
Heim >Technologie-Peripheriegeräte >KI >Der Durchsatz wird um das Fünffache erhöht. Die LLM-Schnittstelle zum gemeinsamen Entwerfen des Back-End-Systems und der Front-End-Sprache ist vorhanden.
Der Durchsatz wird um das Fünffache erhöht. Die LLM-Schnittstelle zum gemeinsamen Entwerfen des Back-End-Systems und der Front-End-Sprache ist vorhanden.

- PHPznach vorne
- 2024-03-01 22:55:131305Durchsuche
Große Sprachmodelle (LLMs) werden häufig bei komplexen Aufgaben verwendet, die mehrere verkettete Generierungsaufrufe, erweiterte Hinweistechniken, Kontrollfluss und Interaktion mit der externen Umgebung erfordern. Dennoch weisen aktuelle effiziente Systeme zur Programmierung und Ausführung dieser Anwendungen erhebliche Mängel auf.
Forscher haben kürzlich eine neue strukturierte Generationssprache namens SGLang vorgeschlagen, die darauf abzielt, die Interaktivität mit LLM zu verbessern. Durch die Integration des Designs des Back-End-Laufzeitsystems und der Front-End-Sprache macht SGLang LLM leistungsfähiger und einfacher zu steuern. Diese Forschung wurde auch von Chen Tianqi vorangetrieben, einem bekannten Wissenschaftler auf dem Gebiet des maschinellen Lernens und CMU-Assistenzprofessor.
Im Allgemeinen umfassen die Beiträge von SGLang hauptsächlich:
Im Backend schlug das Forschungsteam RadixAttention vor, eine KV-Cache-Wiederverwendungstechnologie (KV-Cache) über mehrere LLM-Generierungsaufrufe hinweg, automatisch und effizient.
In der Frontend-Entwicklung entwickelte das Team eine flexible domänenspezifische Sprache, die in Python eingebettet werden kann, um den Generierungsprozess zu steuern. Diese Sprache kann im Interpretermodus oder Compilermodus ausgeführt werden.
Back-End- und Front-End-Komponenten arbeiten zusammen, um die Ausführung und Programmiereffizienz komplexer LLM-Programme zu verbessern.
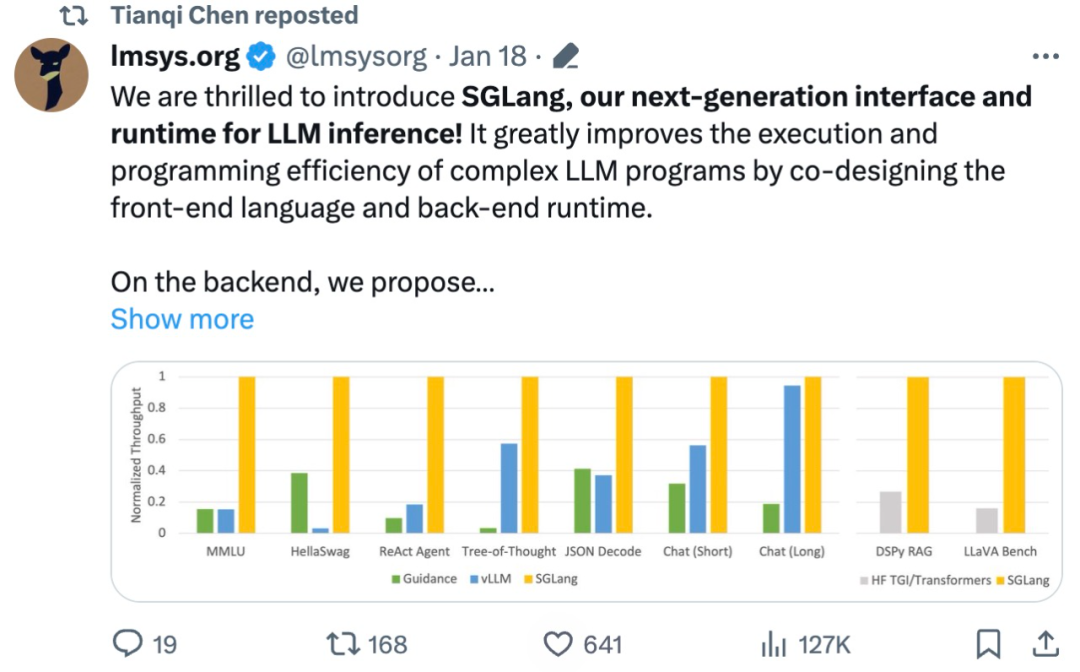
Diese Studie verwendet SGLang zur Implementierung gängiger LLM-Workloads, einschließlich Agenten-, Inferenz-, Extraktions-, Dialog- und Wenig-Schuss-Lernaufgaben, und übernimmt die Modelle Llama-7B und Mixtral-8x7B auf der NVIDIA A10G-GPU. Wie in Abbildung 1 und Abbildung 2 unten dargestellt, ist der Durchsatz von SGLang im Vergleich zu bestehenden Systemen (d. h. Guidance und vLLM) um das Fünffache erhöht.

