
Heim >Web-Frontend >js-Tutorial >Pure js realisiert lokalen Speicher mit unbegrenzten Space_Javascript-Kenntnissen
Pure js realisiert lokalen Speicher mit unbegrenzten Space_Javascript-Kenntnissen

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOriginal
- 2016-05-16 15:54:141541Durchsuche
Es ist lange her, seit ich einen Blog geschrieben habe. Obwohl ich vor zwei Jahren versprochen hatte, den Quellcode zu veröffentlichen, hatte ich endlich Zeit, die Funktion des lokalen Speichers mit unbegrenztem Speicherplatz mithilfe von reinem JS zu öffnen .
Projektadressehttps://github.com/xueduany/localstore,
Demo siehehttp://xueduany.github.io/localstore/,
Lassen Sie mich Ihnen eine kurze Einführung in das allgemeine Prinzip geben. Die spezifischen Details und die Ausnahmebehandlung werden später bei Gelegenheit separat besprochen.
Lassen Sie uns zunächst über das Prinzip des Durchbrechens von localStorage sprechen. Die offiziellen Worte lauten wie folgt: http://www.w3.org/TR/2013/PR-webstorage-20130409/

Sie wissen also, dass Sie die Tatsache, dass localStorage mehrerer Subdomains nicht voneinander abhängt, nutzen können, um einen StorePool durch localStorage mehrerer Subdomains zu entwerfen und zu implementieren und so die Obergrenze zu überschreiten
Wenn dann die eigentliche API gespeichert wird, wird sie nicht in localStorage gespeichert
Dies ähnelt ein wenig dem Manager-Modus, das heißt, Sie sagen dem Lagerleiter, was Sie speichern möchten, der Lagerleiter gibt Ihnen einen Schlüssel und dann nehmen Sie den Schlüssel zum entsprechenden Lager, um Ihre Sachen unterzubringen. und der Manager gibt Ihnen dann ein Token-Zertifikat. In Zukunft müssen Sie nur noch dieses Zertifikat besitzen, um die gespeicherten Dinge herauszunehmen.
Der Endbenutzer muss sich nicht darum kümmern, wo meine Daten gespeichert werden, solange er eine API ähnlich wie localStorage implementiert
