Bei der aktuellen Entwicklung intelligenter Dialogmodelle spielen leistungsstarke zugrunde liegende Modelle eine entscheidende Rolle. Die Vorschulung dieser fortgeschrittenen Modelle basiert häufig auf hochwertigen und vielfältigen Korpora, und der Aufbau eines solchen Korpus ist in der Branche zu einer großen Herausforderung geworden. Im hochkarätigen Bereich der KI für Mathematik schränkt der relative Mangel an qualitativ hochwertigem mathematischen Korpus das Potenzial generativer künstlicher Intelligenz in mathematischen Anwendungen ein. Um dieser Herausforderung zu begegnen, hat das Generative Artificial Intelligence Laboratory der Shanghai Jiao Tong University „MathPile“ ins Leben gerufen. Hierbei handelt es sich um ein hochwertiges, vielfältiges Pre-Training-Korpus, das speziell auf den Bereich Mathematik ausgerichtet ist und etwa 9,5 Milliarden Token enthält und die Fähigkeiten großer Modelle im mathematischen Denken verbessern soll. Darüber hinaus hat das Labor auch die kommerzielle Version von MathPile – „MathPile_Commercial“ – auf den Markt gebracht, um seinen Anwendungsbereich und sein kommerzielles Potenzial weiter zu erweitern. 
- Forschungsverwendung: https://huggingface.co/datasets/GAIR/MathPile
- Kommerziell Version: https://huggingface.co/datasets/GAIR/MathPile_Commercial
MathPile hat die folgenden Funktionen: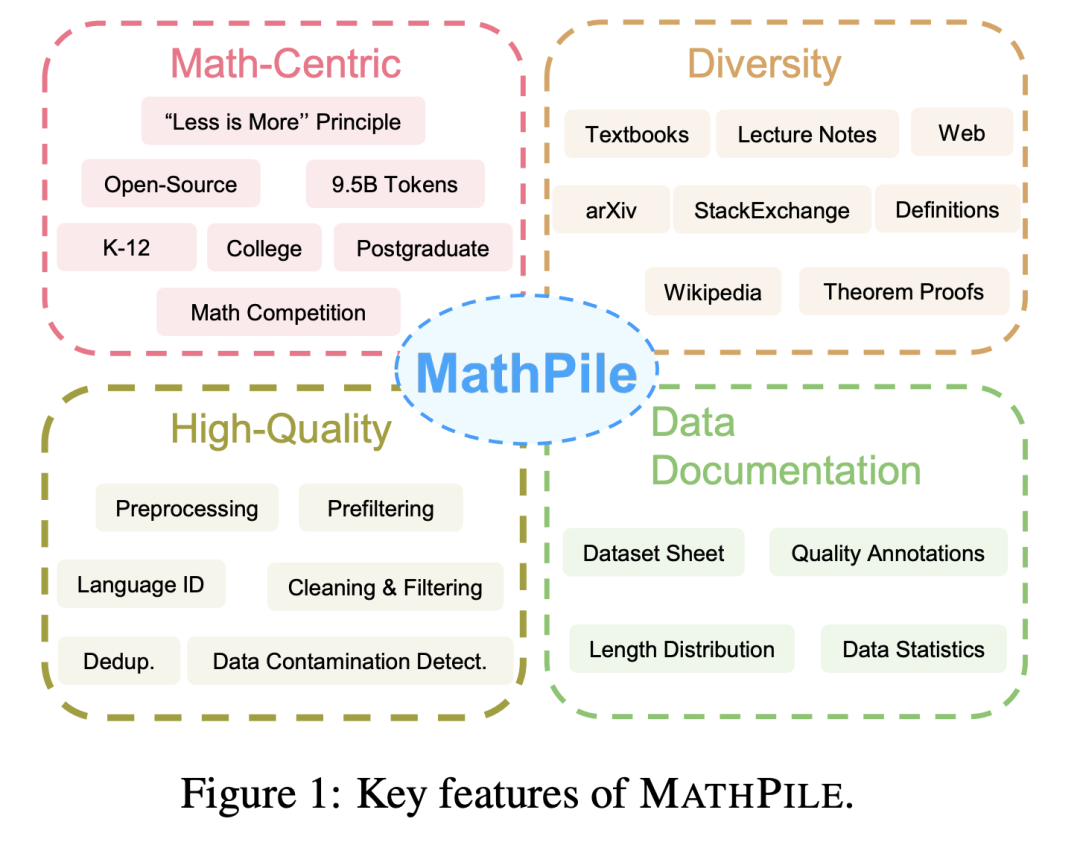
. 1. Mit Mathematik zentriert : Im Gegensatz zu früheren Korpora, die sich auf allgemeine Bereiche konzentrierten, wie Pile, RedPajama oder das mehrsprachige Korpus ROOTS usw., konzentriert sich MathPile auf den Bereich der Mathematik. Obwohl es bereits einige spezialisierte mathematische Korpora gibt, sind diese entweder nicht Open Source (wie das von Google zum Trainieren von Minerva verwendete Korpus, MathMix von OpenAI) oder nicht umfangreich und vielfältig genug (wie ProofPile und das aktuelle OpenWebMath). 2. Vielfalt Beweise und Definitionen für , hochwertige mathematische Fragen und Antworten auf StackExchange, einer Community-Q&A-Site, und Mathematik-Webseiten von Common Crawl. Die oben genannten Inhalte umfassen Inhalte, die für Grund- und weiterführende Schulen, Universitäten, Doktoranden und Mathematikwettbewerbe geeignet sind. MathPile deckt zum ersten Mal 0,19 Milliarden Token an hochwertigen