
Heim >Technologie-Peripheriegeräte >KI >Apples großes Modell MM1 kommt auf den Markt: 30 Milliarden Parameter, multimodal, MoE-Architektur, mehr als die Hälfte der Autoren sind Chinesen
Apples großes Modell MM1 kommt auf den Markt: 30 Milliarden Parameter, multimodal, MoE-Architektur, mehr als die Hälfte der Autoren sind Chinesen

- 王林nach vorne
- 2024-03-15 14:43:21757Durchsuche
Seit diesem Jahr hat Apple offensichtlich seinen Schwerpunkt und seine Investitionen in generative künstliche Intelligenz (GenAI) erhöht. Auf der jüngsten Apple-Aktionärsversammlung sagte Apple-CEO Tim Cook, dass das Unternehmen in diesem Jahr erhebliche Fortschritte im Bereich GenAI erzielen will. Darüber hinaus gab Apple bekannt, dass es sein 10-jähriges Autobauprojekt aufgeben würde, was dazu führte, dass einige Teammitglieder, die ursprünglich im Automobilbau tätig waren, begannen, in den GenAI-Bereich zu wechseln.
Durch diese Initiativen hat Apple der Außenwelt seine Entschlossenheit gezeigt, GenAI zu stärken. Derzeit haben GenAI-Technologie und -Produkte im multimodalen Bereich große Aufmerksamkeit erregt, insbesondere Sora von OpenAI. Apple hofft natürlich auf einen Durchbruch in diesem Bereich.
In einem gemeinsam verfassten Forschungspapier „MM1: Methods, Analysis & Insights from Multimodal LLM Pre-training“ veröffentlichte Apple seine Forschungsergebnisse basierend auf multimodalem Pre-Training und startete eine Bibliothek mit bis zu 30B parametrischen multimodalen LLM-Serien Modell.

Papieradresse: https://arxiv.org/pdf/2403.09611.pdf
Im Rahmen der Recherche führte das Team eine ausführliche Diskussion über die Kritikalität verschiedener Architekturkomponenten und die Datenauswahl. Durch sorgfältige Auswahl von Bildkodierern, visuellen Sprachkonnektoren und verschiedenen Vortrainingsdaten fassten sie einige wichtige Designrichtlinien zusammen. Im Einzelnen umfassen die Hauptbeiträge dieser Studie die folgenden Aspekte.
Zunächst führten die Forscher kleine Ablationsexperimente zu Modellarchitekturentscheidungen und zur Datenauswahl vor dem Training durch und entdeckten mehrere interessante Trends. Die Bedeutung der Modellierungsdesignaspekte liegt in der folgenden Reihenfolge: Bildauflösung, Verlust und Kapazität des visuellen Encoders sowie Vortrainingsdaten des visuellen Encoders.
Zweitens verwendeten die Forscher drei verschiedene Arten von Pre-Training-Daten: Bildunterschriften, verschachtelter Bildtext und reine Textdaten. Sie fanden heraus, dass interleaved und nur Text-Trainingsdaten sehr wichtig sind, wenn es um die Leistung mit wenigen Aufnahmen und nur mit Text geht, während für die Leistung mit null Aufnahmen Untertiteldaten am wichtigsten sind. Diese Trends bleiben auch nach der überwachten Feinabstimmung (SFT) bestehen, was darauf hindeutet, dass die während des Vortrainings getroffenen Leistungs- und Modellierungsentscheidungen nach der Feinabstimmung erhalten bleiben.
Schließlich bauten Forscher MM1, eine multimodale Modellreihe mit Parametern von bis zu 30 Milliarden (andere sind 3 Milliarden und 7 Milliarden), die aus dichten Modellen und Varianten gemischter Experten (MoE) besteht Um SOTA in Metriken vor dem Training zu erreichen, behält es auch die Wettbewerbsleistung bei, nachdem eine überwachte Feinabstimmung anhand einer Reihe vorhandener multimodaler Benchmarks durchgeführt wurde.
Das vorab trainierte Modell MM1 schneidet bei Untertiteln und Frage-und-Antwort-Aufgaben in Szenarien mit wenigen Aufnahmen hervorragend ab und übertrifft Emu2, Flamingo und IDEFICS. MM1 zeigt nach überwachter Feinabstimmung auch eine starke Wettbewerbsfähigkeit bei 12 multimodalen Benchmarks.
Dank des groß angelegten multimodalen Vortrainings weist MM1 eine gute Leistung bei der Kontextvorhersage, der Argumentation mehrerer Bilder und der Gedankenkette auf. In ähnlicher Weise zeigt MM1 nach der Abstimmung der Anweisungen starke Lernfähigkeiten mit wenigen Schüssen.


