
Heim >Technologie-Peripheriegeräte >KI >Neue Arbeit von Tian Yuandong und anderen: Durchbrechen des Speicherengpasses und Ermöglichen eines 4090 vorab trainierten 7B-Großmodells
Neue Arbeit von Tian Yuandong und anderen: Durchbrechen des Speicherengpasses und Ermöglichen eines 4090 vorab trainierten 7B-Großmodells

- 王林nach vorne
- 2024-03-08 15:46:07803Durchsuche
Meta FAIR Das Forschungsprojekt, an dem Tian Yuandong teilnahm, erhielt letzten Monat großes Lob. In ihrem Artikel „MobileLLM: Optimizing Sub-billion Parameter Language Models for On-Device Use Cases“ begannen sie zu untersuchen, wie kleine Modelle mit weniger als 1 Milliarde Parametern optimiert werden können, um das Ziel zu erreichen, große Sprachmodelle auf mobilen Geräten auszuführen .
Am 6. März veröffentlichte das Team von Tian Yuandong die neuesten Forschungsergebnisse, diesmal mit Schwerpunkt auf der Verbesserung der Effizienz des LLM-Speichers. Zum Forschungsteam gehören neben Tian Yuandong selbst auch Forscher des California Institute of Technology, der University of Texas at Austin und der CMU. Ziel dieser Forschung ist es, die Leistung des LLM-Speichers weiter zu optimieren und Unterstützung und Anleitung für die zukünftige Technologieentwicklung bereitzustellen.
Sie schlugen gemeinsam eine Trainingsstrategie namens GaLore (Gradient Low-Rank Projection) vor, die ein vollständiges Parameterlernen ermöglicht. Im Vergleich zu herkömmlichen adaptiven Methoden mit niedrigem Rang wie LoRA weist GaLore eine höhere Gedächtniseffizienz auf.
Diese Studie zeigt zum ersten Mal, dass 7B-Modelle erfolgreich auf einer Consumer-GPU mit 24 GB Speicher (z. B. NVIDIA RTX 4090) vorab trainiert werden können, ohne Modellparallelität, Checkpointing oder Offloading-Strategien zu verwenden.

Papieradresse: https://arxiv.org/abs/2403.03507
Papiertitel: GaLore: Memory-Efficient LLM Training by Gradient Low-Rank Projection
Lass uns als nächstes einen Blick darauf werfen Der Hauptinhalt des Artikels.
Derzeit haben große Sprachmodelle (LLM) in vielen Bereichen ein herausragendes Potenzial gezeigt, aber wir müssen uns auch einem echten Problem stellen, nämlich dass das Vortraining und die Feinabstimmung von LLM nicht nur eine große Menge an Rechenressourcen erfordern. erfordern aber auch viel Speicherunterstützung.
Der Speicherbedarf von LLM umfasst nicht nur Parameter in Milliardenhöhe, sondern auch Gradienten und Optimiererzustände (wie Gradientenimpuls und Varianz in Adam), die größer sein können als der Speicher selbst. Beispielsweise erfordert LLaMA 7B, das von Grund auf mit einer einzelnen Batch-Größe vorab trainiert wurde, mindestens 58 GB Speicher (14 GB für trainierbare Parameter, 42 GB für Adam Optimizer States und Gewichtsgradienten und 2 GB für Aktivierungen). Dadurch ist das Training von LLM auf Consumer-GPUs wie der NVIDIA RTX 4090 mit 24 GB Speicher nicht möglich.
Um die oben genannten Probleme zu lösen, entwickeln Forscher weiterhin verschiedene Optimierungstechniken, um die Speichernutzung während des Vortrainings und der Feinabstimmung zu reduzieren.
