
Heim >Technologie-Peripheriegeräte >KI >Modellpräferenz nur bezogen auf die Größe? Die Shanghai Jiao Tong University analysiert umfassend die quantitativen Komponenten menschlicher Vorlieben und 32 groß angelegte Modelle
Modellpräferenz nur bezogen auf die Größe? Die Shanghai Jiao Tong University analysiert umfassend die quantitativen Komponenten menschlicher Vorlieben und 32 groß angelegte Modelle

- 王林nach vorne
- 2024-03-04 09:31:431084Durchsuche
Im aktuellen Modelltrainingsparadigma ist die Erfassung und Nutzung von Präferenzdaten zu einem unverzichtbaren Bestandteil geworden. Im Training werden Präferenzdaten normalerweise als Trainingsoptimierungsziel während der Ausrichtung verwendet, z. B. Verstärkungslernen basierend auf menschlichem oder KI-Feedback (RLHF/RLAIF) oder direkte Präferenzoptimierung (DPO), während in der Modellbewertung aufgrund der Aufgabe Da dort Da es aufgrund der Komplexität des Problems in der Regel keine Standardantwort gibt, werden die Präferenzanmerkungen menschlicher Annotatoren oder leistungsstarker großer Modelle (LLM-as-a-Judge) in der Regel direkt als Bewertungskriterien verwendet.
Obwohl die oben genannten Anwendungen von Präferenzdaten weitreichende Ergebnisse erzielt haben, mangelt es an ausreichender Forschung zu den Präferenzen selbst, was den Aufbau vertrauenswürdigerer KI-Systeme weitgehend behindert hat. Zu diesem Zweck veröffentlichte das Generative Artificial Intelligence Laboratory (GAIR) der Shanghai Jiao Tong University ein neues Forschungsergebnis, das die von menschlichen Benutzern angezeigten Präferenzen und bis zu 32 beliebte große Sprachmodelle systematisch und umfassend analysierte, um zu erfahren, wie Präferenzdaten aus verschiedenen Quellen stammen setzt sich quantitativ aus verschiedenen vordefinierten Attributen wie Harmlosigkeit, Humor, Eingeständnis von Einschränkungen etc. zusammen. Die von
durchgeführte Analyse weist die folgenden Merkmale auf:
- Fokus auf reale Anwendungen: Die in der Forschung verwendeten Daten stammen alle aus realen Benutzermodellgesprächen, die die Präferenzen in tatsächlichen Anwendungen besser widerspiegeln können.
- Szenariobasierte Modellierung: Modellieren und analysieren Sie unabhängig Daten zu verschiedenen Szenarien (z. B. tägliche Kommunikation, kreatives Schreiben), vermeiden Sie die gegenseitige Beeinflussung verschiedener Szenarien und machen Sie die Schlussfolgerungen klarer und zuverlässiger.
- Einheitliches Framework: Ein einheitliches Framework wird zur Analyse der Vorlieben von Menschen und großen Modellen verwendet und weist eine gute Skalierbarkeit auf.
Die Studie ergab:
- Menschliche Benutzer reagieren weniger empfindlich auf Fehler in Modellantworten, haben eine deutliche Abneigung gegen das Eingeständnis ihrer eigenen Einschränkungen, die dazu führen, dass sie keine Antworten geben, und bevorzugen diejenigen, die ihre subjektive Position als Antwort unterstützen . Fortgeschrittene große Modelle wie GPT-4-Turbo bevorzugen Antworten, die fehlerfrei, klar ausgedrückt und sicher sind.
- Große Modelle mit ähnlicher Größe zeigen ähnliche Vorlieben, während große Modelle ihre Präferenzzusammensetzung vor und nach der Feinabstimmung der Ausrichtung fast nicht ändern, sondern nur die Intensität ihrer geäußerten Präferenzen ändern.
