
Heim >Technologie-Peripheriegeräte >KI >Der technische Bericht zu Stable Diffusion 3 ist durchgesickert, die Sora-Architektur hat wieder großartige Erfolge erzielt! Schlägt die Open-Source-Community gewaltsam gegen Midjourney und DALL·E 3 vor?
Der technische Bericht zu Stable Diffusion 3 ist durchgesickert, die Sora-Architektur hat wieder großartige Erfolge erzielt! Schlägt die Open-Source-Community gewaltsam gegen Midjourney und DALL·E 3 vor?

- PHPznach vorne
- 2024-03-06 16:22:20717Durchsuche
Stability AI hat heute nach der Veröffentlichung von Stable Diffusion 3 einen detaillierten technischen Bericht veröffentlicht.
Das Papier bietet eine eingehende Analyse der Kerntechnologie von Stable Diffusion 3 – eine verbesserte Version des Diffusionsmodells und eine neue Architektur vinzentinischer Diagramme basierend auf DiT!

Meldeadresse:
https://www.php.cn/link/e5fb88b398b042f6cccce46bf3fa53e8
Bestandener Humantest, stabil Verbreitung 3. Im Schriftdesign und in der präzisen Reaktion auf Aufforderungen In puncto Leistung übertrifft es DALL·E 3, Midjourney v6 und Ideogram v1.
Die neu entwickelte Multi-modal Diffusion Transformer (MMDiT)-Architektur von Stability AI verwendet unabhängige Gewichtssätze speziell für die Bild- und Sprachdarstellung. Im Vergleich zu früheren Versionen von SD 3 hat MMDiT deutliche Verbesserungen beim Textverständnis und der Rechtschreibung erzielt.

Leistungsbewertung
Basierend auf menschlichem Feedback vergleicht der technische Bericht SD 3 mit einer großen Anzahl von Open-Source-Modellen SDXL, SDXL Turbo, Stable Cascade, Playground v2.5 und Pixart-α, as sowie die Closed-Source-Modelle DALL·E 3, Midjourney v6 und Ideogram v1 wurden detailliert evaluiert.
Gutachter wählen die beste Ausgabe für jedes Modell basierend auf der Konsistenz der angegebenen Eingabeaufforderungen, der Klarheit des Textes und der Gesamtästhetik der Bilder aus.

Die Testergebnisse zeigen, dass Stable Diffusion 3 das höchste Niveau der aktuellen Technologie zur Generierung vincentischer Diagramme erreicht oder übertroffen hat, sei es in Bezug auf die Genauigkeit beim Befolgen von Eingabeaufforderungen, die klare Darstellung von Text oder die visuelle Schönheit von Bildern.
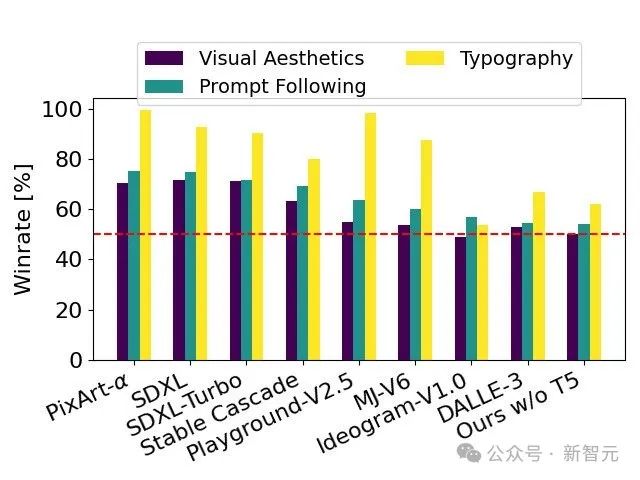
Das vollständig nicht hardwareoptimierte SD 3-Modell verfügt über 8B-Parameter, kann auf einer RTX 4090 Consumer-GPU mit 24 GB Videospeicher ausgeführt werden und erzeugt eine Auflösung von 1024 x 1024 mit 50 Abtastschritten. Das Bild dauert 34 Sekunden .
Darüber hinaus wird Stable Diffusion 3 bei Veröffentlichung mehrere Versionen mit Parametern im Bereich von 800 Millionen bis 8 Milliarden bereitstellen, was die Hardware-Nutzungsschwelle weiter senken kann.

