
Heim >Technologie-Peripheriegeräte >KI >Wählen Sie das Einbettungsmodell, das am besten zu Ihren Daten passt: Ein Vergleichstest von OpenAI und mehrsprachigen Open-Source-Einbettungen
Wählen Sie das Einbettungsmodell, das am besten zu Ihren Daten passt: Ein Vergleichstest von OpenAI und mehrsprachigen Open-Source-Einbettungen

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2024-02-26 18:10:151260Durchsuche
OpenAI hat kürzlich die Einführung seines Einbettungsmodells Embedding v3 der neuesten Generation angekündigt, das seiner Meinung nach das leistungsfähigste Einbettungsmodell mit höherer Mehrsprachenleistung ist. Diese Reihe von Modellen ist in zwei Typen unterteilt: das kleinere Text-Embeddings-3-Small und das leistungsfähigere und größere Text-Embeddings-3-Large.

Es werden nur sehr wenige Informationen darüber offengelegt, wie diese Modelle entworfen und trainiert werden, und auf die Modelle kann nur über kostenpflichtige APIs zugegriffen werden. Es gab also viele Open-Source-Einbettungsmodelle. Aber wie schneiden diese Open-Source-Modelle im Vergleich zum Closed-Source-Modell von OpenAI ab?
In diesem Artikel wird die Leistung dieser neuen Modelle empirisch mit Open-Source-Modellen verglichen. Wir planen, einen Datenabruf-Workflow aufzubauen, dessen Hauptaufgabe darin besteht, basierend auf der Anfrage des Benutzers die relevantesten Dokumente aus dem Korpus zu finden.
Unser Korpus ist das Europäische Gesetz zur künstlichen Intelligenz, das sich derzeit in der Validierungsphase befindet. Dieses Korpus ist der weltweit erste Rechtsrahmen, der künstliche Intelligenz einbezieht, und ist insofern einzigartig, als es in 24 Sprachen verfügbar ist. Dies ermöglicht es uns, die Genauigkeit des Datenabrufs in verschiedenen Sprachhintergründen zu vergleichen, was wichtige Unterstützung für die interkulturelle Anwendung künstlicher Intelligenz liefert.
Wir planen, einen benutzerdefinierten synthetischen Frage-/Antwortdatensatz mithilfe eines mehrsprachigen Textkorpus zu erstellen und diesen Datensatz zu verwenden, um die Genauigkeit von OpenAI und hochmodernen Open-Source-Einbettungsmodellen zu vergleichen. Wir werden den vollständigen Code weitergeben, da unser Ansatz leicht an andere Datenkorpora angepasst werden kann.
Erstellen Sie einen benutzerdefinierten Frage-/Antwort-Datensatz Werden Sie nicht Teil der Modelltrainings-Bias-Faktoren, um Situationen zu vermeiden, die denen ähneln, die bei Benchmark-Referenzen wie MTEB auftreten können. Darüber hinaus können wir durch die Generierung benutzerdefinierter Datensätze den Bewertungsprozess an einen bestimmten Datenkorpus anpassen, was für Szenarien wie Retrieval Augmentation Applications (RAG) wichtig sein kann.
Wir folgen dem einfachen Prozess, der in der Llama-Index-Dokumentation vorgeschlagen wird. Zunächst wird der Korpus in Stücke geteilt. Als nächstes wird für jeden Block ein großes Sprachmodell (LLM) verwendet, um eine Reihe synthetischer Fragen zu generieren, um sicherzustellen, dass sich die Antwort im entsprechenden Block befindet.
