
Heim >Technologie-Peripheriegeräte >KI >时间序列预测+NLP大模型新作:为时序预测自动生成隐式Prompt
时间序列预测+NLP大模型新作:为时序预测自动生成隐式Prompt

- 王林nach vorne
- 2024-03-18 09:20:101233Durchsuche
Heute möchte ich eine aktuelle Forschungsarbeit der University of Connecticut vorstellen, die eine Methode zum Abgleichen von Zeitreihendaten mit großen NLP-Modellen (Natural Language Processing) im latenten Raum vorschlägt, um die Zeitreihenprognose zu verbessern. Der Schlüssel zu dieser Methode besteht darin, latente räumliche Hinweise (Eingabeaufforderungen) zu verwenden, um die Genauigkeit von Zeitreihenvorhersagen zu verbessern.

Papiertitel: S2IP-LLM: Semantic Space Informed Prompt Learning with LLM for Time Series Forecasting
Download-Adresse: https://www.php.cn/link/3695d85c350d924e662ea2cd3b760d40
1. Problemhintergrund
Große Modelle werden zunehmend in Zeitreihen verwendet und sind hauptsächlich in zwei Kategorien unterteilt: Die erste Kategorie verwendet verschiedene Zeitreihendaten, um ein eigenes großes Modell im Zeitreihenfeld zu trainieren, und die zweite Kategorie verwendet direkt Texte, die im NLP-Feld groß trainiert wurden Modelle werden auf Zeitreihen angewendet. Da sich Zeitreihen von Bildern und Texten unterscheiden, haben unterschiedliche Datensätze unterschiedliche Eingabeformate und Verteilungen und es gibt Probleme wie Verteilungsverschiebungen, die es schwierig machen, ein einheitliches Modell unter Verwendung aller Zeitreihendaten zu trainieren. Daher wird immer mehr damit begonnen, zu versuchen, große NLP-Modelle direkt zu verwenden, um zeitreihenbezogene Probleme zu lösen.