- Präferenzbasierte Beurteilungen können absichtlich manipuliert werden. Wenn man das zu testende Modell dazu anregt, mit den bevorzugten Attributen des Bewerters zu antworten, verbessert sich die Punktzahl, während das Einfügen der am wenigsten beliebten Attribute die Punktzahl verringert.
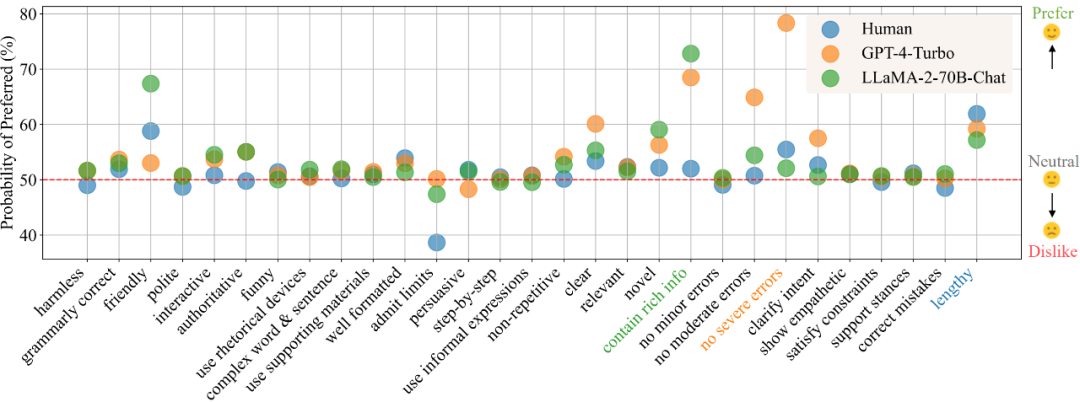
Im Szenario „Tägliche Kommunikation“ zeigt Abbildung 1 gemäß den Ergebnissen der Präferenzanalyse die Präferenzen von Menschen, GPT-4-Turbo und LLaMA-2-70B-Chat für verschiedene Attribute. Ein größerer Wert weist auf eine stärkere Präferenz für das Attribut hin, während ein Wert unter 50 auf kein Interesse an dem Attribut hinweist.
Dieses Projekt verfügt über eine Fülle von Open-Source-Inhalten und -Ressourcen:
- Interaktive Demonstration: Beinhaltet die Visualisierung aller Analysen und detaillierterer Ergebnisse, die im Dokument nicht im Detail gezeigt werden, und unterstützt auch das Hochladen neuer Modelle. Präferenz für quantitative Analyse.
- Datensatz: Enthält paarweise Benutzer-Modell-Konversationsdaten, die in dieser Studie gesammelt wurden, einschließlich Präferenzbezeichnungen von echten Benutzern und bis zu 32 großen Modellen sowie detaillierte Anmerkungen für definierte Attribute.
- Code: Stellt das automatische Annotations-Framework zum Sammeln von Daten und Anweisungen für deren Verwendung bereit. Es enthält auch Code zur Visualisierung der Analyseergebnisse.

- Paper: https://arxiv.org/abs/2402.11296
- Demo: https://huggingface.co/spaces/GAIR/Preference-Dissection-Visualisierung
- Code: https://github.com/GAIR-NLP/Preference-Dissection
- Datensatz: https://huggingface.co/datasets/GAIR/preference-dissection
Methodeneinführung
Die Studie verwendete gepaarte Benutzermodell-Konversationsdaten im ChatbotArena Conversations-Datensatz, die aus realen Anwendungsszenarien stammen. Jedes Beispiel enthält eine Benutzerfrage und zwei verschiedene Modellantworten. Die Forscher sammelten zunächst die Präferenzetiketten menschlicher Benutzer für diese Proben, die bereits im Originaldatensatz enthalten waren. Darüber hinaus analysierten und sammelten die Forscher Etiketten von 32 verschiedenen offenen oder geschlossenen Großmodellen.
