
Heim >Technologie-Peripheriegeräte >KI >Möchten Sie ein Sora-ähnliches Modell trainieren? Ihr Yang-Team OpenDiT erreicht eine Beschleunigung von 80 %
Möchten Sie ein Sora-ähnliches Modell trainieren? Ihr Yang-Team OpenDiT erreicht eine Beschleunigung von 80 %

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2024-02-29 16:34:381156Durchsuche
Soras erstaunliche Leistung Anfang 2024 ist zu einem neuen Maßstab geworden und inspiriert alle, die Wensheng-Videos studieren, dazu, schnell aufzuholen. Jeder Forscher ist bestrebt, Soras Ergebnisse zu reproduzieren und arbeitet gegen die Zeit.
Laut dem von OpenAI veröffentlichten technischen Bericht besteht ein wichtiger Innovationspunkt von Sora darin, visuelle Daten in eine einheitliche Darstellung von Patches umzuwandeln und durch die Kombination von Transformer und Diffusionsmodell eine hervorragende Skalierbarkeit zu demonstrieren. Mit der Veröffentlichung des Berichts hat das von William Peebles, Soras Kernentwickler, und Xie Saining, Assistenzprofessor für Informatik an der New York University, gemeinsam verfasste Papier „Scalable Diffusion Models with Transformers“ große Aufmerksamkeit bei Forschern auf sich gezogen. Die Forschungsgemeinschaft hofft, durch die im Papier vorgeschlagene DiT-Architektur mögliche Wege zur Reproduktion von Sora zu erkunden.