Dieser Artikel konzentriert sich auch auf die zweite Methode zur Lösung von Zeitreihenproblemen, nämlich die Verwendung großer NLP-Modelle. In der aktuellen Praxis wird häufig eine Beschreibung der Zeitreihe als Anhaltspunkt verwendet, aber nicht alle Zeitreihendatensätze enthalten diese Informationen. Darüber hinaus kann die patchbasierte Zeitreihendatenverarbeitungsmethode nicht alle Informationen der Zeitreihendaten vollständig beibehalten.
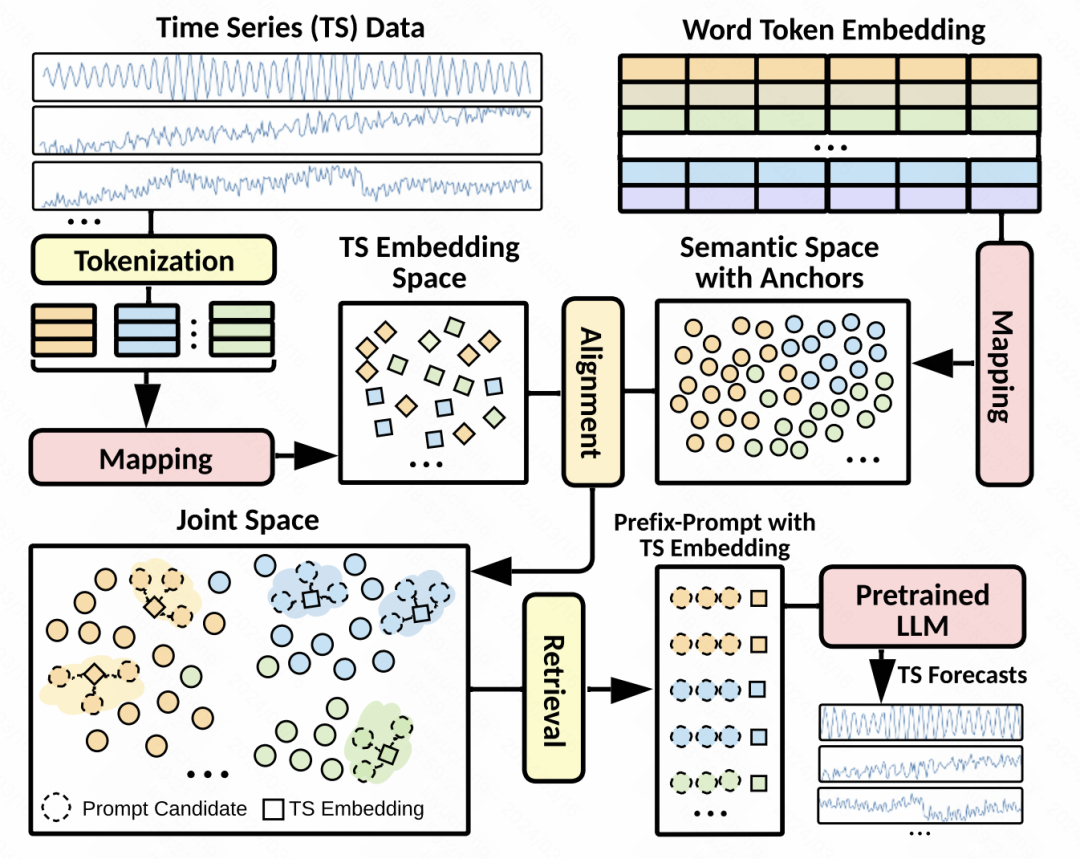
Basierend auf den oben genannten Problemen schlägt dieser Artikel eine neue Modellierungsmethode vor. Die Kernidee der Modellierung besteht einerseits darin, die Zeitreihen nach der Tokenisierungsverarbeitung in die Einbettung abzubilden, und andererseits in der Darstellung dieser Zeitreihenräume Ausgerichtet auf eine große Einbettung des Wortes in das Modell. Auf diese Weise können während des Zeitreihenvorhersageprozesses die Informationen zur ausgerichteten Worteinbettung als Aufforderung zur Verbesserung des Vorhersageeffekts gefunden werden.
 Bilder
Bilder
2. Implementierungsmethode
Im Folgenden wird die Implementierungsmethode dieser Arbeit unter drei Gesichtspunkten vorgestellt: Datenverarbeitung, Latentraumausrichtung und Modelldetails.
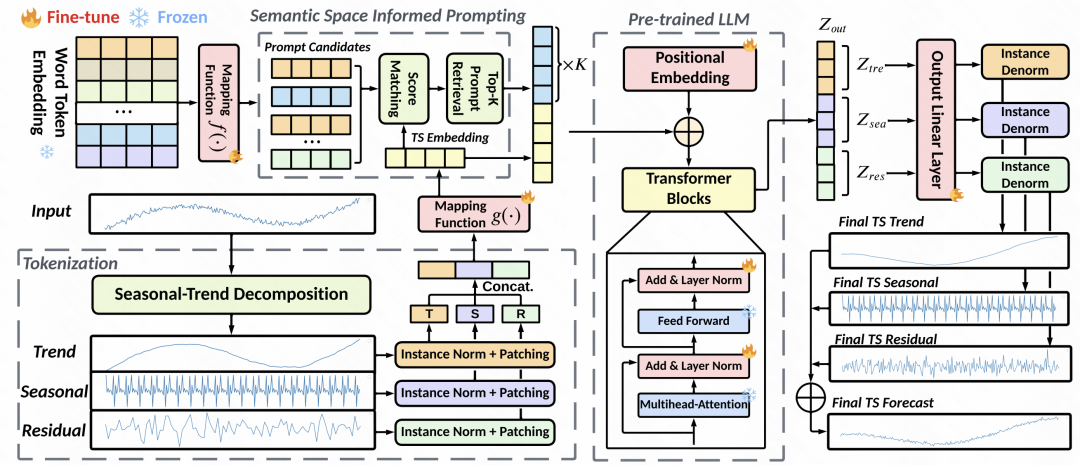
Datenverarbeitung: Aufgrund von Problemen wie der Verteilungsverschiebung von Zeitreihen führt dieser Artikel eine einstufige Zerlegung von Trendelementen und Saisonelementen in der Eingabereihe durch. Jede zerlegte Zeitreihe wird separat standardisiert und dann in überlappende Patches unterteilt. Jeder Patch-Satz entspricht dem Trend-Term-Patch, dem Saison-Term-Patch und dem Rest-Patch. Diese drei Patches-Sets werden zusammengefügt und in das MLP eingegeben, um die grundlegende Einbettungsdarstellung jedes Patch-Sets zu erhalten.