Methodenübersicht: Das Geheimnis des Aufbaus von MM1
Der Aufbau eines leistungsstarken MLLM (Multimodal Large Language Model, multimodales großes Sprachmodell) ist eine äußerst praktische Aufgabe. Obwohl der Architekturentwurf und der Trainingsprozess auf hoher Ebene klar sind, sind die spezifischen Implementierungsmethoden nicht immer offensichtlich. In dieser Arbeit beschreiben die Forscher detailliert die Ablationen, die zum Aufbau von Hochleistungsmodellen durchgeführt werden. Sie untersuchten drei Hauptrichtungen für Designentscheidungen:
- Architektur: Die Forscher untersuchten verschiedene vorab trainierte Bild-Encoder und untersuchten verschiedene Methoden zur Verbindung von LLMs mit diesen Encodern.
- Daten: Die Forscher betrachteten verschiedene Arten von Daten und ihre relativen Mischungsgewichte.
- Trainingsverfahren: Die Forscher untersuchten, wie MLLM trainiert wird, einschließlich Hyperparametern und welche Teile des Modells wann trainiert wurden.
Ablationseinstellungen
Da das Training großer MLLM viele Ressourcen verbraucht, haben die Forscher vereinfachte Ablationseinstellungen übernommen. Die Grundkonfiguration der Ablation ist wie folgt:
- Bildkodierer: Das mit CLIP-Verlust auf DFN-5B und VeCap-300M trainierte ViT-L/14-Modell hat eine Bildgröße von 336×336.
- Visual Language Connector: C-Abstractor, enthält 144 Bild-Tokens.
- Daten vor dem Training: gemischte Untertitelbilder (45 %), verschachtelte Bildtextdokumente (45 %) und reine Textdaten (10 %).
- Sprachmodell: 1.2B Transformer Decoder Sprachmodell.
Um verschiedene Designentscheidungen zu bewerten, verwendeten die Forscher die Leistung von Zero-Shot und Few-Shot (4 und 8 Stichproben) bei verschiedenen VQA- und Bildbeschreibungsaufgaben: COCO Captioning, NoCaps, TextCaps, VQAv2, TextVQA, VizWiz, GQA und OK-VQA.
Modellarchitektur-Ablationsexperiment
