
Heim >Technologie-Peripheriegeräte >KI >Entwickelt für das Training von Llama 3, Meta 49.000 Details zum H100-Cluster bekannt gegeben
Entwickelt für das Training von Llama 3, Meta 49.000 Details zum H100-Cluster bekannt gegeben

- PHPznach vorne
- 2024-03-15 11:30:111296Durchsuche
Generative große Modelle haben zu großen Veränderungen im Bereich der künstlichen Intelligenz geführt. Obwohl die Hoffnung der Menschen auf die Verwirklichung allgemeiner künstlicher Intelligenz (AGI) zunimmt, wird auch die erforderliche Rechenleistung für das Training und den Einsatz großer Modelle immer größer.
Meta hat gerade die Einführung von zwei 24k-GPU-Clustern (insgesamt 49152 H100) angekündigt und markiert damit Metas große Investition in die Zukunft der künstlichen Intelligenz.
Dies ist Teil des ehrgeizigen Infrastrukturplans von Meta. Bis Ende 2024 plant Meta, seine Infrastruktur auf 350.000 NVIDIA H100-GPUs zu erweitern und damit die Rechenleistung von fast 600.000 H100 zu erreichen. Meta ist bestrebt, seine Infrastruktur kontinuierlich zu erweitern, um den zukünftigen Anforderungen gerecht zu werden.
Meta betonte: „Wir unterstützen entschieden Open Computing und Open-Source-Technologie. Wir haben diese Computing-Cluster auf der Basis von Grand Teton, OpenRack und PyTorch aufgebaut und werden weiterhin offene Innovationen in der gesamten Branche fördern. Wir werden diese nutzen.“ Computing-Ressourcencluster zum Trainieren von Lama 3. „
Turing-Award-Gewinner und Meta-Chefwissenschaftler Yann LeCun twitterte ebenfalls, um diesen Punkt hervorzuheben.
Meta teilte Details zu Hardware, Netzwerk, Speicher, Design, Leistung und Software des neuen Clusters mit, der einen hohen Durchsatz und eine hohe Zuverlässigkeit für eine Vielzahl von Workloads mit künstlicher Intelligenz bieten soll.
Cluster-Übersicht
Die langfristige Vision von Meta besteht darin, eine offene und verantwortungsvolle allgemeine künstliche Intelligenz aufzubauen, damit jeder sie umfassend nutzen und davon profitieren kann.
Im Jahr 2022 teilte Meta erstmals Details eines AI Research Super Cluster (RSC) mit, das mit 16.000 NVIDIA A100-GPUs ausgestattet ist. RSC spielte eine wichtige Rolle bei der Entwicklung von Llama und Llama 2 sowie bei der Entwicklung fortschrittlicher Modelle der künstlichen Intelligenz in den Bereichen Computer Vision, NLP, Spracherkennung, Bilderzeugung, Kodierung usw.
Metas neuester KI-Cluster basiert auf den Erfolgen und Lehren aus der vorherigen Phase. Meta betont sein Engagement für den Aufbau eines umfassenden Systems künstlicher Intelligenz und konzentriert sich auf die Verbesserung der Erfahrung und Arbeitseffizienz von Forschern und Entwicklern.
Die leistungsstarke Netzwerkstruktur, die in den beiden neuen Clustern verwendet wird, kombiniert mit wichtigen Speicherentscheidungen und 24576 NVIDIA Tensor Core H100-GPUs in jedem Cluster, ermöglicht es diesen beiden Clustern, größere und komplexere als das RSC-Clustermodell zu unterstützen.