Kürzlich hat ein Open-Source-Projekt namens OpenDiT des You Yang-Teams der National University of Singapore neue Ideen für das Training und den Einsatz von DiT-Modellen eröffnet.
OpenDiT ist ein System zur Verbesserung der Trainings- und Inferenzeffizienz von DiT-Anwendungen. Es ist nicht nur einfach zu bedienen, sondern auch schnell und speichereffizient. Das System umfasst Funktionen wie die Text-zu-Video-Generierung und die Text-zu-Bild-Generierung und zielt darauf ab, Benutzern ein effizientes und komfortables Erlebnis zu bieten.
Projektadresse: https://github.com/NUS-HPC-AI-Lab/OpenDiT
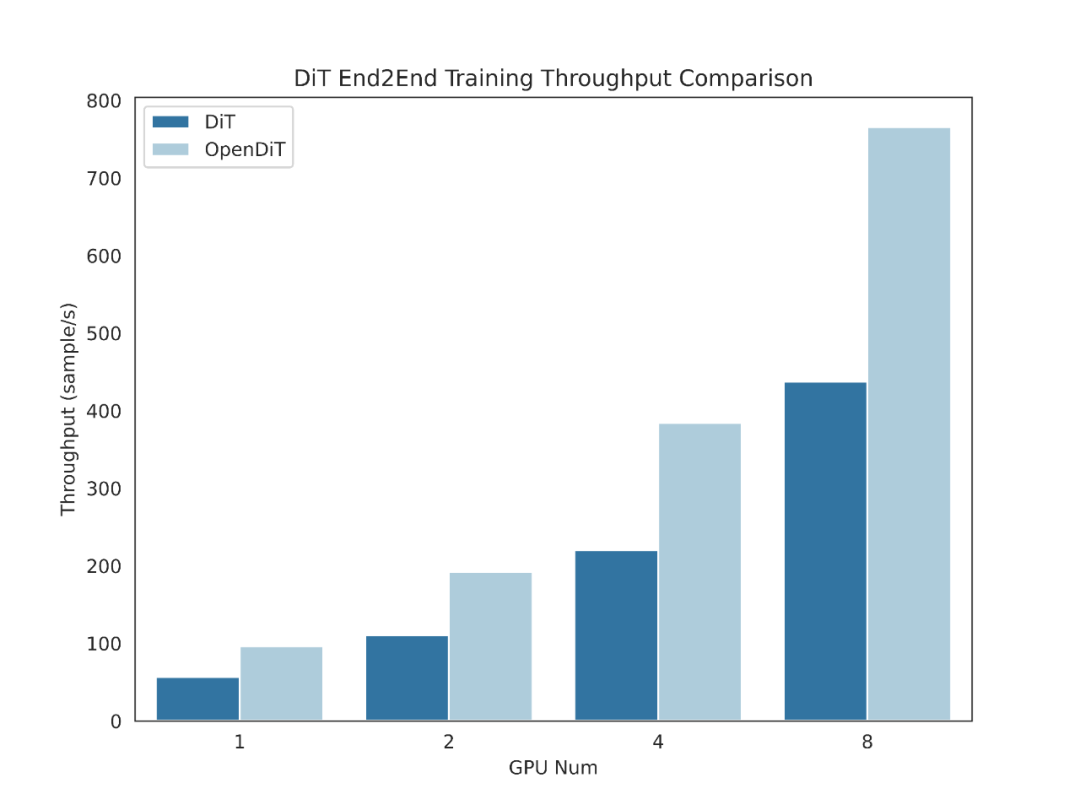
Einführung in die OpenDiT-Methode
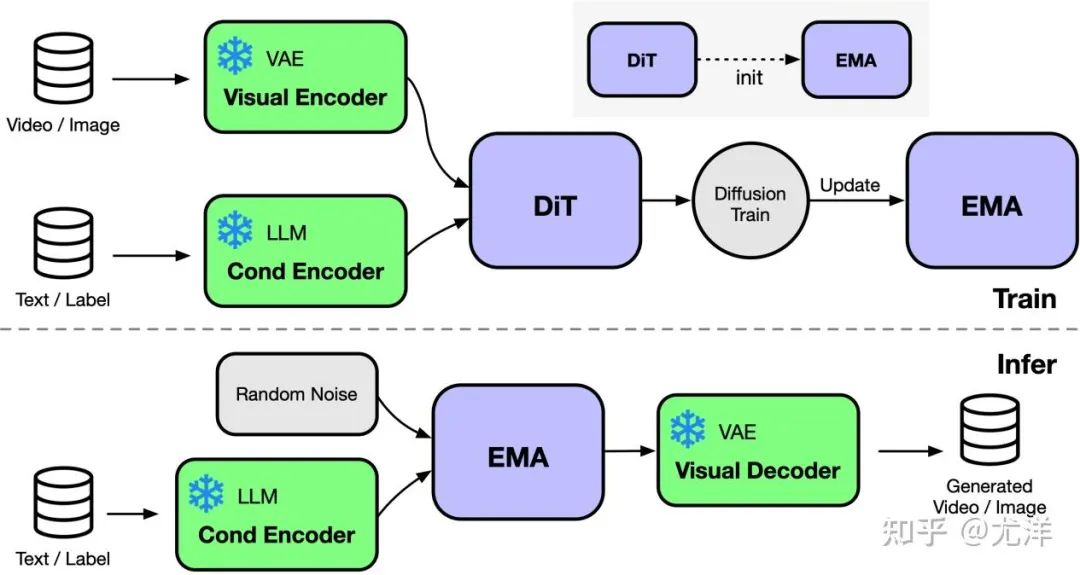
OpenDiT bietet Diffusion unterstützt durch Colossal-AI A Hochleistungsimplementierung von Transformer (DiT). Während des Trainings werden Video- und Zustandsinformationen in den entsprechenden Encoder bzw. als Eingabe in das DiT-Modell eingegeben. Anschließend werden Training und Parameteraktualisierung über die Diffusionsmethode durchgeführt und schließlich werden die aktualisierten Parameter mit dem EMA-Modell (Exponential Moving Average) synchronisiert. In der Inferenzphase wird das EMA-Modell direkt verwendet und Bedingungsinformationen als Eingabe verwendet, um entsprechende Ergebnisse zu generieren.
