

 Technologie-PeripheriegeräteKINeues Werk von Yan Shuicheng/Cheng Mingming! DiT-Training, die Kernkomponente von Sora, wird um das Zehnfache beschleunigt und Masked Diffusion Transformer V2 ist Open Source
Technologie-PeripheriegeräteKINeues Werk von Yan Shuicheng/Cheng Mingming! DiT-Training, die Kernkomponente von Sora, wird um das Zehnfache beschleunigt und Masked Diffusion Transformer V2 ist Open Source
Als eine der überzeugenden Kerntechnologien von Sora nutzt DiT Diffusion Transformer, um das generative Modell auf einen größeren Maßstab zu skalieren und so herausragende Bilderzeugungseffekte zu erzielen.
Größere Modellgrößen führen jedoch dazu, dass die Schulungskosten in die Höhe schnellen.
Das Forschungsteam von Yan Shuicheng und Cheng Mingming vom Sea AI Lab der Nankai University und dem Kunlun Wanwei 2050 Research Institute schlug auf der ICCV 2023-Konferenz ein neues Modell namens Masked Diffusion Transformer vor. Dieses Modell verwendet die Maskenmodellierungstechnologie, um das Training des Diffusion Transformers durch das Erlernen semantischer Darstellungsinformationen zu beschleunigen und SoTA-Ergebnisse im Bereich der Bilderzeugung zu erzielen. Diese Innovation bringt neue Durchbrüche bei der Entwicklung von Bilderzeugungsmodellen und bietet Forschern eine effizientere Trainingsmethode. Durch die Kombination von Fachwissen und Technologie aus verschiedenen Bereichen schlug das Forschungsteam erfolgreich eine Lösung vor, die die Trainingsgeschwindigkeit erhöht und die Generierungsergebnisse verbessert. Ihre Arbeit hat wichtige innovative Ideen zur Entwicklung des Bereichs der künstlichen Intelligenz beigetragen und nützliche Inspiration für zukünftige Forschung und Praxis geliefert , Masked Diffusion Transformer V2 hat SoTA erneut aktualisiert, die Trainingsgeschwindigkeit im Vergleich zu DiT um mehr als das Zehnfache erhöht und den ImageNet-Benchmark-Score von 1,58 erreicht.
Die neueste Version des Papiers und des Codes sind Open Source. 
Zum Beispiel hat DiT, wie im Bild oben gezeigt, gelernt, beim 50. k-ten Trainingsschritt die Haartextur eines Hundes zu erzeugen, und dann beim 200. k-ten Trainingsschritt gelernt, eines der Augen des Hundes zu erzeugen Trainingsschritt und Mund, aber ein weiteres Auge fehlte.
Selbst beim 300-km-Trainingsschritt ist die durch DiT erzeugte relative Position der beiden Ohren des Hundes nicht sehr genau.
Dieser Trainings- und Lernprozess zeigt, dass das Diffusionsmodell die semantische Beziehung zwischen verschiedenen Teilen des Objekts im Bild nicht effizient lernen kann, sondern nur die semantischen Informationen jedes Objekts unabhängig lernt. 
Wie in der Abbildung oben gezeigt, führt MDT eine Lernstrategie für die Maskenmodellierung ein und behält gleichzeitig den Diffusionstrainingsprozess bei. Durch die Maskierung des verrauschten Bildtokens verwendet MDT eine asymmetrische Diffusionstransformator-Architektur (Asymmetric Diffusion Transformer), um das maskierte Bildtoken aus dem nicht maskierten verrauschten Bildtoken vorherzusagen und so gleichzeitig die Prozesse der Maskenmodellierung und des Diffusionstrainings zu erreichen.
