
Heim >Technologie-Peripheriegeräte >KI >Um die Privatsphäre der Kunden zu schützen, führen Sie Open-Source-KI-Modelle lokal mit Ruby aus
Um die Privatsphäre der Kunden zu schützen, führen Sie Open-Source-KI-Modelle lokal mit Ruby aus

- 王林nach vorne
- 2024-03-18 21:40:03746Durchsuche
Übersetzer |. Chen Jun
Rezensent |. Kürzlich haben wir ein maßgeschneidertes Projekt für künstliche Intelligenz (KI) implementiert. Da Partei A über sehr sensible Kundeninformationen verfügt, können wir diese aus Sicherheitsgründen nicht an
OpenAIoder andere proprietäre Modelle weitergeben. Deshalb haben wir ein Open-Source-KI-Modell heruntergeladen und in einer virtuellen AWS-Maschine ausgeführt, sodass wir es vollständig unter unserer Kontrolle haben. Gleichzeitig können Rails-Anwendungen API-Anrufe an die KI in einer sicheren Umgebung tätigen. Wenn Sicherheitsaspekte nicht berücksichtigt werden müssen, würden wir natürlich lieber direkt mit OpenAI zusammenarbeiten.
Im Folgenden erkläre ich Ihnen, wie Sie das Open-Source-KI-Modell lokal herunterladen, laufen lassen und wie Sie das Skript 
dagegen ausführen. Warum anpassen?
Die Motivation für dieses Projekt ist einfach: Datensicherheit. Beim Umgang mit sensiblen Kundeninformationen ist es in der Regel am zuverlässigsten, dies innerhalb des Unternehmens zu tun. Daher benötigen wir maßgeschneiderte KI-Modelle, die dazu beitragen, ein höheres Maß an Sicherheitskontrolle und Datenschutz zu gewährleisten.
Open-Source-Modell
In den vergangenen
6Monaten gab es neue Produkte auf dem Markt wie: Mistral, Mixtral und Lamaetc. Eine große Anzahl von Open-Source-KI-Modellen. Obwohl sie nicht so leistungsstark sind wie GPT-4, übertrifft die Leistung vieler von ihnen GPT-3.5 und sie werden mit der Zeit immer leistungsfähiger. Für welches Modell Sie sich entscheiden, hängt natürlich ganz von Ihren Verarbeitungsmöglichkeiten und dem, was Sie erreichen möchten, ab. Da wir das KI-Modell lokal ausführen werden, haben wir den
Mistralausgewählt, der ungefähr 4 GB ist. Bei den meisten Kennzahlen übertrifft es GPT-3.5. Obwohl Mixtral eine bessere Leistung als Mistral bietet, handelt es sich um ein sperriges Modell, das zum Betrieb mindestens 48 GB Speicher benötigt. Parameter
Wenn wir über große Sprachmodelle (
LLM) sprechen, neigen wir dazu, über die Erwähnung ihrer Parametergrößen nachzudenken. Hier ist das Mistral-Modell, das wir lokal ausführen werden, ein 7-Milliarden-Parametermodell (natürlich hat Mixtral 700 Milliarden Parameter und GPT-3.5 Es gibt ungefähr 1750 Milliarden Parameter). Typischerweise verwenden große Sprachmodelle Techniken, die auf neuronalen Netzwerken basieren. Neuronale Netzwerke bestehen aus Neuronen, und jedes Neuron ist mit allen anderen Neuronen in der nächsten Schicht verbunden.