Bildquelle: https://www.zhihu.com/people/berkeley-you-yang
OpenDiT verwendet die ZeRO-Parallelstrategie, um die DiT-Modellparameter auf mehrere Maschinen zu verteilen. Vorläufig Reduzierter Speicher Druck. Um ein besseres Gleichgewicht zwischen Leistung und Genauigkeit zu erreichen, wendet OpenDiT außerdem eine Trainingsstrategie mit gemischter Präzision an. Insbesondere werden Modellparameter und Optimierer mit float32 gespeichert, um genaue Aktualisierungen sicherzustellen. Während des Modellberechnungsprozesses entwickelte das Forschungsteam eine gemischte Präzisionsmethode aus float16 und float32 für das DiT-Modell, um den Berechnungsprozess zu beschleunigen und gleichzeitig die Modellgenauigkeit beizubehalten.
Die im DiT-Modell verwendete EMA-Methode ist eine Strategie zur Glättung von Modellparameteraktualisierungen, die die Stabilität und Generalisierungsfähigkeit des Modells effektiv verbessern kann. Allerdings wird eine zusätzliche Kopie der Parameter erstellt, was die Belastung des Videospeichers erhöht. Um diesen Teil des Videospeichers weiter zu reduzieren, fragmentierte das Forschungsteam das EMA-Modell und speicherte es auf verschiedenen GPUs. Während des Trainingsprozesses muss jede GPU nur ihren eigenen Teil der EMA-Modellparameter berechnen und speichern und nach jedem Schritt warten, bis ZeRO die Aktualisierung für synchrone Aktualisierungen abgeschlossen hat.
FastSeq
Im Bereich visueller generativer Modelle wie DiT ist Sequenzparallelität für effizientes Training langer Sequenzen und Inferenz mit geringer Latenz von wesentlicher Bedeutung.
Bestehende Methoden wie DeepSpeed-Ulysses, Megatron-LM-Sequenzparallelität usw. stoßen jedoch bei der Anwendung auf solche Aufgaben an Grenzen – entweder führt sie zu viel Sequenzkommunikation ein oder fehlt sie, wenn es um die Effizienz der Sequenzparallelität im kleinen Maßstab geht.
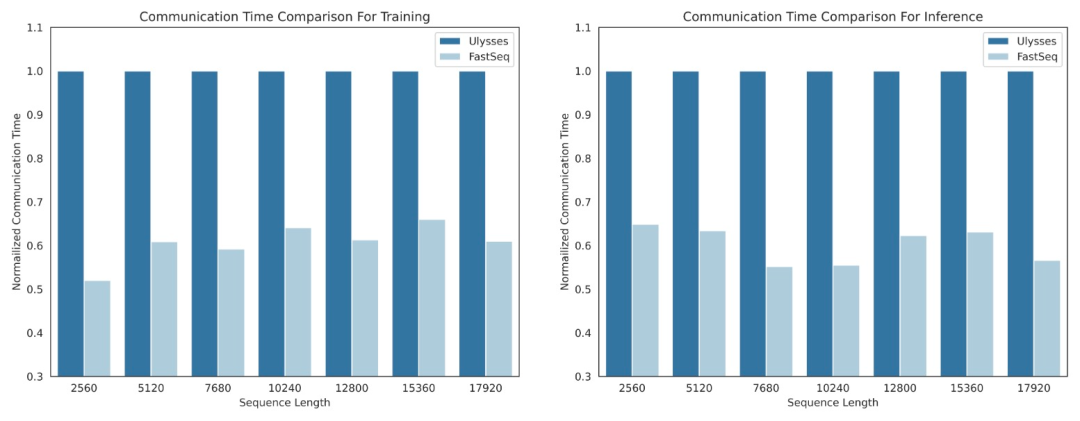
Zu diesem Zweck schlug das Forschungsteam FastSeq vor, eine neue Sequenzparallelität, die für große Sequenzen und Parallelität im kleinen Maßstab geeignet ist. FastSeq minimiert die Sequenzkommunikation durch den Einsatz von nur zwei Kommunikationsoperatoren pro Transformatorschicht, nutzt AllGather zur Verbesserung der Kommunikationseffizienz und setzt strategisch asynchrone Ringe ein, um die AllGather-Kommunikation mit qkv-Berechnungen zu überlappen und so die Leistung weiter zu optimieren.
