
Heim >Technologie-Peripheriegeräte >KI >Wie kann man der KI viel Physikwissen vermitteln? Die Teams des EIT und der Peking-Universität schlugen das Konzept der „Bedeutung von Regeln' vor.
Wie kann man der KI viel Physikwissen vermitteln? Die Teams des EIT und der Peking-Universität schlugen das Konzept der „Bedeutung von Regeln' vor.

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2024-03-14 16:49:181329Durchsuche

Herausgeber |. ScienceAI
Deep-Learning-Modelle haben aufgrund ihrer Fähigkeit, latente Beziehungen aus riesigen Datenmengen zu lernen, einen tiefgreifenden Einfluss auf den Bereich der wissenschaftlichen Forschung gehabt. Modelle, die ausschließlich auf Daten basieren, offenbaren jedoch nach und nach ihre Grenzen, einschließlich einer übermäßigen Abhängigkeit von Daten, Einschränkungen bei den Generalisierungsfähigkeiten und Konsistenzproblemen mit der realen physischen Welt. Diese Probleme veranlassen Forscher dazu, besser interpretierbare und erklärbare Modelle zu erforschen, um die Mängel datengesteuerter Modelle auszugleichen. Daher ist die Kombination von Domänenwissen und datengesteuerten Methoden zur Erstellung von Modellen mit besserer Interpretierbarkeit und Generalisierungsfähigkeit zu einer wichtigen Richtung in der aktuellen wissenschaftlichen Forschung geworden. Diese Art von
Zum Beispiel wird das von der amerikanischen Firma OpenAI entwickelte Text-to-Video-Modell Sora für seine hervorragenden Bilderzeugungsfähigkeiten hoch gelobt und gilt als wichtiger Fortschritt auf dem Gebiet der künstlichen Intelligenz. Obwohl Sora in der Lage ist, realistische Bilder und Videos zu erzeugen, hat er immer noch einige Herausforderungen im Umgang mit den Gesetzen der Physik, wie der Schwerkraft und der Fragmentierung von Objekten. Während Sora bei der Simulation realer Szenarien erhebliche Fortschritte gemacht hat, gibt es noch Raum für Verbesserungen beim Verständnis und der genauen Simulation physikalischer Gesetze. Die Entwicklung der KI-Technologie erfordert weiterhin kontinuierliche Anstrengungen zur Verbesserung der Vollständigkeit und Genauigkeit von Modellen, um sie besser an verschiedene Situationen in der realen Welt anzupassen.
Eine mögliche Lösung dieses Problems besteht darin, menschliches Wissen in Deep-Learning-Modelle einzubeziehen. Durch die Kombination von Vorwissen und Daten kann die Generalisierungsfähigkeit des Modells verbessert werden, was zu einem Modell für „informiertes maschinelles Lernen“ führt, das physikalische Gesetze verstehen kann. Dieser Ansatz soll die Leistung und Genauigkeit des Modells verbessern und es so in die Lage versetzen, komplexe Probleme in der realen Welt besser zu bewältigen. Durch die Integration der Erfahrungen und Erkenntnisse menschlicher Experten in maschinelle Lernalgorithmen können wir intelligentere und effizientere Systeme aufbauen und so die Entwicklung und Anwendung der Technologie der künstlichen Intelligenz fördern.
Derzeit mangelt es noch an einer tiefgreifenden Erforschung des genauen Werts von Wissen im Deep Learning. Es besteht ein dringendes Problem darin, zu bestimmen, welches Vorwissen effektiv in das Modell des „Vorlernens“ integriert werden kann. Gleichzeitig kann die blinde Integration mehrerer Regeln zum Scheitern des Modells führen, was ebenfalls Aufmerksamkeit erfordert. Diese Einschränkungen stellen die eingehende Untersuchung der Beziehung zwischen Daten und Wissen vor Herausforderungen.
Als Reaktion auf dieses Problem schlug das Forschungsteam des Eastern Institute of Technology (EIT) und der Peking-Universität das Konzept der „Regelwichtigkeit“ vor und entwickelte ein Framework, das den Beitrag jeder Regel zur Vorhersagegenauigkeit des Modells genau berechnen kann. Dieses Framework deckt nicht nur die komplexe Wechselwirkung zwischen Daten und Wissen auf und bietet theoretische Anleitungen für die Einbettung von Wissen, sondern trägt auch dazu bei, den Einfluss von Wissen und Daten während des Trainingsprozesses auszugleichen. Darüber hinaus kann diese Methode auch zur Identifizierung unangemessener A-priori-Regeln eingesetzt werden, was breite Perspektiven für Forschung und Anwendung in interdisziplinären Bereichen bietet.