Während des Inferenzprozesses behält MDT weiterhin den Standardprozess der Diffusionsgenerierung bei. Das Design von MDT hilft Diffusion Transformer dabei, sowohl die Fähigkeit zum Ausdruck semantischer Informationen zu nutzen, die durch das Lernen der Maskenmodellierungsdarstellung entsteht, als auch die Fähigkeit des Diffusionsmodells, Bilddetails zu generieren.
Konkret ordnet MDT Bilder über den VAE-Encoder dem latenten Raum zu und verarbeitet sie im latenten Raum, um Rechenkosten zu sparen.
Während des Trainingsprozesses maskiert MDT zunächst einen Teil der Bild-Tokens, nachdem Rauschen hinzugefügt wurde, und sendet die verbleibenden Tokens an den Asymmetric Diffusion Transformer, um nach dem Entrauschen alle Bild-Tokens vorherzusagen.
Asymmetric Diffusion Transformer-Architektur
 Bild
Bild
Wie in der Abbildung oben gezeigt, umfasst die Asymmetric Diffusion Transformer-Architektur einen Encoder, einen Seiteninterpolator (Hilfsinterpolator) und einen Decoder.
 Bilder
Bilder
Während des Trainingsprozesses verarbeitet der Encoder nur Token, die nicht maskiert sind; während des Inferenzprozesses verarbeitet er alle Token, da es keinen Maskierungsschritt gibt.
Um sicherzustellen, dass der Decoder während der Trainings- oder Inferenzphase immer alle Token verarbeiten kann, schlugen die Forscher daher eine Lösung vor: während des Trainingsprozesses durch einen Hilfsinterpolator, der aus DiT-Blöcken besteht (wie in der Abbildung dargestellt). oben), interpolieren und prognostizieren das maskierte Token aus der Ausgabe des Encoders und entfernen es während der Inferenzphase, ohne einen Inferenz-Overhead hinzuzufügen.
MDTs Encoder und Decoder fügen globale und lokale Positionscodierungsinformationen in den Standard-DiT-Block ein, um die Vorhersage des Tokens im Maskenteil zu erleichtern. Asymmetric Diffusion Transformer V2 Prozess der Modellierung.
Dazu gehört die Integration einer langen Verknüpfung im U-Net-Stil in den Encoder und einer dichten Eingabeverknüpfung in den Decoder.
Unter diesen sendet die dichte Eingabeverknüpfung das maskierte Token, nachdem Rauschen an den Decoder hinzugefügt wurde, wobei die dem maskierten Token entsprechenden Rauschinformationen beibehalten werden, wodurch das Training des Diffusionsprozesses erleichtert wird. 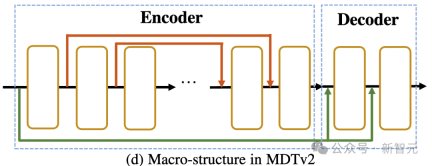
Die obige Tabelle vergleicht die Leistung von MDT und DiT unter dem ImageNet 256-Benchmark bei verschiedenen Modellgrößen.
Es ist offensichtlich, dass MDT bei allen Modellgrößen höhere FID-Werte mit weniger Schulungskosten erzielt.
Die Parameter und Inferenzkosten von MDT sind grundsätzlich die gleichen wie bei DiT, da, wie oben erwähnt, der mit DiT konsistente Standarddiffusionsprozess im MDT-Inferenzprozess weiterhin beibehalten wird. 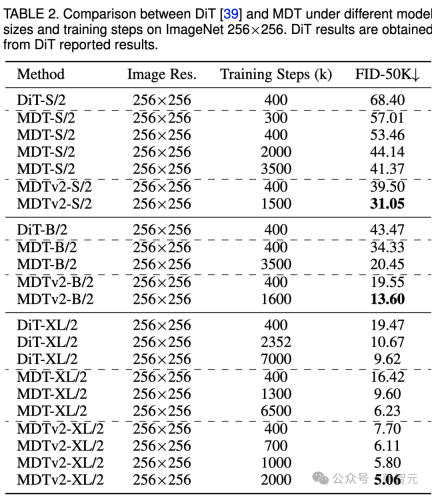
Bei kleinen Modellen erreicht MDTv2-S/2 immer noch eine deutlich bessere Leistung als DiT-S/2 mit deutlich weniger Trainingsschritten. Beispielsweise hat MDTv2 bei gleichem Training mit 400.000 Schritten einen FID-Index von 39,50, was deutlich über dem FID-Index von DiT von 68,40 liegt.