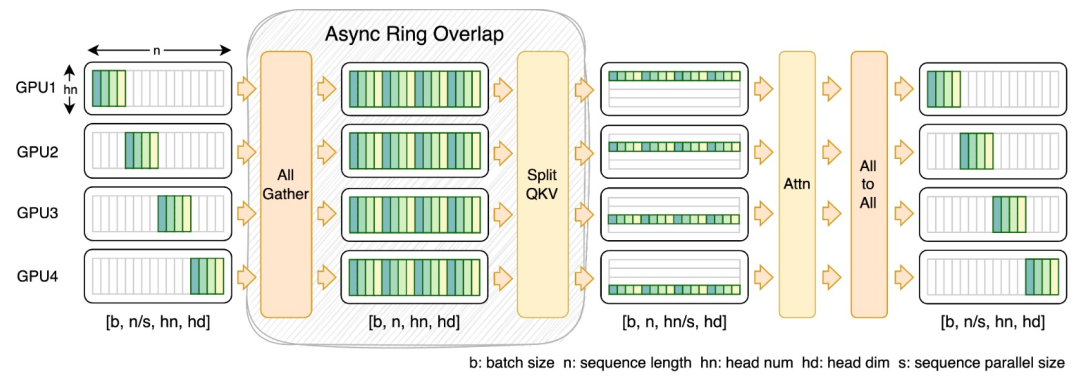
Betreiberoptimierung
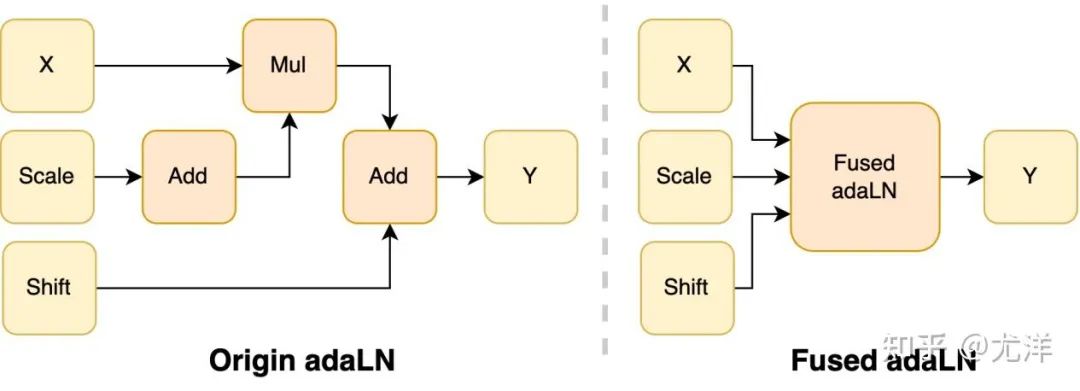
Das adaLN-Modul wird in das DiT-Modell eingeführt, um bedingte Informationen in visuelle Inhalte zu integrieren. Obwohl dieser Vorgang für die Verbesserung der Leistung des Modells von entscheidender Bedeutung ist, bringt er auch eine große Anzahl elementweiser Vorgänge mit sich und wird häufig aufgerufen das Modell, was die Gesamtrecheneffizienz verringert. Um dieses Problem zu lösen, schlug das Forschungsteam einen effizienten Fused adaLN-Kernel vor, der mehrere Vorgänge zu einem zusammenführt, wodurch die Recheneffizienz erhöht und der I/O-Verbrauch visueller Informationen reduziert wird.
Bildquelle: https://www.zhihu.com/people/berkeley-you-yang
Einfach ausgedrückt hat OpenDiT die folgenden Leistungsvorteile:
1 GPU Bis zu 80 % Beschleunigung, 50 % Speichereinsparung
- Entwickelte effiziente Operatoren, einschließlich Fused AdaLN für DiT sowie FlashAttention, Fused Layernorm und HybridAdam.
- Verwendung eines hybriden parallelen Ansatzes einschließlich ZeRO, Gemini und DDP. Durch das Sharding des ema-Modells werden außerdem die Speicherkosten weiter reduziert.
2. FastSeq: Ein neuartiger sequenzparalleler Ansatz
- ist für DiT-ähnliche Arbeitslasten konzipiert, bei denen Sequenzen normalerweise länger sind, aber die Parameter kleiner sind als bei LLM Small.