Abbildung 1: Durchsatz verschiedener Systeme bei LLM-Aufgaben (A10G, Llama-7B bei FP16, Tensorparallelität = 1)
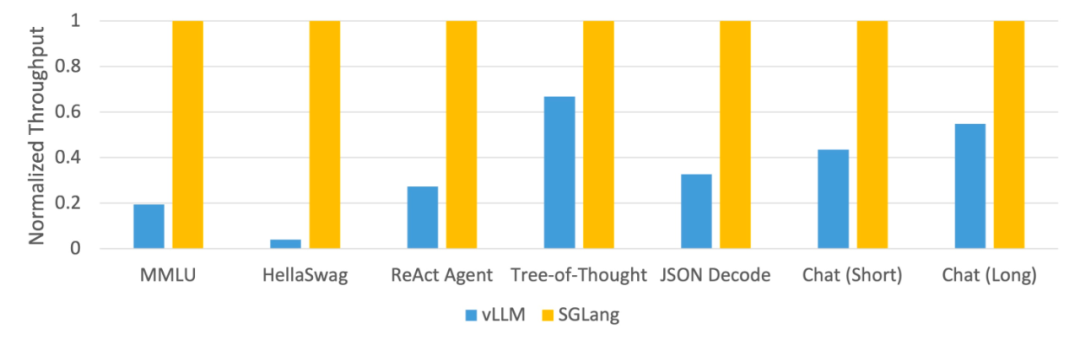
Abbildung 2: Durchsatz verschiedener Systeme bei LLM-Aufgaben ( Mixtral-8x7B auf A10G, FP16, Tensorparallelität = 8)
Backend: Automatische KV-Cache-Wiederverwendung mit RadixAttention
Während der Entwicklung der SGLang-Laufzeit entdeckte diese Studie den Schlüssel zur Optimierung komplexer LLM-Programme – die KV-Cache-Wiederverwendung , was von aktuellen Systemen nicht gut gehandhabt wird. Die Wiederverwendung des KV-Cache bedeutet, dass verschiedene Eingabeaufforderungen mit demselben Präfix den zwischengeschalteten KV-Cache gemeinsam nutzen können, wodurch redundanter Speicher und Berechnungen vermieden werden. In komplexen Programmen mit mehreren LLM-Aufrufen können verschiedene Modi der KV-Cache-Wiederverwendung vorhanden sein. Abbildung 3 unten zeigt vier solcher Muster, die häufig in LLM-Workloads vorkommen. Während einige Systeme in bestimmten Szenarien die Wiederverwendung von KV-Cache bewältigen können, sind häufig manuelle Konfigurationen und Ad-hoc-Anpassungen erforderlich. Darüber hinaus können sich bestehende Systeme aufgrund der Vielfalt möglicher Wiederverwendungsmuster auch durch manuelle Konfiguration nicht automatisch an alle Szenarien anpassen.
