
 Technologie-PeripheriegeräteKICVPR 2024-Partiturarbeit: Die Zhejiang-Universität schlägt eine neue Methode zur hochwertigen monokularen dynamischen Rekonstruktion auf der Grundlage verformbarer dreidimensionaler Gauß-Funktionen vor
Technologie-PeripheriegeräteKICVPR 2024-Partiturarbeit: Die Zhejiang-Universität schlägt eine neue Methode zur hochwertigen monokularen dynamischen Rekonstruktion auf der Grundlage verformbarer dreidimensionaler Gauß-Funktionen vor
Monokulare dynamische Szene bezieht sich auf eine dynamische Umgebung, die mit einer monokularen Kamera beobachtet und analysiert wird, in der sich Objekte in der Szene frei bewegen können. Die monokulare dynamische Szenenrekonstruktion ist von entscheidender Bedeutung für Aufgaben wie das Verständnis dynamischer Veränderungen in der Umgebung, die Vorhersage von Objektbewegungsbahnen und die Generierung dynamischer digitaler Assets. Mithilfe der monokularen Sehtechnologie können eine dreidimensionale Rekonstruktion und Modellschätzung dynamischer Szenen erreicht werden, was uns hilft, verschiedene Situationen in dynamischen Umgebungen besser zu verstehen und damit umzugehen. Diese Technologie kann nicht nur im Bereich Computer Vision eingesetzt werden, sondern spielt auch in Bereichen wie autonomes Fahren, Augmented Reality und Virtual Reality eine wichtige Rolle. Durch die monokulare dynamische Szenenrekonstruktion können wir die Bewegung von Objekten in der Umgebung genauer erfassen.
Mit dem Aufkommen des neuronalen Renderings, das durch das Neural Radiance Field (NeRF) dargestellt wird, beginnen immer mehr Arbeiten, versteckte 3D-Rekonstruktionen dynamischer Szenen durchzuführen implizite Darstellung. Obwohl einige repräsentative Werke, die auf NeRF basieren, wie D-NeRF, Nerfies, K-planes usw., eine zufriedenstellende Wiedergabequalität erreicht haben, sind sie noch weit von einer echten fotorealistischen Wiedergabe entfernt.
Das Forschungsteam der Zhejiang-Universität und ByteDance wies darauf hin, dass der Kern des oben genannten Problems darin besteht, dass die auf Ray Casting basierende NeRF-Pipeline den Beobachtungsraum durch Rückwärtsfluss auf den kanonischen Raum abbildet, was zu Genauigkeits- und Klarheitsproblemen führt. Die inverse Zuordnung ist für die Konvergenz der erlernten Struktur nicht ideal, was dazu führt, dass aktuelle Methoden im D-NeRF-Datensatz nur PSNR-Rendering-Indikatoren mit mehr als 30 Ebenen erreichen.
Um diese Herausforderung zu lösen, schlug das Forschungsteam einen monokularen dynamischen Szenenmodellierungsprozess vor, der auf Rasterisierung basiert. Sie kombinierten erstmals Deformationsfelder mit 3D-Gauß-Funktionen und schufen so eine neue Methode, die eine hochwertige Rekonstruktion und eine neue perspektivische Darstellung ermöglicht. Dieses Forschungspapier „Deformable 3D Gaussians for High-Fidelity Monocular Dynamic Scene Reconstruction“ wurde von CVPR 2024, der führenden internationalen akademischen Konferenz im Bereich Computer Vision, angenommen. Das Besondere an dieser Arbeit ist, dass es sich um die erste Studie handelt, die Deformationsfelder auf 3D-Gaußkurven anwendet, um sie auf monokulare dynamische Szenen auszudehnen.