Die Implementierung dieser Strategie mithilfe eines LLM-Datenrahmens wie Llama Index ist sehr einfach, wie im folgenden Code gezeigt. Das 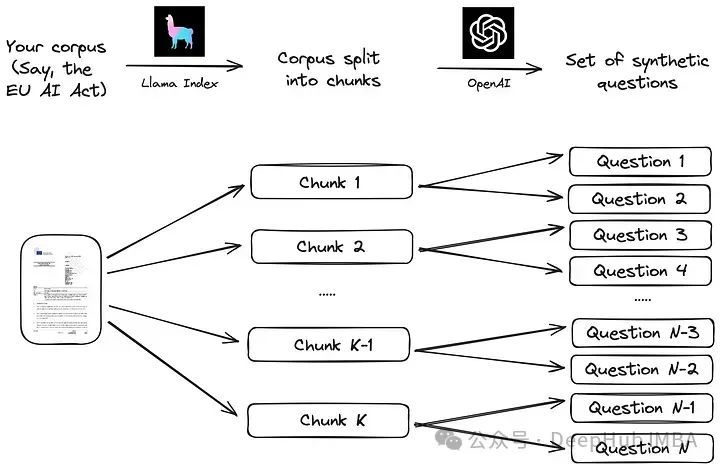
from llama_index.readers.web import SimpleWebPageReader from llama_index.core.node_parser import SentenceSplitter language = "EN" url_doc = "https://eur-lex.europa.eu/legal-content/"+language+"/TXT/HTML/?uri=CELEX:52021PC0206" documents = SimpleWebPageReader(html_to_text=True).load_data([url_doc]) parser = SentenceSplitter(chunk_size=1000) nodes = parser.get_nodes_from_documents(documents, show_progress=True)-Korpus ist die englische Version des EU-Gesetzes über künstliche Intelligenz, die über diese offizielle URL direkt aus dem Internet bezogen werden kann. In diesem Artikel wird die Entwurfsversion vom April 2021 verwendet, da die endgültige Version noch nicht in allen europäischen Sprachen verfügbar ist. Die von uns gewählte Version kann also die Sprache in der URL durch eine der anderen 23 offiziellen EU-Sprachen ersetzen und Text in verschiedenen Sprachen abrufen (BG für Bulgarisch, ES für Spanisch, CS für Tschechisch usw.).
Verwenden Sie ein SentenceSplitter-Objekt, um das Dokument in Blöcke zu je 1000 Token aufzuteilen. Für Englisch werden dadurch etwa 100 Blöcke generiert. Jeder Block wird dann als Kontext für die folgende Eingabeaufforderung angegeben (die in der Llama-Indexbibliothek vorgeschlagene Standardeingabeaufforderung): 
prompts={} prompts["EN"] = """\ Context information is below. --------------------- {context_str} --------------------- Given the context information and not prior knowledge, generate only questions based on the below query. You are a Teacher/ Professor. Your task is to setup {num_questions_per_chunk} questions for an upcoming quiz/examination. The questions should be diverse in nature across the document. Restrict the questions to the context information provided." """
Diese Eingabeaufforderung kann Fragen zum Dokumentblock generieren, mit der Anzahl der für jeden zu generierenden Fragen data chunk as Der Parameter „num_questions_per_chunk“ wird übergeben und wir setzen ihn auf 2. Fragen können dann durch den Aufruf von generic_qa_embedding_pairs in der Llama-Index-Bibliothek generiert werden:
from llama_index.llms import OpenAI from llama_index.legacy.finetuning import generate_qa_embedding_pairs qa_dataset = generate_qa_embedding_pairs(llm=OpenAI(model="gpt-3.5-turbo-0125",additional_kwargs={'seed':42}),nodes=nodes,qa_generate_prompt_tmpl = prompts[language],num_questions_per_chunk=2 )
我们依靠OpenAI的GPT-3.5-turbo-0125来完成这项任务,结果对象' qa_dataset '包含问题和答案(块)对。作为生成问题的示例,以下是前两个问题的结果(其中“答案”是文本的第一部分):
- What are the main objectives of the proposal for a Regulation laying down harmonised rules on artificial intelligence (Artificial Intelligence Act) according to the explanatory memorandum?
- How does the proposal for a Regulation on artificial intelligence aim to address the risks associated with the use of AI while promoting the uptake of AI in the European Union, as outlined in the context information?
