtiges und komplexes Feld dar. Aus bedingter Sicht unterteilen wir diese Aufgabe in drei Teilaufgaben (siehe Abbildung 2).
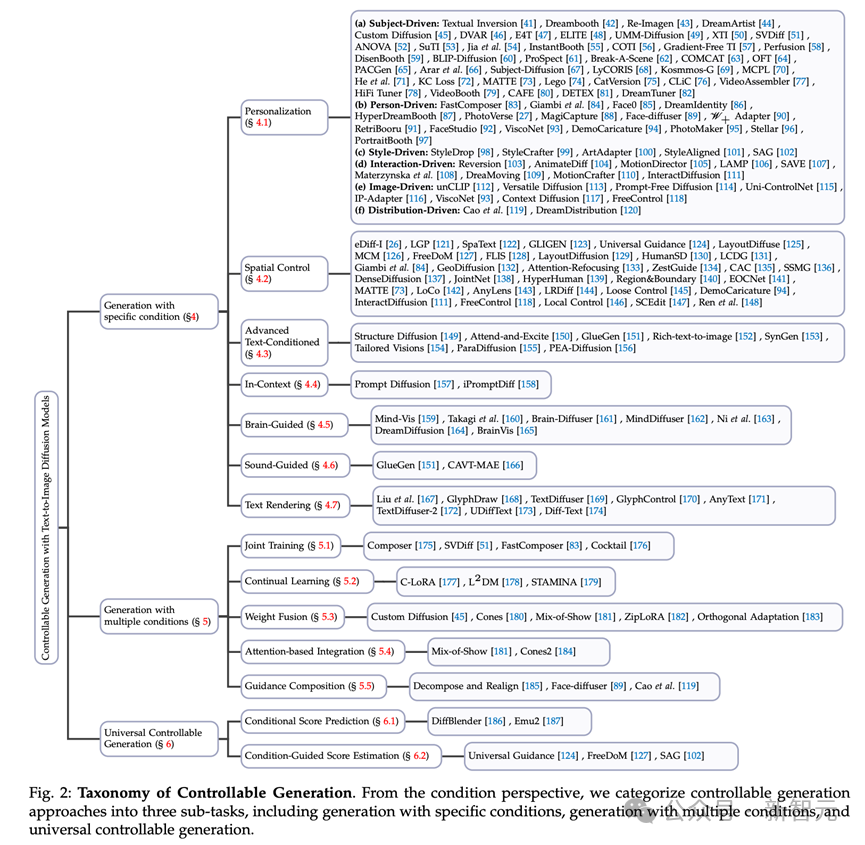
Abbildung 2 Klassifizierung der steuerbaren Erzeugung. Aus der Bedingungsperspektive unterteilen wir die steuerbare Generierungsmethode in drei Unteraufgaben, darunter die Generierung mit bestimmten Bedingungen, die Generierung mit mehreren Bedingungen und die allgemein steuerbare Generierung.
Die meisten Forschungsarbeiten widmen sich der Frage, wie Bilder unter bestimmten Bedingungen generiert werden können, beispielsweise bei der bildgesteuerten Generierung und der Skizze-zu-Bild-Generierung.
Um die Theorie und Eigenschaften dieser Methoden aufzuzeigen, klassifizieren wir sie weiter nach ihren Krankheitstypen.
1. Generieren unter Verwendung spezifischer Bedingungen: bezieht sich auf Methoden, die bestimmte Arten von Bedingungen einführen, einschließlich benutzerdefinierter Bedingungen (Personalisierung, z. B. DreamBooth, Textual Inversion) und direkterer Bedingungen, wie z. B. der ControlNet-Serie, Physiologisch Signal-zu-Bild
2. Generierung mehrerer Bedingungen: Unter Verwendung mehrerer Bedingungen zur Generierung unterteilen wir diese Aufgabe aus technischer Sicht.
3. Einheitliche steuerbare Generierung: Diese Aufgabe ist so konzipiert, dass sie unter Verwendung beliebiger Bedingungen (sogar einer beliebigen Anzahl) generieren kann.