- Knoteninterne Sequenzparallelität kann bis zu 48 % des Kommunikationsvolumens einsparen.
- Überwinden Sie die Speicherbeschränkungen einer einzelnen GPU und reduzieren Sie die gesamte Trainings- und Inferenzzeit.
3. Einfach zu bedienen
- Mit nur wenigen Codezeilen können Sie enorme Leistungsverbesserungen erzielen.
- Benutzer müssen nicht verstehen, wie verteiltes Training umgesetzt wird.
4. Komplette Pipeline zur Text-zu-Bild- und Text-zu-Video-Generierung
- Forscher und Ingenieure können die OpenDiT-Pipeline einfach nutzen und auf praktische Anwendungen anwenden, ohne den parallelen Teil zu ändern.
- Das Forschungsteam überprüfte die Genauigkeit von OpenDiT, indem es ein Text-zu-Bild-Training auf ImageNet durchführte und einen Prüfpunkt freigab.
Installation und Verwendung
Um OpenDiT nutzen zu können, müssen Sie zunächst die Voraussetzungen installieren:
- Python >= 3.10
- PyTorch >= 1.13 beendet, um >2 zu verwenden. 0-Version)
- CUDA >= 11.6
Es wird empfohlen, eine neue Umgebung mit Anaconda (Python >= 3.10) zu erstellen, um die Beispiele auszuführen:
conda create -n opendit pythnotallow=3.10 -yconda activate opendit
Installieren Sie ColossalAI:
git clone https://github.com/hpcaitech/ColossalAI.gitcd ColossalAIgit checkout adae123df3badfb15d044bd416f0cf29f250bc86pip install -e .
Installieren Sie OpenDiT:
git clone https://github.com/oahzxl/OpenDiTcd OpenDiTpip install -e .
(optional, aber empfohlen) Installieren Sie Bibliotheken, um Training und Inferenz zu beschleunigen:
# Install Triton for fused adaln kernelpip install triton# Install FlashAttentionpip install flash-attn# Install apex for fused layernorm kernelgit clone https://github.com/NVIDIA/apex.gitcd apexgit checkout 741bdf50825a97664db08574981962d66436d16apip install -v --disable-pip-version-check --no-cache-dir --no-build-isolation --config-settings "--build-optinotallow=--cpp_ext" --config-settings "--build-optinotallow=--cuda_ext" ./--global-optinotallow="--cuda_ext" --global-optinotallow="--cpp_ext"
Bilderzeugung
Du kannst trainieren das DiT-Modell durch Ausführen des folgenden Befehls:
# Use scriptbash train_img.sh# Use command linetorchrun --standalone --nproc_per_node=2 train.py \--model DiT-XL/2 \--batch_size 2
Alle Beschleunigungsmethoden sind standardmäßig deaktiviert. Hier sind Details zu einigen der Schlüsselelemente im Trainingsprozess:
- Plugin: Unterstützt Booster-Plugins, die von ColossalAI, Zero2 und DDP verwendet werden. Der Standardwert ist Null2. Es wird empfohlen, Null2 zu aktivieren.
- mixed_precision: Der Datentyp des gemischten Präzisionstrainings, der Standardwert ist fp16.
- grad_checkpoint: Ob der Gradienten-Checkpoint aktiviert werden soll. Dies spart Speicherkosten für den Trainingsprozess. Der Standardwert ist False. Es wird empfohlen, es zu deaktivieren, wenn genügend Speicher vorhanden ist.
- enable_modulate_kernel: Gibt an, ob die modulierte Kerneloptimierung aktiviert werden soll, um den Trainingsprozess zu beschleunigen. Der Standardwert ist False und es wird empfohlen, ihn auf GPUs
- enable_layernorm_kernel: Gibt an, ob die Layernorm-Kerneloptimierung aktiviert werden soll, um den Trainingsprozess zu beschleunigen. Der Standardwert ist False und es wird empfohlen, ihn zu aktivieren.
- enable_flashattn: Ob FlashAttention aktiviert werden soll, um den Trainingsprozess zu beschleunigen. Der Standardwert ist False und es wird empfohlen, ihn zu aktivieren.