Entwerfen Sie dann ein js-Objekt, das als Warehouse-Administrator fungiert. Wo sollen die entsprechenden gespeicherten Dinge gespeichert werden? Wir müssen einen solchen Satz von Datenstrukturen entwerfen und implementieren
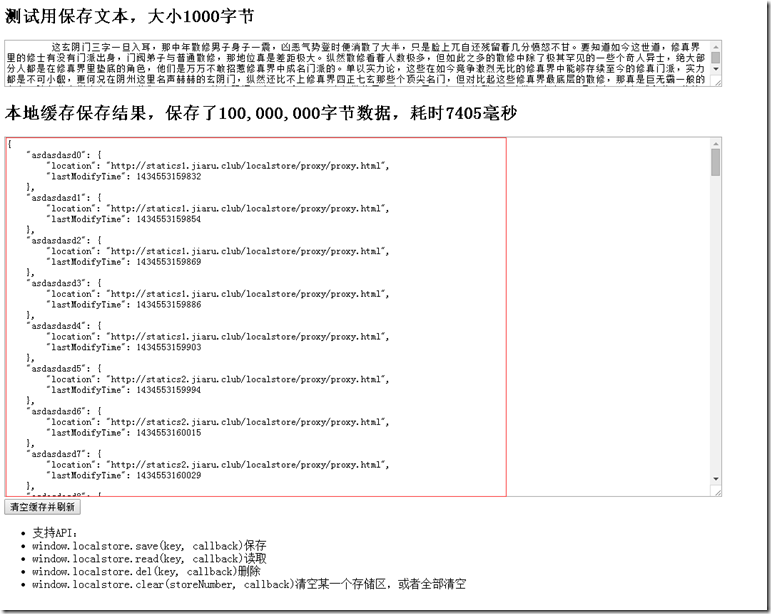
Unter dem entsprechenden Schlüssel steht die Adresse des Lagers, in dem es existiert, und die Lagerzeit. Das Konzept der Lagerzeit wird verwendet, um die Aktualität der Daten zu berechnen, d. h. um zu berechnen, ob sie abgelaufen sind
Also müssen wir zunächst mehrere Iframes erstellen, um Proxydateien unter mehreren Domänennamen zu laden, über die HTML5-API postMessage oder die alte seitenübergreifende Methode miteinander zu interagieren und Daten über den Proxy dieses Proxys zu speichern
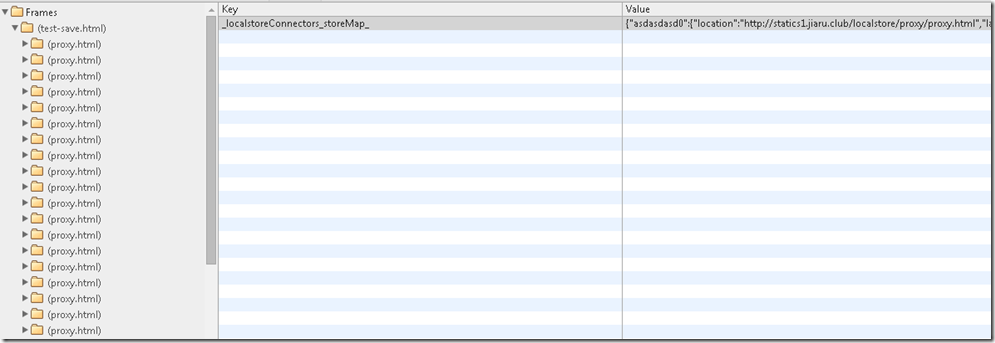
Speichern Sie den Stub des Datenschlüssels unter dem aktuellen Hauptdomänennamen und speichern Sie dann die tatsächlichen Daten unter jedem Subdomänennamen
Okay, nachdem das Speicherlimit überschritten wurde, müssen wir, wenn wir eine Webseite speichern möchten, in Betracht ziehen, alle mit der Webseite verbundenen statischen Ressourcen abzurufen, einschließlich js und css Text, das ist alles einfach. Solange eine Ajax-Anfrage gestellt wird, müssen Sie nur die Sicherheit berücksichtigen, die dazu führt, dass js die Antwortdaten erhält Antwortheader an
auf dem CDN-Knotenserver.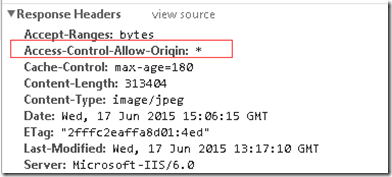
Das war's, holen Sie sich den Inhalt domänenübergreifend
js, d. h. kann in <script>remote erhaltenen Inhalt</script>, CSS, Ändern Sie dies einfach in
Hier müssen wir nur die Codeblöcke berücksichtigen, die mit dem ursprünglichen HTML übereinstimmen können. Wir müssen nur ein Problem berücksichtigen, nämlich dass der reguläre Ausdruck von js standardmäßig im Greedy-Modus ist, sodass unser regulärer Ausdruck die Mindestübereinstimmung erreichen muss.