Projekthomepage: https://ingra14m.github.io/Deformable-Gaussians/
Papierlink: https://arxiv.org/abs/2309.13101
Code: https: //github.com/ingra14m/Deformable-3D-Gaussians
Die experimentellen Ergebnisse zeigen, dass das verformbare Feld die 3D-Gaußsche Vorwärtsabbildung im kanonischen Raum effektiv und genau auf den Beobachtungsraum abbilden kann. Beim D-NeRF-Datensatz wurde eine PSNR-Verbesserung von mehr als 10 % erreicht. Darüber hinaus können in realen Szenen die Rendering-Details erhöht werden, auch wenn die Kamerahaltung nicht genau genug ist. N Abbildung 1 experimentelles Ergebnis der realen Szene von Hypernerf.

Verwandte ArbeitenDie dynamische Szenenrekonstruktion war schon immer ein heißes Thema bei der 3D-Rekonstruktion. Da das durch NeRF dargestellte neuronale Rendering ein qualitativ hochwertiges Rendering ermöglicht, ist im Bereich der dynamischen Rekonstruktion eine Reihe von Arbeiten entstanden, die auf impliziter Darstellung basieren. D-NeRF und Nerfies führen Deformationsfelder basierend auf der NeRF-Raycasting-Pipeline ein, um eine robuste dynamische Szenenrekonstruktion zu erreichen. TiNeuVox, K-Planes und Hexplanes führen auf dieser Basis eine Gitterstruktur ein, die den Modelltrainingsprozess erheblich beschleunigt und die Rendering-Geschwindigkeit verbessert. Diese Methoden basieren jedoch alle auf der inversen Abbildung und können keine wirklich hochwertige Entkopplung von Eichraum und Deformationsfeldern erreichen.
3D Gaussian Splash ist eine Punktwolken-Rendering-Pipeline, die auf Rasterisierung basiert. Seine CUDA-maßgeschneiderte differenzierbare Gaußsche Rasterisierungspipeline und die innovative Verdichtung ermöglichen es 3D-Gaußian nicht nur, SOTA-Rendering-Qualität zu erreichen, sondern auch Echtzeit-Rendering zu erreichen. Dynamischer 3D-Gauß erweitert zunächst den statischen 3D-Gauß auf das dynamische Feld. Allerdings schränkt seine Fähigkeit, nur Multi-View-Szenen zu verarbeiten, seine Anwendung in allgemeineren Situationen, wie Single-View-Szenen wie bei Handyaufnahmen, stark ein.Forschungsideen
Der Kern von Deformable-GS besteht darin, statische 3D-Gaußsche Szenen auf monokulare dynamische Szenen zu erweitern. Jeder 3D-Gauß-Wert trägt Position, Drehung, Skalierung, Deckkraft und SH-Koeffizienten für die Darstellung auf Bildebene. Gemäß der Formel der 3D-Gaußschen Alphamischung ist es nicht schwer herauszufinden, dass die Position über die Zeit sowie die Rotation und Skalierung, die die Gaußsche Form steuert, die entscheidenden Parameter sind, die den dynamischen 3D-Gaußschen Verlauf bestimmen. Im Gegensatz zu herkömmlichen punktwolkenbasierten Rendering-Methoden werden Parameter wie Position und Transparenz jedoch nach der Initialisierung von 3D-Gauß durch Optimierung kontinuierlich aktualisiert. Dies erschwert das Erlernen dynamischer Gauß-Funktionen.Diese Forschung schlägt auf innovative Weise ein dynamisches Szenen-Rendering-Framework vor, das gemeinsam mit Deformationsfeldern und 3D-Gauß-Funktionen optimiert wird. Insbesondere behandelt diese Studie durch COLMAP initialisierte 3D-Gaußsche oder zufällige Punktwolken als kanonischen Raum und verwendet dann das Verformungsfeld, um die Koordinateninformationen der 3D-Gaußschen im kanonischen Raum als Eingabe zu verwenden, um die Position und Form jedes 3D-Gaußschen zu vorhersagen im Laufe der Zeit. Mithilfe von Deformationsfeldern kann diese Studie einen 3D-Gaußschen Raum vom kanonischen Raum in den Beobachtungsraum für die gerasterte Darstellung umwandeln. Diese Strategie hat keinen Einfluss auf die differenzierbare Rasterisierungspipeline von 3D-Gauß-Funktionen, und die von ihr berechneten Gradienten können zur Aktualisierung der Parameter der 3D-Gauß-Funktionen im kanonischen Raum verwendet werden.