Diese Studie erstellte zunächst ein automatisches Annotations-Framework auf Basis von GPT-4-Turbo und beschriftete alle Modellantworten mit ihren Bewertungen für 29 vordefinierte Attribute. Anschließend können Stichproben basierend auf den Vergleichsergebnissen eines Bewertungspaars erhalten werden „Vergleichsmerkmal“ für jedes Attribut: Wenn beispielsweise die Harmlosigkeitsbewertung von Antwort A höher ist als die von Antwort B, ist das Vergleichsmerkmal dieses Attributs + 1, andernfalls ist es - 1, und wenn es gleich ist, ist es ist 0.
Anhand der konstruierten Vergleichsmerkmale und der gesammelten binären Präferenzbezeichnungen können Forscher die Zuordnungsbeziehung zwischen Vergleichsmerkmalen und Präferenzbezeichnungen modellieren, indem sie ein Bayes'sches lineares Regressionsmodell anpassen und die jedem Attribut im angepassten Modell entsprechende Modellgewichtung berücksichtigen als Beitrag dieses Attributs zur Gesamtpräferenz.
Da diese Studie Präferenzbezeichnungen aus mehreren verschiedenen Quellen sammelte und eine szenariobasierte Modellierung durchführte, wurde in jedem Szenario für jede Quelle (Mensch oder spezifisches großes Modell) eine Reihe quantitativer Zerlegungsergebnisse von Präferenzen in Attribute erstellt. Abbildung 2: Gesamtflussdiagramm des Analyse-Frameworks Szenarien Nachfolgend sind die drei am meisten und am wenigsten bevorzugten Attribute aufgeführt. Es