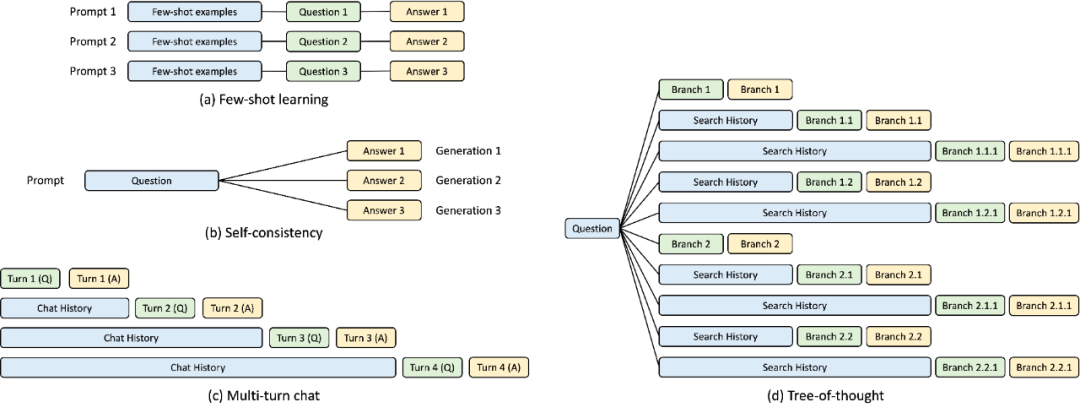
Abbildung 3: KV-Cache-Sharing-Beispiel. Das blaue Kästchen ist der teilbare Eingabeaufforderungsteil, das grüne Kästchen ist der nicht teilbare Teil und das gelbe Kästchen ist die nicht teilbare Modellausgabe. Zu den gemeinsam nutzbaren Teilen gehören kleine Lernbeispiele, Fragen zur Selbstkonsistenz, der Gesprächsverlauf über mehrere Dialogrunden hinweg und der Suchverlauf im Gedankenbaum.
Um diese Wiederverwendungsmöglichkeiten systematisch zu nutzen, schlägt diese Studie eine neue Methode zur automatischen KV-Cache-Wiederverwendung zur Laufzeit vor – RadixAttention. Anstatt den KV-Cache nach Abschluss der Build-Anfrage zu verwerfen, behält diese Methode die Eingabeaufforderung und den KV-Cache des Build-Ergebnisses in einem Basisbaum. Diese Datenstruktur ermöglicht eine effiziente Suche, Einfügung und Entfernung von Präfixen. Diese Studie implementiert eine Räumungsrichtlinie, die am wenigsten kürzlich verwendet wurde (LRU), ergänzt durch eine Cache-bewusste Planungsrichtlinie, um die Cache-Trefferquote zu verbessern.
Radixbäume können als platzsparende Alternative zu Versuchen (Präfixbäume) verwendet werden. Im Gegensatz zu typischen Bäumen können die Kanten von Radixbäumen nicht nur mit einem einzelnen Element, sondern auch mit Sequenzen von Elementen unterschiedlicher Länge markiert werden, was die Effizienz von Radixbäumen verbessert.
Diese Forschung verwendet einen Basisbaum, um die Zuordnung zwischen Token-Sequenzen, die als Schlüssel fungieren, und entsprechenden KV-Cache-Tensoren, die als Werte fungieren, zu verwalten. Diese KV-Cache-Tensoren werden auf der GPU in einem Seitenlayout gespeichert, wobei jede Seite die Größe eines Tokens hat.
Da die GPU-Speicherkapazität begrenzt ist und unbegrenzte KV-Cache-Tensoren nicht neu trainiert werden können, ist eine Räumungsstrategie erforderlich. Diese Studie verwendet die LRU-Räumungsstrategie, um Blattknoten rekursiv zu entfernen. Darüber hinaus ist RadixAttention mit bestehenden Technologien wie Continuous Batching und Paged Attention kompatibel. Für multimodale Modelle kann RadixAttention problemlos um die Verarbeitung von Bildtokens erweitert werden.