So führen Sie neue Bedingungen in das T2I-Diffusionsmodell ein
Einzelheiten finden Sie im Originalpapier. Die Mechanismen dieser Methoden werden im Folgenden kurz vorgestellt.
Bedingte Score-Vorhersage
Im T2I-Diffusionsmodell ist die Verwendung eines trainierbaren Modells (wie UNet) zur Vorhersage des Wahrscheinlichkeits-Scores (d. h. Rauschens) im Entrauschungsprozess eine grundlegende und effektive Methode .
Bei der bedingungsbasierten Score-Vorhersagemethode werden neuartige Bedingungen als Eingaben für das Vorhersagemodell verwendet, um neue Scores direkt vorherzusagen.
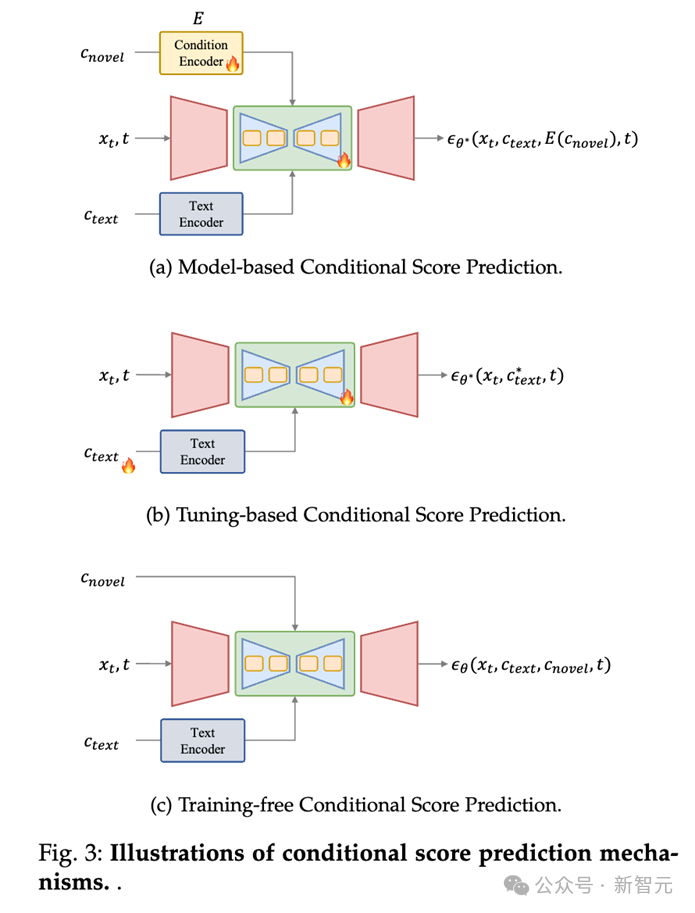
Es kann in drei Methoden zur Einführung neuer Bedingungen unterteilt werden:
1. Modellbasierte Bedingungsbewertungsvorhersage: Diese Art von Methode führt ein Modell zum Codieren neuartiger Bedingungen ein und verwendet die Codierungsfunktionen als Eingabe von UNet (z. B. Einwirken auf die Queraufmerksamkeitsschicht). Vorhersage der Neuheits-Score-Ergebnisse unter Bedingungen;
2. Bedingte Score-Vorhersage basierend auf Feinabstimmung: Diese Art von Methode verwendet keine explizite Bedingung, sondern optimiert die Parameter des Texteinbettungs- und Rauschunterdrückungsnetzwerks um es dazu zu bringen, Informationen über neuartige Bedingungen zu lernen und dabei fein abgestimmte Gewichte zu verwenden, um eine kontrollierbare Erzeugung zu erreichen. Solche Praktiken sind beispielsweise DreamBooth und Textual Inversion.
3. Bedingte Ergebnisvorhersage ohne Training: Diese Art von Methode erfordert kein Training des Modells und kann Bedingungen direkt auf die Vorhersageverknüpfung des Modells anwenden, z. B. im Layout-to-Image ( Aufgabe zur Generierung von Layoutbildern: Sie können die Aufmerksamkeitskarte der Queraufmerksamkeitsebene direkt ändern, um das Layout des Objekts festzulegen.