Darüber hinaus ist die Einführung eines Verformungsfeldes vorteilhaft für die Gaußsche Verdichtung von Teilen mit größeren Bewegungsbereichen. Dies liegt daran, dass der Gradient des Verformungsfeldes in Bereichen mit größeren Bewegungsamplituden relativ höher ist, was dazu führt, dass die entsprechenden Bereiche während des Verdichtungsprozesses feiner reguliert werden. Auch wenn die Anzahl und Positionsparameter der 3D-Gaußschen Werte im kanonischen Raum im Frühstadium ständig aktualisiert werden, zeigen die experimentellen Ergebnisse, dass diese gemeinsame Optimierungsstrategie letztendlich robuste Konvergenzergebnisse erzielen kann. Nach etwa 20.000 Iterationen ändern sich die Positionsparameter des 3D-Gauß-Operators im kanonischen Raum kaum noch.
Das Forschungsteam stellte fest, dass Kamerapositionen in realen Szenen oft nicht genau genug sind und dynamische Szenen dieses Problem verschärfen. Auf die auf dem neuronalen Strahlungsfeld basierende Struktur wird dies keine großen Auswirkungen haben, da das neuronale Strahlungsfeld auf dem Multilayer-Perzeptron (MLP) basiert und eine sehr glatte Struktur darstellt. Allerdings basiert 3D-Gauß auf der expliziten Struktur von Punktwolken, und leicht ungenaue Kamerapositionen lassen sich durch Gauß-Splashing nur schwer robust korrigieren.
Um dieses Problem zu lindern, wurde in dieser Studie das Annealing Smooth Training (AST) innovativ eingeführt. Dieser Trainingsmechanismus soll das Erlernen von 3D-Gauß-Funktionen in der frühen Phase erleichtern und die Rendering-Details in der späteren Phase verbessern. Die Einführung dieses Mechanismus verbessert nicht nur die Qualität des Renderings, sondern verbessert auch die Stabilität und Glätte der zeitlichen Interpolationsaufgabe erheblich.
Abbildung 2 zeigt die Pipeline dieser Forschung. Einzelheiten finden Sie im Originalpapier. Abbildung 2 Die Pipeline dieser Studie.

ErgebnisanzeigeDiese Studie führte zunächst Experimente mit synthetischen Datensätzen am D-NeRF-Datensatz durch, der im Bereich der dynamischen Rekonstruktion weit verbreitet ist. Aus den Visualisierungsergebnissen in Abbildung 3 ist nicht schwer zu erkennen, dass Deformable-GS im Vergleich zur vorherigen Methode eine enorme Verbesserung der Rendering-Qualität aufweist. Abbildung 3 Qualitative experimentelle Vergleichsergebnisse dieser Studie zum D-NeRF-Datensatz.
Die in dieser Studie vorgeschlagene Methode hat nicht nur erhebliche Verbesserungen bei den visuellen Effekten erzielt, sondern auch entsprechende Verbesserungen bei den quantitativen Rendering-Indikatoren. Es ist erwähnenswert, dass das Forschungsteam Fehler in den Lego-Szenen des D-NeRF-Datensatzes festgestellt hat, d. h. es gibt geringfügige Unterschiede zwischen den Szenen im Trainingssatz und im Testsatz. Dies spiegelt sich im inkonsistenten Kippwinkel der Lego-Modellschaufel wider. Dies ist auch der wesentliche Grund, warum die Indikatoren der bisherigen Methode in der Lego-Szene nicht verbessert werden können. Um aussagekräftige Vergleiche zu ermöglichen, verwendete die Studie den Validierungssatz von Lego als Basis für metrische Messungen. Abbildung 4 Quantitativer Vergleich synthetischer Datensätze.