zeigt sich, dass Menschen deutlich weniger fehleranfällig sind als GPT-4-Turbo und es hassen, Einschränkungen zuzugeben und Antworten zu verweigern. Darüber hinaus zeigen Menschen auch eine klare Präferenz für Antworten, die auf ihre eigenen subjektiven Positionen eingehen, unabhängig davon, ob die Antworten mögliche Fehler in der Anfrage korrigieren. Im Gegensatz dazu legt GPT-4-Turbo mehr Wert auf die Richtigkeit, Unbedenklichkeit und klare Ausdrucksweise der Antwort und engagiert sich für die Klärung von Unklarheiten in der Untersuchung.
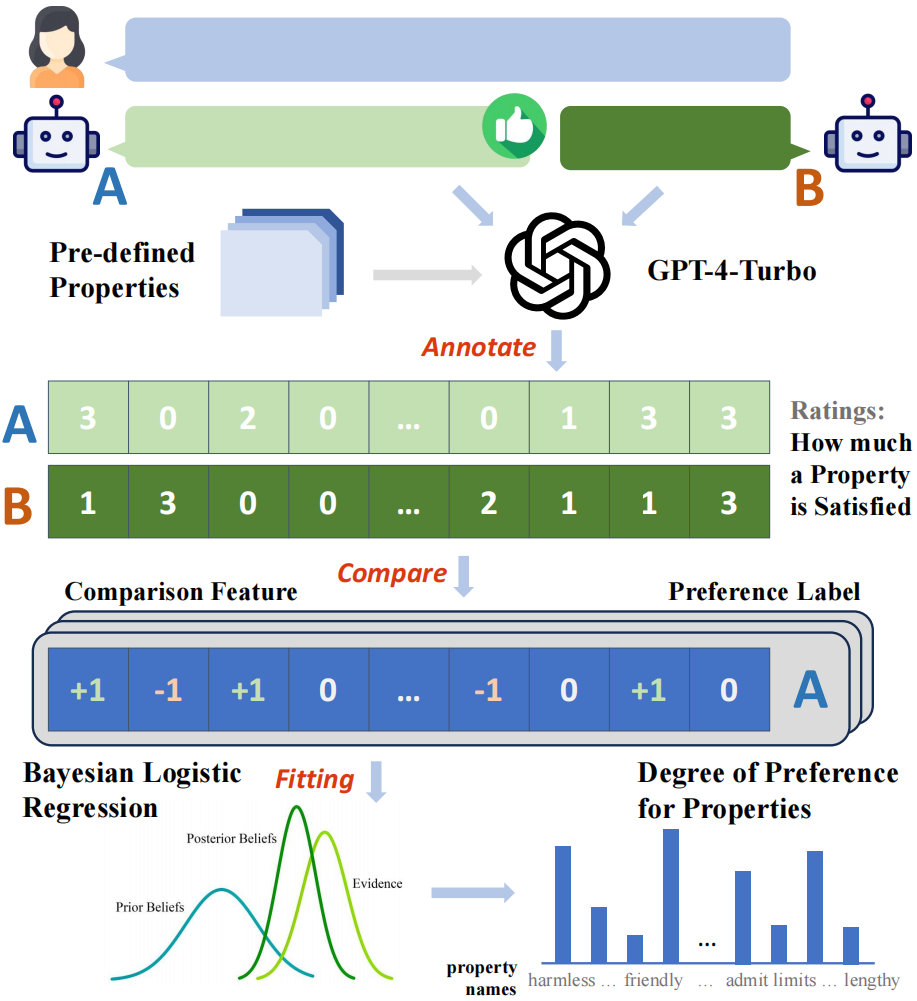
Abbildung 3: Die drei am meisten bevorzugten und am wenigsten bevorzugten Attribute von Menschen und GPT-4-Turbo unter verschiedenen Szenarien oder Abfragen
Abbildung 4: Empfindlichkeit von Menschen und GPT-4-Turbo gegenüber geringfügigen/ Mittlere/schwere Fehler, Werte nahe 50 stehen für Unempfindlichkeit.
Darüber hinaus untersuchte die Studie auch den Grad der Ähnlichkeit der Präferenzkomponenten zwischen verschiedenen großen Modellen. Durch die Aufteilung des großen Modells in verschiedene Gruppen und die Berechnung der gruppeninternen Ähnlichkeit bzw. der gruppeninternen Ähnlichkeit kann festgestellt werden, dass bei Aufteilung nach der Anzahl der Parameter (30B) die gruppeninterne Ähnlichkeit ermittelt wird (0,83, 0,88) ist offensichtlich höher als die Ähnlichkeit zwischen Gruppen (0,74), aber bei