Latentraumausrichtung: Dies ist der Kernschritt in diesem Artikel. Das Design von Eingabeaufforderungen hat großen Einfluss auf die Leistung großer Modelle, und Zeitreihen-Eingabeaufforderungen sind schwierig zu entwerfen. Daher wird in diesem Artikel vorgeschlagen, die Patch-Darstellung der Zeitreihe an der Worteinbettung des großen Modells im latenten Raum auszurichten und dann die topK-Worteinbettungen als implizite Eingabeaufforderungen abzurufen. Die spezifische Methode besteht darin, die im vorherigen Schritt generierte Patch-Einbettung zu verwenden, um die Kosinus-Ähnlichkeit mit der Worteinbettung im Sprachmodell zu berechnen, die topK-Worteinbettungen auszuwählen und diese Worteinbettungen dann als Eingabeaufforderungen zu verwenden, um sie an die Vorderseite des zu verbinden Zeitreihen-Patch-Einbettungen. Da es in großen Modellen viele Worteinbettungen gibt, ordnen wir die Worteinbettungen zunächst einer kleinen Anzahl von Clusterzentren zu, um den Rechenaufwand zu reduzieren.
Modelldetails: In Bezug auf die Modelldetails wird GPT2 als Sprachmodellteil verwendet, mit Ausnahme der Parameter der Positionseinbettungs- und Ebenennormalisierungsteile, der Rest ist eingefroren. Zusätzlich zu MSE führt das Optimierungsziel auch die Ähnlichkeit zwischen der Patch-Einbettung und der abgerufenen TopK-Cluster-Einbettung als Einschränkung ein, was erfordert, dass der Abstand zwischen den beiden so klein wie möglich ist. Die endgültigen Vorhersageergebnisse sind ebenfalls
