
Heim >Technologie-Peripheriegeräte >KI >Technischer Bericht zu Stable Diffusion 3 veröffentlicht: Enthüllung von Details der gleichen Architektur von Sora
Technischer Bericht zu Stable Diffusion 3 veröffentlicht: Enthüllung von Details der gleichen Architektur von Sora

- 王林nach vorne
- 2024-03-07 12:01:11957Durchsuche
Sehr bald ist der technische Bericht von Stable Diffusion 3, dem „neuen König der vinzentinischen Grafik“, hier.
Der Volltext umfasst insgesamt 28 Seiten und ist voller Aufrichtigkeit.

„Alte Regeln“, Werbeplakate (⬇️) werden direkt mit Modellen generiert und zeigen ihre Fähigkeiten zur Textwiedergabe:
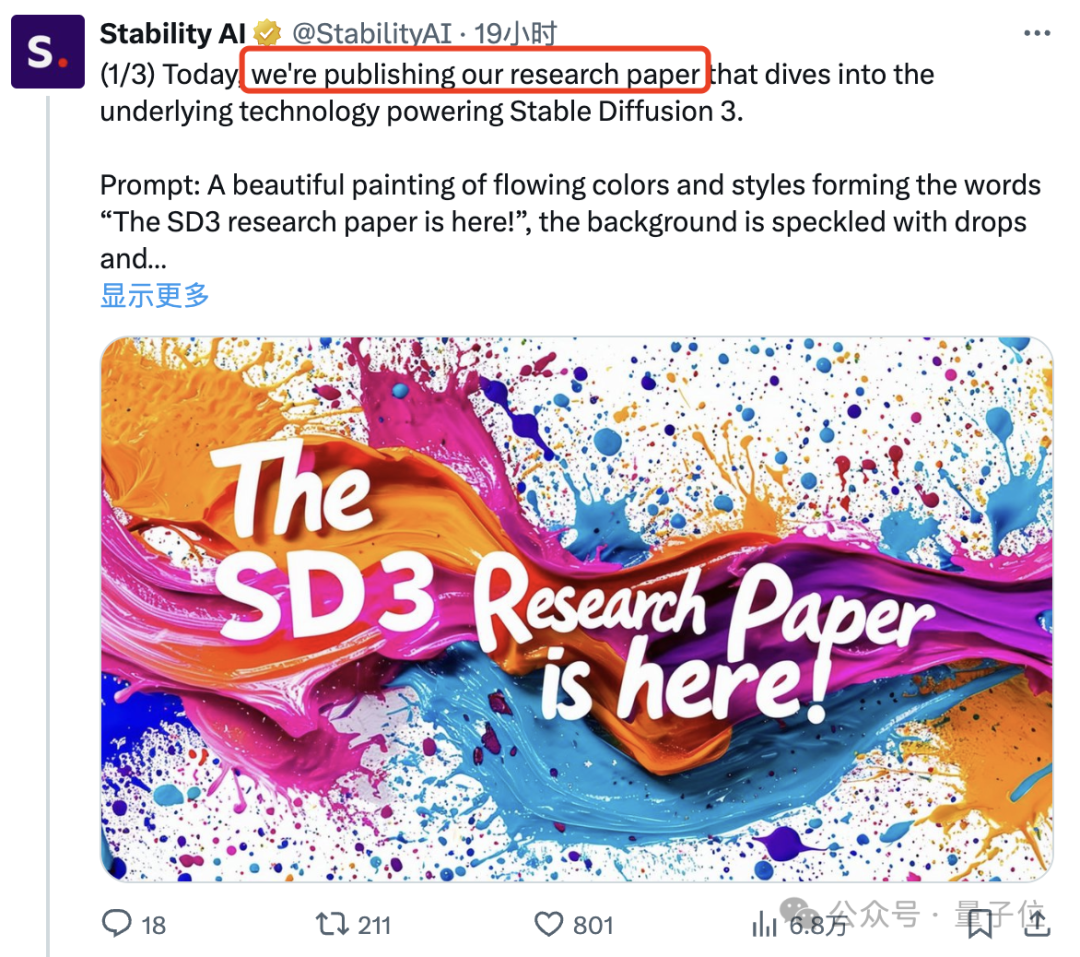
SD3 verfügt also über stärkere Texte und Befehle als DALL·E 3 und Midjourney v6 Wie leuchtet die folgende Fertigkeit auf?