Architektonische Details offengelegt
Beim Generieren des Vincent-Diagramms muss das Modell zwei verschiedene Arten von Informationen, Text und Bild, gleichzeitig verarbeiten. Deshalb nennt der Autor dieses neue Framework MMDiT.
Im Prozess der Text-zu-Bild-Generierung muss das Modell zwei verschiedene Informationstypen, Text und Bild, gleichzeitig verarbeiten. Aus diesem Grund nennen die Autoren diese neue Technologie MMDiT (kurz für Multimodal Diffusion Transformer).
Wie frühere Versionen von Stable Diffusion verwendet SD 3 ein vorab trainiertes Modell, um geeignete Ausdrücke von Text und Bildern zu extrahieren.
Konkret verwendeten sie drei verschiedene Text-Encoder – zwei CLIP-Modelle und einen T5 – zur Verarbeitung von Textinformationen, während sie ein fortschrittlicheres Autoencoding-Modell zur Verarbeitung von Bildinformationen verwendeten.
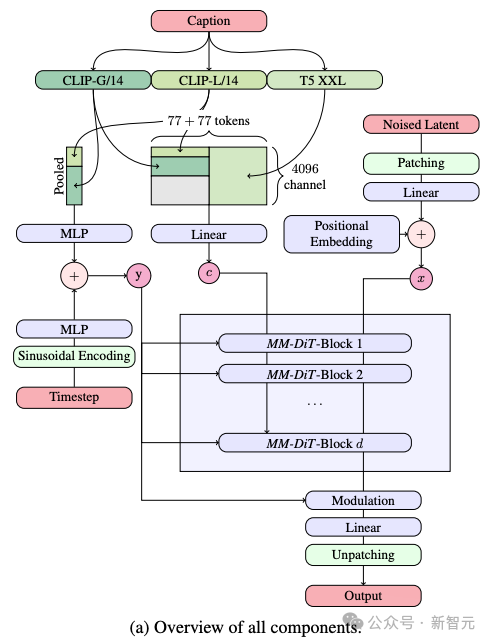
Die Architektur von SD 3 basiert auf Diffusion Transformer (DiT). Aufgrund des Unterschieds zwischen Text- und Bildinformationen legt SD 3 für jede dieser beiden Informationsarten unabhängige Gewichtungen fest.
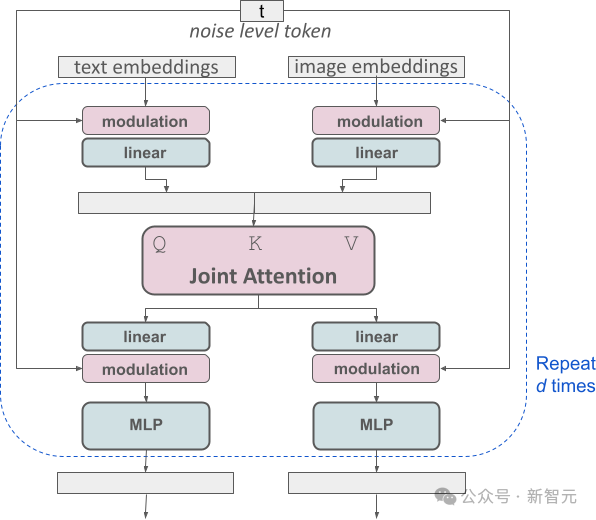
Dieses Design entspricht der Ausstattung zweier unabhängiger Transformatoren für jeden Informationstyp. Bei der Ausführung des Aufmerksamkeitsmechanismus werden jedoch die Datensequenzen der beiden Informationstypen zusammengeführt, sodass sie unabhängig voneinander in ihren jeweiligen Bereichen arbeiten können gegenseitige Referenz und Integration.
Durch diese einzigartige Architektur können Bild- und Textinformationen fließen und miteinander interagieren, wodurch das Gesamtverständnis des Inhalts und die visuelle Darstellung in den generierten Ergebnissen verbessert werden.
Darüber hinaus kann diese Architektur in Zukunft problemlos auf andere Modalitäten, einschließlich Video, erweitert werden.

Dank der Verbesserungen von SD 3 beim Befolgen von Eingabeaufforderungen ist das Modell in der Lage, Bilder präzise zu generieren, die sich auf eine Vielzahl verschiedener Themen und Funktionen konzentrieren, und gleichzeitig ein hohes Maß an Flexibilität im Bildstil beizubehalten.