Mathematiklehrbüchern ab. 3. Hohe Qualität: Das Forschungsteam folgt beim Erhebungsprozess dem Konzept „Weniger ist mehr“ und ist fest davon überzeugt, dass die Datenqualität bereits in der Vorschulungsphase besser ist als die Quantität. Ausgehend von einer Datenquelle von ca. 520 Milliarden Token (ca. 2,2 TB) durchliefen sie eine strenge und komplexe Reihe von Schritten zur Vorverarbeitung, Vorfilterung, Sprachidentifizierung, Bereinigung, Filterung und Deduplizierung, um die hohe Qualität des Korpus sicherzustellen. Es ist erwähnenswert, dass der von OpenAI verwendete MathMix nur über 1,5 Milliarden Token verfügt. 4. Datendokumentation: Um die Transparenz zu erhöhen, hat das Forschungsteam MathPile dokumentiert und ein Datensatzblatt bereitgestellt. Während des Datenverarbeitungsprozesses führte das Forschungsteam auch „Qualitätsannotationen“ an Dokumenten aus dem Web durch. Beispielsweise ermöglichen die Bewertung der Spracherkennung und das Verhältnis von Symbolen zu Wörtern im Dokument Forschern, Dokumente entsprechend ihren eigenen Bedürfnissen weiter zu filtern. Sie führten auch eine nachgeschaltete Testset-Kontaminationserkennung am Korpus durch, um Proben aus Benchmark-Testsets wie MATH und MMLU-STEM zu eliminieren. Gleichzeitig stellte das Forschungsteam auch fest, dass es in OpenWebMath auch eine große Anzahl nachgelagerter Testbeispiele gibt, was zeigt, dass bei der Erstellung des Pre-Training-Korpus besondere Vorsicht geboten ist, um ungültige nachgelagerte Auswertungen zu vermeiden. MathPiles Datenerfassungs- und -verarbeitungsprozess. 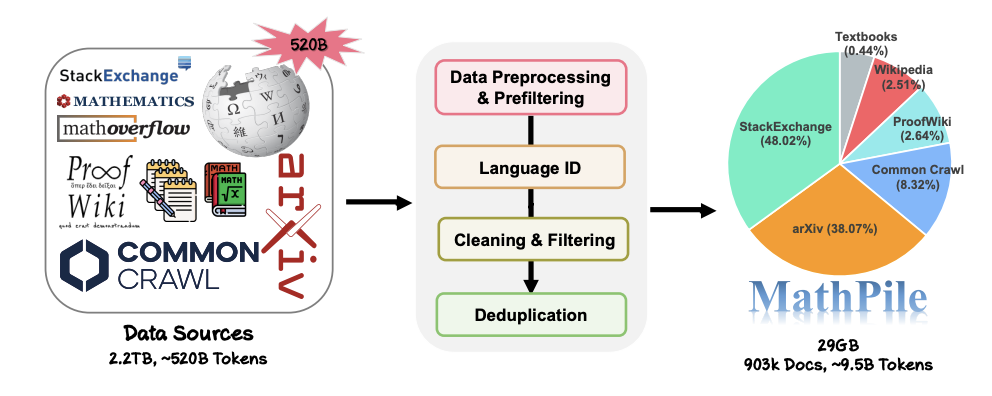 Details zur Datenverarbeitung Da sich der Wettbewerb im Bereich großer Modelle heute verschärft, geben viele Technologieunternehmen ihre Daten sowie ihre Datenquellen und -verhältnisse nicht mehr offen, ganz zu schweigen von detaillierten Vorverarbeitungsdetails. Im Gegenteil, MathPile fasst eine Reihe von Datenverarbeitungsmethoden zusammen, die für den Mathematikbereich geeignet sind und auf früheren Untersuchungen basieren. Im Datenbereinigungs- und Filterungsteil sind die spezifischen Schritte, die das Forschungsteam übernommen hat:
Details zur Datenverarbeitung Da sich der Wettbewerb im Bereich großer Modelle heute verschärft, geben viele Technologieunternehmen ihre Daten sowie ihre Datenquellen und -verhältnisse nicht mehr offen, ganz zu schweigen von detaillierten Vorverarbeitungsdetails. Im Gegenteil, MathPile fasst eine Reihe von Datenverarbeitungsmethoden zusammen, die für den Mathematikbereich geeignet sind und auf früheren Untersuchungen basieren. Im Datenbereinigungs- und Filterungsteil sind die spezifischen Schritte, die das Forschungsteam übernommen hat:
- Erkennen Sie Zeilen, die „lorem ipsum“ in der Zeile ersetzen mehr als 5 Zeichen, entfernen Sie die Zeile;
- Zeilen erkennen, die „javescript“ und auch „enable“, „disable“ oder „browser“ enthalten und die Anzahl der Zeichen in der Zeile weniger als 200 Zeichen beträgt, dann filtern die Zeile „Zeilen“ herausfiltern;
- Zeilen mit weniger als 10 Wörtern herausfiltern und „Anmelden“, „Anmelden“, „Weiterlesen…“ oder „Artikel im Warenkorb“ enthalten; Großbuchstaben: Dokumente, die mehr als 40 % ausmachen;
- Dokumente herausfiltern, bei denen Zeilen, die mit einem Auslassungszeichen enden, mehr als 30 % des gesamten Dokuments ausmachen; als 80 %;
- Dokumente herausfiltern, deren durchschnittliche englische Wortzeichenlänge außerhalb des Bereichs (3, 10) liegt;
- Dokumente herausfiltern, die nicht mindestens zwei Stoppwörter enthalten (z. B. das, be,
- Dokumente herausfiltern, bei denen das Verhältnis von Auslassungspunkten zu Wörtern 50 % übersteigt;
- Dokumente herausfiltern, bei denen Zeilen mit Aufzählungszeichen mehr als 90 % ausmachen; ;
- Leerzeichen und Dokumente mit weniger als 200 Zeichen nach Satzzeichen herausfiltern und entfernen;
- Weitere Verarbeitungsdetails finden Sie im Dokument.
-
Darüber hinaus stellte das Forschungsteam während des Reinigungsprozesses auch viele Datenproben zur Verfügung. Das Bild unten zeigt die nahezu doppelten Dokumente in Common Crawl, die vom MinHash LSH-Algorithmus erkannt wurden (in rosa Hervorhebungen dargestellt).
Wie in der Abbildung unten dargestellt, entdeckte das Forschungsteam während des Datenleckerkennungsprozesses Probleme im MATH-Testsatz (gelb hervorgehoben).
Datensatzstatistiken und Beispiele
Die folgende Tabelle zeigt die statistischen Informationen zu jeder Komponente von MathPile. Sie können feststellen, dass arXiv-Papiere und Lehrbücher normalerweise längere Dokumentlängen haben, während Dokumente in Wikis relativ kurz sind . 