Noch wichtiger ist, dass dieses Ergebnis auch die Leistung des größeren Modells DiT-B/2 bei 400.000 Trainingsschritten übertrifft (39,50 vs. 43,47).
ImageNet 256 Benchmark-CFG-Generierungsqualitätsvergleich
 Bilder
Bilder
In der obigen Tabelle haben wir auch die Bildgenerierungsleistung von MDT mit vorhandenen Methoden unter klassifikatorfreier Anleitung verglichen.
MDT übertrifft frühere SOTA DiT und andere Methoden mit einem FID-Score von 1,79. MDTv2 verbessert die Leistung weiter und treibt den SOTA-FID-Score für die Bilderzeugung mit weniger Trainingsschritten auf einen neuen Tiefstwert von 1,58.
Ähnlich wie bei DiT beobachteten wir während des Trainings keine Sättigung des FID-Scores des Modells, während wir mit dem Training fortfuhren.
 MDT aktualisiert SoTA auf der Rangliste von PaperWithCode
MDT aktualisiert SoTA auf der Rangliste von PaperWithCode
Konvergenzgeschwindigkeitsvergleich
 Bild
Bild
Das obige Bild vergleicht 8×A100 unter dem ImageNet 6 Benchmark DiT-S/ auf GPU 2 FID Leistung von Baseline, MDT-S/2 und MDTv2-S/2 unter verschiedenen Trainingsschritten/Trainingszeiten.
Dank besserer kontextbezogener Lernfähigkeiten übertrifft MDT DiT sowohl in der Leistung als auch in der Generierungsgeschwindigkeit. Die Trainingskonvergenzgeschwindigkeit von MDTv2 ist mehr als zehnmal höher als die von DiT.
MDT ist in Bezug auf Trainingsschritte und Trainingszeit etwa dreimal schneller als DiT. MDTv2 verbessert die Trainingsgeschwindigkeit im Vergleich zu MDT um etwa das Fünffache.
Zum Beispiel zeigt MDTv2-S/2 in nur 13 Stunden (15.000 Schritte) eine bessere Leistung als DiT-S/2, dessen Training etwa 100 Stunden (1.500.000 Schritte) dauert, was zeigt, dass das Lernen der kontextuellen Darstellung wichtig ist Ein schnelleres generatives Lernen von Diffusionsmodellen ist von entscheidender Bedeutung.
Zusammenfassung und Diskussion
MDT führt im Diffusionstrainingsprozess ein MAE-ähnliches Lernschema für die Maskenmodellierungsdarstellung ein, das die Kontextinformationen von Bildobjekten verwenden kann, um die vollständigen Informationen des unvollständigen Eingabebilds zu rekonstruieren und so zu lernen Die Semantik im Bild Die Korrelation zwischen Teilen, wodurch die Qualität der Bilderzeugung und die Lerngeschwindigkeit verbessert werden.
Forscher glauben, dass die Verbesserung des semantischen Verständnisses der physischen Welt durch das Lernen visueller Repräsentationen den Simulationseffekt des generativen Modells auf die physische Welt verbessern kann. Dies deckt sich mit Soras Vision, durch generative Modelle einen physischen Weltsimulator zu bauen. Hoffentlich wird diese Arbeit weitere Arbeiten zur Vereinheitlichung von Repräsentationslernen und generativem Lernen inspirieren.
Referenz:
https://arxiv.org/abs/2303.14389
Das obige ist der detaillierte Inhalt vonNeues Werk von Yan Shuicheng/Cheng Mingming! DiT-Training, die Kernkomponente von Sora, wird um das Zehnfache beschleunigt und Masked Diffusion Transformer V2 ist Open Source. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

