

 Technologie-PeripheriegeräteKIZur Verbesserung der generativen Zero-Shot-Lernfähigkeiten wurde die visuell verbesserte dynamische semantische Prototyping-Methode für CVPR 2024 ausgewählt
Technologie-PeripheriegeräteKIZur Verbesserung der generativen Zero-Shot-Lernfähigkeiten wurde die visuell verbesserte dynamische semantische Prototyping-Methode für CVPR 2024 ausgewählt
Obwohl ich dich noch nie getroffen habe, ist es für mich möglich, dich zu „kennen“ – das ist der Zustand, den Menschen von künstlicher Intelligenz auf den ersten Blick erwarten.
Um dieses Ziel zu erreichen, trainieren Menschen bei herkömmlichen Bilderkennungsaufgaben Algorithmusmodelle anhand einer großen Anzahl von Bildbeispielen mit unterschiedlichen Kategoriebezeichnungen, damit das Modell die Fähigkeit erwerben kann, diese Bilder zu erkennen. Bei der Zero-Shot-Learning-Aufgabe (ZSL) hoffen die Menschen, dass das Modell Schlussfolgerungen ziehen und Kategorien identifizieren kann, die in der Trainingsphase keine Bildbeispiele gesehen haben.
Generatives Zero-Shot-Lernen (GZSL) gilt als effektive Methode für Zero-Shot-Lernen. Bei GZSL besteht der erste Schritt darin, einen Generator zu trainieren, um visuelle Merkmale unsichtbarer Kategorien zu synthetisieren. Dieser Generierungsprozess wird durch die Nutzung semantischer Beschreibungen wie Attributbezeichnungen als Bedingungen vorangetrieben. Sobald diese virtuellen visuellen Merkmale generiert sind, können Sie mit dem Training eines Klassifizierungsmodells beginnen, das unsichtbare Klassen erkennen kann, genau wie Sie es mit einem herkömmlichen Klassifikator tun würden.
Das Training des Generators ist entscheidend für generative Zero-Shot-Lernalgorithmen. Idealerweise sollten die visuellen Merkmalsproben einer unsichtbaren Kategorie, die vom Generator basierend auf der semantischen Beschreibung generiert werden, die gleiche Verteilung aufweisen wie die visuellen Merkmale realer Proben dieser Kategorie. Das bedeutet, dass der Generator in der Lage sein muss, die Beziehungen und Muster zwischen visuellen Merkmalen genau zu erfassen, um Proben mit einem hohen Maß an Konsistenz und Glaubwürdigkeit zu generieren. Durch das Training des Generators können die visuellen Merkmalsunterschiede zwischen verschiedenen Kategorien effektiv erlernt werden Die Kategorie ist bedingt, was den Generator darauf beschränkt, nur die gesamte Kategorie zu optimieren, anstatt jede Beispielinstanz zu beschreiben. Daher ist es schwierig, die Verteilung der visuellen Merkmale realer Proben genau wiederzugeben, was zu einer schlechten Generalisierungsleistung des Modells führt. Schlecht. Darüber hinaus werden die visuellen Informationen des von sichtbaren und unsichtbaren Klassen gemeinsam genutzten Datensatzes, also das Domänenwissen, im Trainingsprozess des Generators nicht vollständig genutzt, was den Wissenstransfer von sichtbaren Klassen zu unsichtbaren Klassen einschränkt.
Um diese Probleme zu lösen, schlugen Doktoranden der Huazhong University of Science and Technology und technische Experten der Intime Business Group, einer Tochtergesellschaft von Alibaba, eine Methode namens Visually Enhanced Dynamic Semantic Prototyping (VADS) vor. Dieser Ansatz führt visuelle Merkmale gesehener Klassen vollständiger in semantische Bedingungen ein und ermöglicht es dem Push-Generator, genaue semantisch-visuelle Zuordnungen zu lernen. Dieses Forschungspapier „Visual-Augmented Dynamic Semantic Prototype for Generative Zero-Shot Learning“ wurde von CVPR 2024, der führenden internationalen akademischen Konferenz im Bereich Computer Vision, angenommen.
Die obige Forschung stellt insbesondere drei innovative Punkte dar:
Beim Zero-Shot-Lernen werden visuelle Merkmale verwendet, um den Generator zu verbessern und zuverlässige visuelle Merkmale zu generieren, was eine innovative Methode darstellt.