Technischer Bericht enthüllt:
Alles basiert auf der multimodalen Diffusions-Transformer-Architektur MMDiT.
Durch die Anwendung unterschiedlicher Gewichtungen auf Bild- und Textdarstellungen werden größere Leistungsverbesserungen als in früheren Versionen erzielt, was der Schlüssel zum Erfolg ist.
Für die spezifische Geometrie öffnen wir den Bericht und sehen uns um.
DiT verfeinert, um die Textwiedergabefähigkeiten zu verbessern
Zu Beginn der Veröffentlichung von SD3 gab der Beamte bekannt, dass seine Architektur denselben Ursprung wie Sora hat und ein Diffusionstransformer – DiT – ist.
Jetzt wird die Antwort enthüllt:
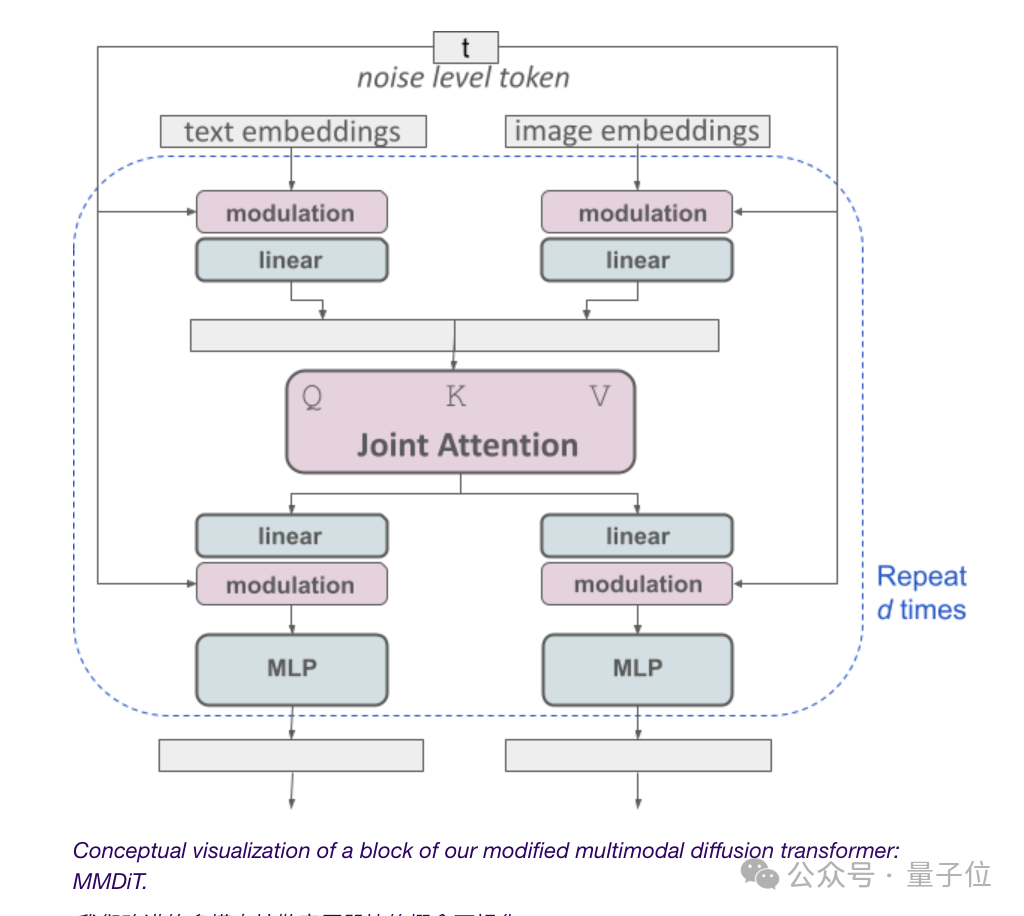
Da das Vincent-Diagrammmodell sowohl Text- als auch Bildmodi berücksichtigen muss, geht Stability AI noch einen Schritt weiter als DiT und schlägt eine neue Architektur MMDiT vor.