Wie in Abbildung 4 dargestellt, verglich diese Studie SOTA-Methoden bei voller Auflösung (800 x 800), einschließlich D-NeRF von CVPR 2020, TiNeuVox von Sig Asia 2022 und Tensor4D von CVPR2023, K-Ebenen. Die in dieser Studie vorgeschlagene Methode hat bei verschiedenen Rendering-Indikatoren (PSNR, SSIM, LPIPS) und in verschiedenen Szenarien erhebliche Verbesserungen erzielt. Die in dieser Studie vorgeschlagene Methode ist nicht nur auf synthetische Szenen anwendbar, sondern erzielt auch SOTA-Ergebnisse in realen Szenen, in denen die Kamerahaltung nicht genau genug ist. Wie in Abbildung 5 dargestellt, wird diese Studie mit der SOTA-Methode für den NeRF-DS-Datensatz verglichen. Experimentelle Ergebnisse zeigen, dass die in dieser Studie vorgeschlagene Methode auch ohne spezielle Verarbeitung stark lichtreflektierender Oberflächen NeRF-DS, das speziell für stark lichtreflektierende Szenen entwickelt wurde, immer noch übertreffen und den besten Rendering-Effekt erzielen kann.
Die in dieser Studie vorgeschlagene Methode ist nicht nur auf synthetische Szenen anwendbar, sondern erzielt auch SOTA-Ergebnisse in realen Szenen, in denen die Kamerahaltung nicht genau genug ist. Wie in Abbildung 5 dargestellt, wird diese Studie mit der SOTA-Methode für den NeRF-DS-Datensatz verglichen. Experimentelle Ergebnisse zeigen, dass die in dieser Studie vorgeschlagene Methode auch ohne spezielle Verarbeitung stark lichtreflektierender Oberflächen NeRF-DS, das speziell für stark lichtreflektierende Szenen entwickelt wurde, immer noch übertreffen und den besten Rendering-Effekt erzielen kann.

Obwohl die Einführung von MLP den Rendering-Overhead erhöht, können wir dank der äußerst effizienten CUDA-Implementierung von 3D Gaussian und unserer kompakten MLP-Struktur immer noch Echtzeit-Rendering erreichen. Auf 3090 kann die durchschnittliche FPS des D-NeRF-Datensatzes 85 (400 x 400) bzw. 68 (800 x 800) erreichen.
Darüber hinaus wendet diese Forschung erstmals auch eine differenzierbare Gaußsche Rasterisierungspipeline mit Vorwärts- und Rückwärts-Tiefenausbreitung an. Wie in Abbildung 6 dargestellt, beweist diese Tiefe auch, dass Deformable-GS auch robuste geometrische Darstellungen erhalten kann. Deep Backpropagation kann viele Aufgaben fördern, die in Zukunft eine umfassende Überwachung erfordern, wie z. B. Inverse Rendering (Inverse Rendering), SLAM und autonomes Fahren. Abbildung 6 Tiefenvisualisierung.Der erste Autor des Artikels: Yang Ziyi, ein Masterstudent im zweiten Jahr an der Zhejiang-Universität. Seine Hauptforschungsrichtungen sind dreidimensionale Gaußsche Felder, neuronale Strahlungsfelder, Echtzeit-Rendering, usw. 
Andere Autoren des Artikels: Gao Xinyu, ein Masterstudent im dritten Jahr an der Zhejiang-Universität. Sein Forschungsschwerpunkt sind neuronale Strahlungsfelder und implizite Szenenkombinationen.
Zhang Yuqing: Masterstudentin im zweiten Jahr an der Zhejiang-Universität. Ihre Hauptforschungsrichtung ist 3D-Generierung und Reverse Rendering.Der korrespondierende Autor des Artikels ist Professor Jin Xiaogang von der School of Computer Science and Technology der Zhejiang University.