Das Diagramm unten zeigt, wie ein Basisbaum bei der Bearbeitung mehrerer eingehender Anfragen verwaltet wird. Das Frontend sendet immer die vollständige Eingabeaufforderung an die Laufzeit, und die Laufzeit führt automatisch den Präfixabgleich, die Wiederverwendung und das Caching durch. Die Baumstruktur wird auf der CPU gespeichert und verursacht einen geringen Wartungsaufwand.
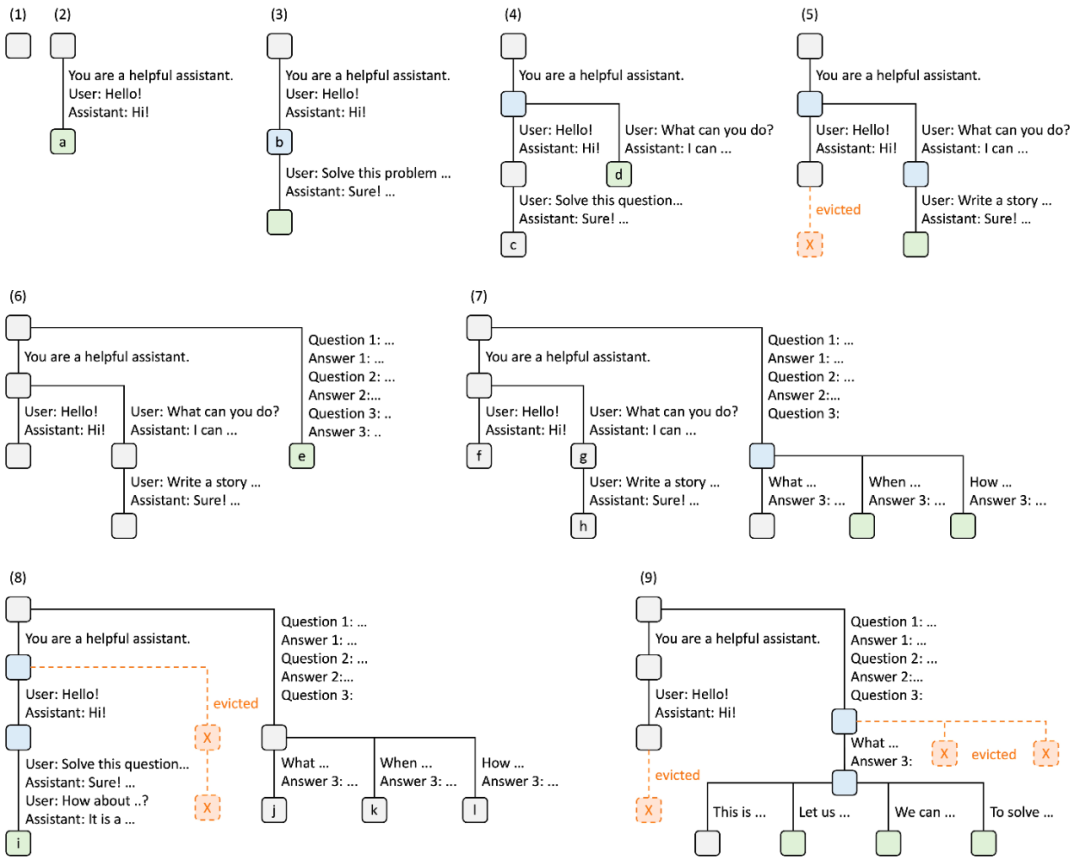
Abbildung 4. RadixAttention-Betriebsbeispiel unter Verwendung der LRU-Räumungsrichtlinie, erklärt in neun Schritten.