Die Forscher analysierten die Komponenten, die es LLM ermöglichen, visuelle Daten zu verarbeiten. Konkret untersuchten sie (1) wie man visuelle Encoder optimal vortrainiert und (2) wie man visuelle Merkmale mit dem Raum von LLMs verbindet (siehe Abbildung 3 links).
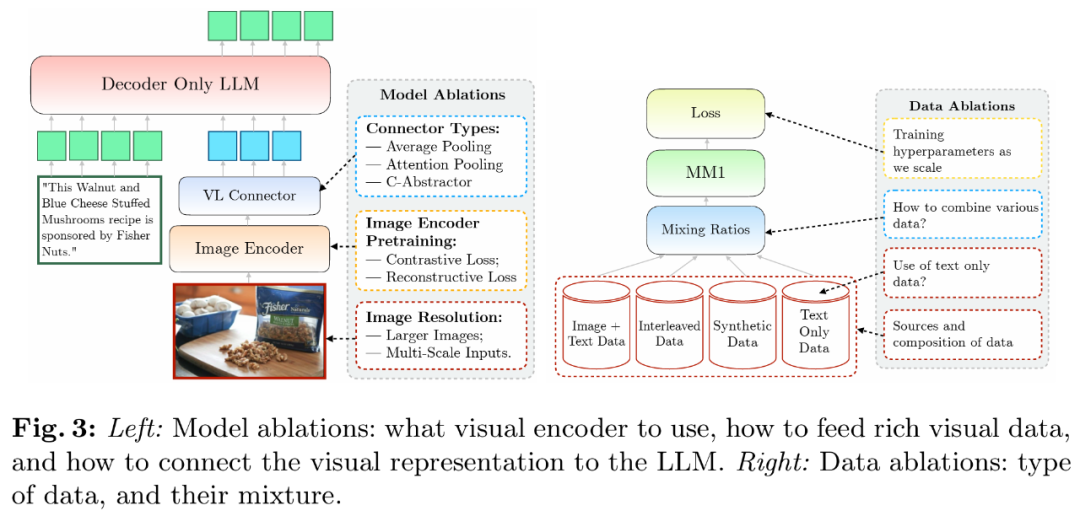
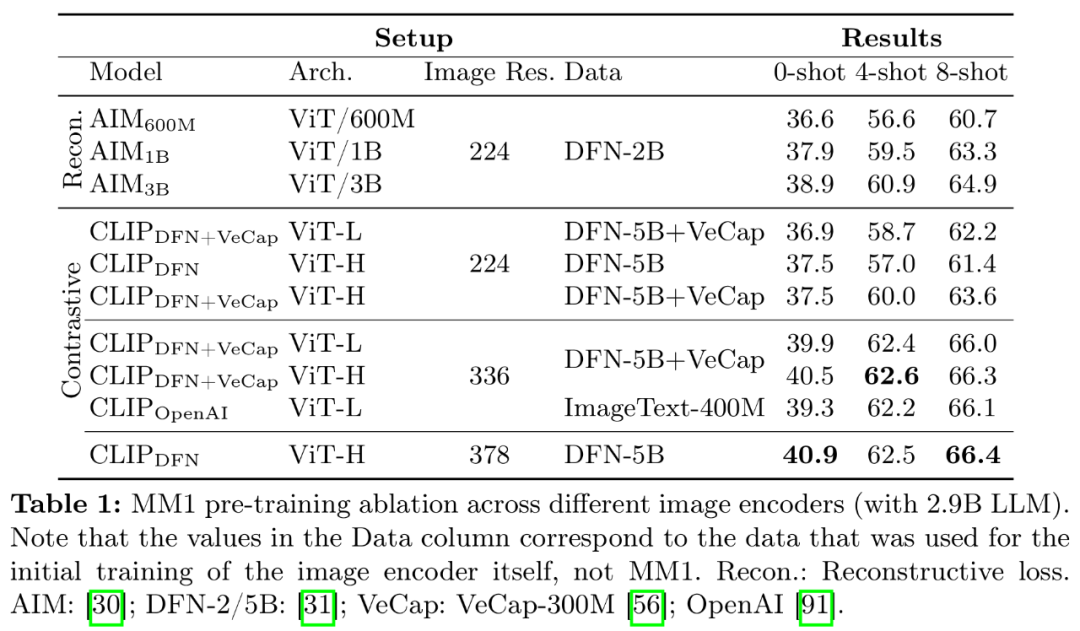
- Bild-Encoder-Vorschulung. In diesem Prozess haben die Forscher vor allem die Bedeutung der Bildauflösung und der Ziele vor dem Training des Bild-Encoders vernachlässigt. Es ist zu beachten, dass die Forscher im Gegensatz zu anderen Ablationsexperimenten 2,9 B LLM (anstelle von 1,2 B) verwendeten, um eine ausreichende Kapazität für die Verwendung einiger größerer Bildkodierer sicherzustellen.
- Encoder-Erfahrung: Die Bildauflösung hat den größten Einfluss, gefolgt von der Modellgröße und der Zusammensetzung der Trainingsdaten. Wie in Tabelle 1 gezeigt, verbessert die Erhöhung der Bildauflösung von 224 auf 336 alle Metriken für alle Architekturen um etwa 3 %. Durch Erhöhen der Modellgröße von ViT-L auf ViT-H werden die Parameter verdoppelt, der Leistungsgewinn ist jedoch bescheiden und beträgt typischerweise weniger als 1 %. Schließlich verbessert das Hinzufügen von VeCap-300M, einem Datensatz mit synthetischen Untertiteln, die Leistung in Szenarien mit wenigen Aufnahmen um mehr als 1 %.
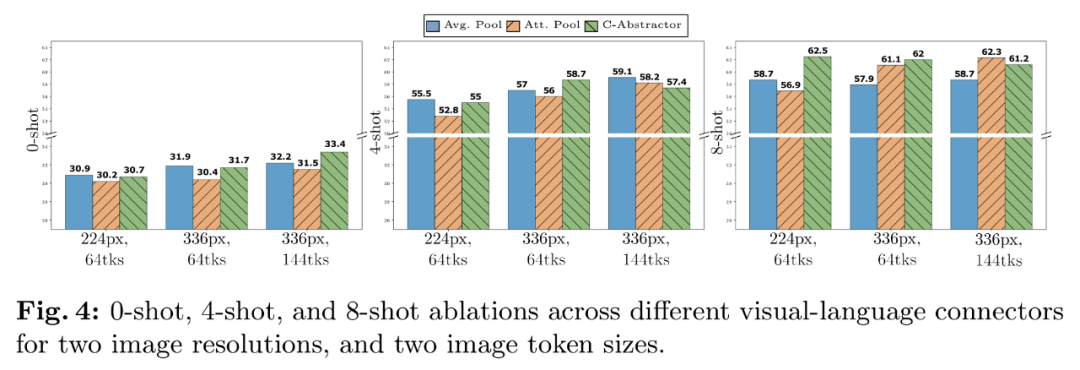
- Visuelle Sprachanschlüsse und Bildauflösung. Das Ziel dieser Komponente besteht darin, visuelle Darstellungen in den LLM-Raum umzuwandeln. Da es sich bei dem Bildencoder um ViT handelt, ist seine Ausgabe entweder eine einzelne Einbettung oder ein Satz gitterförmig angeordneter Einbettungen, die Eingabebildsegmenten entsprechen. Daher muss die räumliche Anordnung der Bild-Token in die sequentielle Anordnung von LLM umgewandelt werden. Gleichzeitig muss die eigentliche Bild-Token-Darstellung auch dem Worteinbettungsraum zugeordnet werden.