Das „MM“ bezieht sich hier auf „multimodal“.
Wie frühere Versionen von Stable Diffusion verwendet der Beamte zwei vorab trainierte Modelle, um geeignete Text- und Bilddarstellungen zu erhalten.
Die Kodierung der Textdarstellung erfolgt über drei verschiedene Texteinbetter (Embedder), darunter zwei CLIP-Modelle und ein T5-Modell.
Die Kodierung des Bild-Tokens erfolgt mithilfe eines verbesserten Autoencoder-Modells.
Da Text- und Bildeinbettung konzeptionell nicht dasselbe sind, verwendet SD3 zwei Sätze unabhängiger Gewichtungen für diese beiden Modi.
(Einige Internetnutzer beschwerten sich: Dieses Architekturdiagramm scheint das „Human Completion Project“ zu starten, ja, einige Leute haben einfach „die Informationen zu „Neon Genesis Evangelion“ gesehen und auf diesen Bericht geklickt“)
Um auf das Thema zurückzukommen: Wie in der Abbildung oben gezeigt, entspricht dies zwei unabhängigen Transformatoren für jede Modalität, deren Sequenzen jedoch für Aufmerksamkeitsoperationen verbunden werden.
Auf diese Weise können beide Darstellungen in ihrem eigenen Raum wirken und gleichzeitig den anderen berücksichtigen.
Letztendlich können durch diese Methode Informationen zwischen Bildern und Text-Tokens „fließen“, wodurch das Gesamtverständnis des Modells und die Textwiedergabefähigkeiten bei der Ausgabe verbessert werden.
Und wie der vorherige Effekt zeigt, kann diese Architektur auch problemlos auf mehrere Modi wie Video erweitert werden.

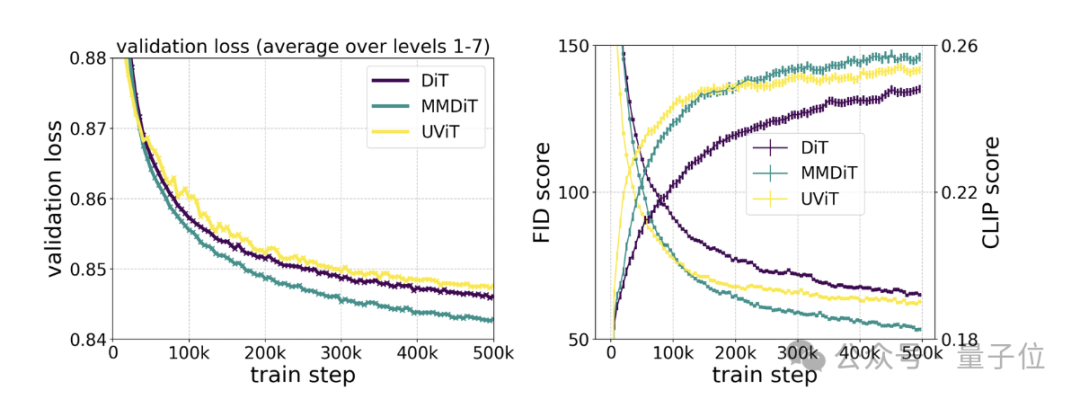
Spezifische Tests zeigen, dass MMDiT auf DiT basiert, aber besser als DiT ist:
Seine visuelle Wiedergabetreue und Textausrichtung während des Trainingsprozesses sind besser als bestehende Text-zu-Bild-Backbones wie UViT und DiT.
Neugewichtete Flow-Technologie zur kontinuierlichen Verbesserung der Leistung
Zu Beginn der Veröffentlichung enthüllte der Beamte neben der Diffusions-Transformer-Architektur auch, dass SD3 Flow-Matching beinhaltet.
Welcher „Flow“?
Wie aus dem Titel des heute veröffentlichten Papiers hervorgeht, verwendet SD3 „Rectified Flow“ (RF).

Dies ist eine „extrem vereinfachte, einstufige Generierung“-Methode zur Generierung neuer Diffusionsmodelle, die für ICLR2023 ausgewählt wurde.
Es ermöglicht die Verbindung der Daten und des Rauschens des Modells während des Trainings in einer linearen Trajektorie, wodurch ein „geradlinigerer“ Inferenzpfad entsteht, der weniger Schritte für die Stichprobenerhebung erfordert.