Wie im Bild oben gezeigt, hat jede Verbindung ein Gewicht, das normalerweise als Prozentsatz ausgedrückt wird. Jedes Neuron verfügt außerdem über eine Vorspannung, die die Daten korrigiert, wenn sie einen Knoten durchlaufen. 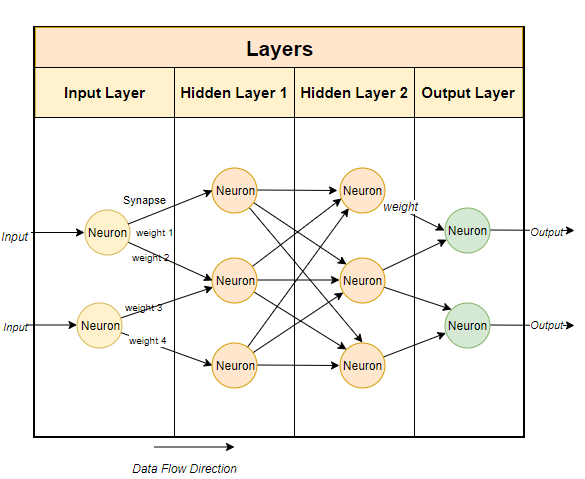
Der Zweck des neuronalen Netzwerks besteht darin, einen erweiterten Algorithmus, einen Mustervergleichsalgorithmus, zu „lernen“. Indem es an großen Textmengen trainiert wird, lernt es nach und nach die Fähigkeit, Textmuster vorherzusagen und sinnvoll auf die Hinweise zu reagieren, die wir ihm geben. Einfach ausgedrückt sind Parameter die Anzahl der Gewichte und Verzerrungen im Modell. Es gibt uns eine Vorstellung davon, wie viele Neuronen es in einem neuronalen Netzwerk gibt. Beispielsweise gibt es für ein 7 Milliarden Parametermodell ungefähr
100Schichten mit jeweils Tausenden von Neuronen. Führen Sie das Modell lokal aus
Um das Open-Source-Modell lokal auszuführen, müssen Sie zunächst die entsprechende Anwendung herunterladen. Obwohl es viele Optionen auf dem Markt gibt, istOllama diejenige, die sich meiner Meinung nach am einfachsten und am einfachsten auf Intel
Macausführen lässt. Obwohl Ollama derzeit nur auf
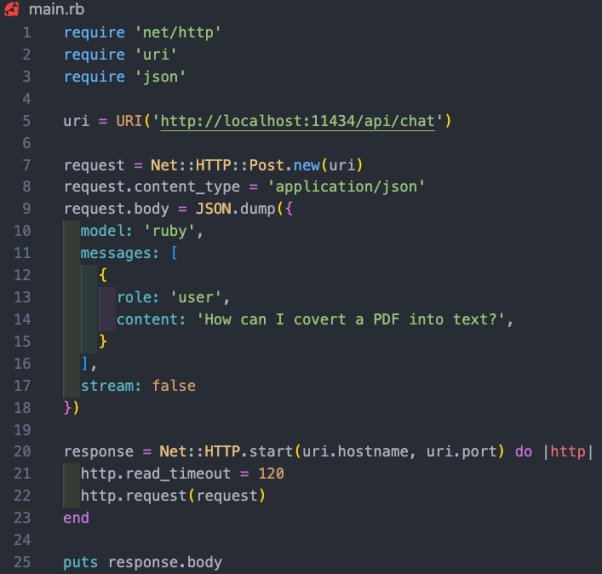
Mac und Linux läuft, wird es in Zukunft auch auf Windows laufen. Natürlich können Sie WSL (Windows-Subsystem für Linux) verwenden, um Linux-Shell unter Windows auszuführen. Ollama ermöglicht Ihnen nicht nur das Herunterladen und Ausführen verschiedener Open-Source-Modelle, sondern öffnet das Modell auch auf einem lokalen Port, sodass Sie API-Aufrufe über RubyCode tätigen können. Dies erleichtert Ruby-Entwicklern das Schreiben von Ruby-Anwendungen, die in lokale Modelle integriert werden können. Da Ollama hauptsächlich befehlszeilenbasiert ist, ist es sehr einfach, Ollama auf Mac und Linux zu installieren . Sie müssen Ollama nur über den Link https://www.php.cn/link/04c7f37f2420f0532d7f0e062ff2d5b5 herunterladen, etwa 5 Minuten für die Installation des Softwarepakets aufwenden und dann das Modell ausführen. Nachdem Sie Ollama eingerichtet und ausgeführt haben, sehen Sie das Ollama-Symbol in der Taskleiste Ihres Browsers. Das bedeutet, dass es im Hintergrund läuft und Ihr Modell ausführen kann. Um das Modell herunterzuladen, können Sie ein Terminal öffnen und den folgenden Befehl ausführen: Da Mistral etwa 4GB groß ist, wird es bei Ihnen eine Weile dauern um den Download abzuschließen. Sobald der Download abgeschlossen ist, wird