Verbesserter gleichgerichteter Fluss durch die Neugewichtungsmethode
Neben der neuen Diffusion Transformer-Architektur hat SD 3 auch erhebliche Verbesserungen am Diffusionsmodell vorgenommen.
SD 3 nutzt die Rectified Flow (RF)-Strategie, um Trainingsdaten und Rauschen entlang einer geraden Flugbahn zu verbinden.
Diese Methode macht den Inferenzpfad des Modells direkter, sodass die Probengenerierung in weniger Schritten abgeschlossen werden kann.
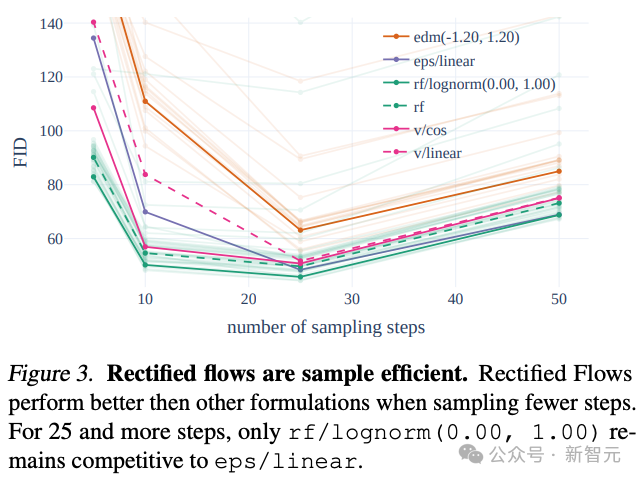
Der Autor führte im Trainingsprozess einen innovativen Trajektorien-Sampling-Plan ein, der insbesondere das Gewicht auf den mittleren Teil der Trajektorie erhöhte, wo die Vorhersageaufgabe anspruchsvoller ist.
Durch den Vergleich mit 60 anderen Diffusionstrajektorien (wie LDM, EDM und ADM) stellten die Autoren fest, dass die vorherige RF-Methode zwar bei der Abtastung in wenigen Schritten eine bessere Leistung erbrachte, die Leistung jedoch mit zunehmender Anzahl der Abtastschritte langsam abnahm. .
Um diese Situation zu vermeiden, kann die vom Autor vorgeschlagene gewichtete RF-Methode die Modellleistung weiter verbessern.
Erweitertes RF-Transformator-Modell
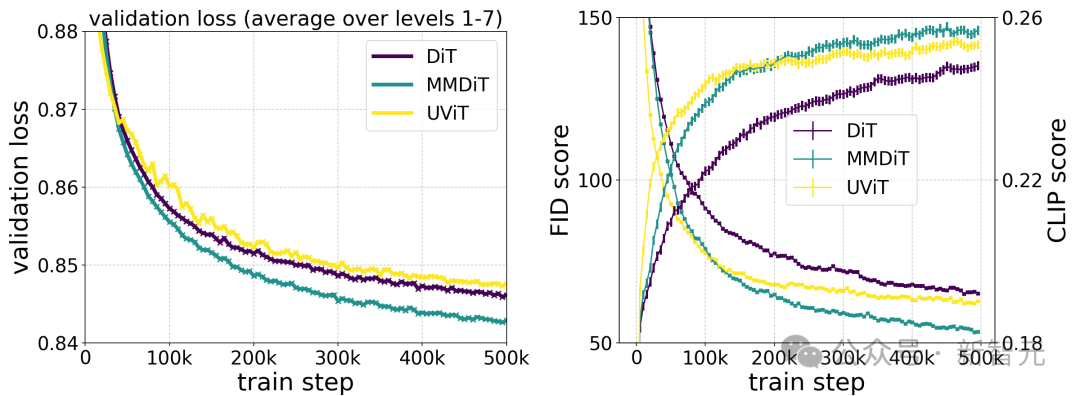
Stabilitäts-KI trainierte mehrere Modelle unterschiedlicher Größe, von 15 Modulen und 450 Millionen Parametern bis hin zu 38 Modulen und 8B Parametern, und stellte fest, dass sowohl die Modellgröße als auch die Trainingsschritte den Verifizierungsverlust reibungslos reduzieren können.
Um zu überprüfen, ob dies eine wesentliche Verbesserung der Modellausgabe bedeutete, bewerteten sie auch automatische Bildausrichtungsmetriken und menschliche Präferenzwerte.
Die Ergebnisse zeigen, dass diese Bewertungsindikatoren stark mit dem Verifizierungsverlust korrelieren, was darauf hinweist, dass der Verifizierungsverlust ein wirksamer Indikator zur Messung der Gesamtleistung des Modells ist.
Darüber hinaus hat dieser Expansionstrend noch keinen Sättigungspunkt erreicht, was uns optimistisch stimmt, dass wir die Modellleistung in Zukunft weiter verbessern können.
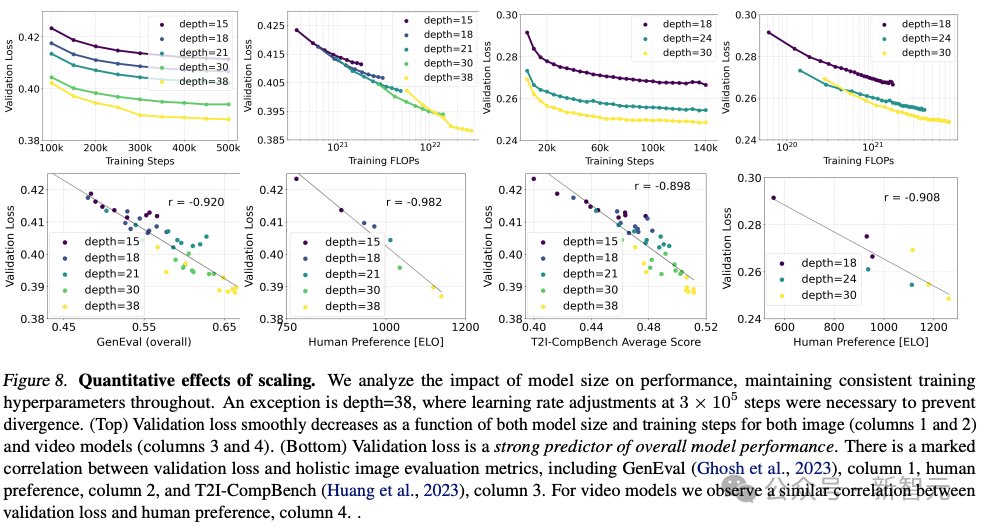
Der Autor hat das Modell für 500.000 Schritte mit unterschiedlicher Anzahl von Parametern bei einer Auflösung von 256 * 256 Pixeln und einer Stapelgröße von 4096 trainiert.