- VL-Connector-Erfahrung: Die Anzahl der visuellen Token und die Bildauflösung sind am wichtigsten, während der Typ des VL-Connectors kaum Einfluss hat. Wie in Abbildung 4 dargestellt, steigen mit zunehmender Anzahl visueller Token oder/und Bildauflösung die Erkennungsraten von Nullproben und wenigen Proben.
Experiment zur Datenablation vor dem Training
Im Allgemeinen ist das Training des Modells in zwei Phasen unterteilt: Vortraining und Anweisungsoptimierung. Die erste Stufe verwendet Daten im Netzwerkmaßstab, während die zweite Stufe missionsspezifische kuratierte Daten verwendet. Das Folgende konzentriert sich auf die Vortrainingsphase dieses Artikels und beschreibt die Datenauswahl des Forschers (Abbildung 3 rechts).
Es gibt zwei Arten von Daten, die üblicherweise zum Trainieren von MLLM verwendet werden: Bildunterschriftendaten, die aus Beschreibungen von Bild- und Textpaaren bestehen, und verschachtelte Bild-Text-Dokumente aus dem Internet. Tabelle 2 ist die vollständige Liste der Datensätze:

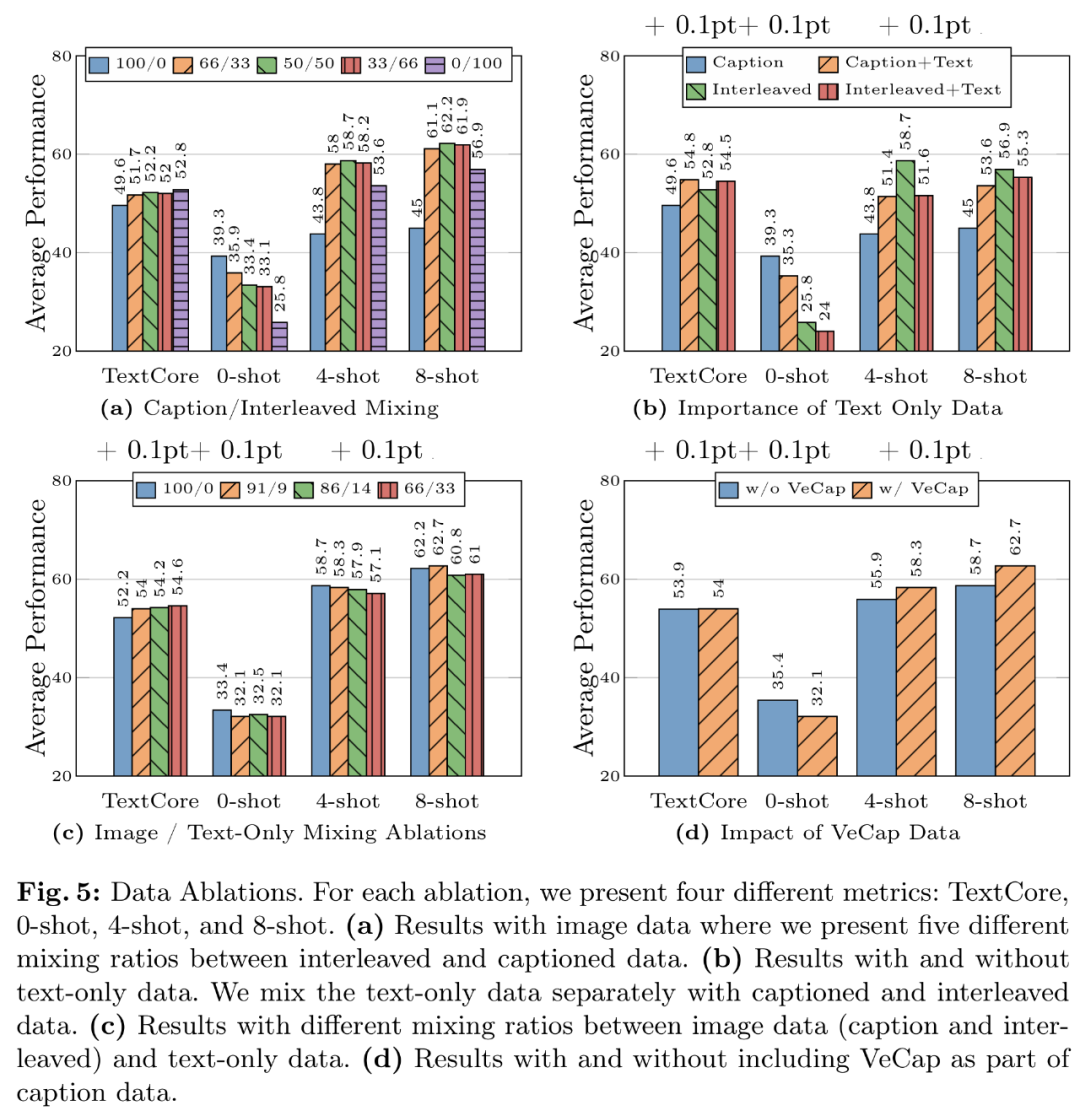
- Datenerfahrung 1: Interleaved-Daten tragen zur Verbesserung der Leistung bei wenigen Samples und reinem Text bei, während Untertiteldaten die Leistung bei Zero-Samples verbessern können. Abbildung 5a zeigt die Ergebnisse für verschiedene Kombinationen von verschachtelten und untertitelten Daten.
- Datenerfahrung 2: Klartextdaten tragen zur Verbesserung der Leistung bei wenigen Stichproben und Klartext bei. Wie in Abbildung 5b dargestellt, verbessert die Kombination von Klartextdaten und Untertiteldaten die Leistung bei wenigen Aufnahmen.
- Datenlektion 3: Mischen Sie Bild- und Textdaten sorgfältig, um die beste multimodale Leistung zu erzielen und eine starke Textleistung beizubehalten. In Abbildung 5c werden verschiedene Mischverhältnisse zwischen Bilddaten (Titel und Interlaced) und Nur-Text-Daten ausprobiert.
- Datenerfahrung 4: Synthetische Daten helfen beim Lernen mit wenigen Schüssen. Wie in Abbildung 5d dargestellt, verbessern synthetische Daten die Leistung des Wenig-Schuss-Lernens erheblich, mit absoluten Werten von 2,4 % bzw. 4 %.