Die Forschung führte auch zwei Komponenten ein, VDKL und VOSU. Mit Hilfe dieser Komponenten wird der visuelle Prior des Datensatzes effektiv ermittelt, und durch dynamische Aktualisierung der visuellen Merkmale des Bildes wird die semantische Beschreibung der vordefinierten Kategorie erstellt Aktualisiert . Diese Methode nutzt visuelle Merkmale effektiv aus.
Die experimentellen Ergebnisse zeigen, dass der Effekt der Verwendung visueller Funktionen zur Verbesserung des Generators in dieser Studie sehr signifikant ist. Dieser Plug-and-Play-Ansatz ist nicht nur äußerst vielseitig, sondern verbessert auch die Generatorleistung.
Forschungsdetails
VADS besteht aus zwei Modulen: (1) Das Lernmodul für visuelles Wahrnehmungsdomänenwissen (VDKL) lernt lokale Vorurteile und globale Prioritäten visueller Merkmale, d. h. domänenvisuelles Wissen, das reines Gaußsches Rauschen ersetzt Bietet umfangreichere vorherige Rauschinformationen. (2) Das visionsorientierte semantische Aktualisierungsmodul (VOSU) lernt, wie es seinen semantischen Prototyp entsprechend der visuellen Darstellung der Probe aktualisiert, und der aktualisierte post-semantische Prototyp enthält auch domänenvisuelles Wissen.
Schließlich verband das Forschungsteam die Ausgänge der beiden Module zu einem dynamischen semantischen Prototypvektor als Bedingung des Generators. Eine große Anzahl von Experimenten zeigt, dass die VADS-Methode bei häufig verwendeten Zero-Shot-Lerndatensätzen eine deutlich bessere Leistung als bestehende Methoden erzielt und mit anderen generativen Zero-Shot-Lernmethoden kombiniert werden kann, um allgemeine Verbesserungen der Genauigkeit zu erzielen.
Im visuellen Wahrnehmungsdomänenwissens-Lernmodul (VDKL) entwarf das Forschungsteam einen visuellen Encoder (VE) und ein Domänenwissens-Lernnetzwerk (DKL). Unter anderem kodiert VE visuelle Merkmale in latente Merkmale und latente Kodierung. Durch die Verwendung von Kontrastverlust zum Trainieren von VE mithilfe gesehener Klassenbildproben während der Generator-Trainingsphase kann VE die Klassentrennbarkeit visueller Merkmale verbessern. 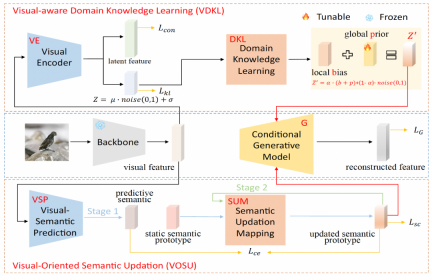
Beim Training des ZSL-Klassifikators werden die vom Generator generierten unsichtbaren visuellen Merkmale ebenfalls in VE eingegeben und die erhaltenen latenten Merkmale werden mit den generierten visuellen Merkmalen als endgültige visuelle Merkmalsprobe verknüpft. Die andere Ausgabe von VE, also die latente Codierung, bildet nach der DKL-Transformation eine lokale Abweichung b, die mit dem lernbaren globalen Prior-P und dem zufälligen Gaußschen Rauschen in domänenbezogenes visuelles Prior-Rauschen kombiniert wird, um andere generative Nullproben von Pure zu ersetzen Gaußsches Rauschen wird häufig beim Lernen als Teil der Generatorerzeugungsbedingungen verwendet.
Im Vision-Oriented Semantic Update Module (VOSU) entwarf das Forschungsteam einen visuellen semantischen Prädiktor VSP und ein semantisches Update-Mapping-Netzwerk SUM. In der Trainingsphase von VOSU verwendet VSP visuelle Bildmerkmale als Eingabe, um einen vorhergesagten semantischen Vektor zu generieren, der das visuelle Muster des Zielbilds erfassen kann. Gleichzeitig verwendet SUM den semantischen Kategorieprototyp als Eingabe, aktualisiert ihn und erhält ihn der aktualisierte semantische Prototyp, und dann werden VSP und SUM trainiert, indem der Kreuzentropieverlust zwischen dem vorhergesagten semantischen Vektor und dem aktualisierten semantischen Prototyp minimiert wird. Das VOSU-Modul kann den semantischen Prototyp basierend auf visuellen Merkmalen dynamisch anpassen, sodass der Generator bei der Synthese neuer Kategoriemerkmale auf genauere semantische Informationen auf Instanzebene zurückgreifen kann.