Bedingte geführte Bewertungsbewertung
Die Bewertungsmethode der bedingten geführten Bewertung besteht darin, dem Rauschunterdrückungsprozess eine bedingte Anleitung hinzuzufügen, indem der Gradient durch das bedingte Vorhersagemodell (wie den oben genannten Condition Predictor) rückwärts propagiert wird ).
... werden per Text beschrieben und müssen aus Beispielbildern extrahiert werden. Wie DreamBooth, Texutal Inversion und LoRA. 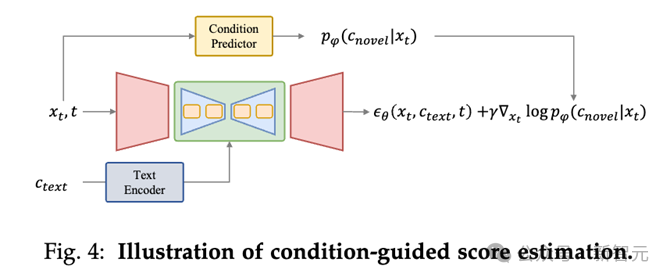
2. Räumliche Kontrolle:
Da es für Text schwierig ist, strukturelle Informationen darzustellen, d , menschliche Haltung, Analyse des menschlichen Körpers. Methoden wie ControlNet.
3. Erweiterte textbedingte Generierung: Obwohl Text in Text-zu-Bild-Diffusionsmodellen eine grundlegende Bedingungsrolle spielt, gibt es in diesem Bereich immer noch einige Herausforderungen.
Zuallererst stößt man bei der textgesteuerten Synthese in komplexen Texten mit mehreren Themen oder ausführlichen Beschreibungen häufig auf das Problem der Textfehlausrichtung. Darüber hinaus werden diese Modelle hauptsächlich auf englischsprachigen Datensätzen trainiert, was zu einem erheblichen Mangel an Möglichkeiten zur Generierung mehrerer Sprachen führt. Um dieser Einschränkung zu begegnen, wurden in vielen Arbeiten innovative Ansätze vorgeschlagen, die darauf abzielen, den Anwendungsbereich dieser Modellsprachen zu erweitern. 4. In-Kontext-Generierung:
Verstehen und führen Sie in der Kontextgenerierungsaufgabe basierend auf einem Paar aufgabenspezifischer Beispielbilder und Textanleitungen eine bestimmte Aufgabe für ein neues Abfragebild aus. 5. Brain-Guided Generation:
Brain-Guided Generation-Aufgaben konzentrieren sich auf die Steuerung der Bilderzeugung direkt aus der Gehirnaktivität, wie z. B. Elektroenzephalographie (EEG)-Aufzeichnungen und funktionelle Magnetresonanztomographie (fMRT).
6. Tongesteuerte Generierung: Generieren Sie passende Bilder basierend auf Ton.
7. Textwiedergabe: Erzeugen Sie Text in Bildern, der häufig in Postern, Datencovern, Emoticons und anderen Anwendungsszenarien verwendet werden kann.
Multi-bedingte Generierung
Die multi-bedingte Generierungsaufgabe ist darauf ausgelegt, Bilder basierend auf mehreren Bedingungen zu generieren, z. B. das Generieren einer bestimmten Person in einer benutzerdefinierten Pose oder das Generieren einer Person in drei personalisierte Identitäten. In diesem Abschnitt geben wir einen umfassenden Überblick über diese Methoden aus technischer Sicht und ordnen sie in die folgenden Kategorien ein:
1. Gemeinsames Training: Führen Sie während der Trainingsphase mehrere Bedingungen für das gemeinsame Training ein.
2. Kontinuierliches Lernen: Lernen Sie mehrere Bedingungen nacheinander und vergessen Sie nicht die alten Bedingungen, während Sie neue Bedingungen lernen, um die Generierung mehrerer Bedingungen zu erreichen.
3. Gewichtsfusion: Verwenden Sie Parameter, die durch Feinabstimmung unter verschiedenen Bedingungen für die Gewichtsfusion erhalten wurden, sodass das Modell unter mehreren Bedingungen gleichzeitig generiert werden kann.