Basierend auf RF führt SD3 eine neue Flugbahnabtastung während des Trainingsprozesses ein.
Der Schwerpunkt liegt darauf, dem mittleren Teil der Flugbahn mehr Gewicht zu verleihen, da der Autor davon ausgeht, dass diese Teile anspruchsvollere Vorhersageaufgaben erfüllen.
Beim Testen dieser Generierungsmethode im Vergleich zu 60 anderen Diffusions-Trajektorien-Methoden (wie LDM, EDM und ADM) über mehrere Datensätze, Metriken und Sampler-Konfigurationen hinweg wurde Folgendes festgestellt:
Während frühere RF-Methoden in Probenahmeschemata mit wenigen Schritten gut funktionierten, lieferten sie eine gute Leistung, Ihre relative Leistung nimmt jedoch mit zunehmender Anzahl der Schritte ab.
Im Gegensatz dazu verbessert die SD3-neugewichtete RF-Variante die Leistung kontinuierlich.
Die Modellfähigkeit kann weiter verbessert werden
Der Beamte führte eine Skalierungsstudie zur Text-zu-Bild-Generierung unter Verwendung der neu gewichteten RF-Methode und der MMDiT-Architektur durch.
Trainierte Modelle reichen von 15 Modulen mit 450 Millionen Parametern bis zu 38 Modulen mit 8 Milliarden Parametern.
Daraus beobachteten sie: Mit zunehmender Modellgröße und zunehmenden Trainingsschritten zeigt der Validierungsverlust einen sanften Abwärtstrend, das heißt, das Modell passt sich durch kontinuierliches Lernen an komplexere Daten an.
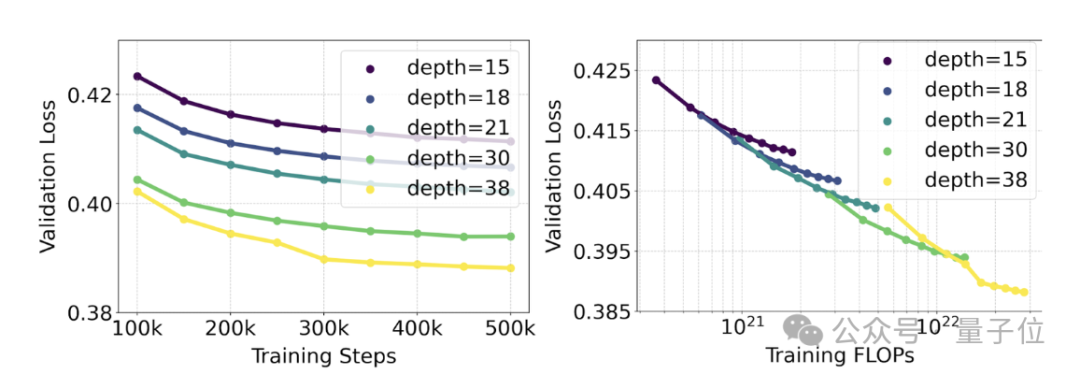
Um zu testen, ob dies zu sinnvolleren Verbesserungen der Modellausgabe führte, haben wir auch die automatische Bildausrichtungsmetrik (GenEval) sowie den menschlichen Präferenzwert (ELO) ausgewertet.
Das Ergebnis ist:
Es besteht ein starker Zusammenhang zwischen beiden. Das heißt, der Verifizierungsverlust kann als sehr aussagekräftiger Indikator zur Vorhersage der Gesamtleistung des Modells verwendet werden.