OpenAI嵌入模型
评估函数也是遵循Llama Index文档:首先所有答案(文档块)的嵌入都存储在VectorStoreIndex中,以便有效检索。然后评估函数循环遍历所有查询,检索前k个最相似的文档,并根据MRR (Mean Reciprocal Rank)评估检索的准确性,代码如下:
def evaluate(dataset, embed_model, insert_batch_size=1000, top_k=5):# Get corpus, queries, and relevant documents from the qa_dataset objectcorpus = dataset.corpusqueries = dataset.queriesrelevant_docs = dataset.relevant_docs # Create TextNode objects for each document in the corpus and create a VectorStoreIndex to efficiently store and retrieve embeddingsnodes = [TextNode(id_=id_, text=text) for id_, text in corpus.items()]index = VectorStoreIndex(nodes, embed_model=embed_model, insert_batch_size=insert_batch_size)retriever = index.as_retriever(similarity_top_k=top_k) # Prepare to collect evaluation resultseval_results = [] # Iterate over each query in the dataset to evaluate retrieval performancefor query_id, query in tqdm(queries.items()):# Retrieve the top_k most similar documents for the current query and extract the IDs of the retrieved documentsretrieved_nodes = retriever.retrieve(query)retrieved_ids = [node.node.node_id for node in retrieved_nodes] # Check if the expected document was among the retrieved documentsexpected_id = relevant_docs[query_id][0]is_hit = expected_id in retrieved_ids # assume 1 relevant doc per query # Calculate the Mean Reciprocal Rank (MRR) and append to resultsif is_hit:rank = retrieved_ids.index(expected_id) + 1mrr = 1 / rankelse:mrr = 0eval_results.append(mrr) # Return the average MRR across all queries as the final evaluation metricreturn np.average(eval_results)
嵌入模型通过' embed_model '参数传递给评估函数,对于OpenAI模型,该参数是一个用模型名称和模型维度初始化的OpenAIEmbedding对象。
from llama_index.embeddings.openai import OpenAIEmbedding embed_model = OpenAIEmbedding(model=model_spec['model_name'],dimensinotallow=model_spec['dimensions'])
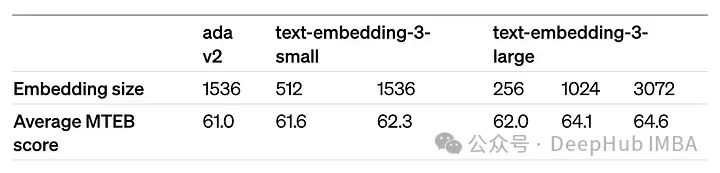
dimensions参数可以缩短嵌入(即从序列的末尾删除一些数字),而不会失去嵌入的概念表示属性。OpenAI在他们的公告中建议,在MTEB基准测试中,嵌入可以缩短到256大小,同时仍然优于未缩短的text-embedding-ada-002嵌入(大小为1536)。
我们在四种不同的嵌入模型上运行评估函数:
两个版本的text-embedding-3-large:一个具有最低可能维度(256),另一个具有最高可能维度(3072)。它们被称为“OAI-large-256”和“OAI-large-3072”。
OAI-small:text-embedding-3-small,维数为1536。
OAI-ada-002:传统的文本嵌入text-embedding-ada-002,维度为1536。
每个模型在四种不同的语言上进行评估:英语(EN),法语(FR),捷克语(CS)和匈牙利语(HU),分别涵盖日耳曼语,罗曼语,斯拉夫语和乌拉尔语的例子。