4. Aufmerksamkeitsbasierte Integration: legt die Position mehrerer Bedingungen (normalerweise Objekte) im Bild durch Aufmerksamkeitskarte fest, um eine Generierung mehrerer Bedingungen zu erreichen.
Universelle bedingte Generierung
Neben Methoden, die auf bestimmte Arten von Bedingungen zugeschnitten sind, gibt es auch allgemeine Methoden, die sich an beliebige Bedingungen bei der Bildgenerierung anpassen lassen.
Diese Methoden werden auf der Grundlage ihrer theoretischen Grundlagen grob in zwei Gruppen eingeteilt: allgemeine bedingte Score-Vorhersage-Frameworks und allgemeine bedingte Bootstrap-Score-Schätzung.
1. Universelles Vorhersage-Framework für den Zustands-Score: Das universelle Vorhersage-Framework für den Zustands-Score erstellt ein Framework, das in der Lage ist, alle gegebenen Bedingungen zu kodieren und sie zu nutzen, um Rauschen in jedem Zeitschritt während der Bildsynthese vorherzusagen.
Diese Methode bietet eine universelle Lösung, die flexibel an verschiedene Bedingungen angepasst werden kann. Durch die direkte Integration bedingter Informationen in das generative Modell ermöglicht dieser Ansatz die dynamische Anpassung des Bilderzeugungsprozesses an verschiedene Bedingungen, wodurch er vielseitig und auf verschiedene Bildsyntheseszenarien anwendbar ist.
2. Allgemeine bedingte geführte Bewertungsschätzung: Andere Methoden nutzen die bedingte geführte Bewertungsschätzung, um verschiedene Bedingungen in Text-zu-Bild-Diffusionsmodelle zu integrieren. Die größte Herausforderung besteht darin, während der Rauschunterdrückung zustandsspezifische Hinweise aus latenten Variablen zu erhalten.
Apps
Die Einführung neuartiger Bedingungen kann bei mehreren Aufgaben nützlich sein, einschließlich Bildbearbeitung, Bildvervollständigung, Bildkombination, Text-/Bildgenerierung in 3D.
Bei der Bildbearbeitung können Sie beispielsweise eine benutzerdefinierte Methode verwenden, um die Katze im Bild in eine Katze mit einer bestimmten Identität zu bearbeiten. Weitere Informationen finden Sie im Papier.
Zusammenfassung
Diese Rezension befasst sich mit dem Bereich der bedingten Generierung von Text-zu-Bild-Diffusionsmodellen und enthüllt neuartige Bedingungen, die in den textgesteuerten Generierungsprozess integriert sind.
Zunächst vermittelt der Autor den Lesern Grundwissen, indem er das probabilistische Entrauschungsdiffusionsmodell, das berühmte Text-zu-Bild-Diffusionsmodell und eine gut strukturierte Taxonomie vorstellt. Anschließend enthüllten die Autoren den Mechanismus zur Einführung neuer Bedingungen in das T2I-Diffusionsmodell.
Anschließend fasst der Autor bisherige Methoden zur bedingten Generierung zusammen und analysiert sie unter den Aspekten theoretische Basis, technischer Fortschritt und Lösungsstrategien.
Darüber hinaus untersucht der Autor die praktischen Anwendungen der kontrollierbaren Generierung und betont deren wichtige Rolle und großes Potenzial im Zeitalter der KI-Inhaltsgenerierung.
Diese Umfrage zielt darauf ab, den aktuellen Status des Bereichs der kontrollierbaren T2I-Erzeugung umfassend zu verstehen und so die weitere Entwicklung und Erweiterung dieses dynamischen Forschungsbereichs zu fördern.
Das obige ist der detaillierte Inhalt vonDer neueste Testbericht zur steuerbaren Bilderzeugung! Die Universität für Post und Telekommunikation Peking hat 20 Seiten mit 249 Dokumenten geöffnet, die verschiedene „Bedingungen' im Bereich der Text-zu-Bild-Verbreitung abdecken.. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!