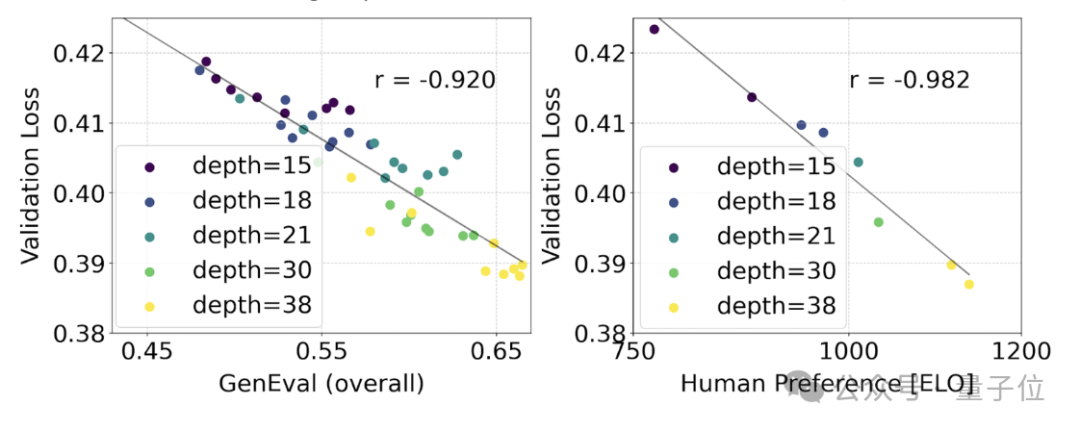
Da der Expansionstrend hier außerdem keine Anzeichen einer Sättigung zeigt (d. h. mit zunehmender Modellgröße verbessert sich die Leistung immer noch und hat das Limit noch nicht erreicht), ist der Beamte sehr optimistisch:
The Die Leistung von SD3 kann in Zukunft noch weiter verbessert werden.
Abschließend erwähnt der technische Bericht auch das Problem der Text-Encoder:
Durch die Entfernung des speicherintensiven T5-Text-Encoders mit 4,7 Milliarden Parametern, der für die Inferenz verwendet wird, kann der Speicherbedarf von SD3 deutlich reduziert werden, gleichzeitig kann aber Der Leistungsverlust ist erheblich (die Gewinnrate ist von 50 % auf 46 % gesunken).
Aus Gründen der Textwiedergabefähigkeit lautet die offizielle Empfehlung jedoch, T5 nicht zu entfernen, da sonst die Erfolgsrate der Textdarstellung auf 38 % sinken wird.

Um es zusammenzufassen: Unter den drei Text-Encodern von SD3 leistet T5 den größten Beitrag bei der Generierung von Bildern mit Text (und sehr detaillierten Szenenbeschreibungsbildern).
Internetnutzer: Die Open-Source-Verpflichtung wurde wie geplant erfüllt, vielen Dank
Sobald der SD3-Bericht herauskam, sagten viele Internetnutzer:
Stability AI ist sehr erfreut, dass die Open-Source-Verpflichtung wie geplant erfüllt wurde. und ich hoffe, dass sie es noch lange warten und betreiben können.

Manche Leute trauen sich nur knapp, den Namen OpenAI zu beanspruchen:

Was noch erfreulicher ist, ist, dass jemand im Kommentarbereich erwähnt hat:
Alle Gewichte des SD3-Modells können heruntergeladen werden, und Der aktuelle Plan umfasst 800 Millionen Parameter, 2 Milliarden Parameter und 8 Milliarden Parameter.


Wie ist die Geschwindigkeit?
Ähm, im technischen Bericht heißt es:
8 Milliarden SD3 benötigen 34 Sekunden, um ein 1024*1024-Bild auf einer 24-GB-RTX 4090 zu erzeugen (50 Abtastschritte) – aber das ist nur ein frühes, nicht optimiertes vorläufiges Inferenztestergebnis.
Vollständiger Text des Berichts: https://stabilityai-public-packages.s3.us-west-2.amazonaws.com/Stable+Diffusion+3+Paper.pdf.
Referenzlink:
[1]https://stability.ai/news/stable-diffusion-3-research-paper.
[2]https://news.ycombinator.com/item?id=39599958.
Das obige ist der detaillierte Inhalt vonTechnischer Bericht zu Stable Diffusion 3 veröffentlicht: Enthüllung von Details der gleichen Architektur von Sora. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Stabilitäts-KI-Open-Source-Grafikmodell von Vincent; Mo Yan bat ChatGPT, die Preisrede zu schreiben; Yuncong veröffentlichte täglich ein großes KI-Modell丨AIGC-Großereignis
- Stability AI bringt das Vincentian-Grafikmodell SDXL0.9 auf den Markt, wobei die GPU-Anforderungen auf Verbraucherniveau gesenkt werden