Endgültiges Modell und Trainingsmethode
Die Forscher sammelten frühere Ablationsergebnisse und legten das endgültige Rezept für das multimodale Vortraining MM1 fest:
- Bildkodierer: Berücksichtigung der Bildauflösung Aufgrund von Aufgrund der Bedeutung der Rate verwendeten die Forscher das ViT-H-Modell mit einer Auflösung von 378 x 378 Pixel und das CLIP-Ziel für das Vortraining auf DFN-5B.
- Visual Language Connector: Da die Anzahl der visuellen Token am wichtigsten ist In der Studie verwendete der Autor einen VL-Connector mit 144 Token. Die tatsächliche Architektur scheint weniger wichtig zu sein, und der Forscher hat sich für C-Abstract entschieden -Text-Interleaved-Dokument, 45 % Bild-Text-Dokumente und 10 % reine Textdokumente.
- Um die Leistung des Modells zu verbessern, erweiterten die Forscher die Größe von LLM auf die Parameter 3B, 7B und 30B. Alle Modelle wurden mit einer Stapelgröße von 512 Sequenzen mit einer Sequenzlänge von 4096, maximal 16 Bildern pro Sequenz und einer Auflösung von 378 × 378 vollständig vorab trainiert. Alle Modelle wurden mit dem AXLearn-Framework trainiert.
Sie führten eine Rastersuche nach Lernraten im kleinen Maßstab, 9M, 85M, 302M und 1,2B, durch und verwendeten dabei lineare Regression im Protokollraum, um Änderungen von kleineren zu größeren Modellen abzuleiten (siehe Abbildung 6). Das Ergebnis ist die Vorhersage der optimalen Spitzenlernrate η angesichts der Anzahl der (nicht eingebetteten) Parameter N:
erweitert durch Mix of Experts (MoE). In Experimenten untersuchten die Forscher weiter Möglichkeiten, das dichte Modell zu erweitern, indem sie mehr Experten zur FFN-Schicht des Sprachmodells hinzufügten. 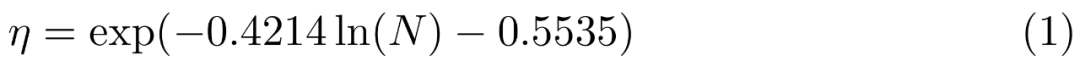
Um ein dichtes Modell in MoE zu konvertieren, ersetzen Sie einfach den dichten Sprachdecoder durch einen MoE-Sprachdecoder. Um MoE zu trainieren, verwendeten die Forscher dieselben Trainingshyperparameter und dieselben Trainingseinstellungen wie Dense Backbone 4, einschließlich Trainingsdaten und Trainingstokens.