 Bilder
Bilder
3. Experimentelle Ergebnisse
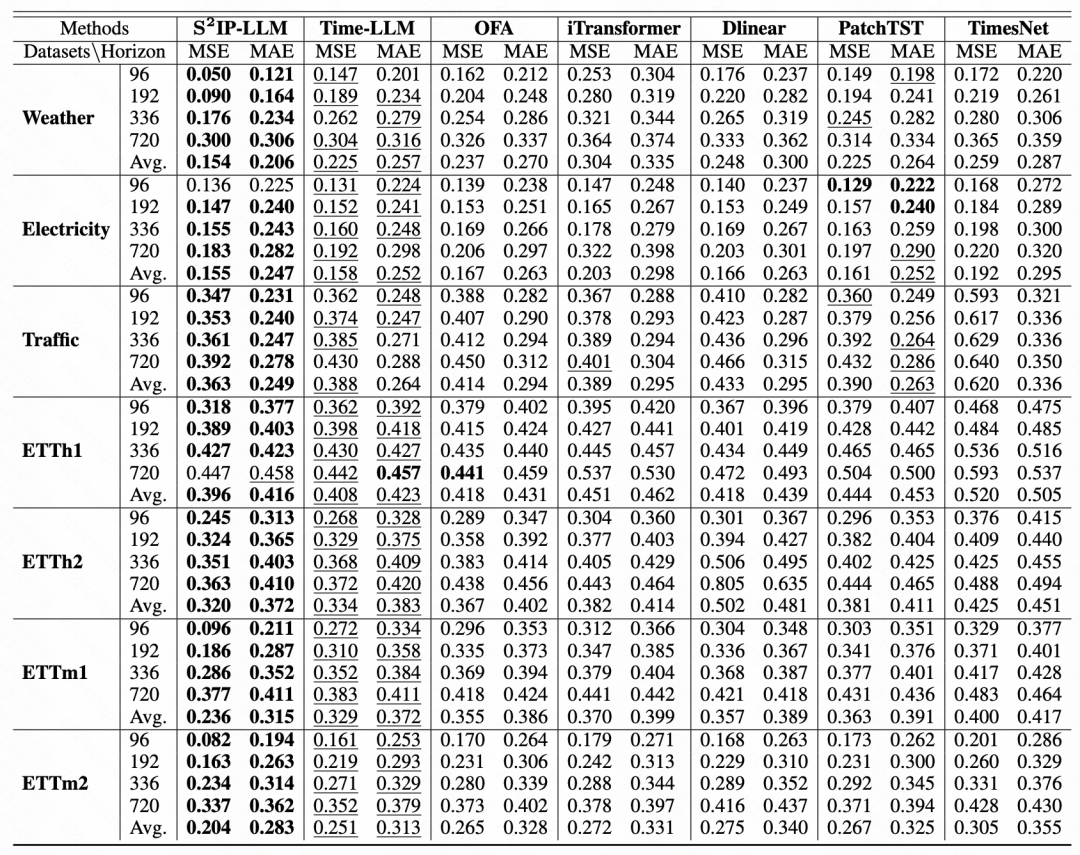
Der Artikel vergleicht die Auswirkungen einiger großer Zeitreihenmodelle, iTransformer, PatchTST und anderer SOTA-Modelle sowie die Vorhersagen der meisten Daten in verschiedenen Zeitfenstern Sätze Beide haben relativ gute Ergebnisse erzielt.
 Bild
Bild
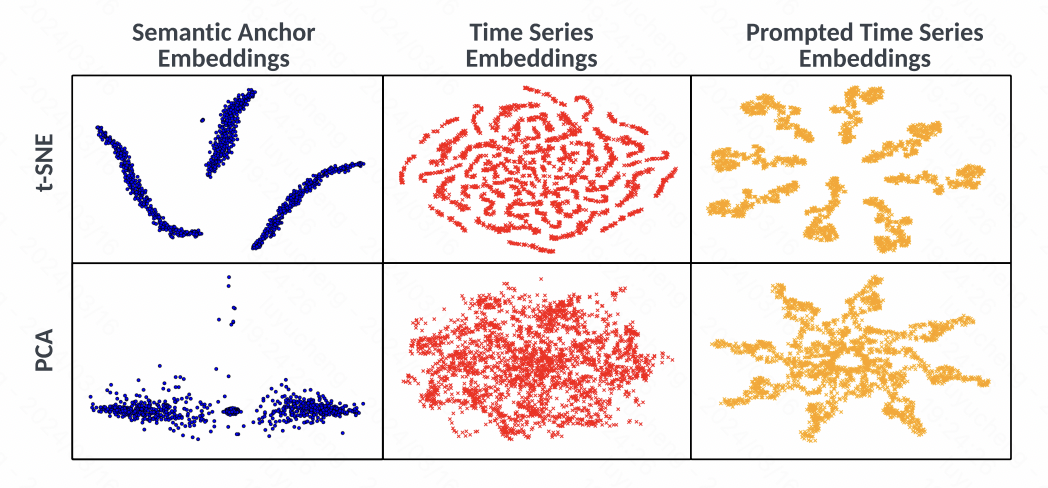
Gleichzeitig analysiert der Artikel auch visuell die Einbettung durch t-SNE. Wie aus der Abbildung ersichtlich ist, weist die Einbettung der Zeitreihe vor der Ausrichtung kein offensichtliches Clustering-Phänomen auf Die offensichtlichen Änderungen in den Clustern weisen darauf hin, dass die in diesem Artikel vorgeschlagene Methode die räumliche Ausrichtung von Text und Zeitreihen sowie die entsprechenden Eingabeaufforderungen effektiv nutzt, um die Qualität der Zeitreihendarstellung zu verbessern.
 Bilder
Bilder
Das obige ist der detaillierte Inhalt von时间序列预测+NLP大模型新作:为时序预测自动生成隐式Prompt. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Was ist ein Haufen? Was ist der Methodenbereich? Einführung in den Heap- und Methodenbereich im JVM-Speichermodell
- So exportieren Sie ein Modell in Navicat
- Zu welcher Art von Datenmodell gehört SQL Server?
- Technische Ideen zur Implementierung der Suche und Aggregation von Zeitreihendaten mit RiSearch PHP