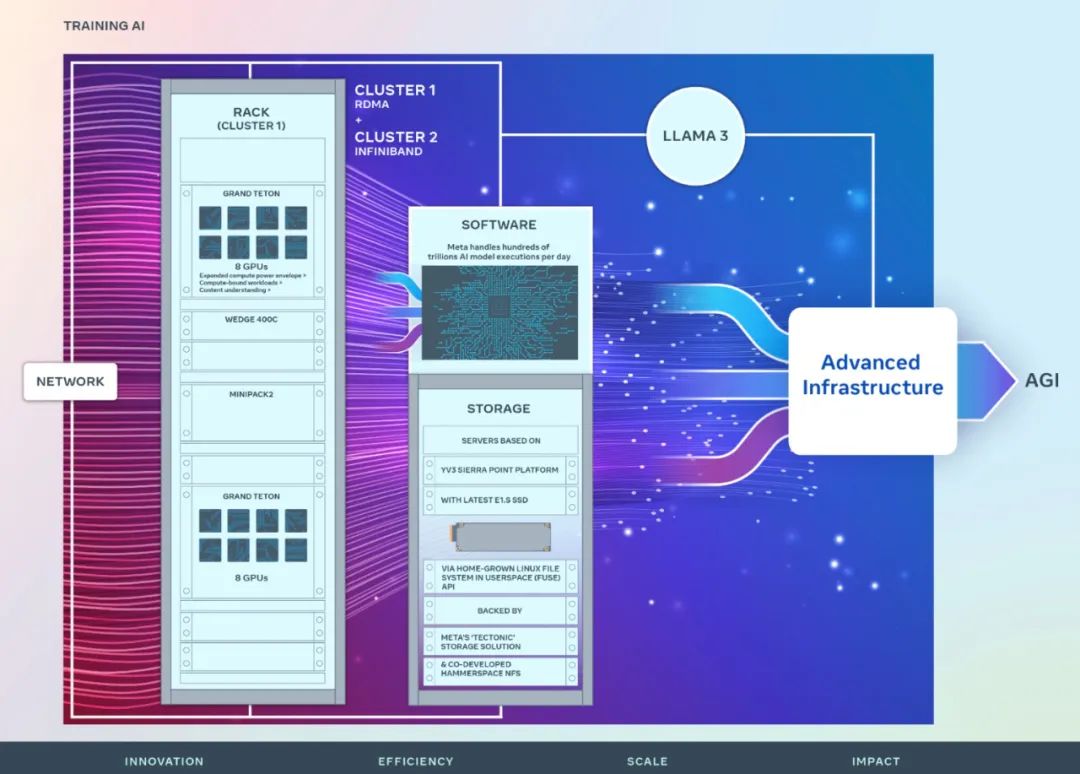
Netzwerk
Meta verarbeitet täglich Hunderte Milliarden KI-Modellläufe. Die Bereitstellung von KI-Modellen im großen Maßstab erfordert eine hochentwickelte und flexible Infrastruktur.
Um das End-to-End-Erlebnis für Forscher im Bereich der künstlichen Intelligenz zu optimieren und gleichzeitig sicherzustellen, dass das Rechenzentrum von Meta effizient arbeitet, hat Meta ein Cluster-Netzwerk-Kommunikationsprotokoll basierend auf Arista 7800 und Wedge400 sowie Minipack2 OCP-Rack-Switches entwickelt Strukturcluster, der Remote Direct Memory Access (RDMA) über Ethernet implementiert. Der andere Cluster verwendet NVIDIA Quantum2 InfiniBand Fabric. Beide Lösungen verbinden 400-Gbit/s-Endpunkte.
Diese beiden neuen Cluster können verwendet werden, um die Eignung und Skalierbarkeit verschiedener Arten von Verbindungen für groß angelegte Schulungen zu bewerten und Meta dabei zu helfen, zu verstehen, wie in Zukunft größere Cluster entworfen und aufgebaut werden können. Durch sorgfältiges Co-Design von Netzwerk, Software und Modellarchitektur konnte Meta RoCE- und InfiniBand-Cluster erfolgreich für große GenAI-Workloads nutzen, ohne dass es zu Netzwerkengpässen kam.
Compute
Beide Cluster werden mit Grand Teton erstellt, einer offenen GPU-Hardwareplattform, die intern bei Meta entwickelt wurde.
Grand Teton basiert auf mehreren Generationen von KI-Systemen und integriert Strom-, Steuerungs-, Rechen- und Fabric-Schnittstellen in einem einzigen Gehäuse für eine bessere Gesamtleistung, Signalintegrität und thermische Leistung. Es bietet schnelle Skalierbarkeit und Flexibilität in einem vereinfachten Design, sodass es schnell in Rechenzentrumsflotten bereitgestellt und einfach gewartet und erweitert werden kann.