Im Hinblick auf die Ergebnisse des multimodalen Vortrainings bewerteten die Forscher die vorab trainierten Modelle hinsichtlich Obergrenze und VQA-Aufgaben mit entsprechenden Eingabeaufforderungen. In Tabelle 3 werden die Ergebnisse bei Nullstichproben und wenigen Stichproben ausgewertet:
Ergebnisse der überwachten Feinabstimmung 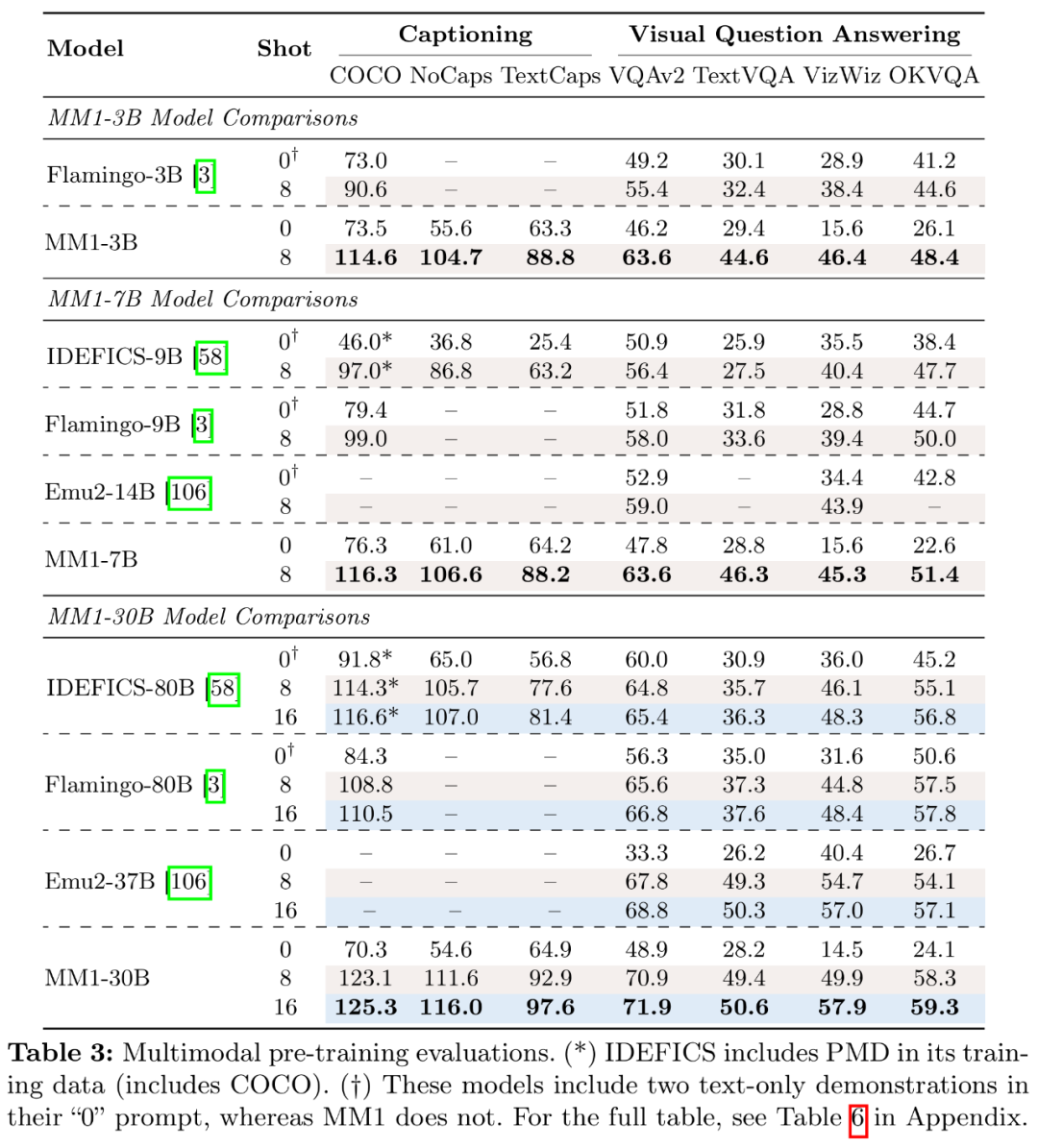
Schließlich stellten die Forscher das Experiment zur überwachten Feinabstimmung (SFT) vor, das zusätzlich zu den vorab trainierten Experimenten trainiert wurde Modell.