Diese Forschung mit dem Titel „Prior Knowledge's Impact on Deep Learning“ wurde am 8. März 2024 in der interdisziplinären Zeitschrift „Nexus“ bei Cell Press veröffentlicht. Die Forschung erhielt Aufmerksamkeit von AAAS (American Association for the Advancement of Science) und EurekAlert!

Wenn Sie Kindern Rätsel beibringen, können Sie sie entweder die Antworten durch Ausprobieren herausfinden lassen oder sie mit einigen grundlegenden Regeln und Techniken anleiten. Ebenso kann die Einbeziehung von Regeln und Techniken – etwa den Gesetzen der Physik – in das KI-Training dieses realistischer und effizienter machen. Allerdings war es für Forscher schon immer ein schwieriges Problem, den Wert dieser Regeln in der künstlichen Intelligenz einzuschätzen.
Angesichts der großen Vielfalt an Vorwissen ist die Integration von Vorwissen in Deep-Learning-Modelle eine komplexe Optimierungsaufgabe mit mehreren Zielen. Das Forschungsteam schlägt auf innovative Weise einen Rahmen vor, um die Rolle verschiedener Vorkenntnisse bei der Verbesserung von Deep-Learning-Modellen zu quantifizieren. Sie betrachten diesen Prozess als ein Spiel voller Kooperation und Wettbewerb und definieren die Bedeutung von Regeln, indem sie ihren marginalen Beitrag zu Modellvorhersagen bewerten. Zunächst werden alle möglichen Regelkombinationen (d. h. „Koalitionen“) generiert, für jede Kombination ein Modell erstellt und der mittlere quadratische Fehler berechnet.
Um die Rechenkosten zu senken, haben sie einen effizienten, auf Störungen basierenden Algorithmus eingeführt: Trainieren Sie zunächst ein vollständig datenbasiertes neuronales Netzwerk als Basismodell, fügen Sie dann jede Regelkombination einzeln für zusätzliches Training hinzu und bewerten Sie schließlich die Modellleistung auf den Testdaten. Durch den Vergleich der Leistung des Modells über alle Koalitionen mit und ohne Regel kann der marginale Beitrag dieser Regel und damit ihre Bedeutung berechnet werden.
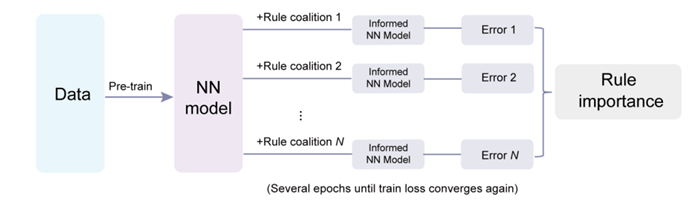
Anhand von Beispielen der Strömungsmechanik untersuchten Forscher die komplexe Beziehung zwischen Daten und Regeln. Sie fanden heraus, dass Daten und vorherige Regeln bei verschiedenen Aufgaben völlig unterschiedliche Rollen spielten. Wenn die Verteilung von Testdaten und Trainingsdaten ähnlich ist (d. h. in der Verteilung), schwächt die Zunahme des Datenvolumens die Wirkung der Regeln.
Wenn jedoch die Verteilungsähnlichkeit zwischen den Testdaten und den Trainingsdaten gering ist (d. h. außerhalb der Verteilung), wird die Bedeutung globaler Regeln hervorgehoben, während der Einfluss lokaler Regeln abgeschwächt wird. Der Unterschied zwischen diesen beiden Arten von Regeln besteht darin, dass globale Regeln (z. B. maßgebende Gleichungen) den gesamten Bereich betreffen, während lokale Regeln (z. B. Randbedingungen) nur auf bestimmte Bereiche wirken.