automatisch die Ollama-Eingabeaufforderung geöffnet, damit Sie mit Mistral interagieren und kommunizieren können. Wenn Sie mistral das nächste Mal durch Ollama laufen, können Sie das entsprechende Modell direkt ausführen. Ähnlich wie wir benutzerdefiniertes GPT in OpenAI erstellen, können Sie über Ollama das Basismodell anpassen. Hier können wir einfach ein benutzerdefiniertes Modell erstellen. Ausführlichere Fälle finden Sie in der Online-Dokumentation von Ollama. Zunächst können Sie ein Modelfile (Modelldatei) erstellen und darin den folgenden Text hinzufügen: Die oben erscheinende Systemmeldung ist die Grundlage für die konkrete Reaktion der KI Modell. Als nächstes können Sie den folgenden Befehl auf dem Terminal ausführen, um ein neues Modell zu erstellen: In unserem Projektfall habe ich das Modell Ruby genannt. Gleichzeitig können Sie den folgenden Befehl verwenden, um Ihre vorhandenen Modelle aufzulisten und anzuzeigen: https://www.php.cn/link/dcd3f83c96576c0fd437286a1ff6f1f0“ darauf zugreifen können. Darüber hinaus bietet die Dokumentation für die Ollama-API auch verschiedene Endpunkte für grundlegende Befehle wie Chat-Konversationen und das Erstellen von Einbettungen. In diesem Projektfall möchten wir den Endpunkt /api/chat verwenden, um Eingabeaufforderungen an das KI-Modell zu senden. Das Bild unten zeigt einige grundlegende RubyCode für die Interaktion mit dem Modell: Die Funktionalität des oben genannten RubyCode-Snippets umfasst: netto /http“, „uri “ drei Bibliotheken führen jeweils HTTP-Anfragen aus, analysieren URI bzw. verarbeiten , Autor: Kane Hooper
Holen Sie sich Ollama
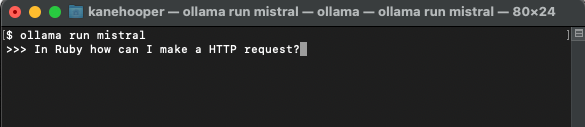
Installieren Ihres ersten Modells
ollama run mistral
Maßgeschneidertes Modell
FROM mistral# Set the temperature set the randomness or creativity of the responsePARAMETER temperature 0.3# Set the system messageSYSTEM ”””You are an excerpt Ruby developer. You will be asked questions about the Ruby Programminglanguage. You will provide an explanation along with code examples.”””
ollama create <model-name> -f './Modelfile</model-name>
ollama create ruby -f './Modelfile'
ollama list
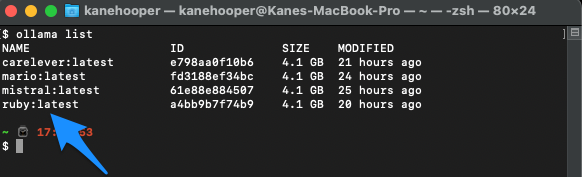
Ollama run ruby
11434 öffnen, sodass Sie über „
 json
jsonJSON
Mac
How To Run Open-Source AI Models Locally With Ruby
Das obige ist der detaillierte Inhalt vonUm die Privatsphäre der Kunden zu schützen, führen Sie Open-Source-KI-Modelle lokal mit Ruby aus. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!