

 Technologie-PeripheriegeräteKIDECO: Ein rein auf Faltungsabfragen basierender Detektor übertrifft DETR!
Technologie-PeripheriegeräteKIDECO: Ein rein auf Faltungsabfragen basierender Detektor übertrifft DETR!DECO: Ein rein auf Faltungsabfragen basierender Detektor übertrifft DETR!


Titel: DECO: Query-Based End-to-End Object Detection with ConvNets
Papier: https://arxiv.org/pdf/2312.13735.pdf
Quellcode: https://github.com / xinghaochen/DECO
Originaltext: https://zhuanlan.zhihu.com/p/686011746@王云河
Einführung
Nach der Einführung des Detection Transformer (DETR) gab es einen Boom im Bereich der Zielerkennung , und viele nachfolgende Studien konzentrierten sich auf die Genauigkeit. Im Hinblick auf Geschwindigkeit und Geschwindigkeit wurden gegenüber dem ursprünglichen DETR Verbesserungen vorgenommen. Die Diskussion geht jedoch weiter, ob Transformers das visuelle Feld vollständig dominieren können. Einige Studien wie ConvNeXt und RepLKNet zeigen, dass CNN-Strukturen im Sichtfeld noch großes Potenzial haben.
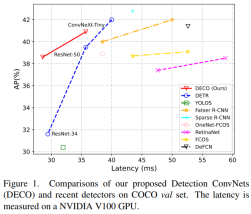
Was wir in dieser Arbeit untersuchen, ist, wie man die Architektur der „reinen Faltung“ nutzen kann, um einen DETR-ähnlichen Framework-Detektor mit hoher Leistung zu erhalten. Als Hommage an DETR nennen wir unseren Ansatz (Detection ConvNets). Unter Verwendung einer ähnlichen Struktureinstellung wie DETR und der Verwendung unterschiedlicher Backbones erreichte DECO 38,6 % und 40,8 % AP auf COCO und 35 FPS und 28 FPS auf V100 und erzielte damit eine bessere Leistung als DETR. In Kombination mit Modulen wie RT-DETR-ähnlichen Multiskalenfunktionen erreichte DECO eine Geschwindigkeit von 47,8 % AP und 34 FPS. Die Gesamtleistung weist im Vergleich zu vielen DETR-Verbesserungsmethoden gute Vorteile auf. DECOMethode
Netzwerkarchitektur
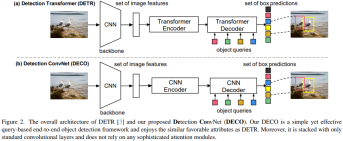 Die Hauptfunktion von DETR besteht darin, die Struktur von Transformer Encoder-Decoder zu verwenden, um mit einem Eingabebild zu interagieren, indem ein Satz von Abfragen verwendet wird, um mit Bildfunktionen zu interagieren, und ein bestimmtes direkt ausgegeben werden kann Dadurch entfällt die Abhängigkeit von Nachbearbeitungsvorgängen wie NMS. Die von uns vorgeschlagene Gesamtarchitektur von DECO ähnelt DETR. Sie umfasst außerdem Backbone für die Bildmerkmalsextraktion, eine Encoder-Decoder-Struktur für die Interaktion mit Query und gibt schließlich eine bestimmte Anzahl von Erkennungsergebnissen aus. Der einzige Unterschied besteht darin, dass DECOs Encoder und Decoder reine Faltungsstrukturen sind, sodass DECO ein abfragebasierter End-to-End-Detektor ist, der aus reiner Faltung besteht.
Die Hauptfunktion von DETR besteht darin, die Struktur von Transformer Encoder-Decoder zu verwenden, um mit einem Eingabebild zu interagieren, indem ein Satz von Abfragen verwendet wird, um mit Bildfunktionen zu interagieren, und ein bestimmtes direkt ausgegeben werden kann Dadurch entfällt die Abhängigkeit von Nachbearbeitungsvorgängen wie NMS. Die von uns vorgeschlagene Gesamtarchitektur von DECO ähnelt DETR. Sie umfasst außerdem Backbone für die Bildmerkmalsextraktion, eine Encoder-Decoder-Struktur für die Interaktion mit Query und gibt schließlich eine bestimmte Anzahl von Erkennungsergebnissen aus. Der einzige Unterschied besteht darin, dass DECOs Encoder und Decoder reine Faltungsstrukturen sind, sodass DECO ein abfragebasierter End-to-End-Detektor ist, der aus reiner Faltung besteht.
Encoder
Der Austausch der Encoder-Struktur von DETR ist relativ einfach. Wir entscheiden uns für die Verwendung von 4 ConvNeXt-Blöcken, um die Encoder-Struktur zu bilden. Konkret wird jede Schicht des Encoders durch Stapeln einer 7x7-Tiefenfaltung, einer LayerNorm-Schicht, einer 1x1-Faltung, einer GELU-Aktivierungsfunktion und einer weiteren 1x1-Faltung implementiert. Darüber hinaus muss in DETR, da die Transformer-Architektur eine Permutationsinvarianz gegenüber der Eingabe aufweist, der Eingabe jeder Encoderschicht eine Positionscodierung hinzugefügt werden. Für den Encoder, der aus Faltungen besteht, ist es jedoch nicht erforderlich, eine Positionscodierung hinzuzufügen