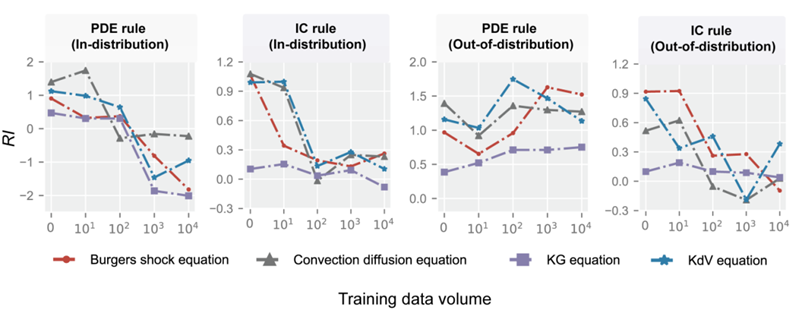
Das Forschungsteam fand durch numerische Experimente heraus, dass es drei interaktive Effekte zwischen Regeln bei der Wissenseinbettung gibt: Abhängigkeitseffekt und Synergieeffekt und Substitutionseffekt.
Abhängigkeitseffekt bedeutet, dass einige Regeln auf andere Regeln angewiesen sind, um wirksam zu sein. Der Synergieeffekt zeigt, dass die Wirkung mehrerer Regeln die Summe ihrer unabhängigen Effekte übersteigt Daten oder andere Regeln.
Diese drei Effekte treten gleichzeitig auf und werden von der Datenmenge beeinflusst. Durch die Berechnung der Regelwichtigkeit können diese Effekte klar nachgewiesen werden und liefern wichtige Hinweise für die Wissenseinbettung.
Auf der Anwendungsebene versuchte das Forschungsteam, ein Kernproblem im Prozess der Wissenseinbettung zu lösen: Wie lässt sich die Rolle von Daten und Regeln ausbalancieren, um die Einbettungseffizienz zu verbessern und unangemessenes Vorwissen auszusortieren? Während des Trainingsprozesses des Modells schlug das Team eine Strategie zur dynamischen Anpassung der Gewichtung der Regeln vor.
Konkret nimmt mit zunehmenden Trainingsiterationsschritten die Gewichtung der Regeln mit positiver Wichtigkeit allmählich zu, während die Gewichtung der Regeln mit negativer Wichtigkeit abnimmt. Diese Strategie kann die Aufmerksamkeit des Modells entsprechend den Anforderungen des Optimierungsprozesses in Echtzeit an verschiedene Regeln anpassen und so eine effizientere und genauere Wissenseinbettung erreichen.
Darüber hinaus kann die Vermittlung der Gesetze der Physik an KI-Modelle dazu führen, dass diese „für die reale Welt relevanter werden und somit eine größere Rolle in Wissenschaft und Technik spielen“. Daher bietet dieses Framework ein breites Spektrum praktischer Anwendungen in den Bereichen Ingenieurwesen, Physik und Chemie. Die Forscher optimierten nicht nur das maschinelle Lernmodell zur Lösung multivariater Gleichungen, sondern identifizierten auch genau Regeln, die die Leistung des Vorhersagemodells für die Dünnschichtchromatographieanalyse verbessern.
Experimentelle Ergebnisse zeigen, dass durch die Einbeziehung dieser effektiven Regeln die Leistung des Modells deutlich verbessert wird und der mittlere quadratische Fehler im Testdatensatz von 0,052 auf 0,036 reduziert wird (eine Reduzierung um 30,8 %). Das bedeutet, dass das Framework empirische Erkenntnisse in strukturiertes Wissen umwandeln und so die Modellleistung deutlich verbessern kann.
Im Allgemeinen trägt die genaue Einschätzung des Werts von Wissen dazu bei, realistischere KI-Modelle zu erstellen, die Sicherheit und Zuverlässigkeit zu verbessern, und ist von großer Bedeutung für die Entwicklung von Deep Learning.

Als Nächstes plant das Forschungsteam, sein Framework zu einem Plug-in-Tool zu entwickeln, das von Entwicklern künstlicher Intelligenz verwendet werden kann. Ihr ultimatives Ziel ist es, Modelle zu entwickeln, die Wissen und Regeln direkt aus Daten extrahieren und sich dann selbst verbessern können, wodurch ein geschlossenes System von der Wissensentdeckung bis zur Wissenseinbettung entsteht, das das Modell zu einem echten Wissenschaftler der künstlichen Intelligenz macht.
Link zum Papier: https://www.cell.com/nexus/fulltext/S2950-1601(24)00001-9
Das obige ist der detaillierte Inhalt vonWie kann man der KI viel Physikwissen vermitteln? Die Teams des EIT und der Peking-Universität schlugen das Konzept der „Bedeutung von Regeln' vor.. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!