embeddings_model_spec = { } embeddings_model_spec['OAI-Large-256']={'model_name':'text-embedding-3-large','dimensions':256} embeddings_model_spec['OAI-Large-3072']={'model_name':'text-embedding-3-large','dimensions':3072} embeddings_model_spec['OAI-Small']={'model_name':'text-embedding-3-small','dimensions':1536} embeddings_model_spec['OAI-ada-002']={'model_name':'text-embedding-ada-002','dimensions':None} results = [] languages = ["EN", "FR", "CS", "HU"] # Loop through all languages for language in languages: # Load datasetfile_name=language+"_dataset.json"qa_dataset = EmbeddingQAFinetuneDataset.from_json(file_name) # Loop through all modelsfor model_name, model_spec in embeddings_model_spec.items(): # Get modelembed_model = OpenAIEmbedding(model=model_spec['model_name'],dimensinotallow=model_spec['dimensions']) # Assess embedding score (in terms of MRR)score = evaluate(qa_dataset, embed_model) results.append([language, model_name, score]) df_results = pd.DataFrame(results, columns = ["Language" ,"Embedding model", "MRR"])MRR精度如下:
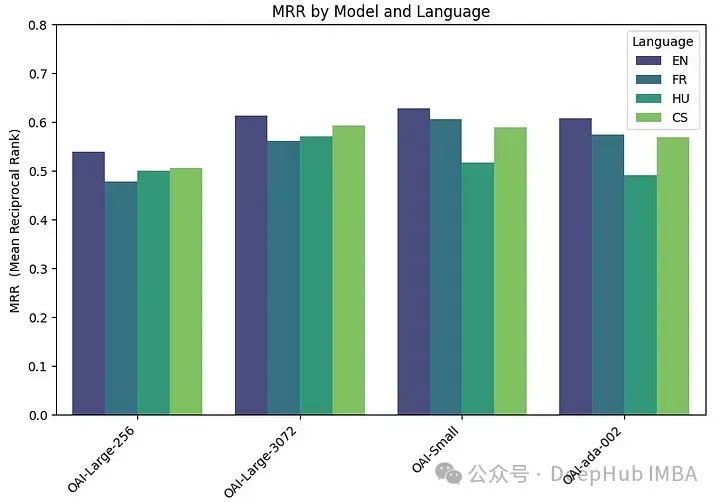
嵌入尺寸越大,性能越好。
开源嵌入模型
围绕嵌入的开源研究也是非常活跃的,Hugging Face 的 MTEB leaderboard会经常发布最新的嵌入模型。
为了在本文中进行比较,我们选择了一组最近发表的四个嵌入模型(2024)。选择的标准是他们在MTEB排行榜上的平均得分和他们处理多语言数据的能力。所选模型的主要特性摘要如下。

e5-mistral-7b-instruct:微软的这个E5嵌入模型是从Mistral-7B-v0.1初始化的,并在多语言混合数据集上进行微调。模型在MTEB排行榜上表现最好,但也是迄今为止最大的(14GB)。
multilingual-e5-large-instruct(ML-E5-large):微软的另一个E5模型,可以更好地处理多语言数据。它从xlm-roberta-large初始化,并在多语言数据集的混合上进行训练。它比E5-Mistral小得多(10倍),上下文大小也小得多(514)。
BGE-M3:该模型由北京人工智能研究院设计,是他们最先进的多语言数据嵌入模型,支持100多种工作语言。截至2024年2月22日,它还没有进入MTEB排行榜。
nomic-embed-text-v1 (Nomic- embed):该模型由Nomic设计,其性能优于OpenAI Ada-002和text-embedding-3-small,而且大小仅为0.55GB。该模型是第一个完全可复制和可审计的(开放数据和开源训练代码)的模型。
用于评估这些开源模型的代码类似于用于OpenAI模型的代码。主要的变化在于模型参数:
embeddings_model_spec = { } embeddings_model_spec['E5-mistral-7b']={'model_name':'intfloat/e5-mistral-7b-instruct','max_length':32768, 'pooling_type':'last_token', 'normalize': True, 'batch_size':1, 'kwargs': {'load_in_4bit':True, 'bnb_4bit_compute_dtype':torch.float16}} embeddings_model_spec['ML-E5-large']={'model_name':'intfloat/multilingual-e5-large','max_length':512, 'pooling_type':'mean', 'normalize': True, 'batch_size':1, 'kwargs': {'device_map': 'cuda', 'torch_dtype':torch.float16}} embeddings_model_spec['BGE-M3']={'model_name':'BAAI/bge-m3','max_length':8192, 'pooling_type':'cls', 'normalize': True, 'batch_size':1, 'kwargs': {'device_map': 