Decoder
Im Vergleich dazu ist der Austausch des Decoders deutlich komplizierter. Die Hauptfunktion des Decoders besteht darin, vollständig mit Bildmerkmalen und Query zu interagieren, sodass Query die Bildmerkmalsinformationen vollständig wahrnehmen und dadurch die Koordinaten und Kategorien von Zielen im Bild vorhersagen kann. Der Decoder umfasst hauptsächlich zwei Eingaben: die Feature-Ausgabe des Encoders und eine Reihe lernbarer Abfragevektoren (Query). Wir unterteilen die Hauptstruktur von Decoder in zwei Module: Self-Interaction Module (SIM) und Cross-Interaction Module (CIM).
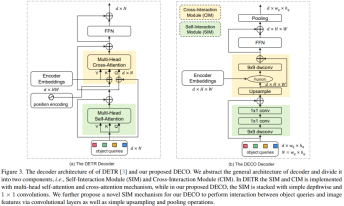 Hier integriert das SIM-Modul hauptsächlich die Ausgabe der Abfrage- und oberen Decoderschicht. Dieser Teil der Struktur kann aus mehreren Faltungsschichten bestehen, wobei eine 9x9-Tiefenfaltung und eine 1x1-Faltung in der räumlichen Dimension bzw. der Kanaldimension verwendet werden . Führen Sie einen Informationsaustausch durch, um die erforderlichen Zielinformationen vollständig zu erhalten, und senden Sie sie zur weiteren Extraktion der Zielerkennungsmerkmale an das nachfolgende CIM-Modul. Die Abfrage ist ein Satz zufällig initialisierter Vektoren. Diese Zahl bestimmt die Anzahl der vom Detektor letztendlich ausgegebenen Erkennungsrahmen. Ihr spezifischer Wert kann entsprechend den tatsächlichen Anforderungen angepasst werden. Da für DECO alle Strukturen aus Faltungen bestehen, wandeln wir Abfragen in zwei Dimensionen um. Beispielsweise können 100 Abfragen zu 10 x 10 Dimensionen werden.
Hier integriert das SIM-Modul hauptsächlich die Ausgabe der Abfrage- und oberen Decoderschicht. Dieser Teil der Struktur kann aus mehreren Faltungsschichten bestehen, wobei eine 9x9-Tiefenfaltung und eine 1x1-Faltung in der räumlichen Dimension bzw. der Kanaldimension verwendet werden . Führen Sie einen Informationsaustausch durch, um die erforderlichen Zielinformationen vollständig zu erhalten, und senden Sie sie zur weiteren Extraktion der Zielerkennungsmerkmale an das nachfolgende CIM-Modul. Die Abfrage ist ein Satz zufällig initialisierter Vektoren. Diese Zahl bestimmt die Anzahl der vom Detektor letztendlich ausgegebenen Erkennungsrahmen. Ihr spezifischer Wert kann entsprechend den tatsächlichen Anforderungen angepasst werden. Da für DECO alle Strukturen aus Faltungen bestehen, wandeln wir Abfragen in zwei Dimensionen um. Beispielsweise können 100 Abfragen zu 10 x 10 Dimensionen werden.
Die Hauptfunktion des CIM-Moduls besteht in der vollständigen Interaktion zwischen Bildmerkmalen und Query, sodass Query die Bildmerkmalsinformationen vollständig wahrnehmen und dadurch die Koordinaten und Kategorien von Zielen im Bild vorhersagen kann. Für die Transformer-Struktur ist es einfach, dieses Ziel durch die Verwendung des Queraufmerksamkeitsmechanismus zu erreichen, aber für die Faltungsstruktur ist die vollständige Interaktion mit den beiden Funktionen die größte Schwierigkeit.
Um die globalen Funktionen des SIM-Ausgangs und des Encoder-Ausgangs mit unterschiedlichen Größen zu verschmelzen, müssen wir die beiden zunächst räumlich ausrichten und dann verschmelzen. Zuerst führen wir ein Next-Neighbor-Upsampling am SIM-Ausgang durch:
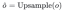
damit nach dem Upsampling Die Features haben die gleiche Größe wie die vom Encoder ausgegebenen globalen Features, und dann werden die hochgetasteten Features mit den vom Encoder ausgegebenen globalen Features fusioniert, gehen dann zur Feature-Interaktion in eine tiefe Faltung ein und fügen dann die verbleibende Eingabe hinzu:

Schließlich werden die interagierten Merkmale über FNN gegen Kanalinformationen ausgetauscht und dann zur Zielnummer zusammengefasst, um die Ausgabeeinbettung des Decoders zu erhalten:
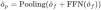
Schließlich senden wir die erhaltene Ausgabeeinbettung zur anschließenden Klassifizierung an den Erkennungskopf und Rückschritt.
Multiskalenfunktionen
Wie das ursprüngliche DETR weist das durch das obige Framework erhaltene DECO einen gemeinsamen Nachteil auf, nämlich das Fehlen von Multiskalenfunktionen, was einen großen Einfluss auf die hochpräzise Zielerkennung hat. Deformable DETR integriert Merkmale verschiedener Skalen mithilfe eines deformierbaren Aufmerksamkeitsmoduls mit mehreren Skalen. Diese Methode ist jedoch stark mit dem Aufmerksamkeitsoperator gekoppelt und kann daher nicht direkt auf unserem DECO verwendet werden. Damit DECO Multi-Scale-Features verarbeiten kann, verwenden wir nach den vom Decoder ausgegebenen Features ein von RT-DETR vorgeschlagenes Cross-Scale-Feature-Fusion-Modul. Tatsächlich wurden nach der Geburt von DETR eine Reihe von Verbesserungsmethoden abgeleitet. Wir glauben, dass viele Strategien auch auf DECO anwendbar sind, und wir hoffen, dass interessierte Menschen dies gemeinsam diskutieren können.
Experiment
Wir haben Experimente mit COCO durchgeführt und DECO und DETR verglichen, während die Hauptarchitektur unverändert blieb, z. B. die Anzahl der Abfragen konsistent blieb, die Anzahl der Decoderschichten unverändert blieb usw. und nur der Transformer in DETR geändert wurde Die Struktur wird durch unsere oben beschriebene Faltungsstruktur ersetzt. Es ist ersichtlich, dass DECO eine bessere Genauigkeit und einen schnelleren Kompromiss als DETR erreicht hat.
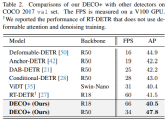
Wir haben DECO, das mit Multiskalenfunktionen ausgestattet ist, auch mit mehr Zielerkennungsmethoden verglichen, darunter viele Variationen von DETR. Wie Sie der Abbildung unten entnehmen können, hat DECO sehr gute Ergebnisse erzielt Leistung als viele frühere Detektoren.
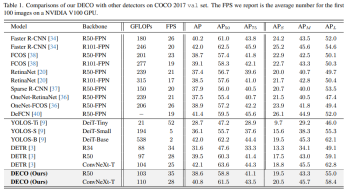
Die DECO-Struktur im Artikel wurde vielen Ablationsexperimenten und Visualisierungen unterzogen, einschließlich der im Decoder ausgewählten spezifischen Fusionsstrategien (Addition, Punktmultiplikation, Concat) und der Einstellung der Abfragedimensionen, um optimale Ergebnisse zu erzielen. usw. gibt es auch einige interessante Erkenntnisse. Weitere detaillierte Ergebnisse und Diskussionen finden Sie im Originalartikel.
Zusammenfassung
In diesem Artikel soll untersucht werden, ob es möglich ist, ein abfragebasiertes End-to-End-Objekterkennungsframework zu erstellen, ohne eine komplexe Transformer-Architektur zu verwenden. Es wird ein neues Erkennungsframework namens Detection ConvNet (DECO) vorgeschlagen, das ein Backbone-Netzwerk und eine Faltungs-Encoder-Decoder-Struktur umfasst. Durch die sorgfältige Gestaltung des DECO-Encoders und die Einführung eines neuartigen Mechanismus ist der DECO-Decoder in der Lage, die Interaktion zwischen der Zielabfrage und den Bildmerkmalen durch Faltungsschichten zu erreichen. Beim COCO-Benchmark wurden Vergleiche mit früheren Detektoren angestellt, und trotz seiner Einfachheit erzielte DECO eine wettbewerbsfähige Leistung in Bezug auf Erkennungsgenauigkeit und Laufgeschwindigkeit. Insbesondere unter Verwendung der ResNet-50- und ConvNeXt-Tiny-Backbones erreichte DECO 38,6 % bzw. 40,8 % AP bei der COCO-Validierung, die auf 35 bzw. 28 FPS eingestellt war, und übertraf damit das DET-Modell. Es besteht die Hoffnung, dass DECO eine neue Perspektive für die Gestaltung von Objekterkennungs-Frameworks bietet.
Das obige ist der detaillierte Inhalt vonDECO: Ein rein auf Faltungsabfragen basierender Detektor übertrifft DETR!. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