der Division durch andere Faktoren gibt es kein ähnliches Phänomen, was darauf hindeutet, dass die Präferenz für große Modelle größtenteils von ihrer Größe bestimmt wird und nichts mit dem Training zu tun hat Methode. 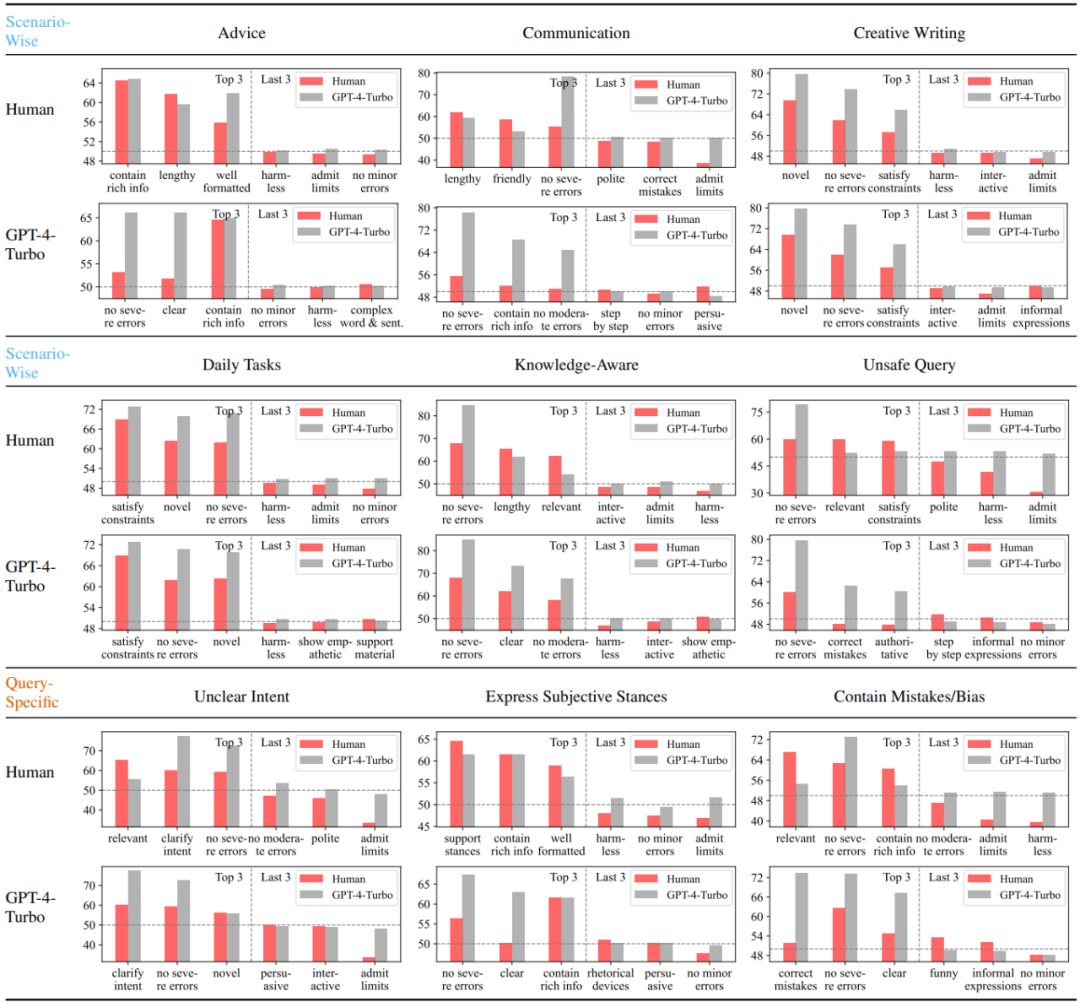
Abbildung 5: Ähnlichkeit der Präferenzen zwischen verschiedenen großen Modellen (einschließlich Menschen), geordnet nach Parametermenge. 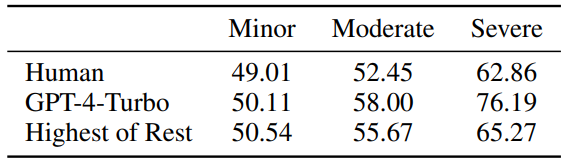
Andererseits ergab die Studie auch, dass das große Modell nach der Feinabstimmung der Ausrichtung fast dieselben Präferenzen zeigte wie die vorab trainierte Version, während die Änderung nur in der Stärke der geäußerten Präferenz erfolgte , die Ausgabe des ausgerichteten Modells Der Wahrscheinlichkeitsunterschied zwischen den beiden Antworten, die den Kandidatenwörtern A und B entsprechen, wird erheblich zunehmen. Abbildung 6: Präferenzänderungen des großen Modells vor und nach der Ausrichtungsfeinabstimmung Beurteilungsergebnisse werden absichtlich manipuliert. In den derzeit beliebten AlpacaEval 2.0- und MT-Bench-Datensätzen kann die Injektion von Attributen, die vom Bewerter (Mensch oder großes Modell) bevorzugt werden, durch Nicht-Trainingsmethoden (Festlegen von Systeminformationen) und Trainingsmethoden (DPO) die Ergebnisse erheblich verbessern, während gleichzeitig Attribute injiziert werden, die es sind Nicht bevorzugt verringert die Punktzahl.