'cuda', 'torch_dtype':torch.float16}} embeddings_model_spec['Nomic-Embed']={'model_name':'nomic-ai/nomic-embed-text-v1','max_length':8192, 'pooling_type':'mean', 'normalize': True, 'batch_size':1, 'kwargs': {'device_map': 'cuda', 'trust_remote_code' : True}} results = [] languages = ["EN", "FR", "CS", "HU"] # Loop through all models for model_name, model_spec in embeddings_model_spec.items(): print("Processing model : "+str(model_spec)) # Get modeltokenizer = AutoTokenizer.from_pretrained(model_spec['model_name'])embed_model = AutoModel.from_pretrained(model_spec['model_name'], **model_spec['kwargs']) if model_name=="Nomic-Embed":embed_model.to('cuda') # Loop through all languagesfor language in languages: # Load datasetfile_name=language+"_dataset.json"qa_dataset = EmbeddingQAFinetuneDataset.from_json(file_name) start_time_assessment=time.time() # Assess embedding score (in terms of hit rate at k=5)score = evaluate(qa_dataset, tokenizer, embed_model, model_spec['normalize'], model_spec['max_length'], model_spec['pooling_type']) # Get duration of score assessmentduration_assessment = time.time()-start_time_assessment results.append([language, model_name, score, duration_assessment]) df_results = pd.DataFrame(results, columns = ["Language" ,"Embedding model", "MRR", "Duration"])Die Ergebnisse sind wie folgt:
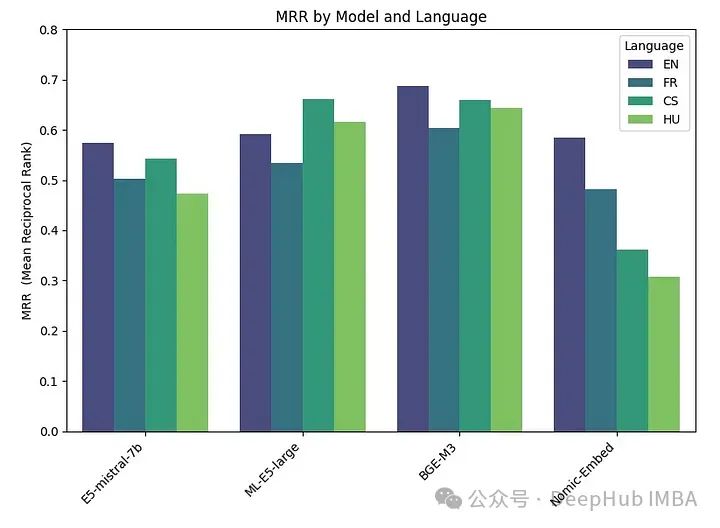
BGE-M3 schnitt am besten ab, gefolgt von ML-E5-Large, E5-mistral-7b und Nomic-Embed. Das BGE-M3-Modell wurde noch nicht in der MTEB-Rangliste bewertet und unsere Ergebnisse deuten darauf hin, dass es möglicherweise einen höheren Rang als andere Modelle einnimmt. Obwohl BGE-M3 für mehrsprachige Daten optimiert ist, schneidet es auch in Englisch besser ab als andere Modelle.
Da Open-Source-Modelle in der Regel lokal ausgeführt werden müssen, haben wir bewusst auch die Verarbeitungszeit jedes eingebetteten Modells erfasst.
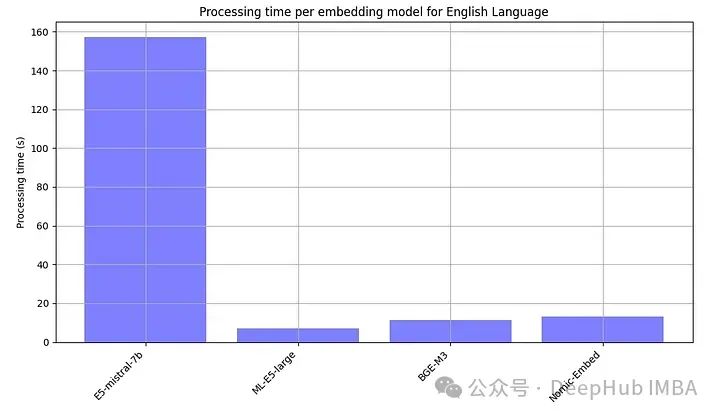
E5-mistral-7b ist mehr als zehnmal größer als andere Modelle, daher ist das langsamste normal
Zusammenfassung
Wir fassen alle Ergebnisse zusammen
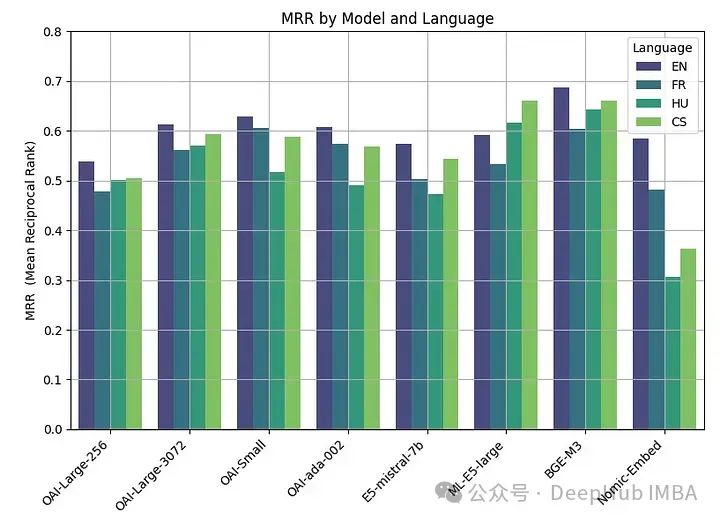
Das Beste Die Leistung wurde mit Open-Source-Modellen erreicht, wobei das BGE-M3-Modell die beste Leistung erbrachte. Dieses Modell hat die gleiche Kontextlänge (8 KB) wie das OpenAI-Modell und ist 2,2 GB groß.