 Die KI -Kompetenzlücke verlangsamt die VersorgungskettenApr 26, 2025 am 11:13 AM
Die KI -Kompetenzlücke verlangsamt die VersorgungskettenApr 26, 2025 am 11:13 AMDer Begriff "AI-fähige Belegschaft" wird häufig verwendet, aber was bedeutet das in der Lieferkettenindustrie wirklich? Nach Abe Eshkenazi, CEO des Association for Supply Chain Management (ASCM), bedeutet dies Fachkräfte, die kritisch sind
 Wie ein Unternehmen leise daran arbeitet, die KI für immer zu verwandelnApr 26, 2025 am 11:12 AM
Wie ein Unternehmen leise daran arbeitet, die KI für immer zu verwandelnApr 26, 2025 am 11:12 AMDie dezentrale KI -Revolution gewinnt leise an Dynamik. An diesem Freitag in Austin, Texas, markiert der Bittensor Endgame Summit einen entscheidenden Moment, in dem die dezentrale KI (DEAI) von Theorie zu praktischer Anwendung übergeht. Im Gegensatz zum glitzernden Werbespot
 Nvidia veröffentlicht Nemo Microservices, um die Entwicklung der AI -Agenten zu optimierenApr 26, 2025 am 11:11 AM
Nvidia veröffentlicht Nemo Microservices, um die Entwicklung der AI -Agenten zu optimierenApr 26, 2025 am 11:11 AMEnterprise KI steht vor der Datenintegrationsprobleme Die Anwendung von Enterprise KI steht vor einer großen Herausforderung: Aufbau von Systemen, die die Genauigkeit und Praktikabilität durch kontinuierlich lernende Geschäftsdaten aufrechterhalten können. NEMO Microservices lösen dieses Problem, indem er das erstellt, was NVIDIA als "Datenschwungrad" beschreibt und KI -Systemen durch kontinuierliche Exposition gegenüber Unternehmensinformationen und Benutzerinteraktion relevant bleibt. Dieses neu gestartete Toolkit enthält fünf wichtige Microservices: Nemo Customizer behandelt die Feinabstimmung großer Sprachmodelle mit höherem Trainingsdurchsatz. NEMO Evaluator bietet eine vereinfachte Bewertung von KI -Modellen für benutzerdefinierte Benchmarks. NEMO -Leitplanken implementiert Sicherheitskontrollen, um die Einhaltung und Angemessenheit aufrechtzuerhalten
 KI malt ein neues Bild für die Zukunft von Kunst und DesignApr 26, 2025 am 11:10 AM
KI malt ein neues Bild für die Zukunft von Kunst und DesignApr 26, 2025 am 11:10 AMAI: Die Zukunft von Kunst und Design Künstliche Intelligenz (KI) verändert das Kunst- und Designgebiet auf beispiellose Weise, und seine Auswirkungen beschränken sich nicht mehr auf Amateure, sondern beeinflussen jedoch die Fachkräfte. Kunstwerke und Designschemata, die von KI erzeugt wurden, ersetzen traditionelle materielle Bilder und Designer in vielen Transaktionsdesignaktivitäten wie Werbung, Social -Media -Bildgenerierung und Webdesign schnell. Professionelle Künstler und Designer finden jedoch auch den praktischen Wert von KI. Sie verwenden AI als Hilfsmittel, um neue ästhetische Möglichkeiten zu erforschen, verschiedene Stile zu mischen und neuartige visuelle Effekte zu erzeugen. KI hilft Künstlern und Designer, sich wiederholende Aufgaben zu automatisieren, verschiedene Designelemente vorzuschlagen und kreative Eingaben zu leisten. AI unterstützt den Stiltransfer, der einen Bildstil anwenden soll
 Wie Zoom die Arbeit mit Agentic AI: Von Meetings bis Meilensteinen revolutioniertApr 26, 2025 am 11:09 AM