 Lesen des AI-Index 2025: Ist AI Ihr Freund, Feind oder Co-Pilot?Apr 11, 2025 pm 12:13 PM
Lesen des AI-Index 2025: Ist AI Ihr Freund, Feind oder Co-Pilot?Apr 11, 2025 pm 12:13 PMDer Bericht des Stanford University Institute for Human-orientierte künstliche Intelligenz bietet einen guten Überblick über die laufende Revolution der künstlichen Intelligenz. Interpretieren wir es in vier einfachen Konzepten: Erkenntnis (verstehen, was geschieht), Wertschätzung (Sehenswürdigkeiten), Akzeptanz (Gesichtsherausforderungen) und Verantwortung (finden Sie unsere Verantwortlichkeiten). Kognition: Künstliche Intelligenz ist überall und entwickelt sich schnell Wir müssen uns sehr bewusst sein, wie schnell künstliche Intelligenz entwickelt und ausbreitet. Künstliche Intelligenzsysteme verbessern sich ständig und erzielen hervorragende Ergebnisse bei mathematischen und komplexen Denktests, und erst vor einem Jahr haben sie in diesen Tests kläglich gescheitert. Stellen Sie sich vor, KI zu lösen komplexe Codierungsprobleme oder wissenschaftliche Probleme auf Graduiertenebene-seit 2023-
 Erste Schritte mit Meta Lama 3.2 - Analytics VidhyaApr 11, 2025 pm 12:04 PM
Erste Schritte mit Meta Lama 3.2 - Analytics VidhyaApr 11, 2025 pm 12:04 PMMetas Lama 3.2: Ein Sprung nach vorne in der multimodalen und mobilen KI Meta hat kürzlich Lama 3.2 vorgestellt, ein bedeutender Fortschritt in der KI mit leistungsstarken Sichtfunktionen und leichten Textmodellen, die für mobile Geräte optimiert sind. Aufbau auf dem Erfolg o
 AV -Bytes: META ' S Lama 3.2, Googles Gemini 1.5 und mehrApr 11, 2025 pm 12:01 PM
AV -Bytes: META ' S Lama 3.2, Googles Gemini 1.5 und mehrApr 11, 2025 pm 12:01 PMDie KI -Landschaft dieser Woche: Ein Wirbelsturm von Fortschritten, ethischen Überlegungen und regulatorischen Debatten. Hauptakteure wie OpenAI, Google, Meta und Microsoft haben einen Strom von Updates veröffentlicht, von bahnbrechenden neuen Modellen bis hin zu entscheidenden Verschiebungen in LE
 Die menschlichen Kosten für das Gespräch mit Maschinen: Kann sich ein Chatbot wirklich darum kümmern?Apr 11, 2025 pm 12:00 PM
Die menschlichen Kosten für das Gespräch mit Maschinen: Kann sich ein Chatbot wirklich darum kümmern?Apr 11, 2025 pm 12:00 PMDie beruhigende Illusion der Verbindung: Blühen wir in unseren Beziehungen zur KI wirklich auf? Diese Frage stellte den optimistischen Ton des "Fortschritts -Menschen mit AI) des MIT Media Lab in Frage. Während die Veranstaltung moderne EDG präsentierte
 Verständnis der Scipy Library in PythonApr 11, 2025 am 11:57 AM
Verständnis der Scipy Library in PythonApr 11, 2025 am 11:57 AMEinführung Stellen Sie sich vor, Sie sind ein Wissenschaftler oder Ingenieur, der sich mit komplexen Problemen befasst - Differentialgleichungen, Optimierungsherausforderungen oder Fourier -Analysen. Pythons Benutzerfreundlichkeit und Grafikfunktionen sind ansprechend, aber diese Aufgaben erfordern leistungsstarke Tools
 3 Methoden zum Ausführen von LLAMA 3.2 - Analytics VidhyaApr 11, 2025 am 11:56 AM
3 Methoden zum Ausführen von LLAMA 3.2 - Analytics VidhyaApr 11, 2025 am 11:56 AMMETAs Lama 3.2: Ein multimodales KI -Kraftpaket Das neueste multimodale Modell von META, Lama 3.2, stellt einen erheblichen Fortschritt in der KI dar, das ein verbessertes Sprachverständnis, eine verbesserte Genauigkeit und die überlegenen Funktionen der Textgenerierung bietet. Seine Fähigkeit t
 Automatisierung von Datenqualitätsprüfungen mit DagsterApr 11, 2025 am 11:44 AM
Automatisierung von Datenqualitätsprüfungen mit DagsterApr 11, 2025 am 11:44 AMDatenqualitätssicherung: Automatisieren von Schecks mit Dagster und großen Erwartungen Die Aufrechterhaltung einer hohen Datenqualität ist für datengesteuerte Unternehmen von entscheidender Bedeutung. Wenn Datenvolumina und Quellen zunehmen, wird die manuelle Qualitätskontrolle ineffizient und anfällig für Fehler.
 Haben Mainframes eine Rolle in der KI -Ära?Apr 11, 2025 am 11:42 AM
Haben Mainframes eine Rolle in der KI -Ära?Apr 11, 2025 am 11:42 AMMainframes: Die unbesungenen Helden der KI -Revolution Während die Server bei allgemeinen Anwendungen und mehreren Kunden übernommen werden, werden Mainframes für hochvolumige, missionskritische Aufgaben erstellt. Diese leistungsstarken Systeme sind häufig in Heavil gefunden


Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

ZendStudio 13.5.1 Mac
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Herunterladen der Mac-Version des Atom-Editors
Der beliebteste Open-Source-Editor

Dreamweaver CS6
Visuelle Webentwicklungstools

MinGW – Minimalistisches GNU für Windows
Dieses Projekt wird derzeit auf osdn.net/projects/mingw migriert. Sie können uns dort weiterhin folgen. MinGW: Eine native Windows-Portierung der GNU Compiler Collection (GCC), frei verteilbare Importbibliotheken und Header-Dateien zum Erstellen nativer Windows-Anwendungen, einschließlich Erweiterungen der MSVC-Laufzeit zur Unterstützung der C99-Funktionalität. Die gesamte MinGW-Software kann auf 64-Bit-Windows-Plattformen ausgeführt werden.

MantisBT
Mantis ist ein einfach zu implementierendes webbasiertes Tool zur Fehlerverfolgung, das die Fehlerverfolgung von Produkten unterstützen soll. Es erfordert PHP, MySQL und einen Webserver. Schauen Sie sich unsere Demo- und Hosting-Services an.