Diese Methode reduziert die Speichernutzung unter Optimierungszuständen um 65,5 %, während die Effizienz und Leistung des Vortrainings auf LLaMA 1B- und 7B-Architekturen unter Verwendung des C4-Datensatzes mit bis zu 19,7 B-Tokens und in GLUE-Feinabstimmung erhalten bleibt Effizienz und Leistung von RoBERTa bei der Aufgabe. Im Vergleich zur BF16-Basislinie reduziert 8-Bit-GaLore den Optimierungsspeicher um 82,5 % und den gesamten Trainingsspeicher um 63,3 %.
Nachdem sie diese Studie gesehen hatten, sagten Internetnutzer: „Es ist Zeit, die Cloud und HPC zu vergessen. Mit GaLore wird die gesamte AI4Science auf einer 2.000-Dollar-GPU für Endverbraucher durchgeführt.“
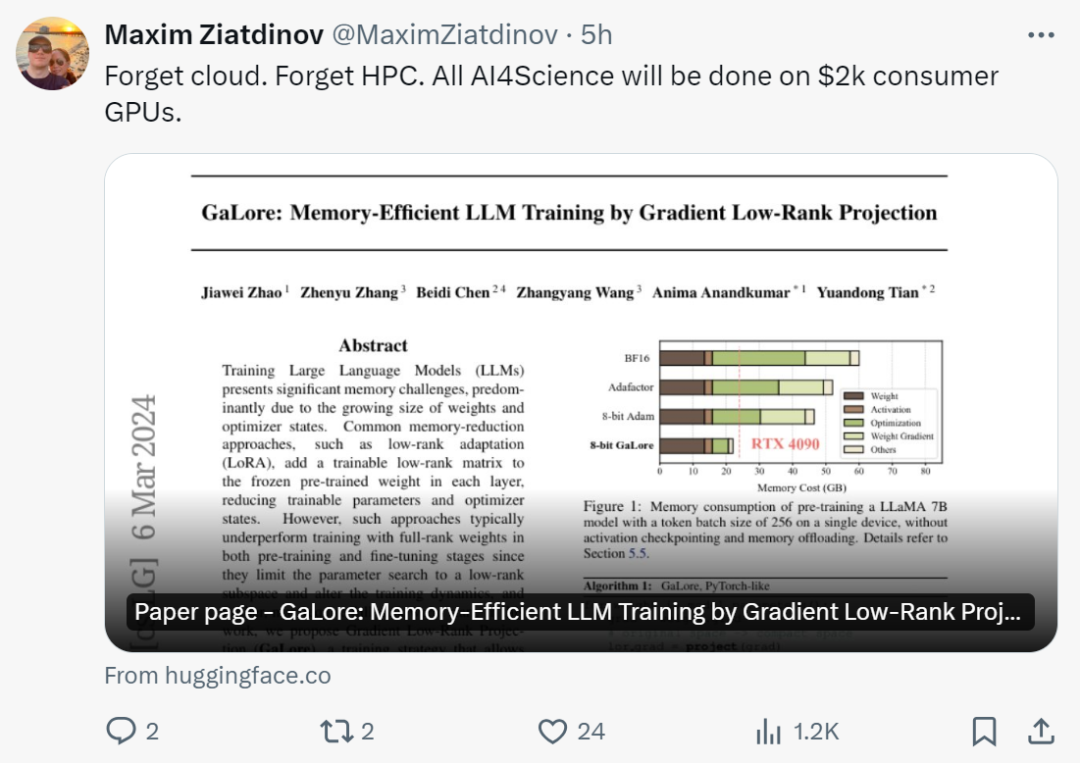
Tian Yuandong sagte: „Mit GaLore ist es jetzt möglich, das 7B-Modell in NVidia RTX 4090s mit 24G-Speicher vorab zu trainieren.