Speicher
Speicher spielt eine wichtige Rolle im KI-Training, ist aber einer der am wenigsten diskutierten Aspekte.
Im Laufe der Zeit sind die GenAI-Trainingsbemühungen multimodaler geworden, verbrauchen große Mengen an Bild-, Video- und Textdaten und der Bedarf an Datenspeicherung ist schnell gewachsen.
Metas Speicherbereitstellung für den neuen Cluster erfüllt die Daten- und Checkpointing-Anforderungen des KI-Clusters über die Native Linux File System (FUSE) API im Benutzerbereich, die auf der verteilten Speicherlösung „Tectonic“ von Meta basiert. Diese Lösung ermöglicht es Tausenden von GPUs, Prüfpunkte synchron zu speichern und zu laden und bietet gleichzeitig den flexiblen und durchsatzstarken Speicher im Exabyte-Bereich, der zum Laden von Daten erforderlich ist.
Meta arbeitet auch mit Hammerspace zusammen, um gemeinsam die parallele Bereitstellung von Network File System (NFS) zu entwickeln und zu implementieren. Mit Hammerspace können Ingenieure interaktives Debuggen von Jobs mit Tausenden von GPUs durchführen.
Leistung
Meta Eines der Prinzipien für den Aufbau großer Cluster für künstliche Intelligenz besteht darin, gleichzeitig Leistung und Benutzerfreundlichkeit zu maximieren. Dies ist ein wichtiges Prinzip für die Erstellung erstklassiger KI-Modelle.
Meta Wenn man die Grenzen von Systemen mit künstlicher Intelligenz ausreizt, kann man die Fähigkeiten eines skalierbaren Designs am besten testen, indem man einfach ein System baut, es dann optimiert und tatsächlich testet (Simulatoren sind zwar hilfreich, können aber nur bedingt gehen). ).
In diesem Design verglich Meta die Leistung kleiner und großer Cluster, um zu verstehen, wo die Engpässe liegen. Im Folgenden wird die kollektive AllGather-Leistung (ausgedrückt als normalisierte Bandbreite auf einer Skala von 0–100) gezeigt, wenn eine große Anzahl von GPUs mit der Kommunikationsgröße mit der höchsten erwarteten Leistung miteinander kommuniziert.
Die Out-of-the-Box-Leistung großer Cluster ist im Vergleich zur optimierten Leistung kleiner Cluster zunächst schlecht und inkonsistent. Um dieses Problem zu beheben, hat Meta einige Änderungen an der Art und Weise vorgenommen, wie der interne Job-Scheduler auf die Kenntnis der Netzwerktopologie abgestimmt ist, was Latenzvorteile mit sich bringt und den Datenverkehr zu den oberen Schichten des Netzwerks minimiert.
Meta optimiert außerdem Netzwerk-Routing-Richtlinien in Verbindung mit Änderungen der NVIDIA Collective Communications Library (NCCL) für eine optimale Netzwerkauslastung. Dies trägt dazu bei, dass große Cluster die gleiche erwartete Leistung erzielen wie kleinere Cluster.