Wie erhält man also bei Bildern den Inhalt des Bildes? Wir wissen, dass das Bild Rohdaten und binär ist. Zuerst müssen wir das Problem lösen, den Binärstrom des Bildes zu erhalten
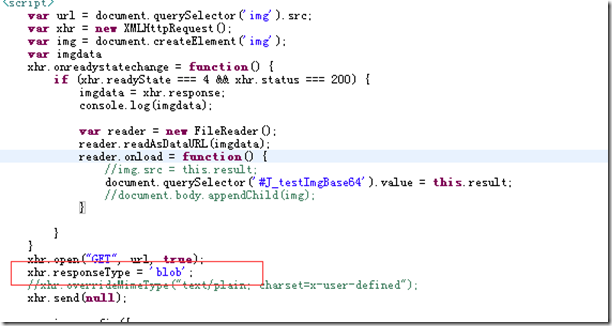
Dann ersetzen Sie die entsprechenden Ressourcen im gesamten Webseiten-HTML durch unsere speziellen Tags
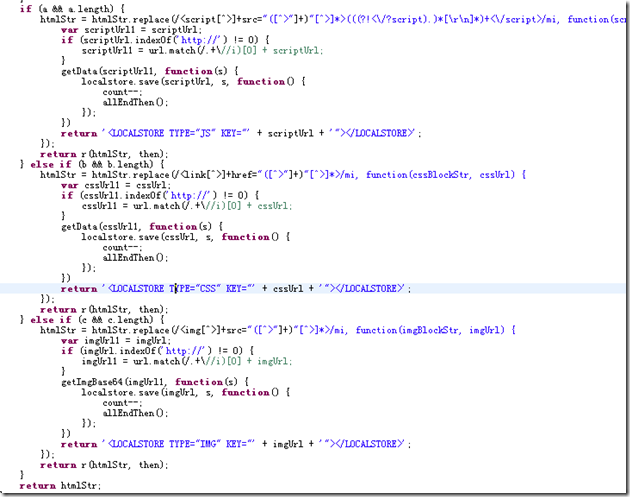
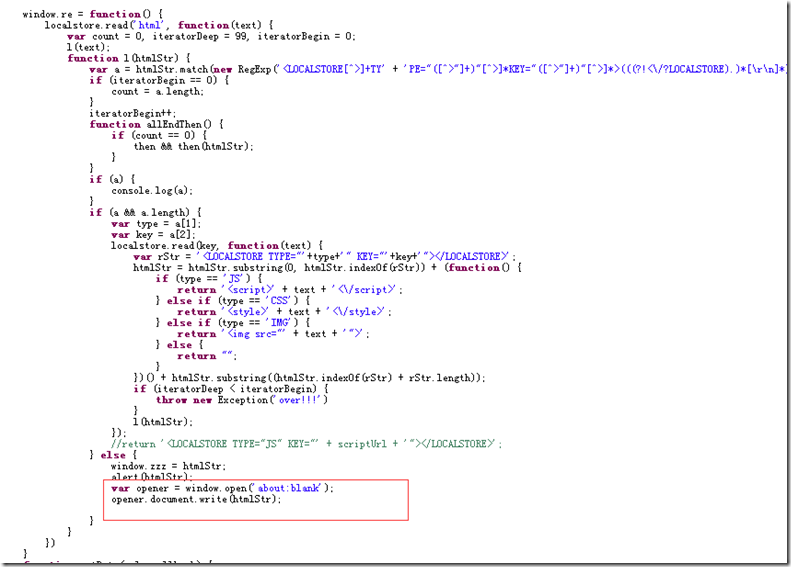
Durch dieses Prinzip können Sie eine Website offline schalten und lokalisieren und dann die SinglePage-Technologie verwenden, um das Surfen zu ermöglichen, ohne dass Anfragen gestellt werden müssen. Was sind das? Verdammt, lass es mich das nächste Mal aufschlüsseln! ! !
Das Obige ist der gesamte Inhalt dieses Artikels. Ich hoffe, er gefällt Ihnen allen.
In Verbindung stehende Artikel
Mehr sehen- Eine eingehende Analyse der Bootstrap-Listengruppenkomponente
- Detaillierte Erläuterung des JavaScript-Funktions-Curryings
- Vollständiges Beispiel für die Generierung von JS-Passwörtern und die Erkennung der Stärke (mit Download des Demo-Quellcodes)
- Angularjs integriert WeChat UI (weui)
- Wie man mit JavaScript schnell zwischen traditionellem Chinesisch und vereinfachtem Chinesisch wechselt und wie Websites den Wechsel zwischen vereinfachtem und traditionellem Chinesisch unterstützen – Javascript-Kenntnisse