Im experimentellen Teil verwendete die obige Forschung drei ZSL-Datensätze, die in der Wissenschaft häufig verwendet werden: Tiere mit Attributen 2 (AWA2), SUN-Attribut (SUN) und Caltech-USCD Birds-200-2011 (CUB) für traditionell Die Hauptindikatoren für Zero-Shot-Lernen und verallgemeinertes Zero-Shot-Lernen werden umfassend mit anderen neueren repräsentativen Methoden verglichen.
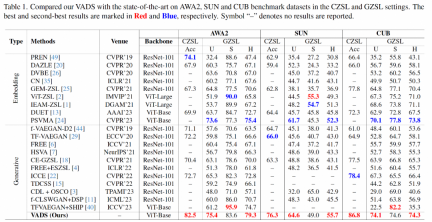
In Bezug auf den Acc-Indikator des traditionellen Zero-Shot-Lernens hat die Methode dieser Studie im Vergleich zu bestehenden Methoden erhebliche Genauigkeitsverbesserungen erzielt und liegt bei den drei Datensätzen bei 8,4 %, 10,3 % bzw. 8,4. %. Im verallgemeinerten Zero-Shot-Lernszenario nimmt die obige Forschungsmethode auch eine führende Position im harmonischen Mittelwertindex H der unsichtbaren Klasse und der Genauigkeit der gesehenen Klasse ein.
VADS-Methode kann auch mit anderen generativen Zero-Shot-Lernmethoden kombiniert werden. Nach der Kombination mit den drei Methoden CLSWGAN, TF-VAEGAN und FREE werden beispielsweise die Acc- und H-Indikatoren der drei Datensätze erheblich verbessert, und die durchschnittliche Verbesserung der drei Datensätze beträgt 7,4 %/5,9 %, 5,6 % /6,4 % und 3,3 %/4,2 %.
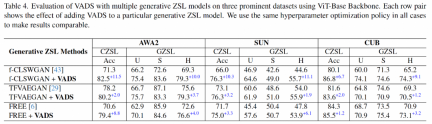
Durch die Visualisierung der vom Generator generierten visuellen Merkmale ist ersichtlich, dass die Merkmale einiger Kategorien ursprünglich miteinander verwechselt wurden, wie z. B. die sichtbare Klasse „Yellow breasted Chat“ und die unsichtbare Klasse in (b ) unten. Die beiden Arten von Merkmalen „Yellowthroat“ können in Abbildung (c) nach Verwendung der VADS-Methode klar in zwei Cluster unterteilt werden, wodurch Verwirrung beim Klassifikatortraining vermieden wird.
Kann auf die Bereiche intelligente Sicherheit und große Modelle ausgeweitet werden
Machine Heart versteht, dass das Zero-Shot-Lernen, auf das sich das oben genannte Forschungsteam konzentriert, darauf abzielt, das Modell in die Lage zu versetzen, neue Kategorien zu erkennen die in der Trainingsphase keine Bildbeispiele haben, was potenziellen Wert im Bereich der intelligenten Sicherheit hat.
Behandeln Sie zunächst neu auftretende Risiken in Sicherheitsszenarien. Da in Sicherheitsszenarien weiterhin neue Bedrohungstypen oder ungewöhnliche Verhaltensmuster auftauchen, sind diese möglicherweise nicht in früheren Trainingsdaten aufgetreten. Zero-Shot-Learning ermöglicht es Sicherheitssystemen, neue Risikoarten schnell zu erkennen und darauf zu reagieren und so die Sicherheit zu verbessern.
Zweitens: Reduzieren Sie die Abhängigkeit von Beispieldaten: Die Beschaffung ausreichender annotierter Daten zum Trainieren eines effektiven Sicherheitssystems ist teuer und zeitaufwändig. Zero-Shot-Learning reduziert die Abhängigkeit des Systems von einer großen Anzahl von Bildbeispielen und spart dadurch Forschungs- und Entwicklungskosten. .
Drittens verbessern Sie die Stabilität in dynamischen Umgebungen: Zero-Shot-Learning verwendet semantische Beschreibungen, um unsichtbare Klassenmuster zu erkennen, und ist von Natur aus widerstandsfähiger gegenüber Änderungen in der visuellen Umgebung.