Wir sind nicht von einer Low-Rank-Gewichtsstruktur wie LoRA ausgegangen, sondern haben bewiesen, dass der Gewichtsgradient von Natur aus niedrig ist.“ Rang und kann somit in einen (variierenden) niedrigdimensionalen Raum projiziert werden. Daher speichern wir gleichzeitig Speicher für Gradienten, Adam-Impuls und Varianz
Daher verändert GaLore im Gegensatz zu LoRA nicht die Trainingsdynamik und kann dies auch tun Beginnen Sie mit dem Vortraining des 7B-Modells ohne speicherintensives Aufwärmen und erzielen Sie Ergebnisse, die mit denen von LoRA vergleichbar sind.
Methodeneinführung
Wie bereits erwähnt, ist GaLore eine Trainingsstrategie, die das Lernen vollständiger Parameter ermöglicht, aber speichereffizienter ist als gängige adaptive Methoden mit niedrigem Rang (wie LoRA). Die Schlüsselidee von GaLore besteht darin, die sich langsam ändernde Struktur mit niedrigem Rang des Gradienten 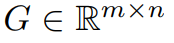 der Gewichtsmatrix W zu nutzen, anstatt zu versuchen, die Gewichtsmatrix direkt in eine Form mit niedrigem Rang zu approximieren.
der Gewichtsmatrix W zu nutzen, anstatt zu versuchen, die Gewichtsmatrix direkt in eine Form mit niedrigem Rang zu approximieren.
Dieser Artikel beweist zunächst theoretisch, dass die Gradientenmatrix G während des Trainingsprozesses einen niedrigen Rang erhält. Auf der Grundlage der Theorie verwendet dieser Artikel GaLore, um zwei Projektionsmatrizen zu berechnen 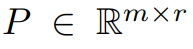 und
und 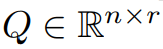 , um die Gradientenmatrix G zu projizieren Niedrigrangige Form P^⊤GQ. In diesem Fall können die Speicherkosten von Optimiererzuständen, die auf Komponentengradientenstatistiken basieren, erheblich reduziert werden. Wie in Tabelle 1 gezeigt, ist GaLore speichereffizienter als LoRA. Tatsächlich kann dies im Vergleich zu LoRA das Gedächtnis während des Vortrainings um bis zu 30 % reduzieren.
, um die Gradientenmatrix G zu projizieren Niedrigrangige Form P^⊤GQ. In diesem Fall können die Speicherkosten von Optimiererzuständen, die auf Komponentengradientenstatistiken basieren, erheblich reduziert werden. Wie in Tabelle 1 gezeigt, ist GaLore speichereffizienter als LoRA. Tatsächlich kann dies im Vergleich zu LoRA das Gedächtnis während des Vortrainings um bis zu 30 % reduzieren.

Dieser Artikel beweist, dass GaLore beim Vortraining und bei der Feinabstimmung gute Leistungen erbringt. Beim Vortraining von LLaMA 7B auf dem C4-Datensatz kombiniert 8-Bit-GaLore einen 8-Bit-Optimierer und eine Schicht-für-Schicht-Gewichtsaktualisierungstechnologie, um eine mit Full Rank vergleichbare Leistung zu erreichen, mit weniger als 10 % Speicherkosten für den Optimiererstatus.