Die obige Abbildung veranschaulicht die Auswirkungen des Trainings eines größeren Modells über einen langen Zeitraum auf die Probenqualität.
Die obige Tabelle zeigt die Ergebnisse von GenEval. Bei Verwendung der von den Autoren vorgeschlagenen Trainingsmethode und Erhöhung der Auflösung der Trainingsbilder schnitt das größte Modell in den meisten Kategorien gut ab und übertraf DALL·E in der Gesamtpunktzahl um 3.
Laut dem Testvergleich verschiedener Architekturmodelle durch den Autor ist MMDiT sehr effektiv und übertrifft DiT, Cross DiT, UViT und MM-DiT.
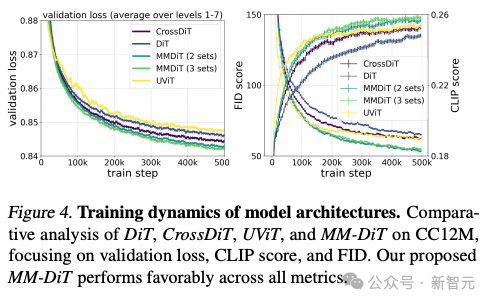
Flexibler Text-Encoder
Durch das Entfernen des speicherintensiven 4,7-B-Parameter-T5-Text-Encoders während der Inferenzphase werden die Speicheranforderungen von SD 3 bei minimalem Leistungsverlust erheblich reduziert.
Das Entfernen dieses Textencoders hat keinen Einfluss auf die visuelle Schönheit des Bildes (50 % Gewinnrate ohne T5), verringert jedoch nur geringfügig die Fähigkeit des Textes, genau zu folgen (46 % Gewinnrate).
Um jedoch die Fähigkeit von SD 3 zur Textgenerierung voll auszuschöpfen, empfiehlt der Autor dennoch die Verwendung des T5-Encoders.
Weil der Autor festgestellt hat, dass die Leistung beim Setzen von generiertem Text ohne sie stärker sinken würde (Gewinnquote 38 %).

Heiße Diskussion unter Internetnutzern
Die Internetnutzer sind ein wenig ungeduldig angesichts der ständigen Bemühungen von Stability AI, Benutzer zu ärgern, verweigern ihnen jedoch die Nutzung und fordern alle auf, es so schnell wie möglich online zu stellen.
Nachdem die Internetnutzer die technische Anwendung gelesen hatten, sagten sie, dass es den Anschein habe, dass der Fotografiekreis nun der erste Weg sein wird, in dem Open Source Closed Source vernichten wird!
Das obige ist der detaillierte Inhalt vonDer technische Bericht zu Stable Diffusion 3 ist durchgesickert, die Sora-Architektur hat wieder großartige Erfolge erzielt! Schlägt die Open-Source-Community gewaltsam gegen Midjourney und DALL·E 3 vor?. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!