Abbildung 4 zeigt die dynamische Entwicklung des Basisbaums als Reaktion auf verschiedene Anfragen. Zu diesen Anfragen gehören zwei Chat-Sitzungen, eine Reihe von Lernabfragen mit wenigen Schüssen und selbstkonsistente Stichproben. Jede Baumkante ist mit einer Beschriftung gekennzeichnet, die einen Teilstring oder eine Folge von Token darstellt. Knoten sind farblich gekennzeichnet, um unterschiedliche Zustände widerzuspiegeln: Grün zeigt neu hinzugefügte Knoten an, Blau zeigt zwischengespeicherte Knoten an, auf die zu diesem Zeitpunkt zugegriffen wurde, und Rot zeigt Knoten an, die entfernt wurden.
Frontend: LLM-Programmierung leicht gemacht mit SGLang
Auf dem Frontend schlägt die Forschung SGLang vor, eine in Python eingebettete domänenspezifische Sprache, die den Ausdruck fortgeschrittener Eingabeaufforderungstechniken, Kontrollfluss und Multimodalität ermöglicht , Dekodierung von Einschränkungen und externen Interaktionen. SGLang-Funktionen können über verschiedene Backends wie OpenAI, Anthropic, Gemini und native Modelle ausgeführt werden.
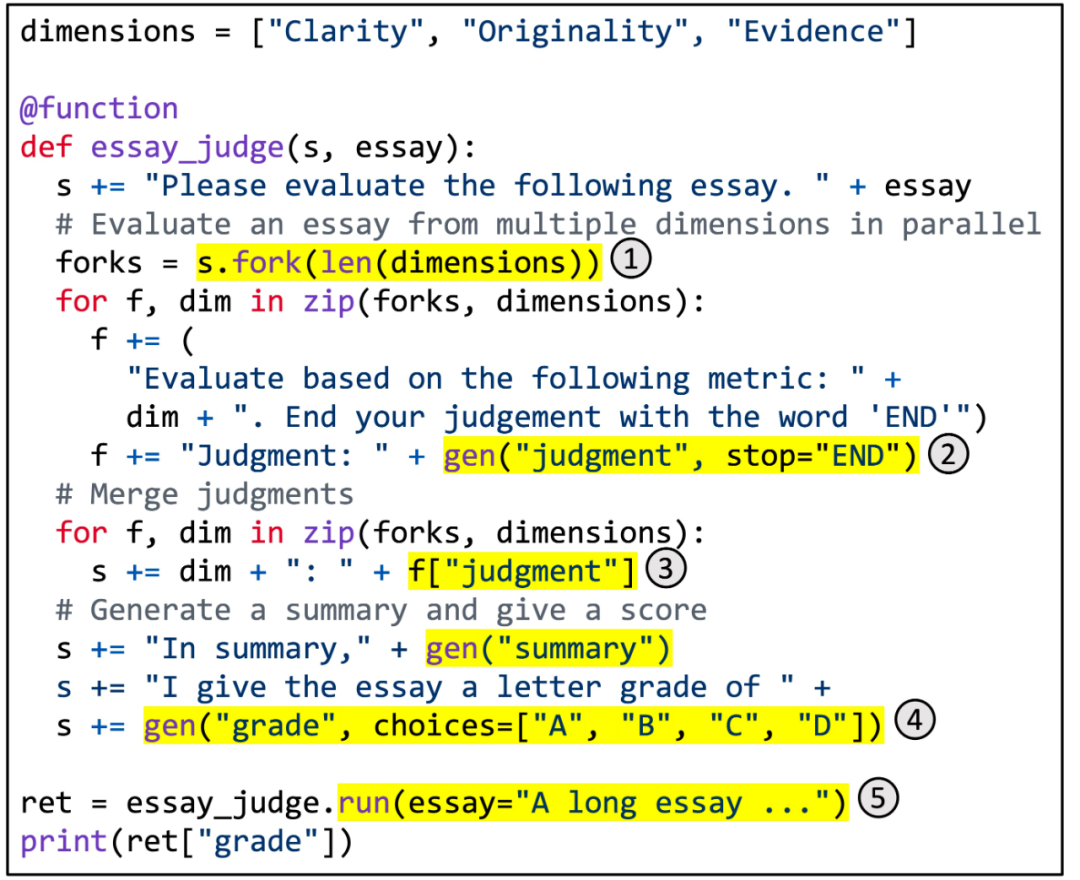
Abbildung 5. Verwendung von SGLang zur Implementierung der mehrdimensionalen Artikelbewertung.