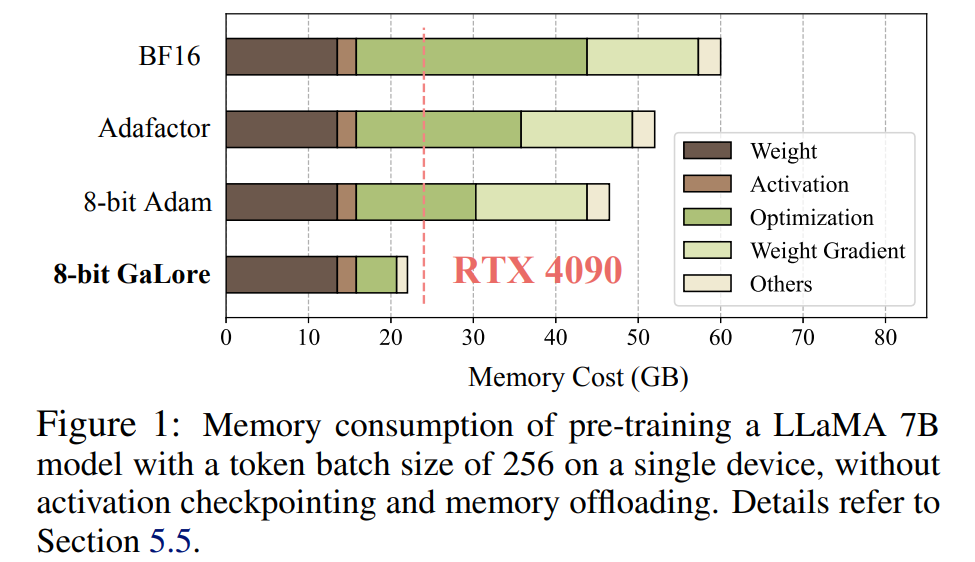
Es ist erwähnenswert, dass GaLore vor dem Training das Gedächtnis während des gesamten Trainingsprozesses niedrig hält, ohne dass ein umfassendes Training wie ReLoRA erforderlich ist. Dank der Speichereffizienz von GaLore kann LLaMA 7B erstmals von Grund auf auf einer einzelnen GPU mit 24 GB Speicher (z. B. auf einer NVIDIA RTX 4090) trainiert werden, ohne dass teure Techniken zur Speicherauslagerung erforderlich sind (Abbildung 1).
Als Gradientenprojektionsmethode ist GaLore unabhängig von der Wahl des Optimierers und kann einfach mit nur zwei Codezeilen in einen vorhandenen Optimierer eingebunden werden, wie in Algorithmus 1 gezeigt.

Die folgende Abbildung zeigt den Algorithmus zur Anwendung von GaLore auf Adam:

Experimente und Ergebnisse
Die Forscher bewerteten das Vortraining von GaLore und die Feinabstimmung von LLM. Alle Experimente wurden auf einer NVIDIA A100-GPU durchgeführt.
Um seine Leistung zu bewerten, verwendeten die Forscher GaLore, um ein großes Sprachmodell basierend auf LLaMA auf dem C4-Datensatz zu trainieren. Der C4-Datensatz ist eine riesige, bereinigte Version des Web-Crawling-Korpus Common Crawl, der hauptsächlich zum Vorabtrainieren von Sprachmodellen und Wortdarstellungen verwendet wird. Um das tatsächliche Szenario vor dem Training bestmöglich zu simulieren, trainierten die Forscher mit einer ausreichend großen Datenmenge, ohne die Daten zu duplizieren, wobei die Modellgrößen bis zu 7 Milliarden Parameter umfassten.
Dieses Papier folgt dem experimentellen Aufbau von Lialin et al. und verwendet eine LLaMA3-basierte Architektur mit RMSNorm- und SwiGLU-Aktivierung. Für jede Modellgröße verwendeten sie mit Ausnahme der Lernrate den gleichen Satz an Hyperparametern und führten alle Experimente im BF16-Format durch, um die Speichernutzung zu reduzieren und gleichzeitig die Lernrate für jede Methode mit demselben Rechenbudget anzupassen und eine optimale Leistung zu erzielen.
Darüber hinaus nutzten die Forscher die GLUE-Aufgabe als Benchmark für die speichereffiziente Feinabstimmung von GaLore und LoRA. GLUE ist ein Benchmark zur Bewertung der Leistung von NLP-Modellen bei einer Vielzahl von Aufgaben, einschließlich Stimmungsanalyse, Beantwortung von Fragen und Textkorrelation.