Wie Zoom die Arbeit mit Agentic AI: Von Meetings bis Meilensteinen revolutioniertApr 26, 2025 am 11:09 AMZoom, ursprünglich für seine Video -Konferenz -Plattform bekannt, führt eine Revolution am Arbeitsplatz mit der innovativen Nutzung der Agenten -KI. Ein aktuelles Gespräch mit Zooms CTO, XD Huang, enthüllte die ehrgeizige Vision des Unternehmens. Definieren von Agenten AI Huang d
 Die existenzielle Bedrohung für UniversitätenApr 26, 2025 am 11:08 AM
Die existenzielle Bedrohung für UniversitätenApr 26, 2025 am 11:08 AMWird AI die Bildung revolutionieren? Diese Frage führt zu ernsthafter Reflexion unter Pädagogen und Stakeholdern. Die Integration von KI in Bildung bietet sowohl Chancen als auch Herausforderungen. Wie Matthew Lynch von The Tech Edvocate bemerkt, Universität
 Der Prototyp: Amerikanische Wissenschaftler suchen nach Jobs im AuslandApr 26, 2025 am 11:07 AM
Der Prototyp: Amerikanische Wissenschaftler suchen nach Jobs im AuslandApr 26, 2025 am 11:07 AMDie Entwicklung wissenschaftlicher Forschung und Technologie in den Vereinigten Staaten kann vor Herausforderungen stehen, möglicherweise aufgrund von Budgetkürzungen. Nach der Natur stieg die Zahl der amerikanischen Wissenschaftler, die sich für Arbeitsplätze in Übersee bewerben, von Januar bis März 2025 im Vergleich zum gleichen Zeitraum von 2024 um 32%. Eine frühere Umfrage ergab, dass 75% der untersuchten Forscher über die Suche nach Arbeitsplätzen in Europa und Kanada in Betracht gezogen wurden. In den letzten Monaten wurden Hunderte von NIH- und NSF-Zuschüssen beendet, wobei die neuen Zuschüsse von NIH in diesem Jahr um etwa 2,3 Milliarden US-Dollar gesunken sind, ein Rückgang von fast einem Drittel. Der durchgesickerte Haushaltsvorschlag zeigt, dass die Trump -Administration mit einer möglichen Reduzierung von um bis zu 50%ein starkes Budget für wissenschaftliche Institutionen in Betracht zieht. Die Turbulenzen auf dem Gebiet der Grundlagenforschung haben sich auch auf einen der Hauptvorteile der Vereinigten Staaten ausgewirkt: die Gewinnung von Talenten in Übersee. 35
 Alles über Open AIs neueste GPT 4.1 -Familie - Analytics VidhyaApr 26, 2025 am 10:19 AM
Alles über Open AIs neueste GPT 4.1 -Familie - Analytics VidhyaApr 26, 2025 am 10:19 AMOpenAI enthüllt die leistungsstarke GPT-4.1-Serie: eine Familie von drei fortschrittlichen Sprachmodellen für reale Anwendungen. Dieser signifikante Sprung nach vorne bietet schnellere Reaktionszeiten, verbessertes Verständnis und drastisch reduzierte Kosten im Vergleich t t


Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

Video Face Swap
Tauschen Sie Gesichter in jedem Video mühelos mit unserem völlig kostenlosen KI-Gesichtstausch-Tool aus!

Heißer Artikel
Heiße Werkzeuge

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)

MinGW – Minimalistisches GNU für Windows
Dieses Projekt wird derzeit auf osdn.net/projects/mingw migriert. Sie können uns dort weiterhin folgen. MinGW: Eine native Windows-Portierung der GNU Compiler Collection (GCC), frei verteilbare Importbibliotheken und Header-Dateien zum Erstellen nativer Windows-Anwendungen, einschließlich Erweiterungen der MSVC-Laufzeit zur Unterstützung der C99-Funktionalität. Die gesamte MinGW-Software kann auf 64-Bit-Windows-Plattformen ausgeführt werden.

PHPStorm Mac-Version
Das neueste (2018.2.1) professionelle, integrierte PHP-Entwicklungstool

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