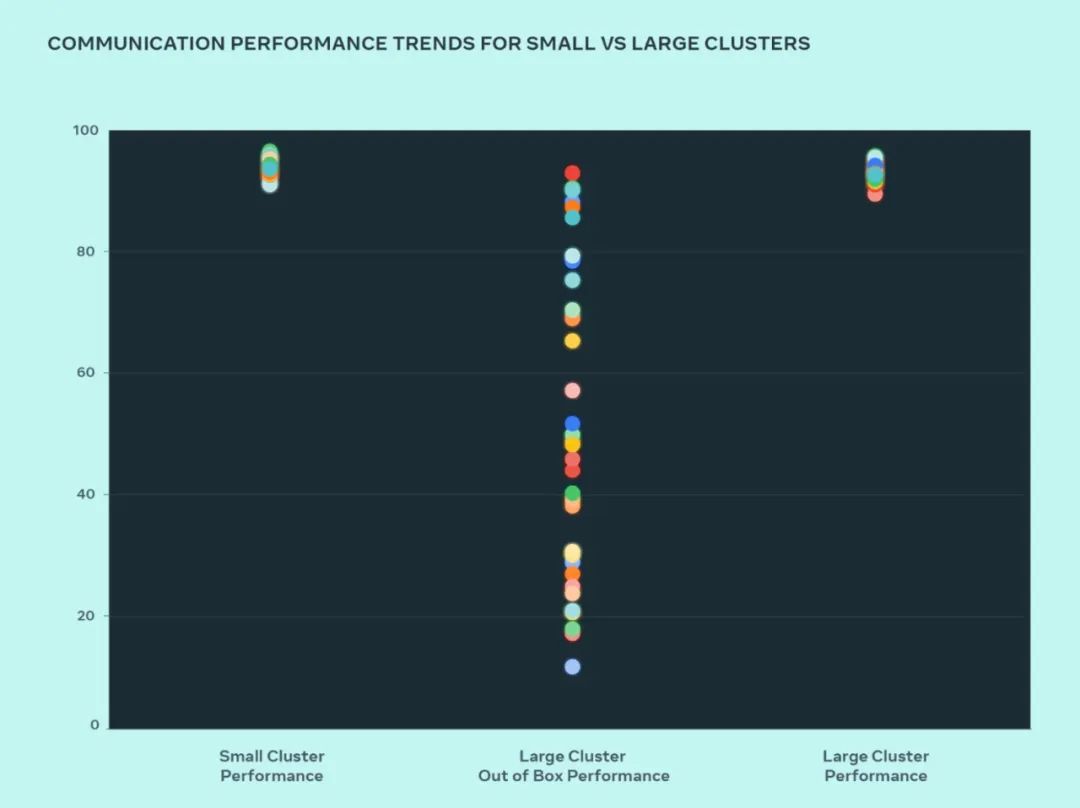
Aus der Abbildung können wir ersehen, dass die Leistung des kleinen Clusters (Gesamtkommunikationsbandbreite und -auslastung) standardmäßig über 90 % erreicht, die Leistungsauslastung des nicht optimierten großen Clusters jedoch sehr niedrig ist und bei 10 % liegt von 90 % auf 90 %. Nach der Optimierung des gesamten Systems (Software, Netzwerk usw.) stellten wir fest, dass die Leistung großer Cluster in den idealen Bereich von über 90 % zurückkehrte.
Neben Softwareänderungen an der internen Infrastruktur arbeitet Meta eng mit den Teams zusammen, die Trainingsrahmen und -modelle schreiben, um sie an die sich entwickelnde Infrastruktur anzupassen. Beispielsweise eröffnet die NVIDIA H100-GPU die Möglichkeit, mit neuen Datentypen wie 8-Bit-Gleitkomma (FP8) zu trainieren. Um die Vorteile größerer Cluster voll auszuschöpfen, sind Investitionen in zusätzliche Parallelisierungstechniken und neue Speicherlösungen erforderlich, die die Möglichkeit bieten, Prüfpunkte auf Tausenden von Ebenen so zu optimieren, dass sie in Hunderten von Millisekunden ausgeführt werden.
Meta erkennt auch, dass die Debugbarkeit eine der größten Herausforderungen beim Training im großen Maßstab ist. Die Identifizierung fehlerhafter GPUs, die das gesamte Training blockieren, ist im großen Maßstab schwierig. Meta entwickelt Tools wie asynchrones Debugging oder verteilte kollektive Flugaufzeichnungen, um die Details verteilter Schulungen offenzulegen und dabei zu helfen, auftretende Probleme schneller und einfacher zu identifizieren.
Das obige ist der detaillierte Inhalt vonEntwickelt für das Training von Llama 3, Meta 49.000 Details zum H100-Cluster bekannt gegeben. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Was ist ein Haufen? Was ist der Methodenbereich? Einführung in den Heap- und Methodenbereich im JVM-Speichermodell
- Was ist das CSS-Box-Modell?
- Zu welcher Art von Datenmodell gehört SQL Server?
- Welche sind die am häufigsten verwendeten logischen Modelle in Datenbanken?
- Wie füge ich Datenbeschriftungen in Microsoft Excel-Diagrammen hinzu und passe sie an?