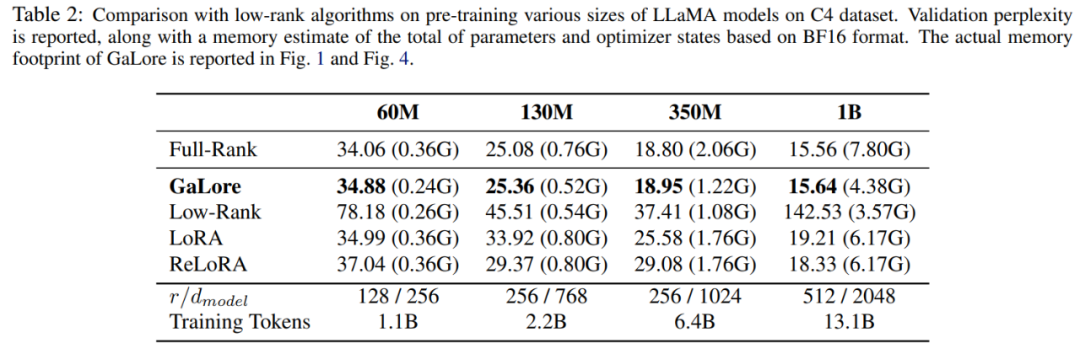
In diesem Artikel wird zunächst der Adam-Optimierer verwendet, um GaLore mit vorhandenen Low-Rank-Methoden zu vergleichen. Die Ergebnisse sind in Tabelle 2 aufgeführt.
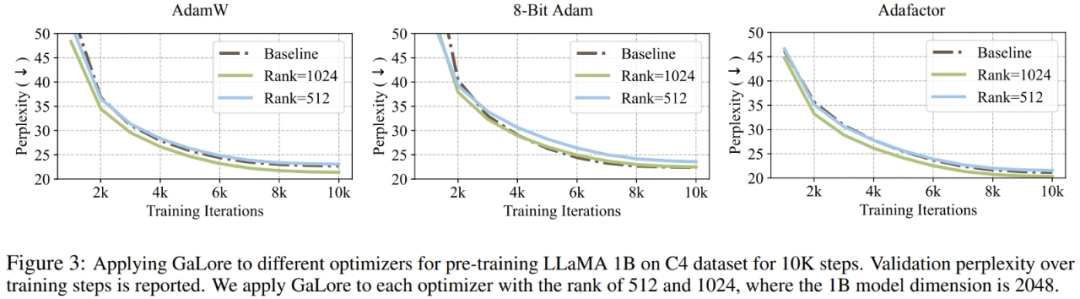
Forscher haben bewiesen, dass GaLore auf verschiedene Lernalgorithmen, insbesondere speichereffiziente Optimierer, angewendet werden kann, um die Speichernutzung weiter zu reduzieren. Die Forscher wendeten GaLore auf die Optimierer AdamW, 8-bit Adam und Adafactor an. Sie verwenden den statistischen Adafaktor erster Ordnung, um Leistungseinbußen zu vermeiden.
Experimentes bewertete sie auf der LLaMA 1B-Architektur mit 10.000 Trainingsschritten, optimierte die Lernrate für jede Einstellung und meldete die beste Leistung. Wie in Abbildung 3 dargestellt, zeigt die folgende Grafik, dass GaLore mit gängigen Optimierern wie AdamW, 8-Bit Adam und Adafactor funktioniert. Darüber hinaus hat die Einführung sehr weniger Hyperparameter keinen Einfluss auf die Leistung von GaLore.