- sequence_parallel_size: Größe der Sequenzparallelität. Die Sequenzparallelität wird aktiviert, wenn ein Wert > 1 eingestellt wird. Der Standardwert ist 1. Es wird empfohlen, ihn zu deaktivieren, wenn genügend Speicher vorhanden ist.
Wenn Sie das DiT-Modell zur Inferenz verwenden möchten, können Sie den folgenden Code ausführen. Sie müssen den Prüfpunktpfad durch Ihr eigenes trainiertes Modell ersetzen.
# Use scriptbash sample_img.sh# Use command linepython sample.py --model DiT-XL/2 --image_size 256 --ckpt ./model.pt
视频生成
你可以通过执行以下命令来训练视频 DiT 模型:
# train with sciptbash train_video.sh# train with command linetorchrun --standalone --nproc_per_node=2 train.py \--model vDiT-XL/222 \--use_video \--data_path ./videos/demo.csv \--batch_size 1 \--num_frames 16 \--image_size 256 \--frame_interval 3# preprocess# our code read video from csv as the demo shows# we provide a code to transfer ucf101 to csv formatpython preprocess.py
使用 DiT 模型执行视频推理的代码如下所示:
# Use scriptbash sample_video.sh# Use command linepython sample.py \--model vDiT-XL/222 \--use_video \--ckpt ckpt_path \--num_frames 16 \--image_size 256 \--frame_interval 3
DiT 复现结果
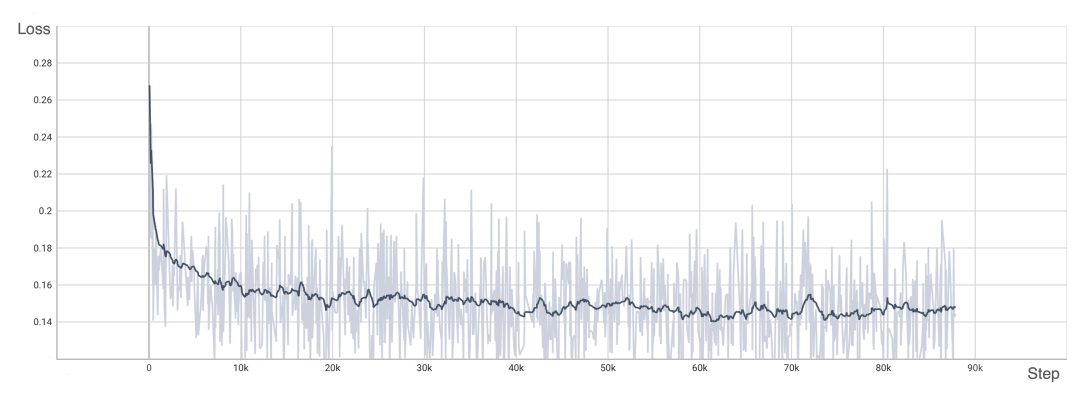
为了验证 OpenDiT 的准确性,研究团队使用 OpenDiT 的 origin 方法对 DiT 进行了训练,在 ImageNet 上从头开始训练模型,在 8xA100 上执行 80k step。以下是经过训练的 DiT 生成的一些结果:

损失也与 DiT 论文中列出的结果一致:
要复现上述结果,需要更改 train_img.py 中的数据集并执行以下命令:
torchrun --standalone --nproc_per_node=8 train.py \--model DiT-XL/2 \--batch_size 180 \--enable_layernorm_kernel \--enable_flashattn \--mixed_precision fp16
感兴趣的读者可以查看项目主页,了解更多研究内容。
Das obige ist der detaillierte Inhalt vonMöchten Sie ein Sora-ähnliches Modell trainieren? Ihr Yang-Team OpenDiT erreicht eine Beschleunigung von 80 %. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Wie kann das Problem gelöst werden, dass die Attributleiste oben in der KI fehlt?
- Wovon ist das konzeptionelle Modell einer Datenbank unabhängig?
- Was ist ein Softwareentwicklungsmodell und welche gängigen Softwareentwicklungsmodelle gibt es?
- Was ist KI-Technologie?
- Was ist der Unterschied zwischen Apple Mac Air und Pro?