E-Mail: jin@cad.zju.edu.cnDas obige ist der detaillierte Inhalt vonCVPR 2024-Partiturarbeit: Die Zhejiang-Universität schlägt eine neue Methode zur hochwertigen monokularen dynamischen Rekonstruktion auf der Grundlage verformbarer dreidimensionaler Gauß-Funktionen vor. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

 4090生成器:与A100平台相比,token生成速度仅低于18%,上交推理引擎赢得热议Dec 21, 2023 pm 03:25 PM
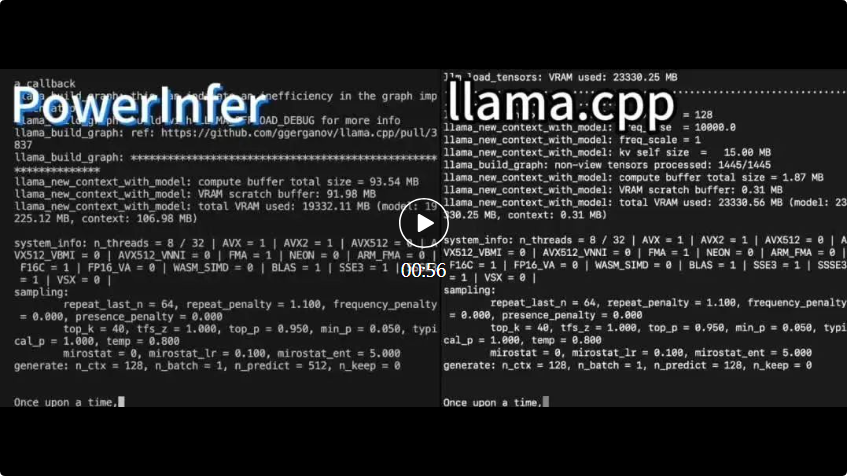
4090生成器:与A100平台相比,token生成速度仅低于18%,上交推理引擎赢得热议Dec 21, 2023 pm 03:25 PMPowerInfer提高了在消费级硬件上运行AI的效率上海交大团队最新推出了超强CPU/GPULLM高速推理引擎PowerInfer。PowerInfer和llama.cpp都在相同的硬件上运行,并充分利用了RTX4090上的VRAM。这个推理引擎速度有多快?在单个NVIDIARTX4090GPU上运行LLM,PowerInfer的平均token生成速率为13.20tokens/s,峰值为29.08tokens/s,仅比顶级服务器A100GPU低18%,可适用于各种LLM。PowerInfer与
 思维链CoT进化成思维图GoT,比思维树更优秀的提示工程技术诞生了Sep 05, 2023 pm 05:53 PM
思维链CoT进化成思维图GoT,比思维树更优秀的提示工程技术诞生了Sep 05, 2023 pm 05:53 PM要让大型语言模型(LLM)充分发挥其能力,有效的prompt设计方案是必不可少的,为此甚至出现了promptengineering(提示工程)这一新兴领域。在各种prompt设计方案中,思维链(CoT)凭借其强大的推理能力吸引了许多研究者和用户的眼球,基于其改进的CoT-SC以及更进一步的思维树(ToT)也收获了大量关注。近日,苏黎世联邦理工学院、Cledar和华沙理工大学的一个研究团队提出了更进一步的想法:思维图(GoT)。让思维从链到树到图,为LLM构建推理过程的能力不断得到提升,研究者也通
 复旦NLP团队发布80页大模型Agent综述,一文纵览AI智能体的现状与未来Sep 23, 2023 am 09:01 AM
复旦NLP团队发布80页大模型Agent综述,一文纵览AI智能体的现状与未来Sep 23, 2023 am 09:01 AM近期,复旦大学自然语言处理团队(FudanNLP)推出LLM-basedAgents综述论文,全文长达86页,共有600余篇参考文献!作者们从AIAgent的历史出发,全面梳理了基于大型语言模型的智能代理现状,包括:LLM-basedAgent的背景、构成、应用场景、以及备受关注的代理社会。同时,作者们探讨了Agent相关的前瞻开放问题,对于相关领域的未来发展趋势具有重要价值。论文链接:https://arxiv.org/pdf/2309.07864.pdfLLM-basedAgent论文列表:
 吞吐量提升5倍,联合设计后端系统和前端语言的LLM接口来了Mar 01, 2024 pm 10:55 PM
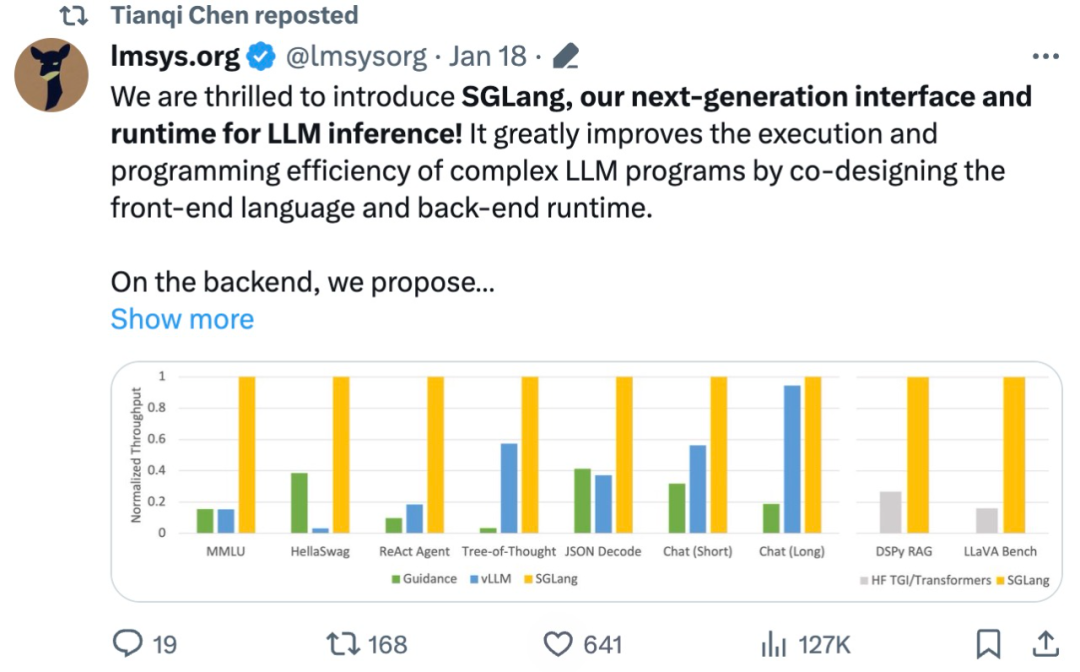
吞吐量提升5倍,联合设计后端系统和前端语言的LLM接口来了Mar 01, 2024 pm 10:55 PM大型语言模型(LLM)被广泛应用于需要多个链式生成调用、高级提示技术、控制流以及与外部环境交互的复杂任务。尽管如此,目前用于编程和执行这些应用程序的高效系统却存在明显的不足之处。研究人员最近提出了一种新的结构化生成语言(StructuredGenerationLanguage),称为SGLang,旨在改进与LLM的交互性。通过整合后端运行时系统和前端语言的设计,SGLang使得LLM的性能更高、更易控制。这项研究也获得了机器学习领域的知名学者、CMU助理教授陈天奇的转发。总的来说,SGLang的
 大模型也有小偷?为保护你的参数,上交大给大模型制作「人类可读指纹」Feb 02, 2024 pm 09:33 PM
大模型也有小偷?为保护你的参数,上交大给大模型制作「人类可读指纹」Feb 02, 2024 pm 09:33 PM将不同的基模型象征为不同品种的狗,其中相同的「狗形指纹」表明它们源自同一个基模型。大模型的预训练需要耗费大量的计算资源和数据,因此预训练模型的参数成为各大机构重点保护的核心竞争力和资产。然而,与传统软件知识产权保护不同,对预训练模型参数盗用的判断存在以下两个新问题:1)预训练模型的参数,尤其是千亿级别模型的参数,通常不会开源。预训练模型的输出和参数会受到后续处理步骤(如SFT、RLHF、continuepretraining等)的影响,这使得判断一个模型是否基于另一个现有模型微调得来变得困难。无
 FATE 2.0发布:实现异构联邦学习系统互联Jan 16, 2024 am 11:48 AM
FATE 2.0发布:实现异构联邦学习系统互联Jan 16, 2024 am 11:48 AMFATE2.0全面升级,推动隐私计算联邦学习规模化应用FATE开源平台宣布发布FATE2.0版本,作为全球领先的联邦学习工业级开源框架。此次更新实现了联邦异构系统之间的互联互通,持续增强了隐私计算平台的互联互通能力。这一进展进一步推动了联邦学习与隐私计算规模化应用的发展。FATE2.0以全面互通为设计理念,采用开源方式对应用层、调度、通信、异构计算(算法)四个层面进行改造,实现了系统与系统、系统与算法、算法与算法之间异构互通的能力。FATE2.0的设计兼容了北京金融科技产业联盟的《金融业隐私计算
 220亿晶体管,IBM机器学习专用处理器NorthPole,能效25倍提升Oct 23, 2023 pm 03:13 PM
220亿晶体管,IBM机器学习专用处理器NorthPole,能效25倍提升Oct 23, 2023 pm 03:13 PMIBM再度发力。随着AI系统的飞速发展,其能源需求也在不断增加。训练新系统需要大量的数据集和处理器时间,因此能耗极高。在某些情况下,执行一些训练好的系统,智能手机就能轻松胜任。但是,执行的次数太多,能耗也会增加。幸运的是,有很多方法可以降低后者的能耗。IBM和英特尔已经试验过模仿实际神经元行为设计的处理器。IBM还测试了在相变存储器中执行神经网络计算,以避免重复访问RAM。现在,IBM又推出了另一种方法。该公司的新型NorthPole处理器综合了上述方法的一些理念,并将其与一种非常精简的计算运行