Das Bild unten ist ein Beispieldokument eines Lehrbuchs im MathPile-Korpus. Es ist ersichtlich, dass die Dokumentstruktur relativ klar und die Qualität hoch ist.
Experimentelle ErgebnisseDas Forschungsteam veröffentlichte auch einige vorläufige experimentelle Ergebnisse. Sie führten ein weiteres Vortraining auf Basis des derzeit beliebten Mistral-7B-Modells durch. Anschließend wurde es anhand einiger gängiger Benchmark-Datensätze für mathematisches Denken mithilfe einer Methode mit wenigen Schüssen ausgewertet. Die bisher erhaltenen vorläufigen experimentellen Daten lauten wie folgt:
Diese Testbenchmarks decken alle Niveaus mathematischer Kenntnisse ab, einschließlich Grundschulmathematik (wie GSM8K, TAL-SCQ5K-EN und MMLU-Math), hoch Schulmathematik (z. B. MATH, SAT-Math, MMLU-Math, AQuA und MathQA) und Hochschulmathematik (z. B. MMLU-Math). Vorläufige experimentelle Ergebnisse, die vom Forschungsteam bekannt gegeben wurden, zeigen, dass das Sprachmodell durch die Fortsetzung des Vortrainings anhand von Lehrbüchern und Wikipedia-Teilmengen in MathPile erhebliche Verbesserungen der mathematischen Denkfähigkeiten auf verschiedenen Schwierigkeitsgraden erzielt hat.
Das Forschungsteam betonte außerdem, dass entsprechende Experimente noch im Gange seien.

Fazit
MathPile hat seit seiner Veröffentlichung große Aufmerksamkeit erhalten und wurde von vielen Parteien nachgedruckt. Derzeit steht es auf der Trendliste von Huggingface Datasets. Das Forschungsteam erklärte, dass es den Datensatz weiter optimieren und aktualisieren werde, um die Datenqualität weiter zu verbessern. 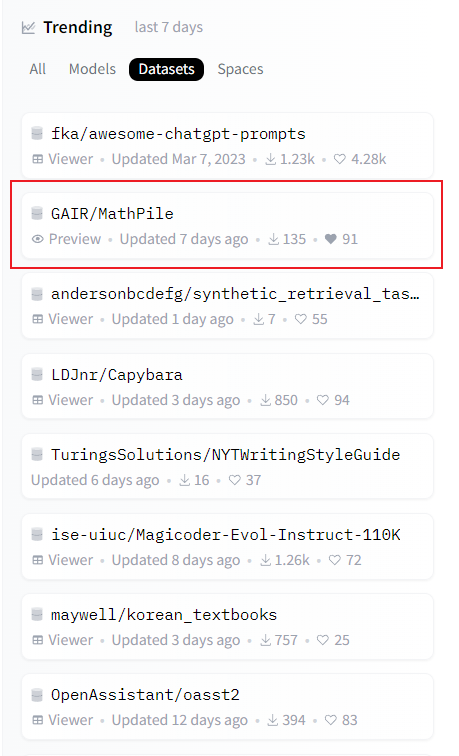
MathPile steht auf der Trendliste der Huggingface-Datensätze.  MathPile wurde vom bekannten KI-Blogger AK weitergeleitet, Quelle: https://twitter.com/_akhaliq/status/1740571256234057798.
MathPile wurde vom bekannten KI-Blogger AK weitergeleitet, Quelle: https://twitter.com/_akhaliq/status/1740571256234057798.
Derzeit wurde MathPile auf die zweite Version aktualisiert, um zur Forschung und Entwicklung der Open-Source-Community beizutragen. Gleichzeitig wurde auch die kommerzielle Version des Datensatzes der Öffentlichkeit zugänglich gemacht.
Das obige ist der detaillierte Inhalt vonUm die Mathematik für große Modelle zu ergänzen, reichen Sie den Open-Source-MathPile-Korpus mit 9,5 Milliarden Token ein, der auch kommerziell genutzt werden kann. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!