Sie folgten LLaVA-1.5 und LLaVA-NeXT und sammelten etwa 1 Million SFT-Proben aus verschiedenen Datensätzen. Da eine intuitiv höhere Bildauflösung zu einer besseren Leistung führt, haben die Forscher auch die auf hohe Auflösung erweiterte SFT-Methode übernommen.
Die Ergebnisse der überwachten Feinabstimmung sind wie folgt:
Tabelle 4 zeigt den Vergleich mit SOTA, „-Chat“ stellt das MM1-Modell nach der überwachten Feinabstimmung dar.
Zuallererst übertreffen MM1-3B-Chat und MM1-7B-Chat im Durchschnitt alle aufgeführten Modelle derselben Größe. MM1-3B-Chat und MM1-7B-Chat schneiden besonders gut bei VQAv2, TextVQA, ScienceQA, MMBench und aktuellen Benchmarks (MMMU und MathVista) ab.
Zweitens untersuchten die Forscher zwei MoE-Modelle: 3B-MoE (64 Experten) und 6B-MoE (32 Experten). Das MoE-Modell von Apple erzielte in fast allen Benchmarks eine bessere Leistung als das dichte Modell. Dies zeigt das enorme Potenzial für den weiteren Ausbau des MoE.
Drittens schneidet MM1-30B-Chat beim Modell der Größe 30B bei TextVQA, SEED und MMMU besser ab als Emu2-Chat37B und CogVLM-30B. Auch im Vergleich zu LLaVA-NeXT erreicht MM1 eine konkurrenzfähige Gesamtleistung.
Allerdings unterstützt LLaVA-NeXT weder Multi-Image-Inferenz noch Wenig-Shot-Hinweise, da jedes Bild als 2880 an LLM gesendete Token dargestellt wird, während die Gesamtzahl der Token in MM1 nur 720 beträgt. Dies schränkt bestimmte Anwendungen mit mehreren Bildern ein.