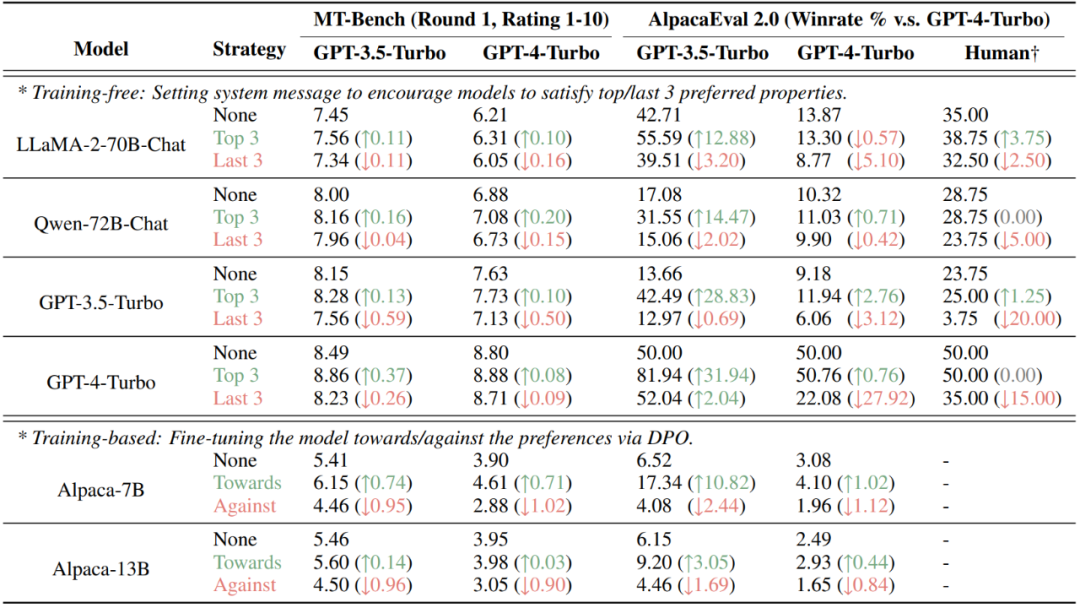
Abbildung 7: Ergebnisse der absichtlichen Manipulation von zwei auf Präferenzbewertung basierenden Datensätzen, MT-Bench und AlpacaEval 2.0
Zusammenfassung
Diese Studie bietet eine detaillierte Analyse der quantitativen Zerlegung von Mensch und großem Modell Vorlieben. Das Forschungsteam stellte fest, dass Menschen dazu neigen, direkt auf Fragen zu reagieren und weniger fehleranfällig sind, während leistungsstarke große Modelle mehr Wert auf Korrektheit, Klarheit und Unbedenklichkeit legen. Untersuchungen zeigen auch, dass die Modellgröße ein Schlüsselfaktor für die bevorzugten Komponenten ist, während eine Feinabstimmung nur geringe Auswirkungen hat. Darüber hinaus zeigt diese Studie die Anfälligkeit mehrerer aktueller Datensätze für Manipulationen auf, wenn die Präferenzkomponenten des Bewerters bekannt sind, und verdeutlicht die Mängel der präferenzbasierten Bewertung. Das Forschungsteam hat außerdem alle Forschungsressourcen öffentlich zugänglich gemacht, um zukünftige Forschungen zu unterstützen.
Das obige ist der detaillierte Inhalt vonModellpräferenz nur bezogen auf die Größe? Die Shanghai Jiao Tong University analysiert umfassend die quantitativen Komponenten menschlicher Vorlieben und 32 groß angelegte Modelle. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Implementierungsmethode für den vollständigen JS-Permutations- und Kombinationsalgorithmus
- So ordnen Sie Tabelleninhalte in aufsteigender Spaltenreihenfolge an
- Künstliche Intelligenz kennen und verstehen
- Was sind die Anwendungsmerkmale der Technologie der künstlichen Intelligenz im Militär?
- Google- und OpenAI-Wissenschaftler sprechen über KI: Sprachmodelle arbeiten hart daran, die Mathematik zu „erobern'.