Als zugrunde liegende Technologie zur Lösung von Bildklassifizierungsproblemen kann diese Technologie auch in Szenarien implementiert werden, die auf visueller Klassifizierungstechnologie basieren, z. B. Attributerkennung von Personen, Gütern, Fahrzeugen und Objekten, Verhaltenserkennung usw. Insbesondere in Szenarien, in denen neue zu identifizierende Kategorien schnell hinzugefügt werden müssen und keine Zeit zum Sammeln von Trainingsbeispielen vorhanden ist oder es schwierig ist, eine große Anzahl von Beispielen zu sammeln (z. B. zur Risikoidentifizierung), bietet die Zero-Shot-Lerntechnologie große Vorteile gegenüber traditionellen Methoden.
Hat diese Forschungstechnologie eine Referenz für die Entwicklung aktueller Großmodelle?
Forscher glauben, dass die Kernidee des generativen Zero-Shot-Lernens darin besteht, den semantischen Raum und den visuellen Merkmalsraum auszurichten, was mit den Forschungszielen visueller Sprachmodelle (wie CLIP) in aktuellen multi- modale große Modelle.
Der größte Unterschied zwischen ihnen besteht darin, dass generatives Zero-Shot-Lernen auf vordefinierte begrenzte Kategorien von Datensätzen trainiert und verwendet wird, während große Modelle in visueller Sprache durch das Erlernen von Big Data vielseitig einsetzbar sind. Semantische und visuelle Darstellungsmöglichkeiten sind nicht eingeschränkt Als Basismodell haben sie ein breiteres Anwendungsspektrum.
Wenn das Anwendungsszenario der Technologie ein bestimmtes Feld ist, können Sie das große Modell an dieses Feld anpassen und verfeinern. Arbeiten Sie dabei in die gleiche oder eine ähnliche Forschungsrichtung, die dieser Artikel theoretisch bringen kann einige nützliche Inspirationen.
Vorstellung des Autors
Hou Wenjin, Masterstudent an der Huazhong University of Science and Technology. Zu seinen Forschungsinteressen gehören Computer Vision, generative Modellierung, Wenig-Schuss-Lernen usw. Er hat diese Arbeit während seines Praktikums abgeschlossen bei Alibaba-Intime Business.
Wang Yan, Alibaba-Intime Commercial Technology Director, Algorithmusleiter des Shenzhen Xiang Intelligent Team.
Feng Xuetao, leitender Algorithmusexperte bei Alibaba-Intime Business, konzentriert sich hauptsächlich auf die Anwendung visueller und multimodaler Algorithmen im Offline-Einzelhandel und anderen Branchen.
Das obige ist der detaillierte Inhalt vonZur Verbesserung der generativen Zero-Shot-Lernfähigkeiten wurde die visuell verbesserte dynamische semantische Prototyping-Methode für CVPR 2024 ausgewählt. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

 Gemma Scope: Das Mikroskop von Google, um in den Denkprozess von AI zu blickenApr 17, 2025 am 11:55 AM
Gemma Scope: Das Mikroskop von Google, um in den Denkprozess von AI zu blickenApr 17, 2025 am 11:55 AMErforschen der inneren Funktionsweise von Sprachmodellen mit Gemma -Umfang Das Verständnis der Komplexität von KI -Sprachmodellen ist eine bedeutende Herausforderung. Die Veröffentlichung von Gemma Scope durch Google, ein umfassendes Toolkit, bietet Forschern eine leistungsstarke Möglichkeit, sich einzuschütteln
 Wer ist ein Business Intelligence Analyst und wie kann man einer werden?Apr 17, 2025 am 11:44 AM
Wer ist ein Business Intelligence Analyst und wie kann man einer werden?Apr 17, 2025 am 11:44 AMErschließung des Geschäftserfolgs: Ein Leitfaden zum Analyst für Business Intelligence -Analyst Stellen Sie sich vor, Rohdaten verwandeln in umsetzbare Erkenntnisse, die das organisatorische Wachstum vorantreiben. Dies ist die Macht eines Business Intelligence -Analysts (BI) - eine entscheidende Rolle in Gu
 Wie füge ich eine Spalte in SQL hinzu? - Analytics VidhyaApr 17, 2025 am 11:43 AM