Die Leistung der großen (3072), kleinen und ada-Modelle von OpenAI ist sehr ähnlich. Die Reduzierung der Einbettungsgröße von Large (256) führt zu Leistungseinbußen und ist nicht so gut wie ada, wie OpenAI sagt.
Fast alle Modelle (außer ML-E5-large) schneiden auf Englisch am besten ab. In Sprachen wie Tschechisch und Ungarisch gibt es erhebliche Leistungsunterschiede, möglicherweise weil weniger Daten zum Trainieren vorhanden sind.
Sollten wir für ein OpenAI-Abonnement bezahlen oder ein eingebettetes Open-Source-Modell hosten?
Die jüngste Preisanpassung von OpenAI hat ihre API erschwinglicher gemacht und kostet jetzt 0,13 US-Dollar pro Million Token. Wenn Sie eine Million Abfragen pro Monat verarbeiten (vorausgesetzt, jede Abfrage umfasst etwa 1.000 Token), belaufen sich die Kosten auf etwa 130 US-Dollar. Daher können Sie basierend auf den tatsächlichen Anforderungen entscheiden, ob Sie das Open-Source-Einbettungsmodell hosten möchten.
Natürlich ist die Kosteneffizienz nicht der einzige Gesichtspunkt. Möglicherweise müssen auch andere Faktoren wie Latenz, Datenschutz und Kontrolle über Datenverarbeitungsabläufe berücksichtigt werden. Das Open-Source-Modell bietet die Vorteile einer vollständigen Datenkontrolle, eines verbesserten Datenschutzes und einer individuellen Anpassung.
Apropos Latenz: Die API von OpenAI hat auch Latenzprobleme, die manchmal zu längeren Antwortzeiten führen, sodass die API von OpenAI manchmal nicht unbedingt die schnellste Wahl ist.
Zusammenfassend lässt sich sagen, dass die Wahl zwischen Open-Source-Modellen und proprietären Lösungen wie OpenAI keine einfache Antwort ist. Die Open-Source-Einbettung bietet eine großartige Option, die Leistung mit größerer Kontrolle über Ihre Daten kombiniert. Und die Produkte von OpenAI könnten immer noch diejenigen ansprechen, die Wert auf Bequemlichkeit legen, insbesondere wenn Datenschutzbedenken zweitrangig sind.
Code dieses Artikels: https://github.com/Yannael/multilingual-embeddings
Das obige ist der detaillierte Inhalt vonWählen Sie das Einbettungsmodell, das am besten zu Ihren Daten passt: Ein Vergleichstest von OpenAI und mehrsprachigen Open-Source-Einbettungen. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Was müssen Sie über die künstliche Intelligenz von Python lernen?
- Auf welche Bereiche konzentriert sich Künstliche Intelligenz derzeit?
- Was sind die Hauptanwendungen künstlicher Intelligenz in der Bildung?
- Was ist der Kern der künstlichen Intelligenz?
- Wird sich Teslas selbstfahrender Guru an ChatGPT beteiligen? Werde OpenAI beitreten