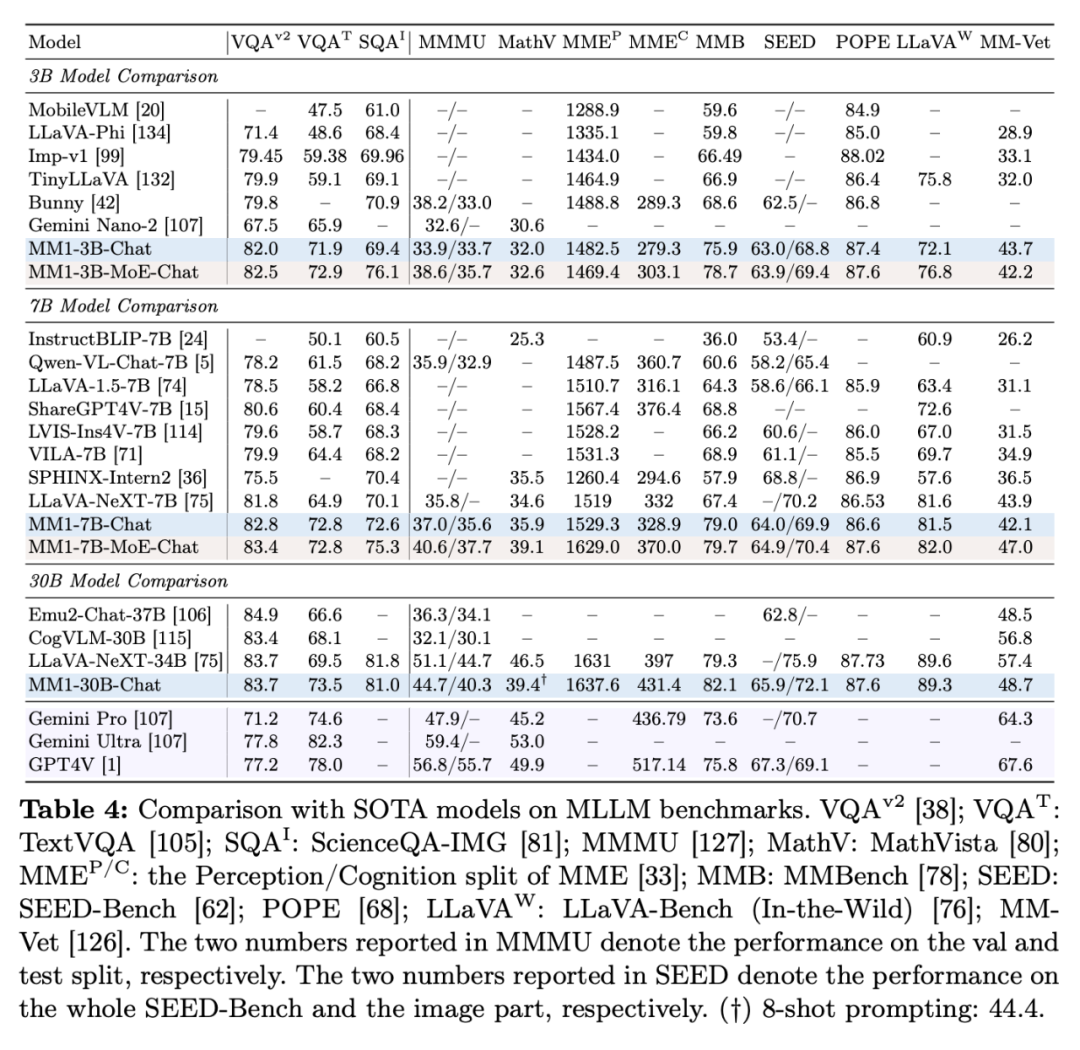
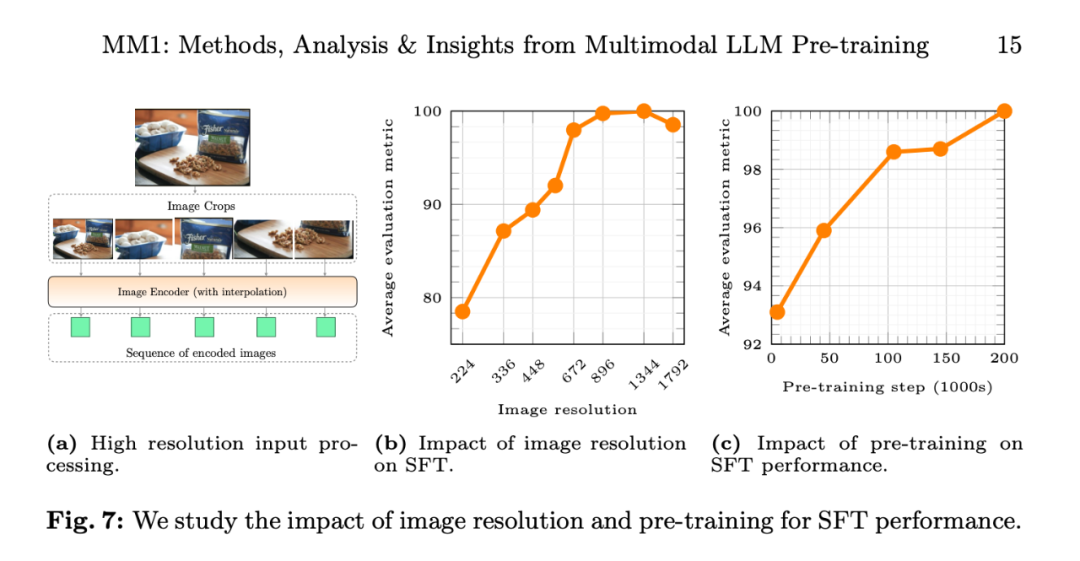
Abbildung 7b zeigt den Einfluss der Eingabebildauflösung auf die durchschnittliche Leistung der SFT-Bewertungsmetrik, und Abbildung 7c zeigt, dass sich die Leistung des Modells mit zunehmenden Daten vor dem Training weiter verbessert.
Der Einfluss der Bildauflösung. Abbildung 7b zeigt den Einfluss der Eingabebildauflösung auf die durchschnittliche Leistung der SFT-Bewertungsmetrik.
Auswirkungen des Vortrainings: Abbildung 7c zeigt, dass sich die Leistung des Modells mit zunehmenden Daten vor dem Training weiter verbessert.
Weitere Forschungsdetails finden Sie im Originalpapier.
Das obige ist der detaillierte Inhalt vonApples großes Modell MM1 kommt auf den Markt: 30 Milliarden Parameter, multimodal, MoE-Architektur, mehr als die Hälfte der Autoren sind Chinesen. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Was soll ich tun, wenn Win10 keine Airpods finden kann?
- Welches Farbmodell wird von Computermonitoren verwendet?
- So ändern Sie UL-Text in CSS in eine horizontale Anordnung
- Was sind die gängigen Softwareentwicklungsmodelle?
- Wie unterteilt der IEEE802-Standard das hierarchische Modell des lokalen Netzwerks?