 制作莫比乌斯环,最少需要多长纸带?50年来的谜题被解开了Oct 07, 2023 pm 06:17 PM
制作莫比乌斯环,最少需要多长纸带?50年来的谜题被解开了Oct 07, 2023 pm 06:17 PM自己动手做过莫比乌斯带吗?莫比乌斯带是一种奇特的数学结构。要构造一个这样美丽的单面曲面其实非常简单,即使是小孩子也可以轻松完成。你只需要取一张纸带,扭曲一次,然后将两端粘在一起。然而,这样容易制作的莫比乌斯带却有着复杂的性质,长期吸引着数学家们的兴趣。最近,研究人员一直被一个看似简单的问题困扰着,那就是关于制作莫比乌斯带所需纸带的最短长度?布朗大学RichardEvanSchwartz谈到,对于莫比乌斯带来说,这个问题没有解决,因为它们是「嵌入的」而不是「浸入的」,这意味着它们不会相互渗透或自我


Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Dreamweaver Mac
Visuelle Webentwicklungstools

DVWA
Damn Vulnerable Web App (DVWA) ist eine PHP/MySQL-Webanwendung, die sehr anfällig ist. Seine Hauptziele bestehen darin, Sicherheitsexperten dabei zu helfen, ihre Fähigkeiten und Tools in einem rechtlichen Umfeld zu testen, Webentwicklern dabei zu helfen, den Prozess der Sicherung von Webanwendungen besser zu verstehen, und Lehrern/Schülern dabei zu helfen, in einer Unterrichtsumgebung Webanwendungen zu lehren/lernen Sicherheit. Das Ziel von DVWA besteht darin, einige der häufigsten Web-Schwachstellen über eine einfache und unkomplizierte Benutzeroberfläche mit unterschiedlichen Schwierigkeitsgraden zu üben. Bitte beachten Sie, dass diese Software

Dreamweaver CS6
Visuelle Webentwicklungstools

EditPlus chinesische Crack-Version
Geringe Größe, Syntaxhervorhebung, unterstützt keine Code-Eingabeaufforderungsfunktion

SublimeText3 Linux neue Version
SublimeText3 Linux neueste Version