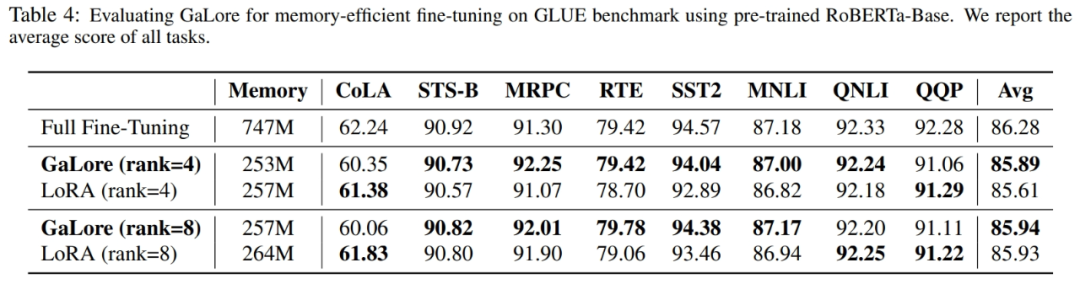
Wie in Tabelle 4 gezeigt, kann GaLore bei den meisten Aufgaben eine höhere Leistung als LoRA mit weniger Speicherverbrauch erzielen. Dies zeigt, dass GaLore als speichereffiziente Full-Stack-Trainingsstrategie für das LLM-Vortraining und die Feinabstimmung verwendet werden kann.
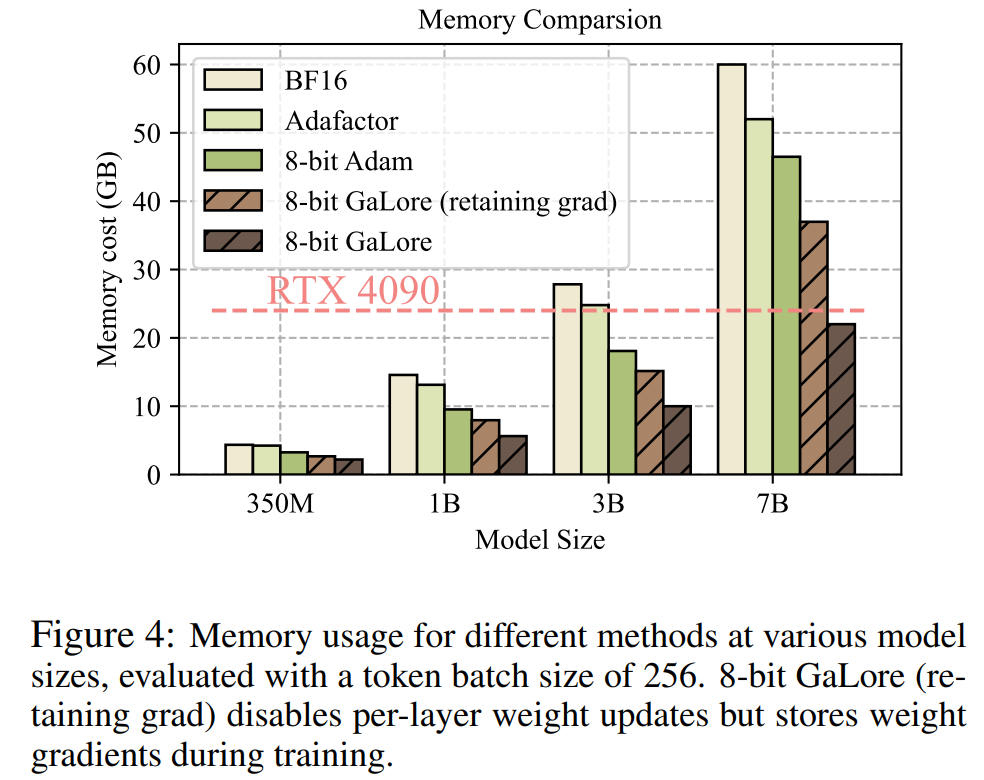
Wie in Abbildung 4 gezeigt, benötigt 8-Bit-GaLore im Vergleich zum BF16-Benchmark und 8-Bit-Adam viel weniger Speicher, beim Vortraining von LLaMA 7B werden nur 22,0 G Speicher und die Token-Batchgröße jeder GPU benötigt ist kleiner (bis zu 500 Token).
Für weitere technische Details lesen Sie bitte das Originalpapier.
Das obige ist der detaillierte Inhalt vonNeue Arbeit von Tian Yuandong und anderen: Durchbrechen des Speicherengpasses und Ermöglichen eines 4090 vorab trainierten 7B-Großmodells. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!