Wie füge ich eine Spalte in SQL hinzu? - Analytics VidhyaApr 17, 2025 am 11:43 AMSQL -Änderungstabellanweisung: Dynamisches Hinzufügen von Spalten zu Ihrer Datenbank Im Datenmanagement ist die Anpassungsfähigkeit von SQL von entscheidender Bedeutung. Müssen Sie Ihre Datenbankstruktur im laufenden Flug anpassen? Die Änderungstabelleerklärung ist Ihre Lösung. Diese Anleitung Details Hinzufügen von Colu
 Business Analyst vs. Data AnalystApr 17, 2025 am 11:38 AM
Business Analyst vs. Data AnalystApr 17, 2025 am 11:38 AMEinführung Stellen Sie sich ein lebhaftes Büro vor, in dem zwei Fachleute an einem kritischen Projekt zusammenarbeiten. Der Business Analyst konzentriert sich auf die Ziele des Unternehmens, die Ermittlung von Verbesserungsbereichen und die strategische Übereinstimmung mit Markttrends. Simu
 Was sind Count und Counta in Excel? - Analytics VidhyaApr 17, 2025 am 11:34 AM
Was sind Count und Counta in Excel? - Analytics VidhyaApr 17, 2025 am 11:34 AMExcel -Datenzählung und -analyse: Detaillierte Erläuterung von Count- und Counta -Funktionen Eine genaue Datenzählung und -analyse sind in Excel kritisch, insbesondere bei der Arbeit mit großen Datensätzen. Excel bietet eine Vielzahl von Funktionen, um dies zu erreichen. Die Funktionen von Count- und Counta sind wichtige Instrumente zum Zählen der Anzahl der Zellen unter verschiedenen Bedingungen. Obwohl beide Funktionen zum Zählen von Zellen verwendet werden, sind ihre Designziele auf verschiedene Datentypen ausgerichtet. Lassen Sie uns mit den spezifischen Details der Count- und Counta -Funktionen ausgrenzen, ihre einzigartigen Merkmale und Unterschiede hervorheben und lernen, wie Sie sie in der Datenanalyse anwenden. Überblick über die wichtigsten Punkte Graf und Cou verstehen
 Chrome ist hier mit KI: Tag zu erleben, täglich etwas Neues !!Apr 17, 2025 am 11:29 AM
Chrome ist hier mit KI: Tag zu erleben, täglich etwas Neues !!Apr 17, 2025 am 11:29 AMDie KI -Revolution von Google Chrome: Eine personalisierte und effiziente Browsing -Erfahrung Künstliche Intelligenz (KI) verändert schnell unser tägliches Leben, und Google Chrome leitet die Anklage in der Web -Browsing -Arena. Dieser Artikel untersucht die Exciti
 Die menschliche Seite von Ai: Wohlbefinden und VierfacheApr 17, 2025 am 11:28 AM
Die menschliche Seite von Ai: Wohlbefinden und VierfacheApr 17, 2025 am 11:28 AMImpacting Impact: Das vierfache Endergebnis Zu lange wurde das Gespräch von einer engen Sicht auf die Auswirkungen der KI dominiert, die sich hauptsächlich auf das Gewinn des Gewinns konzentrierte. Ein ganzheitlicherer Ansatz erkennt jedoch die Vernetzung von BU an
 5 verwendende Anwendungsfälle für Quantum Computing, über die Sie wissen solltenApr 17, 2025 am 11:24 AM
5 verwendende Anwendungsfälle für Quantum Computing, über die Sie wissen solltenApr 17, 2025 am 11:24 AMDie Dinge bewegen sich stetig zu diesem Punkt. Die Investition, die in Quantendienstleister und Startups einfließt, zeigt, dass die Industrie ihre Bedeutung versteht. Und eine wachsende Anzahl realer Anwendungsfälle entsteht, um seinen Wert zu demonstrieren


Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

EditPlus chinesische Crack-Version
Geringe Größe, Syntaxhervorhebung, unterstützt keine Code-Eingabeaufforderungsfunktion

WebStorm-Mac-Version
Nützliche JavaScript-Entwicklungstools

Sicherer Prüfungsbrowser
Safe Exam Browser ist eine sichere Browserumgebung für die sichere Teilnahme an Online-Prüfungen. Diese Software verwandelt jeden Computer in einen sicheren Arbeitsplatz. Es kontrolliert den Zugriff auf alle Dienstprogramme und verhindert, dass Schüler nicht autorisierte Ressourcen nutzen.

SublimeText3 Englische Version
Empfohlen: Win-Version, unterstützt Code-Eingabeaufforderungen!

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