Abbildung 5 zeigt ein konkretes Beispiel. Es nutzt die Branch-Resolve-Merge-Prompt-Technologie, um eine mehrdimensionale Artikelbewertung zu erreichen. Diese Funktion nutzt LLM, um die Qualität eines Artikels in mehreren Dimensionen zu bewerten, Beurteilungen zu kombinieren, eine Zusammenfassung zu erstellen und eine Abschlussnote zu vergeben. Der hervorgehobene Bereich veranschaulicht die Verwendung der SGLang-API. (1) Fork erstellt mehrere parallele Kopien der Eingabeaufforderung. (2) gen ruft die LLM-Generierung auf und speichert die Ergebnisse in Variablen. Dieser Aufruf ist nicht blockierend, sodass mehrere Build-Aufrufe gleichzeitig im Hintergrund ausgeführt werden können. (3) [Variablenname] ruft die generierten Ergebnisse ab. (4) Wählen Sie, ob Sie der Generierung Einschränkungen auferlegen möchten. (5) run führt die SGLang-Funktion unter Verwendung ihrer Parameter aus.
Bei einem solchen SGLang-Programm können wir es entweder über den Interpreter ausführen oder es als Datenflussdiagramm verfolgen und es mit einem Diagramm-Executor ausführen. Die letztere Situation eröffnet Raum für einige potenzielle Compiler-Optimierungen, wie z. B. Codeverschiebung, Befehlsauswahl und automatische Optimierung.
SGLangs Syntax ist stark von Guidance inspiriert und führt neue Grundelemente ein, die auch in-prozedurale Parallelität und Stapelverarbeitung verarbeiten. All diese neuen Funktionen tragen zur hervorragenden Leistung von SGLang bei.
Benchmarks
Das Forschungsteam testete sein System auf gängige LLM-Workloads und berichtete über den erreichten Durchsatz.
Konkret wurden in der Studie Llama-7B auf 1 NVIDIA A10G-GPU (24 GB), Mixtral-8x7B auf 8 NVIDIA A10G-GPUs mit Tensorparallelität und FP16-Genauigkeit sowie vllm v0.2.5, Guidance v0.1.8 und Hugging Face TGI v1 getestet .3.0 als Basissysteme.
Wie in Abbildung 1 und Abbildung 2 dargestellt, übertrifft SGLang das Basissystem in allen Benchmarks und erreicht eine 5-fache Steigerung des Durchsatzes. Auch im Hinblick auf die Latenz schneidet es gut ab, insbesondere bei der Latenz des ersten Tokens, wo Präfix-Cache-Treffer erhebliche Vorteile bringen können. Diese Verbesserungen sind auf die automatische KV-Cache-Wiederverwendung von RadixAttention, die durch den Interpreter ermöglichte programminterne Parallelität und das gemeinsame Design von Front-End- und Back-End-Systemen zurückzuführen. Darüber hinaus zeigen Ablationsstudien, dass kein nennenswerter Overhead entsteht, der dazu führt, dass RadixAttention zur Laufzeit immer aktiviert ist, auch wenn keine Cache-Treffer vorliegen.
Referenzlink: https://lmsys.org/blog/2024-01-17-sglang/
Das obige ist der detaillierte Inhalt vonDer Durchsatz wird um das Fünffache erhöht. Die LLM-Schnittstelle zum gemeinsamen Entwerfen des Back-End-Systems und der Front-End-Sprache ist vorhanden.. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!